Keras深度学习实战(22)——生成对抗网络详解与实现
Keras深度学习实战(22)——生成对抗网络详解与实现
-
- 0. 前言
- 1. 生成对抗网络原理
- 2. 模型分析
- 3. 利用生成对抗网络生成手写数字图像
- 小结
- 系列链接
0. 前言
生成对抗网络 (Generative Adversarial Networks, GAN) 使用神经网络生成与原始图像集非常相似的新图像,它在图像生成中应用广泛,且 GAN 的相关研究正在迅速发展,以伪造生成与真实图像难以区分的逼真图像。在本节中,我们将学习 GAN 网络的原理并使用 Keras 实现 GAN。
1. 生成对抗网络原理
GAN 包含两个网络:生成器和鉴别器。生成器的目标是生成逼真的图像骗过鉴别器,鉴别器的目标是确定输入图像是真实图像还是生成器生成的伪造图像。
假设 GAN 用于生成人脸图像,鉴别器试图将图片分类为真实人脸图像或者伪造的虚假人脸图像,一旦我们训练完成的鉴别器能够将正确分类真实人脸图像和虚假人脸图像,如果我们向鉴别器输入新的人脸图片,它能够将输入图片分类为真实人脸图像和虚假人脸图像。生成器的任务是生成看起来与原始图像集非常相似的人脸图像,以至于鉴别器会误以为所生成的图像来自原始数据集。
2. 模型分析
接下来,我们详细介绍 GAN 生成图像的网络策略:
- 使用生成器生成伪造图像,生成器在最初只能生成噪声图像,噪声图像是通过将一组噪声值通过权重随机的神经网络得到的图像
- 将生成的图像与原始图像串联起来,鉴别器预测每个图像是伪造图像还是真实图像,对鉴别器进行训练:
- 在迭代中训练鉴别器权重
- 鉴别器的损失是图像的预测值和实际值(标签)的二进制交叉熵
- 生成的伪造图像的实际值(标签)为
0,原始数据集中真实图像的实际值(标签)为1
- 对鉴别器进行一次迭代训练后,就可以训练生成器利用输入噪声生成伪造图像,使其看起来更接近真实图像,从而使生成图像有可能欺骗鉴别器:
- 输入噪声通过生成器传递,通过多个隐藏层后,生成器最后输出伪造图像
- 将生成器生成的图像输入到鉴别器中,需要注意的是,鉴别器权重在此迭代训练中被冻结,因此在此迭代中不对其进行训练
- 在此训练过程中,因为生成器的目标是欺骗鉴别器,因此,假设生成的虚假图像实际值(标签)为
1
- 生成器的损失是鉴别器对输入图像的预测值和实际值 (
1) 的二进制交叉熵:- 此步骤中冻结鉴别器权重,冻结鉴别器可确保生成器从鉴别器提供的输出反馈中进行学习
- 重复以上过程,直到生成逼真的图像
3. 利用生成对抗网络生成手写数字图像
在本节中,我们采用 Keras 实现 GAN,并使用 MNIST 数据集训练 GAN 生成手写数字图像。
(1) 首先,导入相关库,并定义超参数:
import numpy as np
from keras.datasets import mnist
from keras.layers import Dense, Reshape, Flatten
from keras.models import Sequential
from keras.optimizers import Adam
import matplotlib.pyplot as plt
from keras.layers import BatchNormalization, LeakyReLU
shape = (28, 28, 1)
epochs = 5000
batch_size = 64
save_interval = 100
(2) 定义生成器,对于生成器模型,其采用形状为 100 维的噪声矢量,通过数个全连接层后生成 28×28×1=1024 的向量,最后将其整形为形状为 (28, 28, 1) 的图像,在模型中使用 LeakyReLU 激活函数。:
def generator():
model = Sequential()
model.add(Dense(256, input_shape=(100,)))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(1024))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(28*28*1, activation='tanh'))
model.add(Reshape(shape))
return model
生成器的简要信息输出如下:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 256) 25856
_________________________________________________________________
leaky_re_lu (LeakyReLU) (None, 256) 0
_________________________________________________________________
batch_normalization (BatchNo (None, 256) 1024
_________________________________________________________________
dense_1 (Dense) (None, 512) 131584
_________________________________________________________________
leaky_re_lu_1 (LeakyReLU) (None, 512) 0
_________________________________________________________________
batch_normalization_1 (Batch (None, 512) 2048
_________________________________________________________________
dense_2 (Dense) (None, 1024) 525312
_________________________________________________________________
leaky_re_lu_2 (LeakyReLU) (None, 1024) 0
_________________________________________________________________
batch_normalization_2 (Batch (None, 1024) 4096
_________________________________________________________________
dense_3 (Dense) (None, 784) 803600
_________________________________________________________________
reshape (Reshape) (None, 28, 28, 1) 0
=================================================================
Total params: 1,493,520
Trainable params: 1,489,936
Non-trainable params: 3,584
_________________________________________________________________
(3) 构建鉴别器模型,该模型将形状为 (28, 28, 1) 的输入图像,并产生输出 1 或 0,用于表示输入图像是原始真实图像还是生成的伪造图像:
def discriminator():
model = Sequential()
model.add(Flatten(input_shape=shape))
model.add(Dense(1024))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(256))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(1, activation='sigmoid'))
return model
鉴别器模型的简要结构信息输出如下:
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 784) 0
_________________________________________________________________
dense_4 (Dense) (None, 1024) 803840
_________________________________________________________________
leaky_re_lu_3 (LeakyReLU) (None, 1024) 0
_________________________________________________________________
dense_5 (Dense) (None, 256) 262400
_________________________________________________________________
leaky_re_lu_4 (LeakyReLU) (None, 256) 0
_________________________________________________________________
dense_6 (Dense) (None, 1) 257
=================================================================
Total params: 1,066,497
Trainable params: 1,066,497
Non-trainable params: 0
_________________________________________________________________
(4) 编译生成器和鉴别器模型:
generator = generator()
generator.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0002, beta_1=0.5, decay=8e-8))
discriminator = discriminator()
discriminator.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0002, beta_1=0.5, decay=8e-8), metrics=['acc'])
(5) 组合生成器与鉴别器,定义 GAN 模型,该模型用于训练生成器的权重,同时冻结鉴别器的权重。GAN 模型将随机噪声作为输入,并使用生成器网络将该噪声转换为形状为 (28, 28, 1) 的图像,然后模型预测生成的图像是真实图像还是伪造图像:
def gan(discriminator, generator):
discriminator.trainable = False
model = Sequential()
model.add(generator)
model.add(discriminator)
return model
gan = gan(discriminator, generator)
gan.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0002, beta_1=0.5, decay=8e-8))
(6) 定义函数 plot_images 用于绘制生成的图像:
def plot_images(samples=16, step=0):
noise = np.random.normal(0, 1, (samples, 100))
images = generator.predict(noise)
plt.figure(figsize=(10, 10))
for i in range(images.shape[0]):
plt.subplot(4, 4, i + 1)
image = images[i, :, :, :]
image = np.reshape(image, [28, 28])
plt.imshow(image, cmap='gray')
plt.axis('off')
plt.tight_layout()
plt.show()
(7) 加载 MNIST 数据集,并对数据集进行预处理:
(x_train, _), (_, _) = mnist.load_data()
x_train = (x_train.astype(np.float32) - 127.5) / 127.5
x_train = np.expand_dims(x_train, axis=3)
因为 GAN 模型基于给定的图像集 x_train 生成新图像,因此我们不需要输出标签。
(8) 通过在多个 epochs 内训练 GAN 来优化网络权重。
获取真实图像 legit_images 并利用噪声数据生成伪造图像 synthetic_images,使用噪声数据 gen_noise 作为输入,尝试生成真实图像:
disc_loss = []
gen_loss = []
for cnt in range(epochs):
random_index = np.random.randint(0, len(x_train) - batch_size / 2)
legit_images = x_train[random_index: random_index + batch_size // 2].reshape(batch_size // 2, 28, 28, 1)
gen_noise = np.random.normal(-1, 1, (batch_size // 2, 100))/2
synthetic_images = generator.predict(gen_noise)
使用 train_on_batch 方法训练鉴别器,train_on_batch 用于使用单个批数据对模型运行一次梯度更新,在输出中,实际图像的值为 1,伪造图像的值为 0:
x_combined_batch = np.concatenate((legit_images, synthetic_images))
y_combined_batch = np.concatenate((np.ones((batch_size // 2, 1)), np.zeros((batch_size // 2, 1))))
d_loss = discriminator.train_on_batch(x_combined_batch, y_combined_batch)
接下来,我们准备用于训练生成器的数据,随机噪声作为输入数据 noise,而 y_mislabeled 是用于训练生成器的输出,需要注意的是,这里的输出与训练鉴别器时的输出完全相反,即使用 1 作为伪造图像的值:
noise = np.random.normal(-1, 1, (batch_size, 100))/2
y_mislabled = np.ones((batch_size, 1))
接下来,我们训练 GAN 模型,其中鉴别器权重被冻结,而生成器的权重会得到更新以最小化损失,生成器的任务是生成可欺骗鉴别器的图像,即令鉴别器输出值 1:
g_loss = stacked_generator_discriminator.train_on_batch(noise, y_mislabled)
然后,我们记录各个 epoch 内的生成器损失和鉴别器损失,并按照指定间隔查看生成器生成图像:
g_loss = gan.train_on_batch(noise, y_mislabled)
disc_loss.append(d_loss[0])
gen_loss.append(g_loss)
print('epoch: {}, [Discriminator: {}], [Generator: {}]'.format(cnt, d_loss[0], g_loss))
if cnt % 100 == 0:
plot_images(step=cnt)
在人眼看来,生成的图像仍然并不真实,因此模型仍具有很大的改进空间,我们将在之后的学习中介绍能够生成更加逼真图像的 GAN 架构。
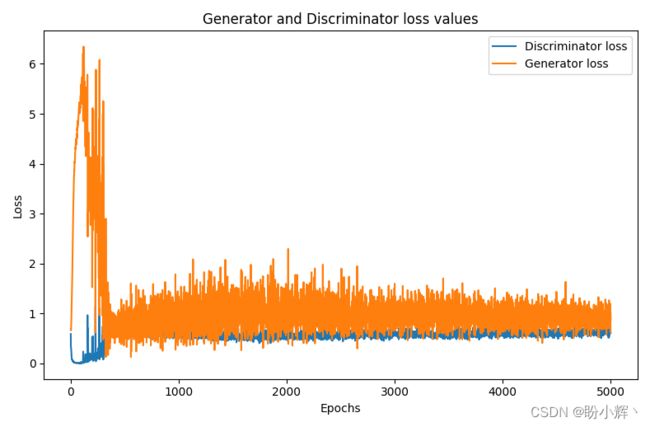
(9) 最后,绘制 GAN 训练过程中的损失变化情况,随着训练 epoch 的增加,鉴别器损失和生成器损失的变化如下:
epochs = range(1, epochs+1)
plt.plot(epochs, disc_loss, 'bo', label='Discriminator loss')
plt.plot(epochs, gen_loss, 'r', label='Generator loss')
plt.title('Generator and Discriminator loss values')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.show()
小结
鉴于生成对抗网络可以利用神经网络生成与原始图像集非常相似的新图像,关于生成对抗网络的研究逐渐引起越来越多领域的关注,在超分辨率重建、图像上色等方面有着不错的成效。本节首先介绍了对抗生成网络的基本原理,并使用 Keras 从零开始实现了一个对抗生成网络用于生成手写数字图像。
系列链接
Keras深度学习实战(1)——神经网络基础与模型训练过程详解
Keras深度学习实战(2)——使用Keras构建神经网络
Keras深度学习实战(3)——神经网络性能优化技术
Keras深度学习实战(4)——深度学习中常用激活函数和损失函数详解
Keras深度学习实战(5)——批归一化详解
Keras深度学习实战(6)——深度学习过拟合问题及解决方法
Keras深度学习实战(7)——卷积神经网络详解与实现
Keras深度学习实战(8)——使用数据增强提高神经网络性能
Keras深度学习实战(9)——卷积神经网络的局限性
Keras深度学习实战(10)——迁移学习详解
Keras深度学习实战(11)——可视化神经网络中间层输出
Keras深度学习实战(12)——面部特征点检测
Keras深度学习实战(13)——目标检测基础详解
Keras深度学习实战(14)——从零开始实现R-CNN目标检测
Keras深度学习实战(15)——从零开始实现YOLO目标检测
Keras深度学习实战(16)——自编码器详解
Keras深度学习实战(17)——使用U-Net架构进行图像分割
Keras深度学习实战(18)——语义分割详解
Keras深度学习实战(19)——使用对抗攻击生成可欺骗神经网络的图像
Keras深度学习实战(20)——DeepDream模型详解
Keras深度学习实战(21)——神经风格迁移详解