【机器学习算法】序列模式的概念,Aprioriall算法和SrefixSpan算法
目录
序列模式
序列模型的概念
序列模型的评估指标
Aprioriall算法及实例说明
PrefixSpan算法及实例说明
序列模式的延伸(状态转移网络)
总结:
我的主页:晴天qt01的博客_CSDN博客-数据分析师领域博主
目前进度:第四部分【机器学习算法】
序列模式
序列模型的概念

我们必须知道顾客购买商品的先后顺序。
要了解交易时间和顾客id。在序列模式我们需要知道同一个顾客购买商品的先后顺序,而关联规则就只需要知道顾客id就可以了,序列模型是以顾客id为单位来找。关联规则(association rules)是利用交易ID来进行分析。
第3个字段代表的就是在这个时间段顾客同时购买的商品
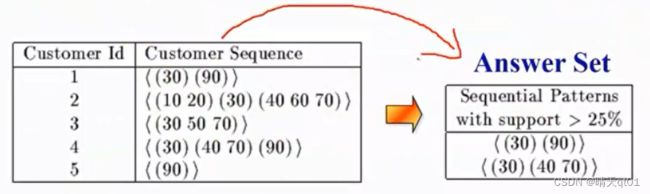
这里的规则我们设定的是(Sequential Patterns with support要大于百分之25)也就是说要有百分之25以上的顾客支持这种先后顺序的规则
我们顾客一共有5个,那么就需要有5*百分之25等于1.25,也就是说要有大于2个顾客满足的先后顺序规则,才能使用,这里我们一共找出了2个规则{(30)(90)}{(30)(40 70)}我们的序列模式的规则。
也就是顾客在购买30之后会购买90,和40 70。那每个规则都至少有2个部分满足该规则。如果顾客购买30之后中途购买了其他再购买90,也代表满足该规则。
这里2号顾客和4号顾客都支持我们的门槛值。从这个例子我们就可以发现1,要找到序列模式,比找关联规则更加的花时间。而且如果从原始数据找很耗费时间。所有我们会对此提前做预处理

我们会先对ID进行排序处理,然后再对交易时间进行排序。我们最终得到我们customer-sequence的数据库就是右下角的表格。一个顾客有一笔数据,比如顾客1就代表,30之后会购买90,我们不考虑其中的时间间隔,我们就考虑他们的先后关系就可以,二号顾客首先买10,20然后买30最后40,60,70一起买。
这个我们叫customer-Sequence Version of the Database,也就是顾客购买序列的数据库
我们的序列模型就是在这个数据库中进行处理寻找

我们的序列模式不需要我们consecutive的购买规则。就是不需要连续的购买才能产生序列模式
而且序列模型不一定只有单一的购买项目。也可能是项目集。比如购买30就会购买40和70的模式。40和70就代表了一个项目集。它是产品集合。不一定是简单的单一商品序列模型。
序列模型的评估指标
支持度:该项目集出现的概率
置信度:该项目集出现的条件概率
Aprioriall算法及实例说明
Aprioriall的算法步骤:
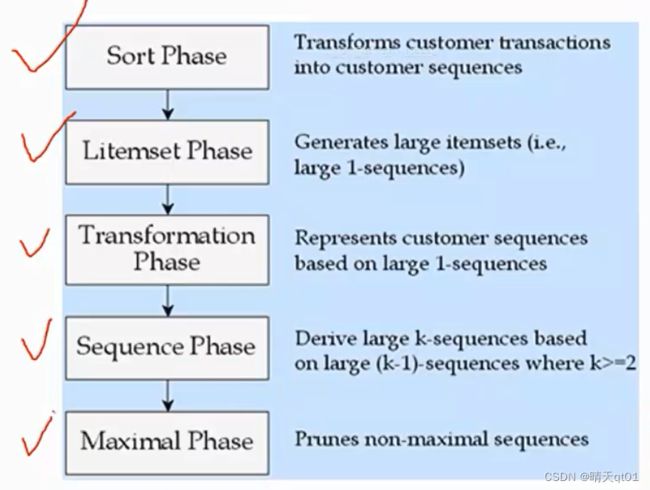
第一步:sort phase
排序的步骤
第二步:litemset phase
要寻找到交易数据库里面那些产品是频繁被购买的商品组合。因为我们序列模式是为了寻找到频繁被购买的商品和频繁被购买商品之间的组合。
第三步:Transformation phase
装换的阶段。
第四步:sequence phase
寻找序列模式的阶段
第五步:Maximal phase
因为我们的寻找到的序列模式经常会包含很多重复包含的内容。我们只要寻找到最大的就好。
接下来我就根据这5个阶段一一进行说明。
第一步:
我们将普通的数据库装换为我们需要的数据库。这个阶段就叫排序阶段。

根据ID,再对每个ID的时间进行排序。
第二步:
寻找那些项目集(单一商品或者多个商品)被频繁购买的情况。

我们用最小支持度定位的出现次数为2,然后我们就会找到这5项频繁项目。
这些都是频繁被购买的产品组合。
第3步:
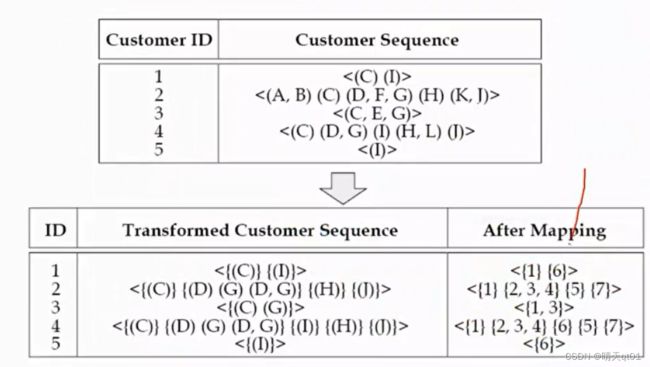
转化阶段,我们要把我们的频繁被购买的产品组合编码,
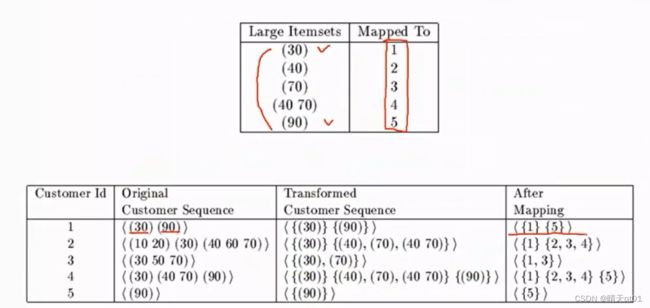
下方的表格第三个字段代表的就是频繁项目集经过排序的项目集,第四个字段代表的就是转化为编码的字段。
比较特别的是这个转化手段,比如id2的情况,40,60,70,因为我们的频繁项目集不包括60,我们就会把60排除。然后剩下40,70,又因为这两个频繁项目集,我们可以理解为,只购买了40,或者只购买了70,或者40,70同时购买。按照编码装换的规则,对应的就是2,3,4。
这样拆解的原因是,我们之后就只选定其中一个最大包含的来组合就可以。方便程序的撰写。第4次id也是我们只会挑选1,3之中的一个来作为序列模式。
这里90对应的部分就只有5
我们把我们的我们的数据库装换为简单的模式,我们可以从这些项目集一个一个组合,只要挑选其中一个组合为作为我们序列模型。
这里我们再举一个复杂一些的例子。:

这里每一步都是为了产生频繁项目集,第3步会用排列组合的方法把1到5的全部两两组合方式尝试一遍,寻找满足我们要求的频繁项目集。
然后第三步就是寻找三三组合的频繁项目集,但是不是完全排列组合,而是通过第三步的两两组合规则来寻找三三组合的频繁项目集以此类推第5步也是这样的方法寻找连续4个商品的序列模式。
每个项目集我们都会把下面覆盖的集合排除掉,比如{1234}就会覆盖{123}{134}{234}{124}。所以最后我们第六步得到的其实只有3个频繁项目集,被包含的频繁项目集就会被排除。
另外其实第二步是没有业务意义的。一个频繁商品对序列模式没有帮助。
这个就是我们的5个阶段。

这里我们产生的频繁项目集1234和1243是不同业务意义的,因为有时间顺序,所以也要排查。最后只得到1243.
不可能的组合其实我们在第345步的时候就有进行筛除。
包含关系:
3,45,8其实是被7,38,9,456,8所包含在里面的
前面被后面包含,前面在我们的步骤Maximal里会直接被拿掉。。
非包含关系:
{3,5}没有被{35}包含
因为后者是同时购买的,只能包含3或者包含5
Maximal就是为了寻找到最长的序列模式,以词此减低模式的复杂度。被包含的部分会被我们过滤掉,不会读取进来。
这步骤简化后就如下图:
这里面其实有很多被包含的频繁项目集,30和40和30,40.其实很多被过滤掉。
最后我们就只保留了2个序列模型。
下面举个案例:
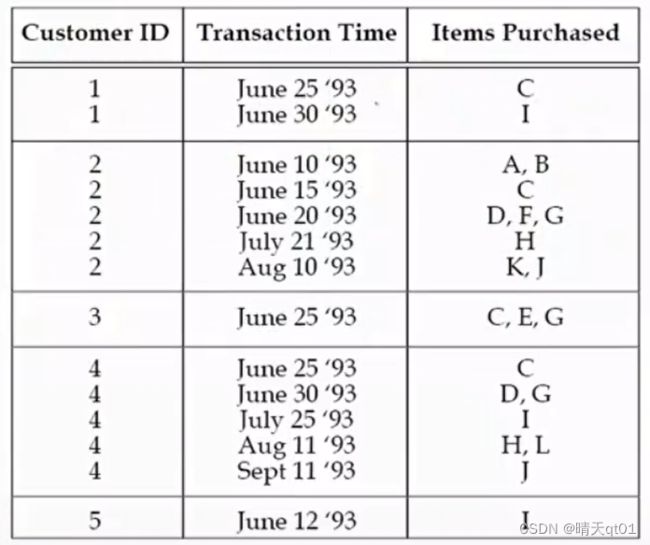
我们第一步进行排序得到我们序列的数据库:

接下来我们寻找我们的频繁项目集:
最小支持度我们定为百分之25

下一步我们就根据我们编码对数据进行装换。
下一步我们在进入我们的频繁序列模型。
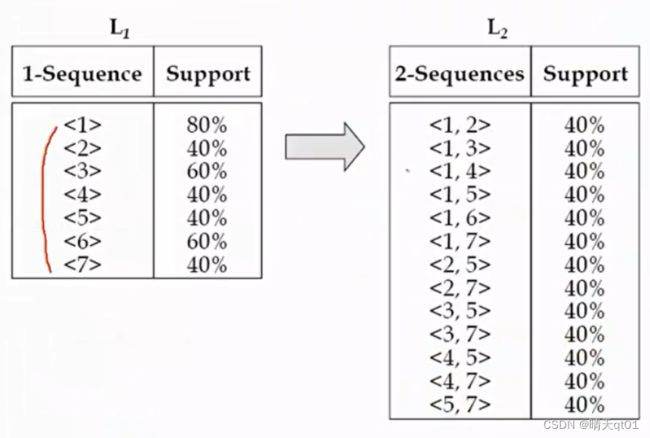
我们生成程度为2的序列模式。序列为3的模式。
在寻找长度为3的序列模式,寻找长度为4的序列模式。
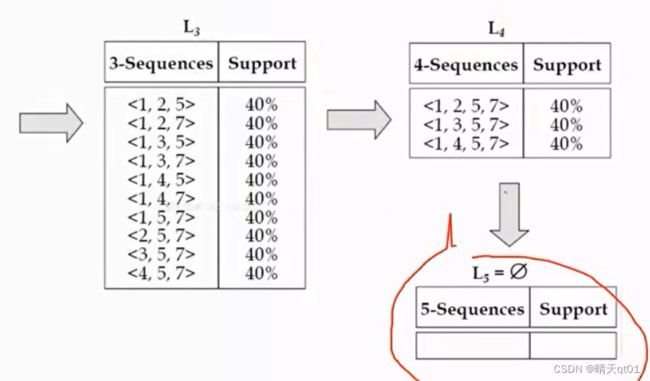
然后再利用maximal来筛除多余的频繁项目集。
注意,使用maximal步骤的时候要把编码装换为原始的频繁项目集,
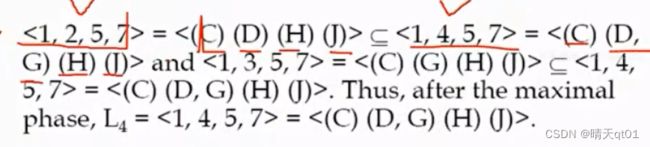
因为我们编码的过程中是不能看出包含关系的。只有装换为频繁项目集才能看出是否有包含关系。所以要还原为最原始的组合。才能知道序列有没有包含关系。
PrefixSpan算法及实例说明
PrefixSpan与aprioriall的区别就在于前者是产生各自商品的频繁项目集。以A为主或者以BB
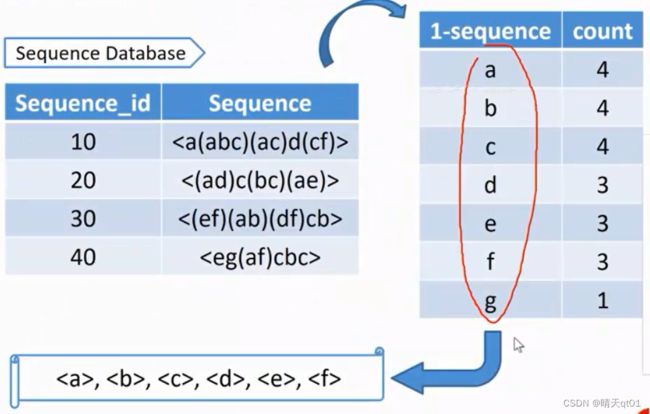
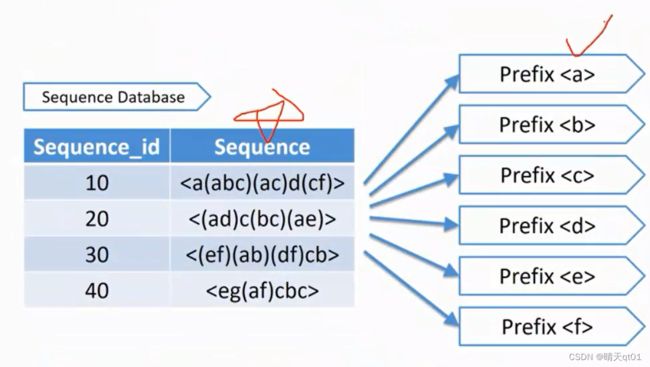
这里我们先寻找对应的单个商品是否满足我们最小支持度的要求。要由大到小排序。我们要把这些交易数据库切割为子资料集。
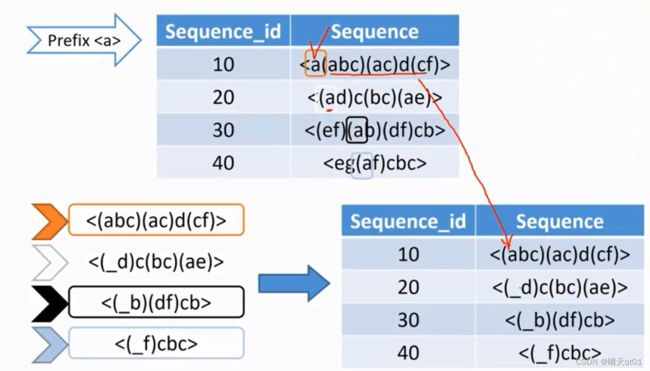
这里举一个关于a的子资料集:
我们先寻找每个顾客交易第一次购买A商品的情况前面的数据进行排查,后面的数据进行保留,如下图。
然后我们寻找每个频繁项目集出现的次数

因为我们最小支持度要求最少出现2次,其他的就被我们排除掉。
然后我们立刻计算一下长度为二的频繁序列模式。
然后再做这些长度为二的子数据集
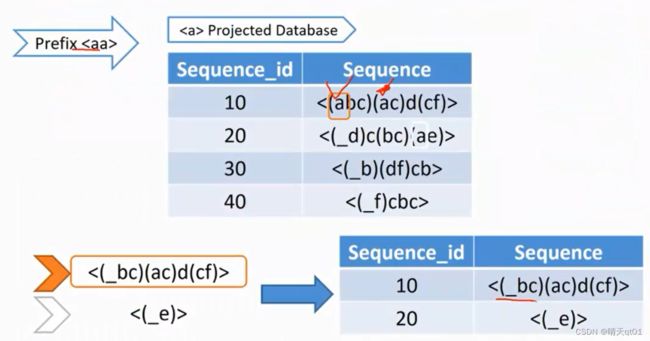
然后我们在根据子数据集a的项目在寻找一个有a的数据集,前面的数据排除,后面的数据留下,成为我们aa的子数据集。因为其中aa之后出现频繁项目集的都没有成功。我们就在寻找另一个子数据集。
最终得到的结果是长度为1,2,3,4,的序列模式。
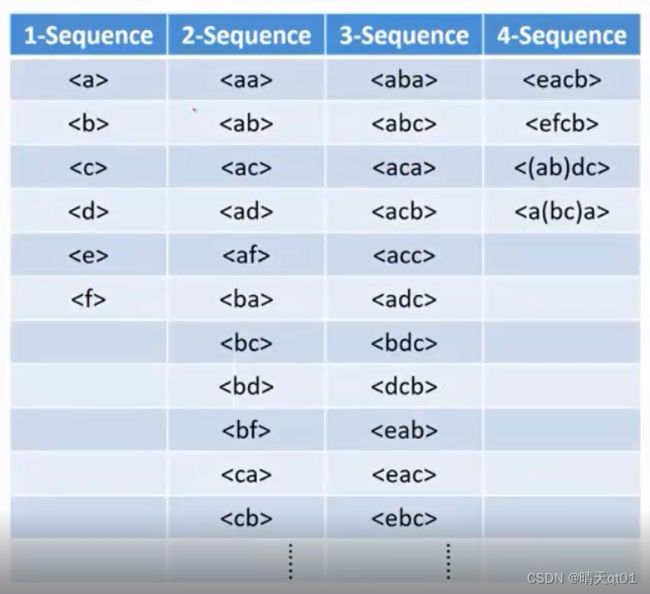
速度自然会比aprioriall的速度快非常多。
总结一下这个算法:

它就是根据原始数据来形成子数据集合,然后得到长度为2的子数据集,然后得到长度为3的子数据集。
它的缺点是这些子数据集都需要内存空间,
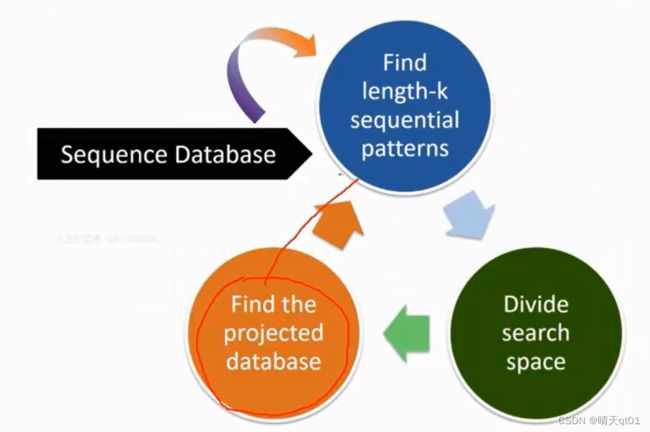
将数据库进行切割——然后寻找到长度为k的频繁序列模式——然后寻找到下一个子序列空间——从原始数据进行分割
重复进行,直到结果产生。
序列模式的延伸(状态转移网络)

状态转移网络(state transaction),是为了了解购买这个商品的顾客有多少的概率会购买接下来这个产品,也被叫状态移转网络(state trantion)。主要了解商品的前后关系。
总结:
我们主要讲的就是序列模式,用的评估指标一直是支持度,但是我们也可以做置信度。比如我们发现20之后购买40的支持度是百分之25.那么我们买20的情况下有多大的概率去购买40。也就是去做条件概率。也就是用20之后买40的概率去除以20的概率.
还有它的两个算法,以及用于观察关系的状态移转网络。