JMeter的基本使用
元件的基本介绍:
元件:多个类似功能组件的容器(类似于类)。
常见的元件类型有:
- 取样器
- 逻辑控制器
- 前置处理器
- 后置处理器
- 断言
- 定时器
- 测试片段
- 配置元件
- 监听器 组件:实现独立的某个功能(类似于方法)
元件作用域:
1.取样器:元件不和其他元件相互作用,因此不存在作用域的问题;
2.逻辑控制器:元件只对其子节点中的取样器和逻辑控制器作用;
3.其他六大元件:除取样器和逻辑控制器元件外,如果是某个取样器的子节点,则该元件对其父子节点起作用;
4.如果其父节点不是取样器,则其作用域是该元件父节点下的其他所有后代节点(包括子节点,子节点的子节点等);
如下图所示:
- 元件执行顺序为
1.配置元件(config elements)
2.前置处理程序(Per-processors)
3.定时器(timers)
4.取样器(Sampler)
5.后置处理程序(Post-processors)
6.断言(Assertions)
7.监听器(Listeners)
JMeter参数化常用方式:
1.用户定义的变量:针对单用户或所有用户使用同一变量,类似postman内的全局变量
添加方式一:测试计划 --> 线程组–> 配置元件 --> 用户定义的变量
添加方式二:点击测试计划—>直接配置用户变量
比如配置好的用户变量为下图:
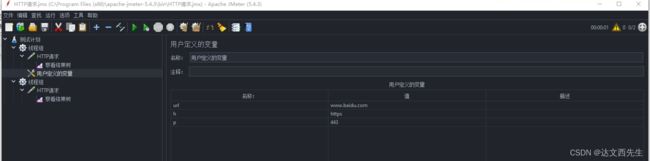
那么这边只需要在HTTP请求内引用就可以了,引用方式为${参数名称},如${url},具体例子请看下图:
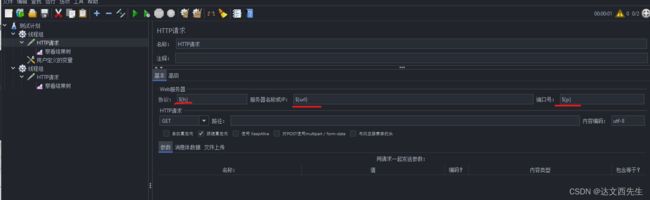
结果为:
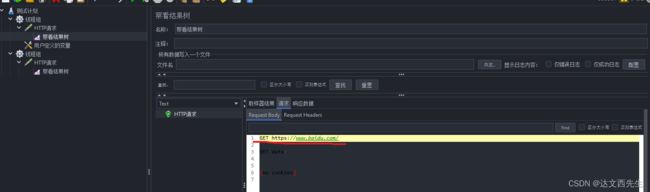
2.用户参数:针对不同用户使用不同变量,类似postman内的环境变量
添加方式:测试计划 --> 线程组–> 前置处理器 --> 用户参数
比如配置不同用户访问的网址不一样,用户1访问百度,用户2访问京东
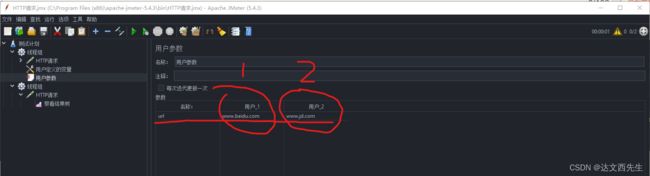
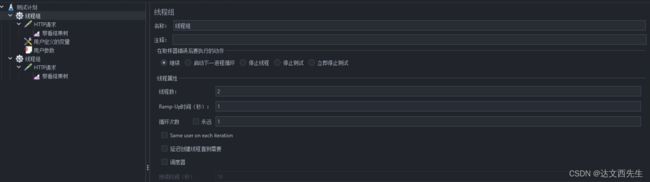
线程数配置为2,注意若是线程数为1那么就算循环次数为7也是一直引用用户1的参数
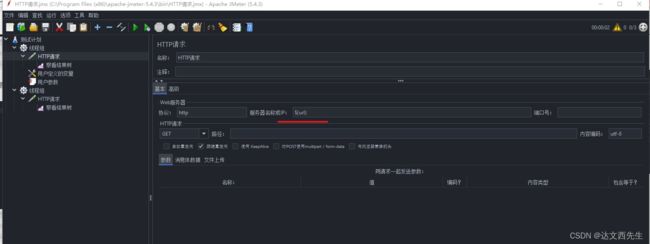
引用方式还是与之前的引用为${参数名称},如${url},具体例子请看下图:
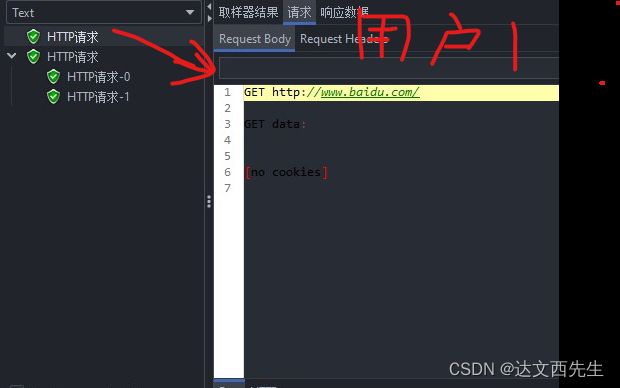
用户1返回结果
用户2返回结果
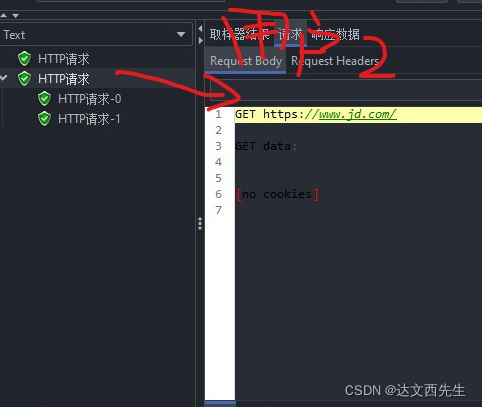
以上可以看见2个线程的返回结果是不一样的
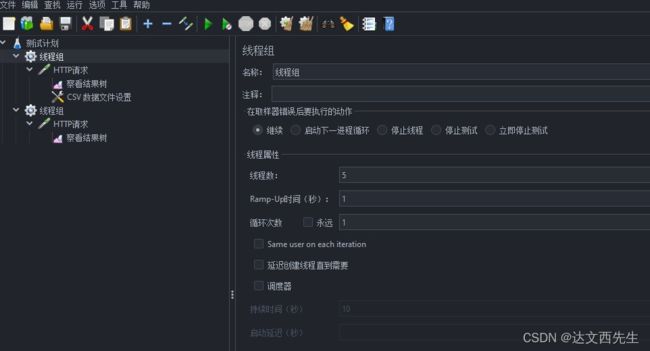
3.CSV数据文件设置:适用单用户、多用户多参数的使用,比如单线程每次请求的参数都不一样
添加方式:测试计划 --> 线程组–> 配置元件 --> CSV 数据文件设置
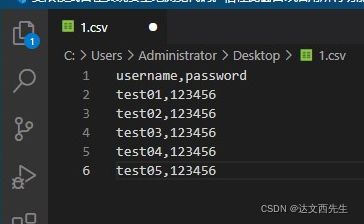
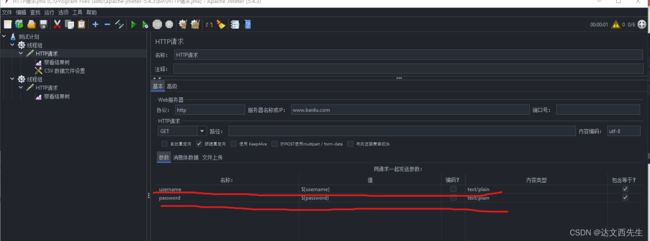
配置csv文件,右键txt文本然后修改后缀为csv即可,比如我想每次请求接口username与password这个参数都要有变化,那么我们可以如下图设置:
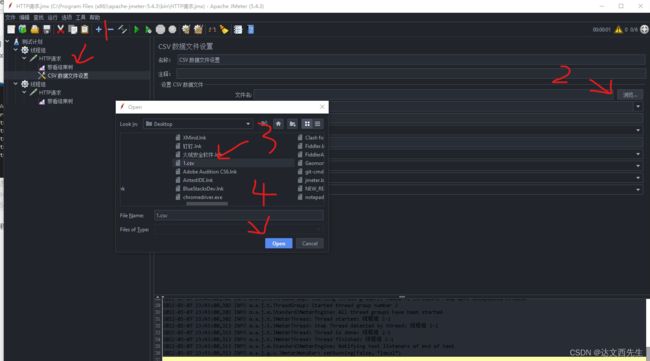
然后测试计划 --> 线程组–> 配置元件 --> CSV 数据文件设置–>浏览文件,选中我们创建好的csv文件即可,如下图:
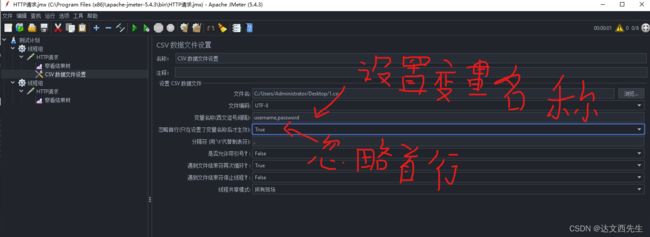
然后需要填写变量名称,因为我们设置了2个变量所以填写username,password(注意多个变量需要用逗号分隔,且变量名称不一定要与csv内的名称一样,也可以设置U和P,只要引用时引用${U}或${P}即可),然后又因为我们第一行的数据并不是要引用的参数所以需要将忽略首行设置为True,如下图:
线程数配置为5,注意与用户参数不一样,若是线程数为1,循环次数为7也是依次引用,而线程为7,循环1次也是依次引用,如下图
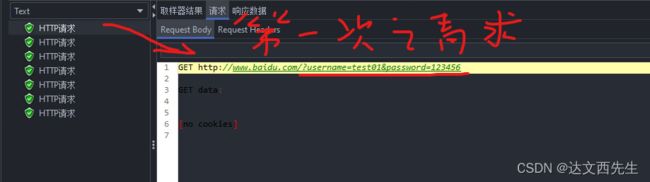
引用方式还是与之前的引用为${参数名称},如${url},具体例子请看下图:
请求1返回结果:
请求2返回结果:
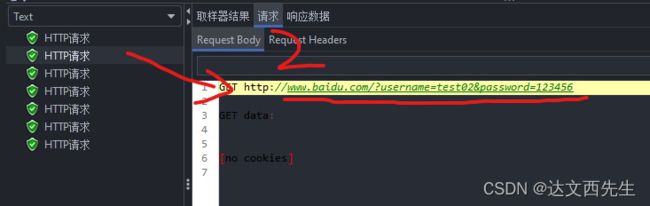
以上可以看见不同个线程的返回结果是不一样的
CSV参数详解:
- 文件名:CSV文件路径
- 文件编码:文件编译字符编码,一般设置UTF-8
- 变量名称:多个变量时,使用英文逗号分隔
- 忽略首行:True为忽略,False为不忽略,默认值:False
- 分隔符:如文件中使用的是逗号分隔,则填写逗号;如使用的是制表符,则填写\t;
- 是否允许带引号: CSV文件中的内容是否允许带引号
- 遇到文件结束符再次循环:当读取文件到结尾时,是否再从头读取文件,False=当读取文件到结尾时,停止读取文件
- 遇到文件结束符停止线程:当“遇到文件结束符再次循环”一项为False时起效;True:当读取文件到结尾时,停止进程
- 线程共享模式:共享模式一般默认即可
- 所有线程:该文件在所有线程之间共享,所有线程循环取值,线程一取第一行,线程二取下一行
- 当前线程组:各个线程组分别循环取值
- 当前线程:每个文件分别为每个线程打开
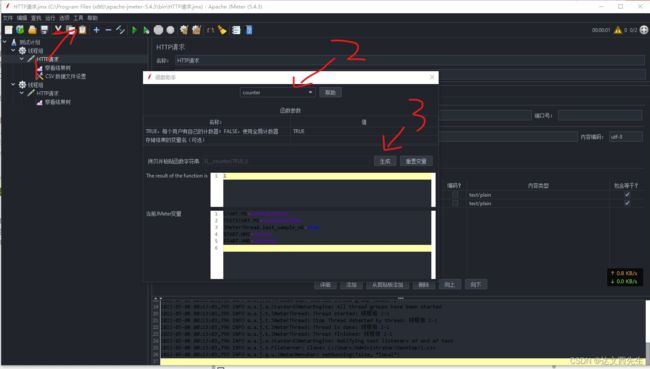
4.函数(counter):计数函数,一般做执行次数统计使用,主要适用与不在乎参数的内容,只要求每次请求的参数内容不一致
位置:在菜单中选择–> 工具 --> 函数助手对话框
从函数下拉列表中选择counter,然后填写参数,我这里填写的是TRUE,然每个不同的线程都用自己的计数器,然后点击生成(注意这里点击生成后是自动复制的)如下图:
然后在HTTP请求内引用然后如下图:
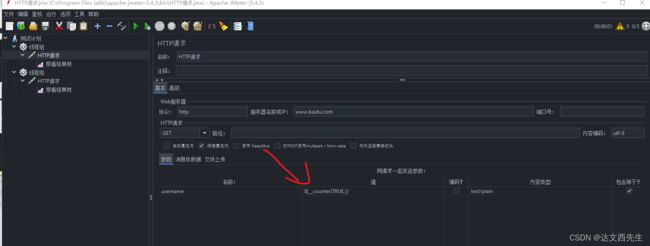
线程数配置为5,然后点击运行如下图
用户1第一次请求结果:
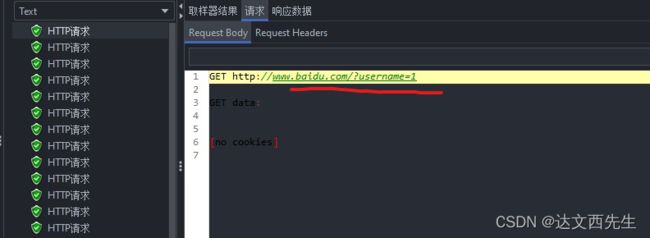
用户1第二次请求结果:
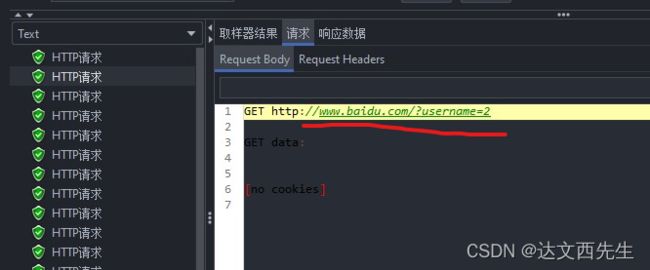
最后关于CSV和用户定义的变量作用域问题
CSV的作用域是针对线程的,只有两种情况:
- 对所有线程组中的线程生效
- 父节点是测试计划,并且线程共享模式是“所有线程”时,
- 对所有线程组中的线程生效 对当前线程组中的线程生效
- 父节点是某个线程组时,只会对当前线程组生效
- 用户定义的变量作用域针对的是测试计划
- 无论用户定义的变量组件放在哪里,他都会针对整个测试计划生效
JMeter断言
响应断言
添加方式:测试计划 --> 线程组–> HTTP请求 --> (右键添加) 断言 --> 响应断言
Apply to:适用范围
Main sample and sub-samples: 作用于父节点取样器及对应子节点取样器;
Main sample only: 仅作用于父节点取样器;
Sub-samples only: 仅作用于子节点取样器;
JMeter Variable: 作用于jmeter变量(输入框内可输入jmeter的变量名称);
状态码
-
响应文本:响应的body
-
响应代码:响应的状态码
-
响应信息:响应状态码对应的信息,也就是Response message的值,直白的说就是状态码后面的信息,比如状态码200的信息一般是OK,状态码302的信息一般是Moved Temporarily,如下图
-
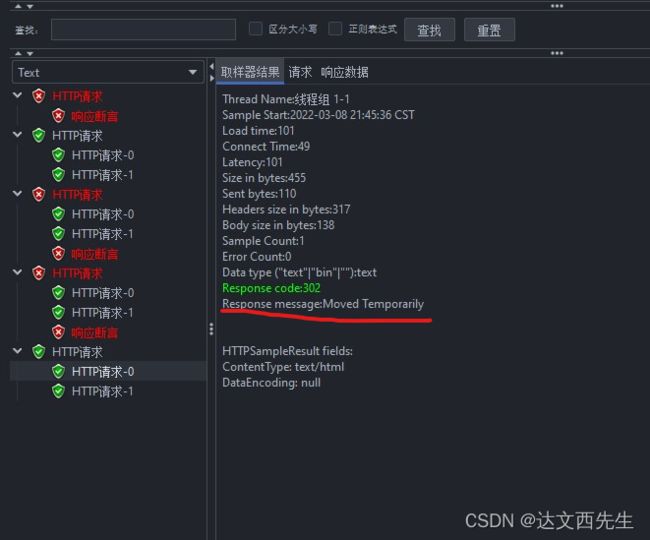
-
响应头:响应header
-
请求头:请求header
-
url样本:请求的url
-
文档:响应的文本模式
-
忽略状态:勾选后如果收到404或503等状态码后不主动判断消息发送失败
-
请求数据:请求数据也就是请求body
模式匹配规则
- 包括:文本包含指定的正则表达式
- 匹配:整个文本匹配指定的正则表达式
- 相等:整个返回结果的文本等于指定的字符串(区分大小写)
- 字符串:返回结果的文本包含指定字符串(区分大小写)
- 否:取反 ,比如我想要返回的结果内不包含
百度2字,那么我需要在测试模式内添加百度2字,然后勾选否 - 或者:如果存在多个测试模式,勾选代表逻辑或(只要有一个模式匹配,则断言就是OK),不勾选代表逻辑与(所有都必 须匹配,断言才是OK)比如下图我生成了2个模式,那么我勾选了或者的话,只要响应数据有地图,或www.baidu.com那么就算断言成功 如下图:
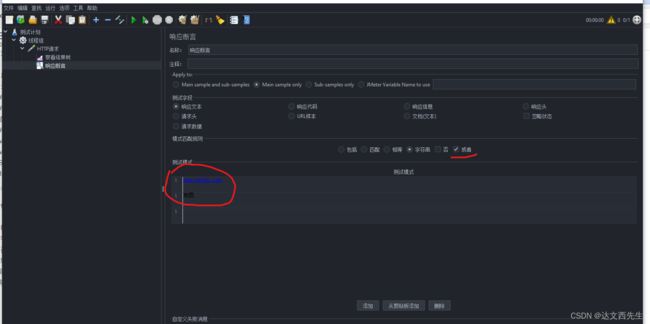
注意:这里我勾选响应文本后添加了地图的响应断言,那么我再点击响应代码那么下方测试模式内的地图就代表着断言状态码为地图
JSON断言
-
添加方式: 测试计划 --> 线程组–> HTTP请求 --> (右键添加) 断言 --> JSON断言
-
**JSON Paht语法:**http://www.noobyard.com/article/p-cyevemcy-nq.html
-
使用方式: 添加JSON断言,然后填写参数与校验的参数值,参数格式为
$.参数1.参数2
,比如我调用接口应该返回{"test":1,"msg":"测试大小"},而我想校验参数test是否是1,那么我们可以如下图操作,如图:
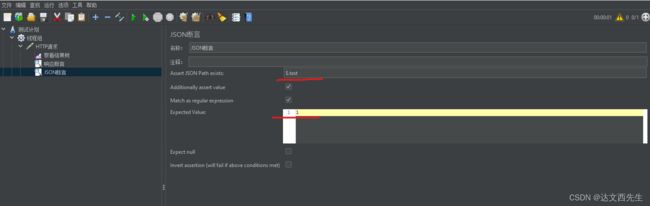
-
详细参数解释:
- Assert JSON Path exists:用于断言的JSON元素的路径
- Additionally assert value:如果您想要用某个值生成断言,请选择复选框
- Match as regular expression:如果需要使用正则表达式,请选择复选框
- Expected Value:期望值,用于断言的值或用于匹配的正则表达式的值
- Expect null:如果希望为空,请选择复选框
- Invert assertion (will fail if above conditions met):反转断言(如果满足以上条件则失败)
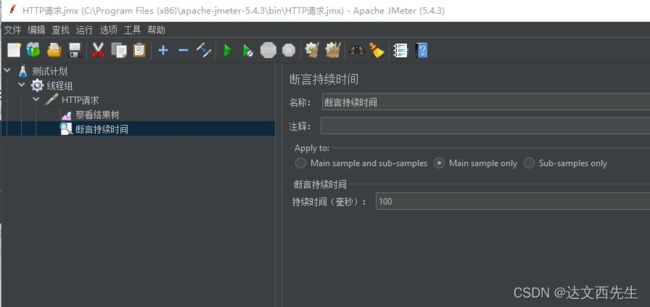
断言持续时间:对响应时间进行断言
- 添加方式: 测试计划 --> 线程组–> HTTP请求 --> (右键添加) 断言 --> 断言持续时间
- 使用方式: 比如要测试返回百度的响应时间是否大于100毫秒,那么我们在断言持续时间内填写100即可,如下图:
然后点击运行,我们看看响应响应时间是否达标,如下图:
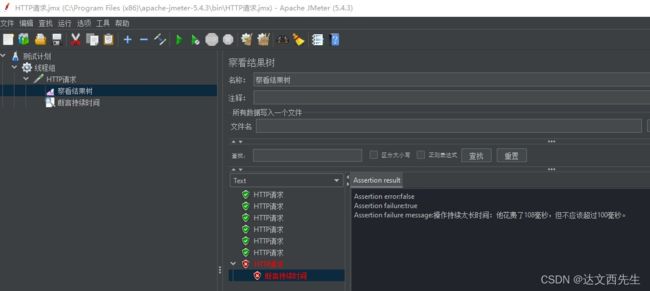
上图我们可以看见,响应时间为108毫秒,没有达到长100毫秒的断言,所以断言失败。
JMeter请求数据的相互引用
正则表达式提取器
一般与用户自定义的变量或者正则表达式提取器配合使用,循环读取用户自定义变量或者正则表达式结果中所有数据
- 添加方式: 测试计划 --> 线程组–> HTTP请求 --> (右键添加) 后置处理器 --> 正则表达式提取器
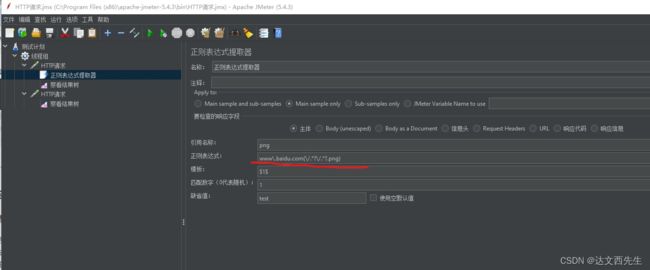
- 使用方式: 先添加正则表达式提取器,然后填写引用名称比如png,然后填写正则表达式,注意从响应结果中要提取的数据内容需要加括号才能提取,比如提取baidu,那么使用
www.().com进行提取,当正则表达是中有多个括号时(多个提取的正则表达式),比如(\d\d\d)-(\d\d\d)-(\d\d\d\d),那么使用模板$提取结果的序列位置$(从1开始),比如提取第2个正则表达式能匹配的值,那么使用$2$即可,而正则表达式的值也可能有多个,那么我们使用匹配数值来选择,比如(\d\d\d)匹配到了 123,456,789那么我们使用匹配数值填写1则可以提取123,注意:匹配随机数值填写1,匹配所有数值并用列表的方式返回填写-1(引用时需要用应用名称_列表索引值的方式引用比如png_1)
,假如正则表达式没有取到值,而我们又想使用默认值式,我们可以在缺省值内填写默认值,比如填写www.baidu.com,假如正则没有获取到值会使用默认值www.baidu.com - 使用例子:比如我需要调用2个接口,我先从从第一个接口获取到图片链接,然后在第二个接口发送,先设置正则表达式提取链接如下图:
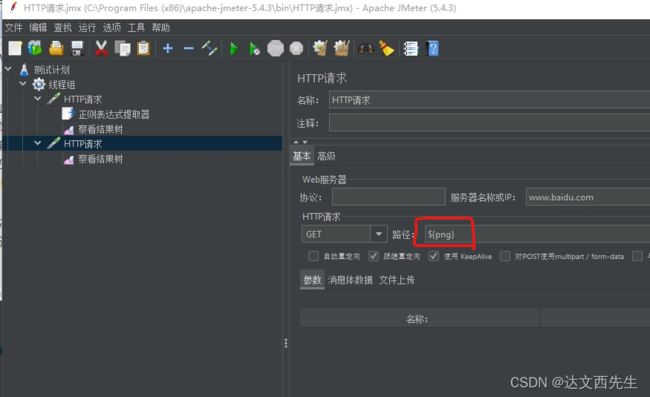
然后在第二个HTTP请求中引用,引用参数方式与之前一致${png}如下图:
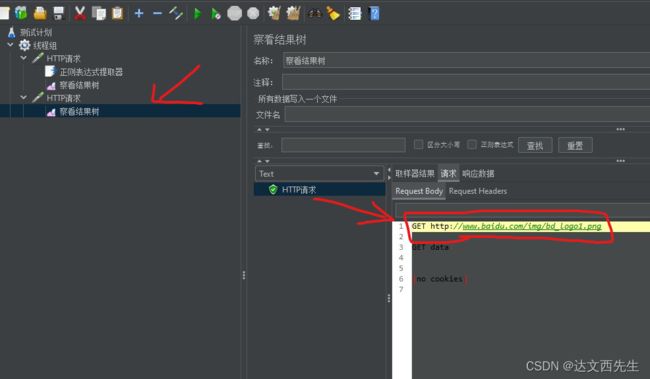
然后运行查看结果,我们会发现第二个接口引用的从第一个接口获取到的参数值,如下图:
XPath提取器:用于提取返回为html格式使用
- 添加方式: 测试计划 --> 线程组–> HTTP请求 --> (右键添加) 后置处理器 --> XPath提取器
参数设置(XPath提取器)
- Use Tidy (tolerant parser):如果勾选此项,则使用Tidy将HTML响应解析为XHTML。当需要处理的页面是HTML格式时,必 须选中该选项,当需要处理的页面是XML或XHTML格式(例如,RSS返回)时,取消选中该选项。
- 引用名称:存放提取出的值的参数
- XPath Query:用于提取值的XPath表达式
- 匹配数字:如果XPath路径查询导致许多结果,则可以选择提取哪个作为变量
- 0:表示随机
- 1:表示提取所有结果(默认值),它们将被命名为<变量名>_N(其中N从1到结果的个数)
- X:表示提取第X个结果。如果这个x大于匹配项的数量,则不返回任何内容。将使用默认值
- 缺省值:参数的默认值
- 使用方式: 比如请求百度,我要提取百度首页的图片那么添加XPath提取器,然后勾选UseTidy(注意必须勾选,否则不会解析html文件格式),填写引用变量PNG,填写XP路径,填写匹配数值为-1,如下图:
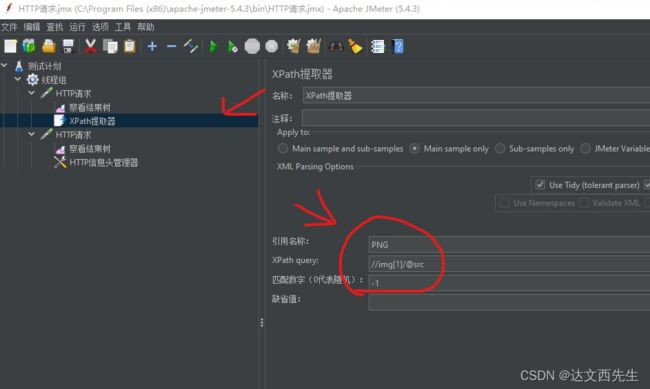
然后在第二个HTTP请求引用${PNG}如下图:
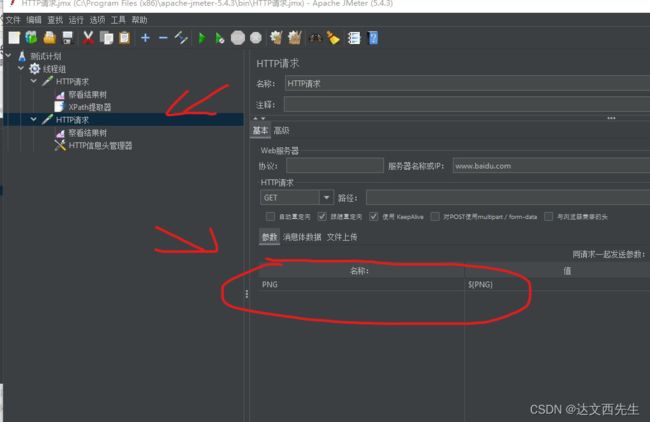
然后运行,最后我们查看结果,发现提取的数据被正常引用了。如下图:
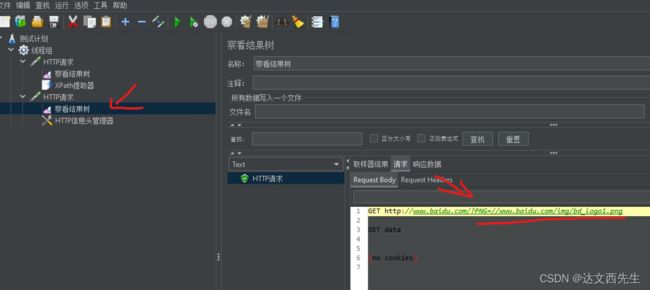
JSON提取器:适用于提取返回结果为json格式的数据
- 添加方式: 测试计划 --> 线程组–> HTTP请求 --> (右键添加) 后置处理器 --> JSON提取器
- 参数设置:
- Names of created variables:存放提取出的值的参数
- JSON Path Expressions:JSON路径表达式
- Match No:提取第几个数据(一般不会填写)
- Defaulf Values:缺省值,假如没有提取到数据则使用默认值
- 使用方式:
添加json提取器,填写变量名,然后填写json路径表达式,如下图:
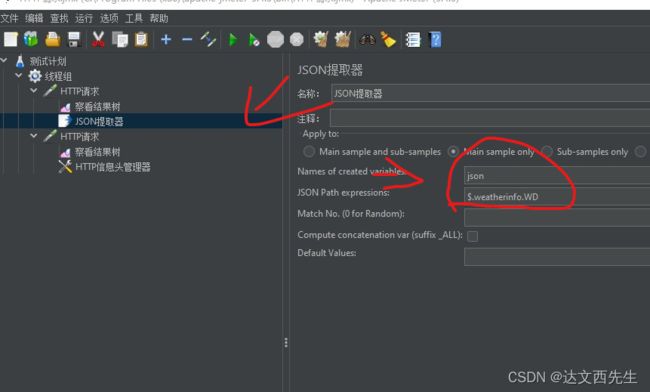
然后在第二个HTTP请求内引用参数如下图:
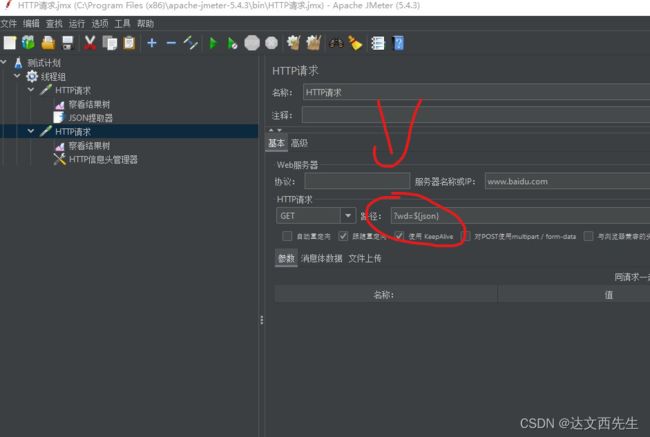
最后运行,最后我们查看结果,发现提取的数据被正常引用了,如下图:
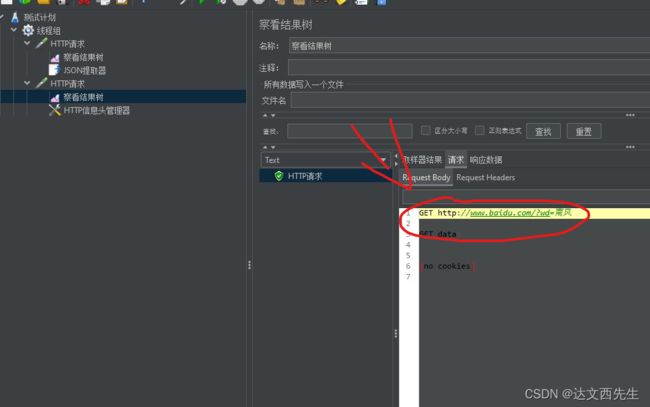
跨线程组关联(BeanShell提取器):适用于不同线程组之间的数据传递
-
**函数实现: **
- __setProperty函数:将值保存成jmeter属性
- __property函数:在其他线程组中使用property函数读取属性
-
使用方式:
-
比如在1线程组的HTTP请求使用json提取器提取数据,然后在2线程组的HTTP请求内引用,那么先添加json提取器,填写变量名然后填写json路径表达式,如下图:
-
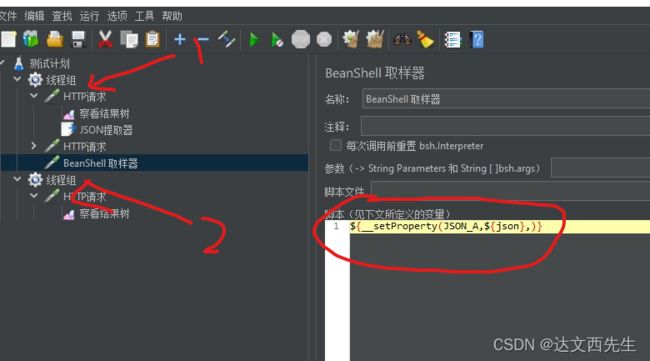
然后添加BeanShell提取器,添加json数据的值,格式为${__setProperty(自定义变量名,${被引用的变量名},)},比如${__setProperty(JSON_A,${json},)},这段的意思是引用json的变量,并且命名为JSON_A,如下图:
-
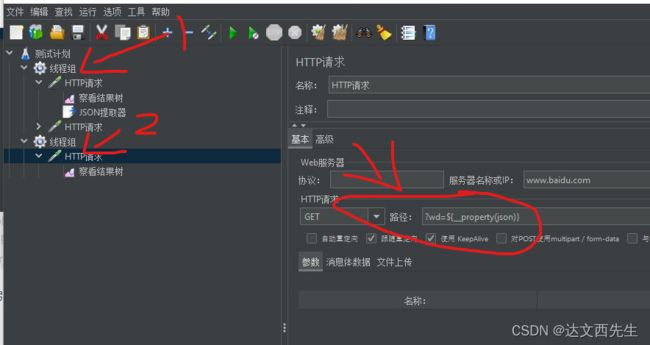
然后在2线程组引用,不一样的是引用方式改变了,格式为
${__property(BeanShell提取器内变量名,,)},比如使用${__property(JSON_A,,)}的方式来进行引用,如下图:
最后运行,最后我们查看结果,发现不同线程组提取的数据被正常引用了,如下图:
JMeter脚本的录制
添加方式: 在jmeter当中添加HTTP代理服务器:测试计划(右键)->非测试元件->HTTP代理服务器
1.添加线程组,用于存放录制的脚本
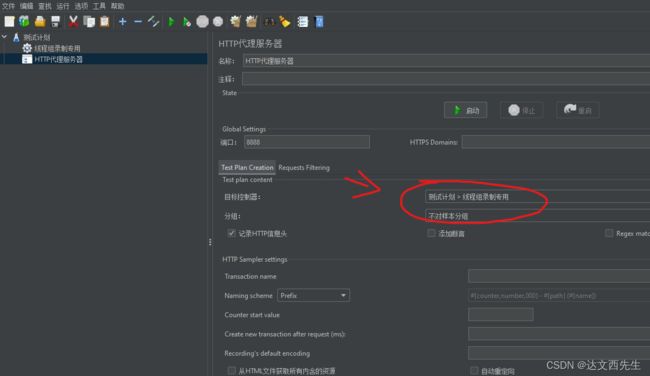
2…在jmeter当中添加非测试元件HTTP代理服务器,设置端口为8888,在目标控制器里面选择存放脚本的线程组,如下图:
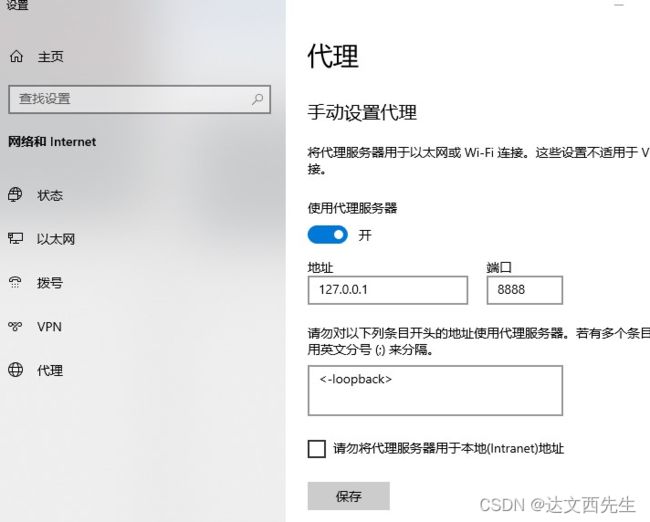
3.然后配置本地代理ip为127.0.0.1,端口号为8888,注意假如要获取本地架设的web或接口服务器,那么需要在代理服务器列表内填写<-loopback>,如下图
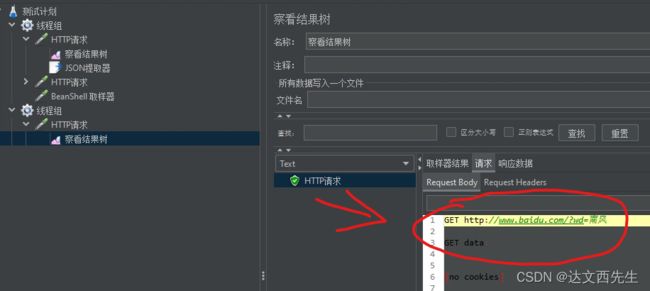
4.然后点击启动,然后打开浏览器访问百度,访问完成后点击停止录制,然后我们会发现线程组内自动添加了HTTP请求,这些请求都是我们访问百度的请求如下图:
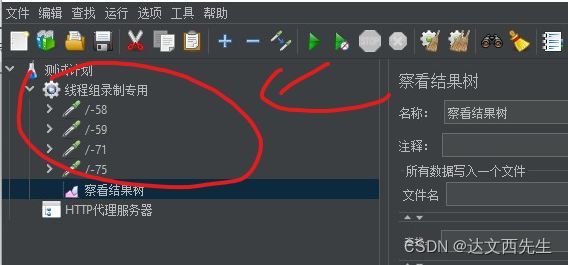
5.然后我们可以直接启动线程组,线程组会请求我们之前录制的请求如下图:
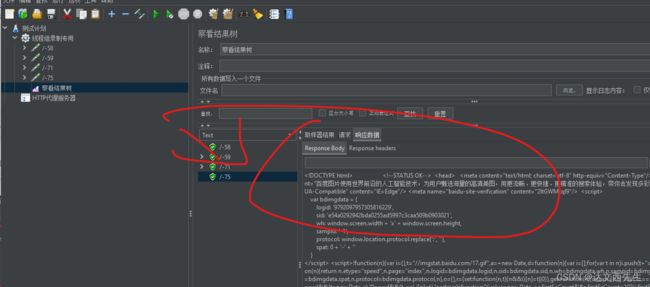
JMeter脚本录制的过滤:
位置:HTTP代理服务器–》Requests Filtering
- Requests Filtering:
- 包含模式:url匹配正则表达式,包含此项 如:只抓取百度域名下的请求
.*www\.baidu\.com.*或者只抓取京东域名下的请求.*www\.jd\.com.* - 排除模式:url匹配正则表达式,不包含此项 如:不抓取png图片地址
.*png或者不抓取js文件.*js
如下图:
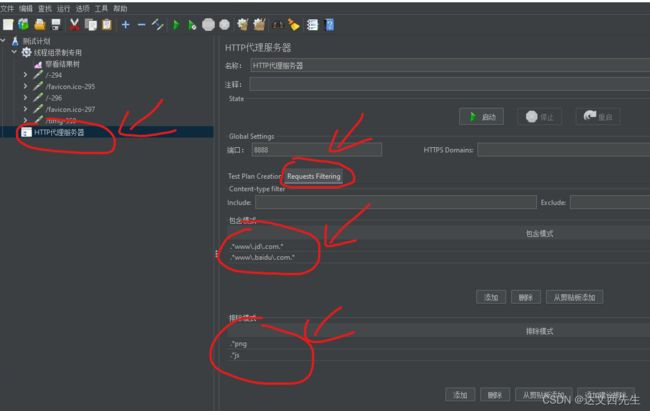
- 包含模式:url匹配正则表达式,包含此项 如:只抓取百度域名下的请求
JMeter的HTTPCookie管理器:
- HTTP Cookie管理器: 假如使用录制的脚本的话会自动将Cookie添加到请求中,类似于python内的requests.Session 函数,用于保存Cookie,使后面的请求自动携带Cookie,或者可以自己手动添加Cookie。
- 添加方式: 测试计划(右键)->配置元件->HTTP Cookie
- 使用方式: 比如以登录的状态进入csdn会员购买界面,先获取Cookie,然后在HTTP Cookie管理器内添加,并设置名称,然后配置使用Cookie的域名
mall.csdn.net(因为访问的是mall.csdn.net会员购买界面所以配置这个域名),如下图: 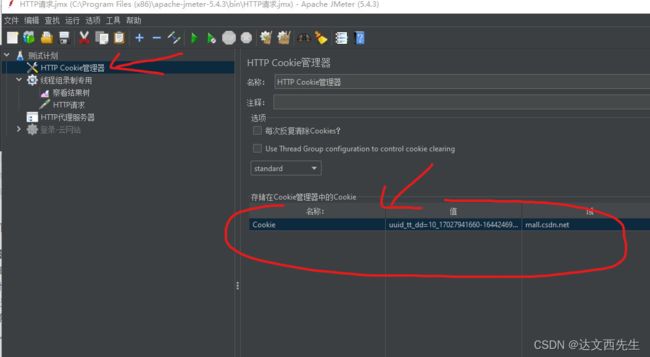
然后运行,查看返回结果是否包含达文西先生,也就是在下,如图:
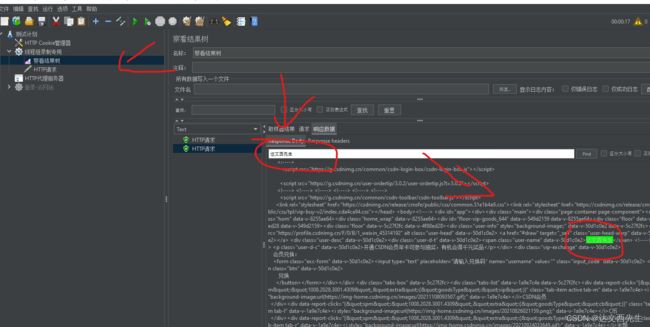
可以看见返回的body是包含达文西先生这个字符串的,也就是说Cookie使用成功。
JMeter连接数据库
准备工作:
1.最新版本的JMeter是默认不展示插件管理器的,所以我们需要手动添加插件管理器
2.下载地址:https://jmeter-plugins.org/install/Install/,下载插件plugins-manager.jar,然后将jar包放在apache-jmeter-x.x.x\lib\ext路径下,重新打开jmeter客户端即可在“选项”下面可以看到了Plugins-Manager这个插件了。
3.然后添加JDBC插件即可,我这里是已经安装了,如下图(注:驱动包的版本必定不能大于数据库的版本,好比数据库版本是5.1.0,驱动包版本必须是5.1.0或如下版本)
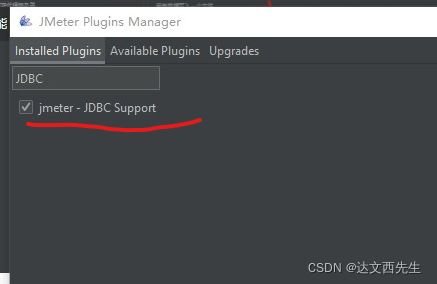
配置数据库连接信息:
- 添加方式: 测试计划 --> 线程组–> (右键添加) 配置元件 --> JDBC Connection Configuration
- 主要参数:
- Variable Name: mysql数据库连接池名称(JDBC请求时要引用)
- Database URL: jdbc:mysql://localhost:3306/tpshop2.0 jdbc:mysql:(MySQL固定格式) //127.0.0.1:(数据库ip地址) 3306:(MySQL默认端口,如改变,请如实填写) books:要连接的数据库名称
- JDBC DRIVER class: com.mysql.jdbc.Driver(MySQL驱动包位置固定格式)
- Username: root(连接数据库用户名,如实填写)
- Password:(MySQL数据库密码,如实填写,如果密码为空不写)
- 如图下图:我们配设置号好数据库的名称之后,填写连接与要连接的数据库,然后填写账号与密码即可
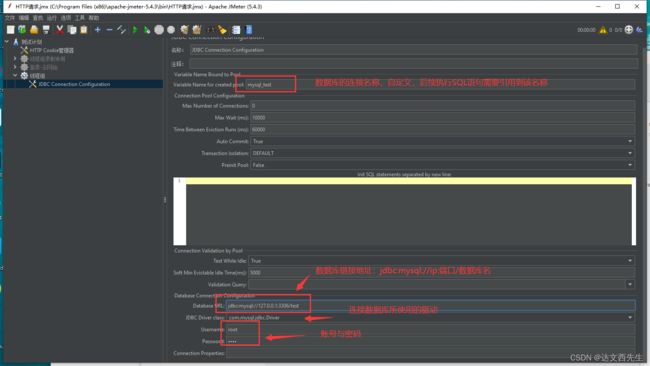
查询数据库:
- 添加方式: 测试计划 --> 线程组–> (右键添加) 配置元件 --> DBC request(注意需要在当前线程组下以配置好数据库信息JDBC Connection Configuration元件)
- 主要参数:
- Variable Name:数据库连接池的名字,需要与JDBC Connection Configuration的Variable Name Bound Pool名字保持一致
- Query Type:语句执行的方式
- Query:填写的sql语句未尾不要加“;”
- Parameter values:参数值
- Parameter types:参数类型
- Variable names:保存sql语句返回结果的变量名
- Result variable name:创建一个对象变量,保存所有返回的结果
- Query timeout:查询超时时间
- Handle result set:定义如何处理由callable statements语句返回的结果
- 使用方式:
我们需填写数据库连接名称,然后选择要执行的语句,比如查询就在Query Type选择 select staatement,然后数据查询语句,并填写要引用查询结果的变量名称( Variable names)如下图:
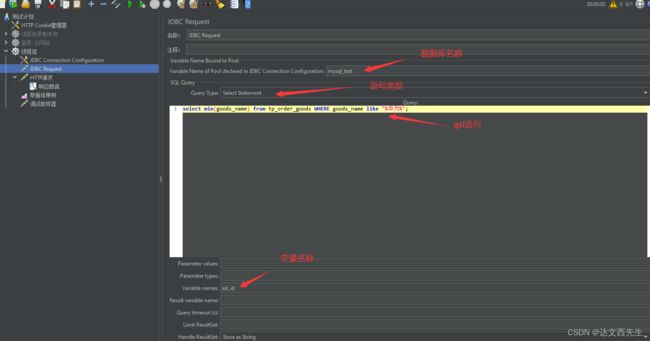
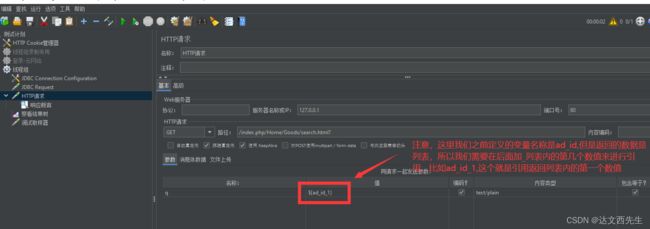
然后我们应用变量,注意 引用变量需要在变量名后面加_变量位置,比如我们之前定义的sql查询结果变量名为ad_id,那么我们要引用第一条数据则需要ad_id_1这样引用,因为sql查询返回的结果是列表形式,所以我们需要在变量名后面加上数字,来告诉程序需要第几个变量值,就如下图():
JMeter控制器:
如果(if)控制器:
if控制器用来控制它下面的测试元素是否运行
- 添加方式: 测试计划 --> 线程组–> (右键添加) 逻辑控制器 --> 如果(If)控制器
- 参数解读:
- Interpret Condition as Variable Expression?:
- 勾选:则需要用
${__jexl3("${变量}"=="变量",)}的方式来进行编写脚本 - 不勾选:直接使用
"${变量}"=="变量"的方式来进行编写脚本
- 勾选:则需要用
- 使用方式:
比如我这里通过用户变量apitest的值来进行判断(默认值为jd),假如apitest是jd就访问京东,假如是baidu就访问百度
那么我们可以如下图设置(百度也同理):
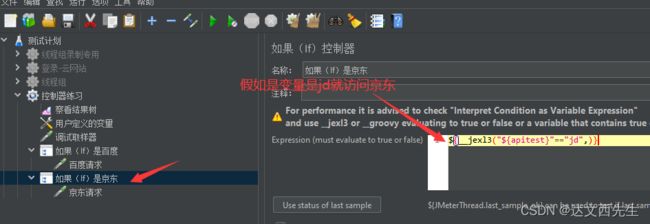
- 注意,http请求需要放在逻辑处理器的下面,这里
Interpret Condition as Variable Expression是默认勾选的,所以语句为${__jexl3("${变量}"=="变量",)},这里使用的是js的语句也可以这样使用,如:- 判断2个变量,只要有一个符合就继续执行
${__jexl3(${VAR}==1 || ${name} != "ha",)} - 判断2个变量,只要全部符合就继续执行
${__jexl3(${VAR}==1 && ${name} != "ha",)}
运行结果如下图:
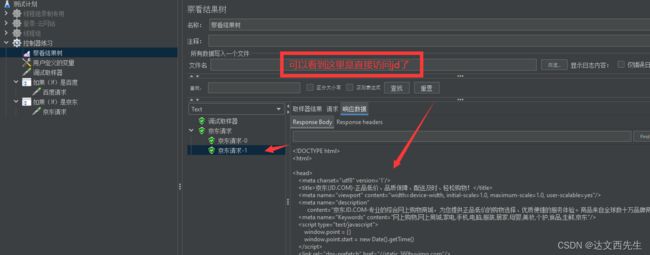
- 判断2个变量,只要有一个符合就继续执行
循环控制器:
- 添加方式: 测试计划 --> 线程组–> (右键添加) 逻辑控制器 --> 循环控制器
- 使用方式:
- http请求访问百度10次,如下图:
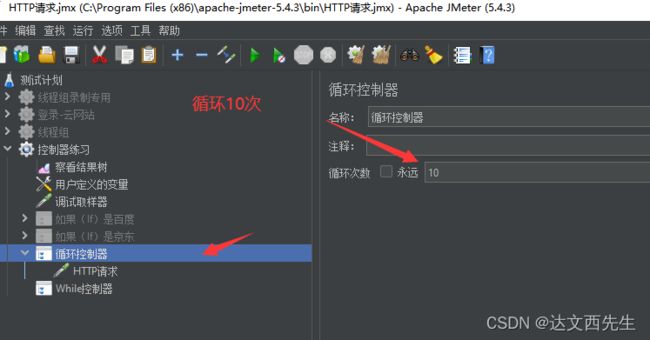
- 注意: 线程组属性控制组内所有取样器的执行次数,而循环控制器可以控制组内部分取样器的循环次数,后者控制精度更高
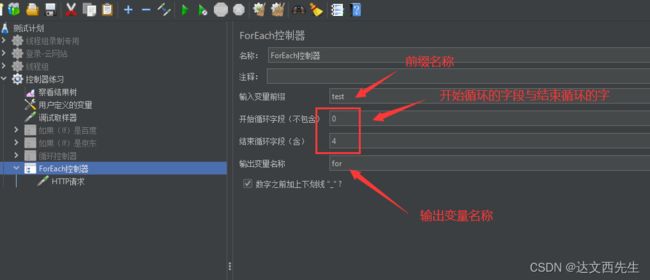
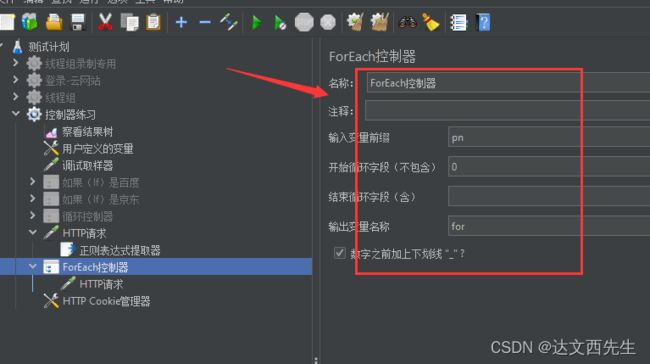
ForEach控制器:
- 添加方式: 测试计划 --> 线程组–> (右键添加) 逻辑控制器 --> ForEach控制器
- 使用方式:
在用户变量内添加test_数字形式的变量,然后使用for控制器依次引用并访问http请求,用户变量如下图设置:
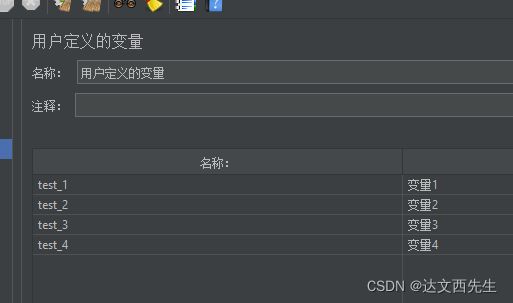
然后我们在ForEach控制器内设置好变量前缀和输出变量名还有循环字段即可注意,要是不填写结束循环则会遍历所有数据,如下图设置:
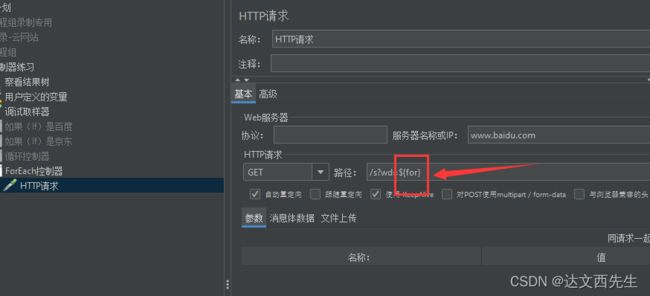
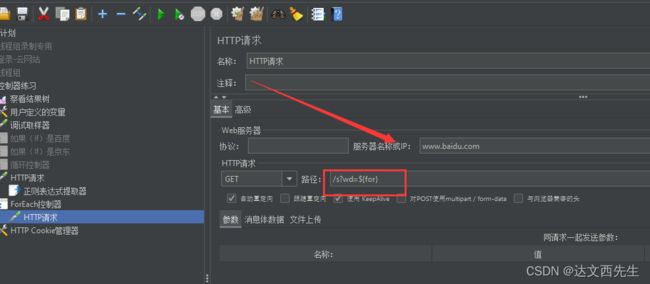
然后在http内应用${for},如下图设置:
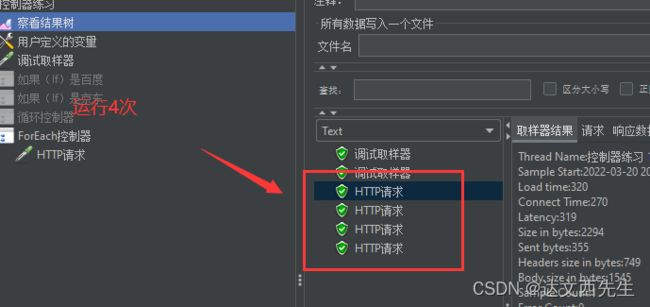
然后我们运行看看结果:
-
案例练习:
- 案例完成条件:
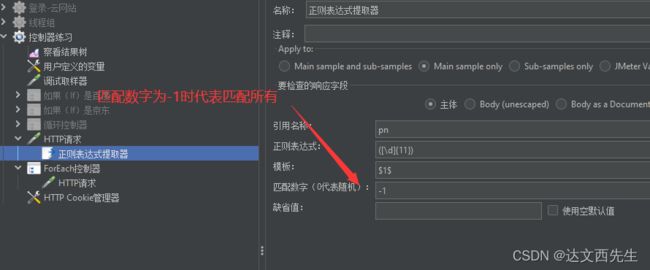
在http://so.qqdna.com/使用正则提取所有手机号,并使用ForEach控制器在百度上依次搜索提取到的手机号 - 1.访问网站提取手机号:
我们先添加so.qqdna.com的请求,然后在该请求上添加正则提取器,这里要注意的时匹配数字我们填写-1,-1代表匹配所有并以列表形式返回,且后续引用变量时需要变量_索引值的方式来获取,比如pn_1,如下图设置:
- 2.设置ForEach控制器
然后我们设置ForEach控制器,变量前缀为pn,结束循环字段不填写(为了遍历所有数据),输出变量为for,并勾选数字之前加上下划线如下图设置:
- 案例完成条件:
-
最后我们在ForEach控制器内添加http请求,请求百度,每次搜索手机号,如下图设置:
-
3.运行查看结果
最后我们运行,查看结果
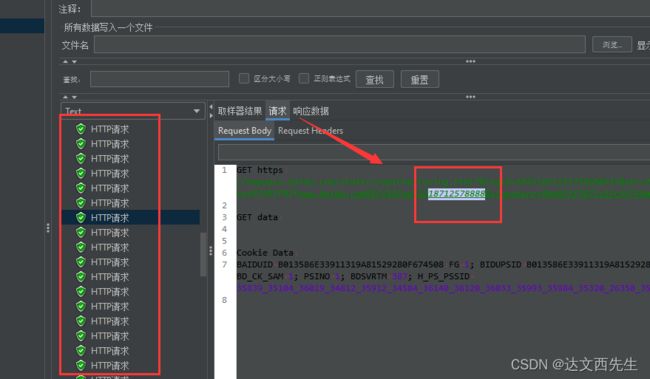
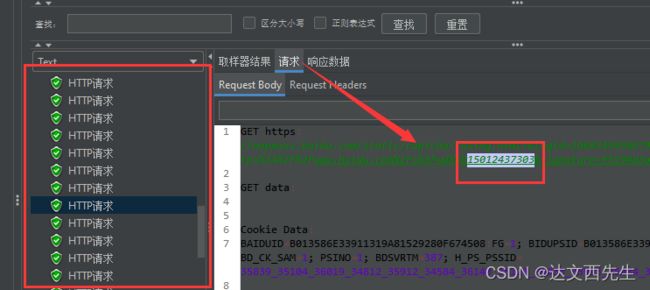
可以看到每次请求都是不同的手机号。
事务控制器:
- 添加方式: 测试计划 --> 线程组–> (右键添加) 逻辑控制器 --> 事务控制器
- 使用方式:
- 添加完成事务控制器后,假如我们需要将多个http请求设置为一个事务我们只需要在当前事务控制器下方添加多个http请求即可,如图:
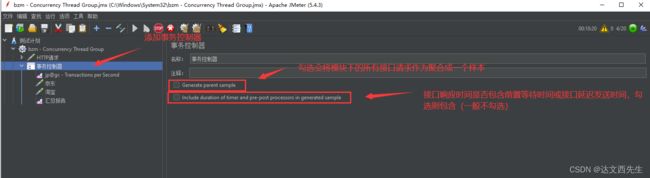
这里我们简单聊一下Generate Parent Sample与Include duration of timer and pre-post processors in generated sample这个2个参数勾选与不勾选产生的影响 - Generate Parent Sample: 假如勾选会将当前事务所有的请求聚合成一个样本,不勾选则将事务控制器做为单独一个样本,这里我们在当前事务控制器下设置2个http接口,并发10个线程,我们可以使用聚合报告比较很直观的看见,如图
-
不勾选

-
勾选

-
- Include duration… : 假如勾选会当前事务平均请求时间会加上前后置处理时间和定时器的时间,不勾选则不增加定时器之类的时间,这里我们在当前事务控制器下设置2个http接口,并发10个线程,每个线程延迟5秒,我们可以使用聚合报告比较很直观的看见,如图:
-
勾选

-
不勾选

通过上图我们可以知道,勾选之后事务平均值=所有接口平均请求值的总和+固定器定时器的时间
-
- 添加完成事务控制器后,假如我们需要将多个http请求设置为一个事务我们只需要在当前事务控制器下方添加多个http请求即可,如图:
JMeter定时器
同步定时器(Synchronizing Timer-集合点)
-
介绍: 目的是阻塞线程,直到阻塞n个线程,然后立即释放它们
-
添加方式: 测试计划 --> 线程组–> HTTP请求 --> (右键添加) 定时器 --> Synchronizing Timer
-
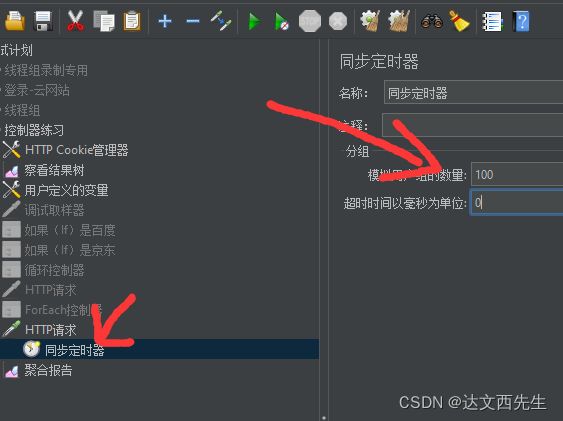
注意 超时时间为0时,模拟用户数量要比线程数少,且可以被整除,比如进程数为1000,那么模拟用户数可以为1000,或者500,如果不能满足以上条件就必须要设置超时时间,假如超过超时时间,同步定时器会立即释掉目前以阻塞的所有线程
-
比如我们需要并发到100,那么我们需要在同步定时器中设置模拟用户组为100,然后运行即可,如下图
-
有无同步定时器对比情况
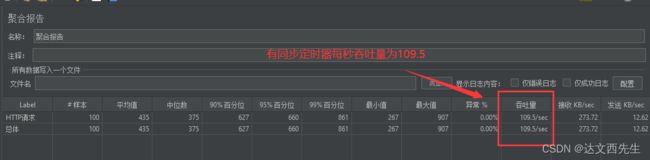
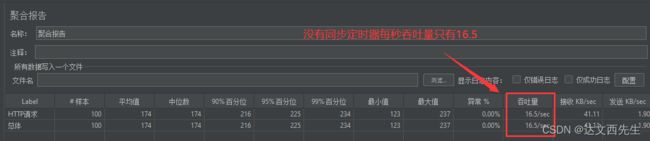
同步定时器中的的模拟用户数量实际有什么用处呢,我们可以用下面2张图看看有同步定时器和没有同步定时器的吞吐量的情况:
有同步定时器,吞吐量为109.5,如下图:
没有同步定时器,吞吐量只有16.5,如下图:
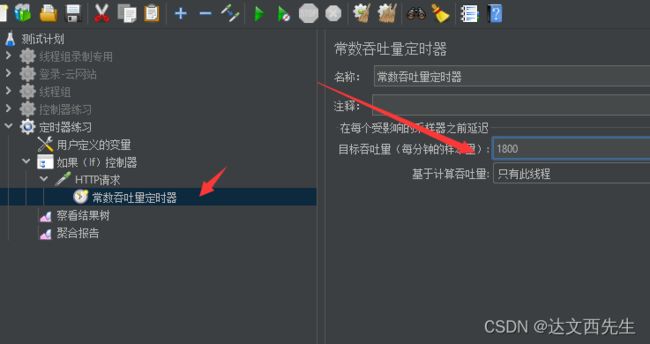
常数吞吐定时器(Constant Throughput Timer)
- 介绍: 常数吞吐量定时器可以让JMeter以指定数字的吞吐量(以每分钟的样本数为单位,而不是每秒)执行。 吞吐量计算的范围可以为 指定为当前线程、当前线程组、所有线程组,常用于稳定性测试。
- 添加方式: 测试计划 --> 线程组–> HTTP请求 --> (右键添加) 定时器 --> Constant Throughput Timer
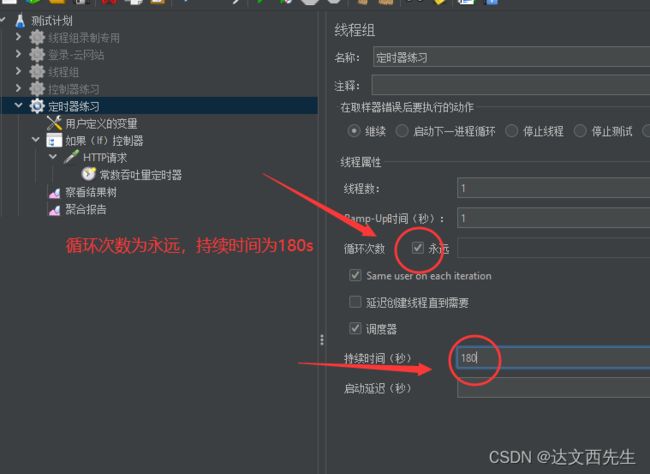
- 使用方式,比如我需要一个用户以30QPS的频率访问百度首页,持续3分钟,那么我们可以在常数吞吐定时器内设置每分钟样本量为(30*60=1800),线程组循环次数为永远,持续时间为180秒,如下图
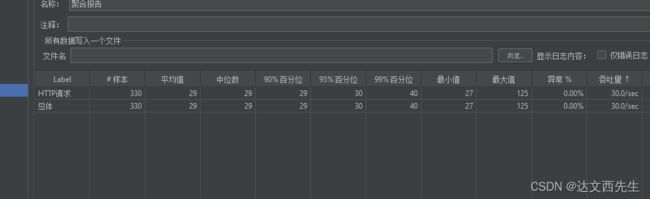
然后我们运行查看结果,可以看到,每秒吞吐量为qps30,如下图:
JMeter分布式测试
-
什么是分布式测试?
-在使用jmeter进行高并发测试时,单台电脑cpu可能无法达到如此高的并发,此时我们可以使用一台电脑作为控制机,在其他电脑上安装jmeter作为代理机,通过控制机发布的脚本发布到不同代理机上进行运行,这就是分布式 -
如何配置分布式并运行?
-
前提条件:
- 需要在同一区域网;
- 代理机防火墙都已关闭;
- 控制机与代理机的jmeter和jdk版本都要一致;
-
代理机配置:
- 1.关闭jmeter内的RMI SSL开关(进入jmeter/bin/jmeter.properties,修改
server.rmi.ssl.disable=true) - 2.启动jmeter/bin/下的jmeter-server.bat如下图:
- 1.关闭jmeter内的RMI SSL开关(进入jmeter/bin/jmeter.properties,修改
-
控制机配置:
- 1.关闭jmeter内的RMI SSL开关(进入jmeter/bin/jmeter.properties,修改
server.rmi.ssl.disable=true) - 2.添加代理机的ip(192.168.0.155),(进入jmeter/bin/jmeter.properties,添加
remote_hosts=127.0.0.1,192.168.0.155:1099)默认端口为1099 - 3.启动jmeter,然后配置并发脚本,比如我要测试50并发的情况下服务器是否正常,那么需要在线程组内配置50并发/代理机数量(1)=50,那么我们只需要配置50个线程即可,如下图:
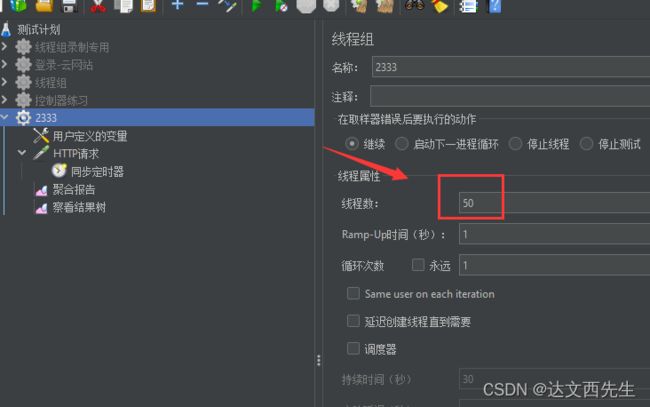
4.然后我们只要点击顶部运行选项——》远程启动所有,这时QPS为42.5,发送了50次请求,如下图:

- 1.关闭jmeter内的RMI SSL开关(进入jmeter/bin/jmeter.properties,修改
JMeter 报告指标解析
聚合报告:
- 参数介绍:
- Label :请求的接口名称
- 样本:请求接口的次数
- 平均值:平均请求的响应时间,以ms为单位
- 中位数:50%的请求数不超过的响应时间
- 90%百分位:90%的请求数不超过的响应时间
- 95%百分位:95%的请求数不超过的响应时间
- 99%百分位:99%的请求数不超过的响应时间
- 最小值:当前请求内最短的响应时间
- 最大值:当前请求内最长的响应时间
- 异常:请求的错误率,也就是所有请求内失败的百分比
- 吞吐量:每秒请求接口次数
- 接收kb/sec:每秒接受的网络传输速率(以kb为单位)
- 发送kb/sec:每秒发送的网络传输速率(以kb为单位)
- 案例:
- 我们分别请求百度和京东各50次,然后查看聚合报告进行分析

这里我们只看百度,可以看到样本为50也就是说我们请求了50次百度的网站,平均响应时间为197毫秒,有50%的请求没有超过192毫秒,有90%的请求没有超过259毫秒,有95%的请求没有超过272毫秒,有99%的请求没有超过291毫秒,最短的响应时间为134毫秒,最长的响应时间为291毫秒,异常为0.00%也就是说没有出现请求出错的情况,吞吐量为42也就是说平均每秒访问42次该接口,平均秒下载速率为104.91kb,平均上传速率4.84kb;
这里我们需要重点关注的性能指标有- 响应时间
- 平均响应时间(这里需要注意观察最大最小值的波动范围,如波动范围不大就以平均值为的响应时间为结果,如果波动较大,以90%或95%的响应时间作为结果)
- 错误率
- 吞吐量
- 响应时间
html性能测试报告:
这里我们需要先用命令行的方式来启动jmeter并生成测试报告
- 命令行方式启动jmeter
- 命令:
jmeter -n -t [jmx file] -l [result file] -e -o [html report folder] - 解析:
-n:非GUI模式执行JMeter
-t [jmx file]:测试计划保存的路径及.jmx文件名,路径可以是相对路径也可以是绝对路径
-l [result file]:保存生成测试结果的文件,jtl文件格式
-e:测试结束后,生成测试报告
-o [html report folder]:存放生成测试报告的路径,路径可以是相对路径也可以是绝对路径 - 示例
比如我们使用示例命令:jmeter -n -t hello.jmx -l result.jtl -e -o ./report,然后运行,可以看到如下图的结果就代表运行成功

此时我们进入生成报告的目录查看报告,如下图:
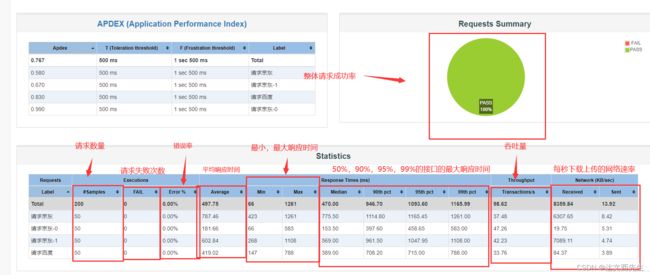
除了以上信息以外,在该页面左侧还有更为详细的吞吐量图表报告,响应时间图表报告等报告,这里就不一一介绍了。
- 命令: