深度学习(pytorch)——利用GPU给网络训练的2种方法
Pytorch是torch的python版本,是由Facebook开源的神经网络框架,专门针对 GPU 加速的深度神经网络(DNN)编程。Torch 是一个经典的对多维矩阵数据进行操作的张量
(tensor )库,在机器学习和其他数学密集型应用有广泛应用。
Pytorch的计算图是动态的,可以根据计算需要实时改变计算图。
由于Torch语言采用 Lua,导致在国内一直很小众,并逐渐被支持 Python 的 Tensorflow 抢走用户。作为经典机器学习库 Torch 的端口,PyTorch 为 Python 语言使用者提供了舒适的写代码选择。
Pytorch是一个基于Python的可续计算包,提供两个高级功能:1、具有强大的GPU加速的张量计算(如NumPy)。2、包含自动求导系统的深度神经网络。
方法一:

找到上图的三种变量,然后.cuda()便可
网络模型.cuda()和损失函数.cuda()程序如下:

训练数据(输入.cuda()、标注.cuda())和 测试数据(输入.cuda()、标注.cuda())程序如下:


电脑内衣GPU可以去Google colab跑程序,设置如下图所示:

把pycharm的代码复制到Google colab上面去
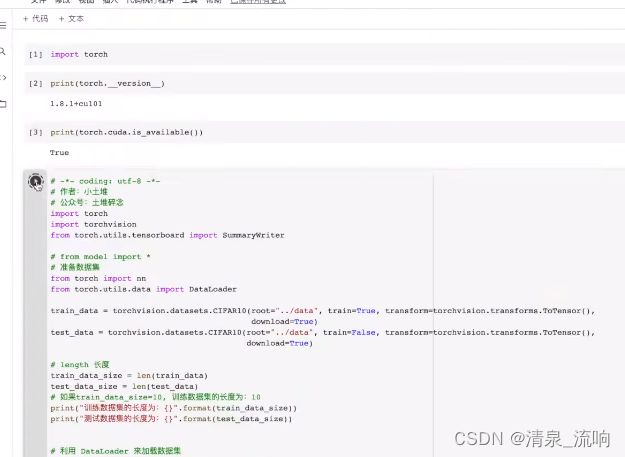

具体程序如下:
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten
from torch.utils.tensorboard import SummaryWriter
# from model import *
from torch.utils.data import DataLoader
train_data = torchvision.datasets.CIFAR10(root='./data_CIFAR10',train=True,
transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root='./data_CIFAR10',train=False,
transform=torchvision.transforms.ToTensor(),download=True)
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{} " .format(train_data_size))
print("测试数据集的长度为:{} " .format(test_data_size))
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
#搭建神经网络
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(3, 32, 5, padding=2, stride=1),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, padding=2, stride=1),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, padding=2, stride=1),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
tudui = Tudui()
# if torch.cuda.is_available():
# tudui = tudui.cuda()
#损失函数
loss_fn = nn.CrossEntropyLoss()
# if torch.cuda.is_available():
# loss_fn = loss_fn.cuda()
#优化器
optimizer = torch.optim.SGD(tudui.parameters(),lr=0.01)
#设置训练网络的一些参数
total_train_step = 0
total_test_step = 0
epoch = 10
writer = SummaryWriter('./logs_train')
for i in range(epoch):
print("------------第 {} 轮训练开始--------------".format(i+1))
tudui.eval()
for data in train_dataloader:
imgs,targets = data
# if torch.cuda.is_available():
# imgs = imgs.cuda()
# targets = targets.cuda()
outputs = tudui(imgs)
loss = loss_fn(outputs,targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step +=1
if total_train_step % 100 ==0:
print("训练次数 : {},Loss : {}".format(total_train_step,loss.item()))
writer.add_scalar("train_loss",loss.item(),total_train_step)
tudui.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs,targets = data
# if torch.cuda.is_available():
# imgs = imgs.cuda()
# targets = targets.cuda()
outputs = tudui(imgs)
loss = loss_fn(outputs,targets)
total_test_loss += loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy +accuracy
print("整体测试数据集的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar('test_loss',total_test_loss,total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step += 1
torch.save(tudui, 'tudui_{}.pth'.format(i))
print("模型已保存")
writer.close()
方法二:

电脑上有多张不同的显卡时,可以用该方法指定模型去哪张显卡运行。具体方法如下:

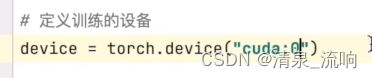
device更加常用的写法如下


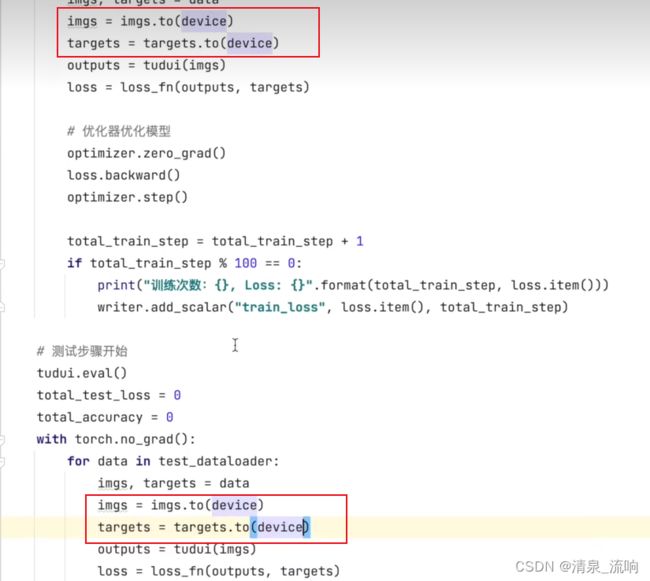
具体程序如下:
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten
from torch.utils.tensorboard import SummaryWriter
# from model import *
from torch.utils.data import DataLoader
device = torch.device("cpu")
# device = torch.device("cuda")
# device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_data = torchvision.datasets.CIFAR10(root='./data_CIFAR10',train=True,
transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root='./data_CIFAR10',train=False,
transform=torchvision.transforms.ToTensor(),download=True)
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{} " .format(train_data_size))
print("测试数据集的长度为:{} " .format(test_data_size))
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
#搭建神经网络
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(3, 32, 5, padding=2, stride=1),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, padding=2, stride=1),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, padding=2, stride=1),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
tudui = Tudui()
tudui = tudui.to(device)
# if torch.cuda.is_available():
# tudui = tudui.cuda()
#损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
# if torch.cuda.is_available():
# loss_fn = loss_fn.cuda()
#优化器
optimizer = torch.optim.SGD(tudui.parameters(),lr=0.01)
#设置训练网络的一些参数
total_train_step = 0
total_test_step = 0
epoch = 10
writer = SummaryWriter('./logs_train')
for i in range(epoch):
print("------------第 {} 轮训练开始--------------".format(i+1))
tudui.eval()
for data in train_dataloader:
imgs,targets = data
imgs = imgs.to(device)
targets = targets.to(device)
# if torch.cuda.is_available():
# imgs = imgs.cuda()
# targets = targets.cuda()
outputs = tudui(imgs)
loss = loss_fn(outputs,targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step +=1
if total_train_step % 100 ==0:
print("训练次数 : {},Loss : {}".format(total_train_step,loss.item()))
writer.add_scalar("train_loss",loss.item(),total_train_step)
tudui.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs,targets = data
imgs = imgs.to(device)
targets = targets.to(device)
# if torch.cuda.is_available():
# imgs = imgs.cuda()
# targets = targets.cuda()
outputs = tudui(imgs)
loss = loss_fn(outputs,targets)
total_test_loss += loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy +accuracy
print("整体测试数据集的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar('test_loss',total_test_loss,total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step += 1
torch.save(tudui, 'tudui_{}.pth'.format(i))
print("模型已保存")
writer.close()