Pytorch深度学习实践第十二讲 RNN 课后1(LSTM)
B站 刘二大人 传送门 循环神经网络(基础篇)
课件链接:https://pan.baidu.com/s/1vZ27gKp8Pl-qICn_p2PaSw
提取码:cxe4
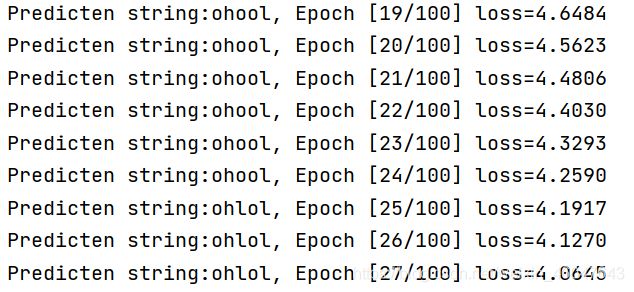
模型还是将输入“hello”训练输出为“ohlol”,用LSTM网络实现。按照计算图实现LSTM之后,又尝试了加入embedding的方法。加embedding的训练快,但是我的LSTM效果不如前面RNN的,不知道是我网络写的有问题还是怎么回事。

LSTM的网络结构示意图和公式:
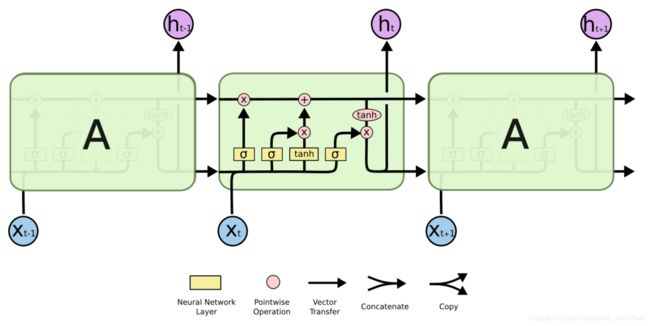
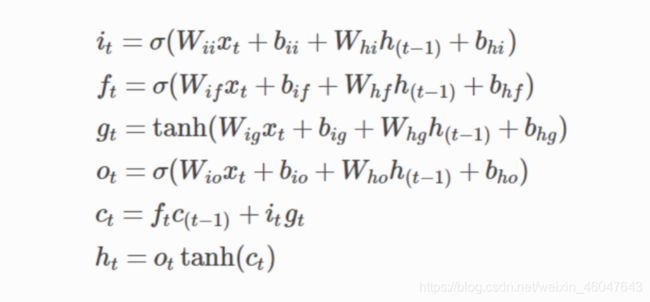
根据我自己的理解写出来的LSTM模型,有不对的地方欢迎指正。
首先看公式有8个线性层,之后又进行了非线性运算,所以模型定义了8个linear。输入是4维向量(h、e、l、o),不打算改变维度,所以输出也都是4维。只有5个输入,所以批量设为1.向前传播根据计算公式和计算图,返回hidden和c继续在下一轮计算继续用。
import torch
input_size = 4
batch_size = 1
class LSTM(torch.nn.Module):
def __init__(self):
super(LSTM, self).__init__()
self.linearix = torch.nn.Linear(4, 4)
self.linearfx = torch.nn.Linear(4, 4)
self.lineargx = torch.nn.Linear(4, 4)
self.linearox = torch.nn.Linear(4, 4)
self.linearih = torch.nn.Linear(4, 4)
self.linearfh = torch.nn.Linear(4, 4)
self.lineargh = torch.nn.Linear(4, 4)
self.linearoh = torch.nn.Linear(4, 4)
self.sigmoid = torch.nn.Sigmoid()
self.tanh = torch.nn.Tanh()
def forward(self, x, hidden, c):
i = self.sigmoid(self.linearix(x) + self.linearih(hidden))
f = self.sigmoid(self.linearfx(x) + self.linearfh(hidden))
g = self.tanh(self.lineargx(x) + self.lineargh(hidden))
o = self.sigmoid(self.linearox(x) + self.linearoh(hidden))
c = f * c + i * g
hidden = o * self.tanh(c)
return hidden, c
net = LSTM()
#---计算损失和更新
criterion = torch.nn.CrossEntropyLoss()#交叉熵
optimizer = torch.optim.Adam(net.parameters(), lr = 0.01)
#---计算损失和更新
我把数据和训练过程定义在一个函数里了
def train():
idx2char = ['e', 'h', 'l', 'o'] # 方便最后输出结果
x_data = [1, 0, 2, 2, 3] # 输入向量
y_data = [3, 1, 2, 3, 2] # 标签
one_hot_lookup = [[1, 0, 0, 0], # 查询ont hot编码 方便转换
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]
x_one_hot = [one_hot_lookup[x] for x in x_data] # 按"1 0 2 2 3"顺序取one_hot_lookup中的值赋给x_one_hot
'''运行结果为x_one_hot = [ [0, 1, 0, 0],
[1, 0, 0, 0],
[0, 0, 1, 0],
[0, 0, 1, 0],
[0, 0, 0, 1] ]
刚好对应输入向量,也对应着字符值'hello'
'''
inputs = torch.Tensor(x_one_hot).view(-1, batch_size, input_size)
labels = torch.LongTensor(y_data).view(-1, 1) # 增加维度方便计算loss
# ---计算损失和更新
criterion = torch.nn.CrossEntropyLoss() # 交叉熵
optimizer = torch.optim.Adam(net.parameters(), lr=0.01)
# ---计算损失和更新
for epoch in range(100):#开始训练
loss = 0
optimizer.zero_grad()
hidden = torch.zeros(batch_size, input_size)#提供初始化隐藏层(h0)
c = torch.zeros(batch_size, input_size) # 提供初始化隐藏层(c0)
print('Predicten string:', end='')
for input, label in zip(inputs,labels):#并行遍历数据集 一个一个训练
hidden, c = net(input, hidden, c)
loss += criterion(hidden, label)#hidden.shape=(1,4) label.shape=1
_, idx = hidden.max(dim=1)#从第一个维度上取出预测概率最大的值和该值所在序号
print(idx2char[idx.item()], end='')#按上面序号输出相应字母字符
loss.backward()
optimizer.step()
print(', Epoch [%d/100] loss=%.4f' %(epoch+1, loss.item()))
差不多训练50-100次左右输出正确结果。
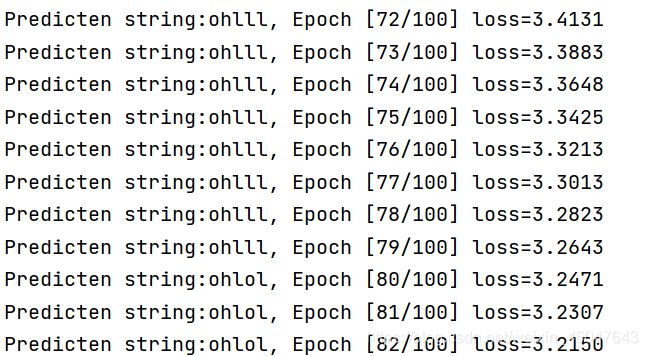
下面放加入embedding的代码。嵌入维度设的是10,所以网络x的线性层要改成输入10,输出4的,hidden的线性层不用改。
class emb_LSTM(torch.nn.Module):
def __init__(self):
super(emb_LSTM, self).__init__()
self.linearix = torch.nn.Linear(10, 4)
self.linearfx = torch.nn.Linear(10, 4)
self.lineargx = torch.nn.Linear(10, 4)
self.linearox = torch.nn.Linear(10, 4)
self.linearih = torch.nn.Linear(4, 4)
self.linearfh = torch.nn.Linear(4, 4)
self.lineargh = torch.nn.Linear(4, 4)
self.linearoh = torch.nn.Linear(4, 4)
self.sigmoid = torch.nn.Sigmoid()
self.tanh = torch.nn.Tanh()
def forward(self, x, hidden, c):
i = self.sigmoid(self.linearix(x) + self.linearih(hidden))
f = self.sigmoid(self.linearfx(x) + self.linearfh(hidden))
g = self.tanh(self.lineargx(x) + self.lineargh(hidden))
o = self.sigmoid(self.linearox(x) + self.linearoh(hidden))
c = f * c + i * g
hidden = o * self.tanh(c)
return hidden, c
model = emb_LSTM()
数据处理和训练过程写在一个函数里了。因为维度不对应,前后debug好几遍修改输入数据维度。
def emb_train():
idx2char = ['e', 'h', 'l', 'o'] # 方便最后输出结果
x_data = torch.LongTensor([[1, 0, 2, 2, 3]]).view(5, 1)
y_data = [3, 1, 2, 3, 2] # 标签
labels = torch.LongTensor(y_data).view(-1, 1) # 增加维度方便计算loss
emb = torch.nn.Embedding(4, 10)
inputs = emb(x_data)
# ---计算损失和更新
criterion = torch.nn.CrossEntropyLoss() # 交叉熵
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
# ---计算损失和更新
for epoch in range(100):
loss = 0
optimizer.zero_grad()
hidden = torch.zeros(batch_size, input_size)#提供初始化隐藏层(h0)
c = torch.zeros(batch_size, input_size) # 提供初始化隐藏层(c0)
print('Predicten string:', end='')
for input, label in zip(inputs,labels):#并行遍历数据集 一个一个训练
hidden, c = model(input, hidden, c)
loss += criterion(hidden, label)
_, idx = hidden.max(dim=1)#从第一个维度上取出预测概率最大的值和该值所在序号
print(idx2char[idx.item()], end='')#按上面序号输出相应字母字符
loss.backward(retain_graph=True)#运行时报错,错误提示是下面这段话,根据提示修改参数就可以了。retain_graph=True
'''Trying to backward through the graph a second time,
but the saved intermediate results have already been freed.
Specify retain_graph=True when calling backward the first time.'''
optimizer.step()
print(', Epoch [%d/100] loss=%.4f' %(epoch+1, loss.item()))
下面是运行两个训练函数的代码。
train()
print('--------------------------------------------------------')
emb_train()
在25次得到正确输出。