深度学习---双层神经网络中矩阵的运算及其含义记录
深度学习---双层神经网络中矩阵的运算及其含义记录
- 神经网络的正向传播与反向传播
-
- 正向传播
-
- 第一层的权重矩阵
- 第一层的输入矩阵
- Z^1^ = W^1^X^1^ + b^1^
- A^1^ = σ(Z^1^)
- 第二层的权重矩阵
- 第二层的输入矩阵
- Z^2^ = W^2^A^1^ + b^2^
- 反向传播
-
- dz^2^ = A^2^ - Y
- dw^2^ = 1/n dz^2^A^1T^
- db^2^ = 1/n np.sum(dz^2^,axis = 1,keepdim=True)
- dz^1^ = W^2T^dz^2^ * g^1`^(Z^1^) (这个地方是sigmoid函数的导函数)
- dw^1^ = 1/n dz^1^A^0T^
- db^1^ = 1/n np.sum(dz^1^,axis = 1,keepdim=True)
- w^1^ 和 dw^1^ 的维度是相同的,这也确保了后续的梯度下降打好了基础。
在看深度学习过程的时候,经常会因为各种矩阵计算搞得头晕,所以就想着梳理一遍并且记录一下,便于自己后续的学习。
神经网络的正向传播与反向传播
神经网络中的正向传播和反向传播都运用了不少的矩阵计算以及数学知识,我期望能够将每一步的含义都记录下来。希望在后续的学习中能够对不同矩阵的意义都能够很熟练的了然于心。 这可能算是矩阵微积分的知识? 目前我还不太明白。。。总之按照自己的理解先记录下去吧~
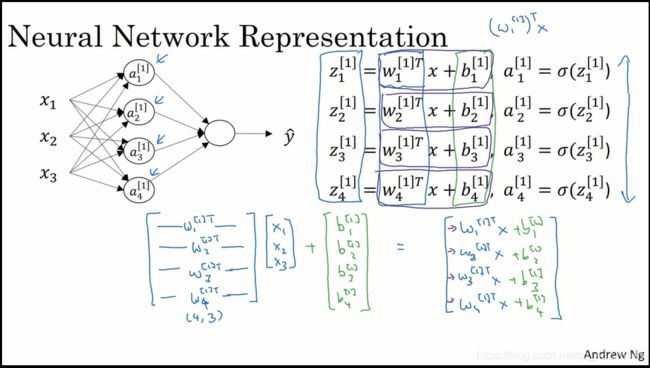
那么就用张图来当这次的demo吧。 如果是一个样本的计算的话,其实还没有那么头疼, 如果是多个样本堆叠之后进行一次运算的话,我就会因为分不清楚每个矩阵的含义和维度开始迷茫。。
总之!就是要记录一下每个矩阵的含义 以及维度,还有每一步运算的意义!帮助理解! 就是这样! 有点语无伦次!不太会说话了!
现在!给出我们输入值的假设! 每个训练样本有m个特征值 , 共有n个训练样本!
第一层神经网络具有k个神经元节点,第二层神经网络只有一个节点。
正向传播
正向传播算是没那么复杂。。
第一层的权重矩阵
先来说明一下 W1 矩阵 (第一层神经网络中的权重, 上标为1 代表它与第一层神经网络有关)
[ ⋯ ⋯ w 1 T ⋯ ⋯ ⋯ ⋯ w 2 T ⋯ ⋯ ⋮ ⋮ ⋮ ⋮ ⋮ ⋯ ⋯ w k T ⋯ ⋯ ] \left[ \begin{matrix} \cdots& \cdots & w_{1}^T&\cdots &\cdots \\ \cdots& \cdots & w_{2}^T & \cdots &\cdots \\ \vdots& \vdots & \vdots & \vdots &\vdots \\ \cdots& \cdots & w_{k}^T & \cdots &\cdots \\ \end{matrix} \right] ⎣⎢⎢⎢⎡⋯⋯⋮⋯⋯⋯⋮⋯w1Tw2T⋮wkT⋯⋯⋮⋯⋯⋯⋮⋯⎦⎥⎥⎥⎤
这个矩阵是一个(k,m)的矩阵,因为这个矩阵的每一行代表着一个神经元节点,每一列代表着一个神经元节点中的一个特征值的权重
第一层的输入矩阵
然后是 X1 矩阵 (也可记作A0,和后续的输入矩阵作比较就明白了~)
[ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ x 1 x 2 x 3 ⋯ x n ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ] \left[ \begin{matrix} \vdots& \vdots &\vdots & \vdots &\vdots \\ \vdots& \vdots & \vdots & \vdots &\vdots \\ x_{1} & x_{2} & x_{3} & \cdots & x_{n} \\ \vdots& \vdots & \vdots & \vdots &\vdots \\ \vdots& \vdots & \vdots & \vdots &\vdots \\ \end{matrix} \right] ⎣⎢⎢⎢⎢⎢⎢⎢⎢⎡⋮⋮x1⋮⋮⋮⋮x2⋮⋮⋮⋮x3⋮⋮⋮⋮⋯⋮⋮⋮⋮xn⋮⋮⎦⎥⎥⎥⎥⎥⎥⎥⎥⎤
这个矩阵是一个(m,n)的矩阵,这个矩阵的每一行代表着一个特征值,每一列代表不同的训练样本。(每一个训练样本是一个列向量,然后把他们纵向堆叠起来)
b1就不提了。
Z1 = W1X1 + b1
然后就是运算过程:Z1 = W1X1 + b1 这个过程计算出了一个中间值。它将投入激活函数中进行运算。。
W1X1这个过程是一个矩阵运算,(k,m)(m,n)两个矩阵进行乘法,之后会计算出一个(k,n)的矩阵
W1中的每一行代表着一个神经元节点,X1中的每一列代表不同的训练样本。所以每一步运算都相当于把每一组特征值xn 和它的权重wn相乘后累加 w1x1+w2x2+…+wnxn (这里的下标标识每一组训练样本中不同的特征值和权重)(我不知道怎么即表示层数又表示不同的特征值。。)
计算出来的(k,n)就代表着,我们每一行代表一个神经元节点,这是一个列向量,然后把n个样本的计算结果(n个列向量)叠加起来。
加上b1这个过程就是python广播然后逐个元素加上一个b就行了。
[ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ Z 1 Z 2 Z 3 ⋯ Z n ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ] \left[ \begin{matrix} \vdots& \vdots &\vdots & \vdots &\vdots \\ \vdots& \vdots & \vdots & \vdots &\vdots \\ Z_{1} & Z_{2} & Z_{3} & \cdots & Z_{n} \\ \vdots& \vdots & \vdots & \vdots &\vdots \\ \vdots& \vdots & \vdots & \vdots &\vdots \\ \end{matrix} \right] ⎣⎢⎢⎢⎢⎢⎢⎢⎢⎡⋮⋮Z1⋮⋮⋮⋮Z2⋮⋮⋮⋮Z3⋮⋮⋮⋮⋯⋮⋮⋮⋮Zn⋮⋮⎦⎥⎥⎥⎥⎥⎥⎥⎥⎤
A1 = σ(Z1)
我们将上一步计算的结果投入sigmoid函数中,经过计算后的矩阵,和输入值的矩阵维度相同 , 等到第二层的计算时,我就不再单独列出了。直接一笔带过。
[ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ A 1 A 2 A 3 ⋯ A n ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ] \left[ \begin{matrix} \vdots& \vdots &\vdots & \vdots &\vdots \\ \vdots& \vdots & \vdots & \vdots &\vdots \\ A_{1} & A_{2} & A_{3} & \cdots & A_{n} \\ \vdots& \vdots & \vdots & \vdots &\vdots \\ \vdots& \vdots & \vdots & \vdots &\vdots \\ \end{matrix} \right] ⎣⎢⎢⎢⎢⎢⎢⎢⎢⎡⋮⋮A1⋮⋮⋮⋮A2⋮⋮⋮⋮A3⋮⋮⋮⋮⋯⋮⋮⋮⋮An⋮⋮⎦⎥⎥⎥⎥⎥⎥⎥⎥⎤
这个A1会作为下一层神经网络的输入值,进行计算,所以下一层的输入值维度变成了(k,n)
第二层的权重矩阵
第二层的权重矩阵用W2表示, 因为第二层就一个神经元节点啦~ 这是一个(1,k)的矩阵,因为只有一个神经元节点 并且有k个参数需要设置权重~
[ ⋯ ⋯ w 1 T ⋯ ⋯ ] \left[ \begin{matrix} \cdots& \cdots & w_{1}^T& \cdots &\cdots \\ \end{matrix} \right] [⋯⋯w1T⋯⋯]
第二层的输入矩阵
就是上面说的 A1 维度为(k,n)
Z2 = W2A1 + b2
和第一层的道理一模一样,所以在此仅记录他们的维度变化
(1,k)(k,n) + (1,n) 第二层只有一个神经元节点,所以只有一行, 第二层有n个训练样本,所以是n列
[ Z 1 Z 2 Z 3 ⋯ Z n ] \left[ \begin{matrix} Z_{1} & Z_{2} & Z_{3} & \cdots & Z_{n} \\ \end{matrix} \right] [Z1Z2Z3⋯Zn]
然后投入sigmoid函数后它变成了
[ A 1 A 2 A 3 ⋯ A n ] \left[ \begin{matrix} A_{1} & A_{2} & A_{3} & \cdots & A_{n} \\ \end{matrix} \right] [A1A2A3⋯An]
到此为止,正向传播就结束了~ 然后就进入了反向传播过程!
第一次写博客,最简单的部分都写了这么久qwq markdown真难。。
反向传播
反向传播结合了矩阵和导数,在本文中也是重点部分。
反向传播中涉及到的 损失函数以及成本函数都不介绍了
dz2 = A2 - Y
不过多介绍为什么长这样 ,dz2的维度为(1,n) 维度和A2相同
输出层1个神经元,所以是1行, 每一列代表一个样本的dz 因为有n个样本,所有共有n列
dw2 = 1/n dz2A1T
dz2 的维度为(1,n) ,A1的维度为(k,n),转置之后的维度为(n,k)
所以 dz2A1T 的计算过程就是将,dz2中保存的每一个样本计算出的dz导数,分别和 利用每一个特征值计算出来的权重相乘后求和,最后再将矩阵整体除以样本个数,就得到了每一个特征值 利用所有数据集计算出的当前权重(因为后续要进行梯度下降寻找最优解,权重会不断更新) 计算之后 矩阵的维度为(1,k)
db2 = 1/n np.sum(dz2,axis = 1,keepdim=True)
因为db 和 dz在数值上相同,所以只需要将所有样本计算出来的 dz 计算一个平均值即可得到db
dz1 = W2Tdz2 * g1`(Z1) (这个地方是sigmoid函数的导函数)
利用链式求导法则,就能推出这个式子。
dz1 =(dz2 /da1) (da1 / dz1)
(da1 / dz1) 就是g1、(Z1) 这个我们稍后再说
那么 W2Tdz2 和 (dz2 /da1)必然有一定的关系,Z2 = W2A1 + b2 这是他们的运算关系。
W2T的维度为(k,1) 每一行代表一个特征值,也就是上一层神经网络中的某个神经元节点, 它都有一个权重,所以列数为1。dz2 保存着每一个样本计算出的导数,维度为(1,n) 。两个矩阵相乘之后会得到一个维度为(k,n)的矩阵,保存着 所有特征值(k个) 和 不同样本计算出来的导数的乘积,相当于(dz2 /da1)。g1、(Z1)的维度和Z1相同,均为 (k,n)。这样 矩阵元素两两相乘就可以实现。
dw1 = 1/n dz1A0T
和dw2的计算道理相同,在此记录维度。 (k,n) (n,m) 计算后的矩阵为 (k, m) k个神经元节点,每个神经元节点中有m个特征值,所有相应的保存了m个权,合乎道理~
db1 = 1/n np.sum(dz1,axis = 1,keepdim=True)
道理同上,维度为 (k,1)
w1 和 dw1 的维度是相同的,这也确保了后续的梯度下降打好了基础。
本文的主要目的还是为了帮助个人理解,人与人之间的理解方式可能不同。如果能帮到你,那就最好不过了,如果不能理解的话,就只能说明本人的脑回路奇葩了吧。个人建议,只需要花一些时间自己进行一下推导,很快就能理清楚,我也是花费了一段时间,然后有所收货之后记录在了博客上。
我也是第一次写博客,不知道博客的质量如何。。请见谅qwq
以上。