python从入门到实践:数据类型、文件处理
目录
一、数据类型
1.数字
整型与浮点型
其他数字类型
2.字符串
3.字节串
4.列表
5.元祖
6.集合
7.字典
8.可变类型与不可变类型
数字类型
字符串
列表
元祖
字典
9.数据类型总结
二、文件处理
1.文件的引入
2.文件的基本操作流程
2.1基本流程
2.2资源回收与with上下文管理
2.3指定操作文本文件的字符编码
3.文件的操作模式
3.1控制文件读写操作的模式
3.2控制文件读写内容的模式
4.操作文件的方法
4.1重点掌握
4.2了解
5.主动控制文件内指针移动
5.1案例一:0模式
5.2案例二:1模式
5.3案例三:2模式
6.文件的修改
6.1文件修改方式1
6.2文件修改方式2
一、数据类型
1.数字
整型与浮点型
#整型int
作用:年纪,等级,身份证号,qq号等整型数字相关
定义:
age=10 #本质age=int(10)
#浮点型float
作用:薪资,身高,体重,体质参数等浮点数相关
salary=3000.3 #本质salary=float(3000.3)
其他数字类型
#复数
>>> x=1-2j
>>> x.real
1.0
>>> x.imag
-2.0 2.字符串
需要掌握的操作
#strip
name='*C_小米同学**'
print(name.strip('*'))
print(name.lstrip('*'))
print(name.rstrip('*'))
C_小米同学
C_小米同学**
*C_小米同学
#lower,upper
name='C_xiaomi'
print(name.lower())
print(name.upper())
c_xiaomi
C_XIAOMI
name='C_xiaomi'
print(name.endswith('mi'))
print(name.startswith('C'))
True
True
#format的三种玩法
res1='{} {} {}'.format('rice',18,'male')
res2='{1} {0} {1}'.format('rice',18,'male')
res3='{name} {age} {sex}'.format(sex='male',name='rice',age=18)
print(res1)
print(res2)
print(res3)
rice 18 male
18 rice 18
rice 18 male
#split
name='root:x:0:0::/root:/bin/bash'
print(name.split(':')) #默认分隔符为空格
name='C:/a/b/c/d.txt' #只想拿到顶级目录
print(name.split('/',1))
['root', 'x', '0', '0', '', '/root', '/bin/bash']
['C:', 'a/b/c/d.txt']
name='a|b|c'
print(name.rsplit('|',1)) #从右开始切分
['a|b', 'c']
#join
tag=' '
print(tag.join(['rice','say','hello','world'])) #可迭代对象必须都是字符串
rice say hello world
#replace
name='rice say :i have one tesla,my name is rice'
print(name.replace('rice','cool',1))
cool say :i have one tesla,my name is rice
#isdigit:可以判断bytes和unicode类型,是最常用的用于于判断字符是否为"数字"的方法
age=input('>>: ')
print(age.isdigit())
False
了解的操作
#find,rfind,index,rindex,count
name='egon say hello'
print(name.find('o',1,3)) #顾头不顾尾,找不到则返回-1不会报错,找到了则显示索引
# print(name.index('e',2,4)) #同上,但是找不到会报错
print(name.count('e',1,3)) #顾头不顾尾,如果不指定范围则查找所有
#center,ljust,rjust,zfill
name='egon'
print(name.center(30,'-'))
print(name.ljust(30,'*'))
print(name.rjust(30,'*'))
print(name.zfill(50)) #用0填充
#expandtabs
name='egon\thello'
print(name)
print(name.expandtabs(1))
#captalize,swapcase,title
print(name.capitalize()) #首字母大写
print(name.swapcase()) #大小写翻转
msg='egon say hi'
print(msg.title()) #每个单词的首字母大写
#is数字系列
#在python3中
num1=b'4' #bytes
num2=u'4' #unicode,python3中无需加u就是unicode
num3='四' #中文数字
num4='Ⅳ' #罗马数字
#isdigt:bytes,unicode
print(num1.isdigit()) #True
print(num2.isdigit()) #True
print(num3.isdigit()) #False
print(num4.isdigit()) #False
#isdecimal:uncicode
#bytes类型无isdecimal方法
print(num2.isdecimal()) #True
print(num3.isdecimal()) #False
print(num4.isdecimal()) #False
#isnumberic:unicode,中文数字,罗马数字
#bytes类型无isnumberic方法
print(num2.isnumeric()) #True
print(num3.isnumeric()) #True
print(num4.isnumeric()) #True
#三者不能判断浮点数
num5='4.3'
print(num5.isdigit())
print(num5.isdecimal())
print(num5.isnumeric())
'''
总结:
最常用的是isdigit,可以判断bytes和unicode类型,这也是最常见的数字应用场景
如果要判断中文数字或罗马数字,则需要用到isnumeric
'''
#is其他
print('===>')
name='egon123'
print(name.isalnum()) #字符串由字母或数字组成
print(name.isalpha()) #字符串只由字母组成
print(name.isidentifier())
print(name.islower())
print(name.isupper())
print(name.isspace())
print(name.istitle())3.字节串
参考博客C_小米同学:字符串与字节串
4.列表
# 定义:在[]内,用逗号分隔开多个任意数据类型的值
l1 = [1,'a',[1,2]] # 本质:l1 = list([1,'a',[1,2]])
# 但凡能被for循环遍历的数据类型都可以传给list()转换成列表类型,list()会跟for循环一样遍历出数据类型中包含的每一个元素然后放到列表中
>>> list('wdad') # 结果:['w', 'd', 'a', 'd']
>>> list([1,2,3]) # 结果:[1, 2, 3]
>>> list({"name":"jason","age":18}) #结果:['name', 'age']
>>> list((1,2,3)) # 结果:[1, 2, 3]
>>> list({1,2,3,4}) # 结果:[1, 2, 3, 4]
重点掌握模块:
# 1.按索引存取值(正向存取+反向存取):即可存也可以取
# 1.1 正向取(从左往右)
>>> my_friends=['tony','jason','tom',4,5]
>>> my_friends[0]
tony
# 1.2 反向取(负号表示从右往左)
>>> my_friends[-1]
5
# 1.3 对于list来说,既可以按照索引取值,又可以按照索引修改指定位置的值,但如果索引不存在则报错
>>> my_friends = ['tony','jack','jason',4,5]
>>> my_friends[1] = 'martthow'
>>> my_friends
['tony', 'martthow', 'jason', 4, 5]
# 2.切片(顾头不顾尾,步长)
# 2.1 顾头不顾尾:取出索引为0到3的元素
>>> my_friends[0:4]
['tony', 'jason', 'tom', 4]
# 2.2 步长:0:4:2,第三个参数2代表步长,会从0开始,每次累加一个2即可,所以会取出索引0、2的元素
>>> my_friends[0:4:2]
['tony', 'tom']
# 3.长度
>>> len(my_friends)
5
# 4.成员运算in和not in
>>> 'tony' in my_friends
True
>>> 'xxx' not in my_friends
True
# 5.添加
# 5.1 append()列表尾部追加元素
>>> l1 = ['a','b','c']
>>> l1.append('d')
>>> l1
['a', 'b', 'c', 'd']
# 5.2 extend()一次性在列表尾部添加多个元素
>>> l1.extend(['a','b','c'])
>>> l1
['a', 'b', 'c', 'd', 'a', 'b', 'c']
# 5.3 insert()在指定位置插入元素
>>> l1.insert(0,"first") # 0表示按索引位置插值
>>> l1
['first', 'a', 'b', 'c', 'alisa', 'a', 'b', 'c']
# 6.删除
# 6.1 del
>>> l = [11,22,33,44]
>>> del l[2] # 删除索引为2的元素
>>> l
[11,22,44]
# 6.2 pop()默认删除列表最后一个元素,并将删除的值返回,括号内可以通过加索引值来指定删除元素
>>> l = [11,22,33,22,44]
>>> res=l.pop()
>>> res
44
>>> res=l.pop(1)
>>> res
22
# 6.3 remove()括号内指名道姓表示要删除哪个元素,没有返回值
>>> l = [11,22,33,22,44]
>>> res=l.remove(22) # 从左往右查找第一个括号内需要删除的元素
>>> print(res)
None
# 7.reverse()颠倒列表内元素顺序
>>> l = [11,22,33,44]
>>> l.reverse()
>>> l
[44,33,22,11]
# 8.sort()给列表内所有元素排序
# 8.1 排序时列表元素之间必须是相同数据类型,不可混搭,否则报错
>>> l = [11,22,3,42,7,55]
>>> l.sort()
>>> l
[3, 7, 11, 22, 42, 55] # 默认从小到大排序
>>> l = [11,22,3,42,7,55]
>>> l.sort(reverse=True) # reverse用来指定是否跌倒排序,默认为False
>>> l
[55, 42, 22, 11, 7, 3]
# 8.2 了解知识:
# 我们常用的数字类型直接比较大小,但其实,字符串、列表等都可以比较大小,原理相同:都是依次比较对应位置的元素的大小,如果分出大小,则无需比较下一个元素,比如
>>> l1=[1,2,3]
>>> l2=[2,]
>>> l2 > l1
True
# 字符之间的大小取决于它们在ASCII表中的先后顺序,越往后越大
>>> s1='abc'
>>> s2='az'
>>> s2 > s1 # s1与s2的第一个字符没有分出胜负,但第二个字符'z'>'b',所以s2>s1成立
True
# 所以我们也可以对下面这个列表排序
>>> l = ['A','z','adjk','hello','hea']
>>> l.sort()
>>> l
['A', 'adjk', 'hea', 'hello','z']
# 9.循环
# 循环遍历my_friends列表里面的值
for line in my_friends:
print(line)
'tony'
'jack'
'jason'
4
5
>>> l=[1,2,3,4,5,6]
>>> l[0:3:1]
[1, 2, 3] # 正向步长
>>> l[2::-1]
[3, 2, 1] # 反向步长
# 通过索引取值实现列表翻转
>>> l[::-1]
[6, 5, 4, 3, 2, 1]5.元祖
元组与列表类似,也是可以存多个任意类型的元素,不同之处在于元组的元素不能修改,即元组相当于不可变的列表,用于记录多个固定不允许修改的值,单纯用于取
# 在()内用逗号分隔开多个任意类型的值
>>> countries = ("中国","美国","英国") # 本质:countries = tuple("中国","美国","英国")
# 强调:如果元组内只有一个值,则必须加一个逗号,否则()就只是包含的意思而非定义元组
>>> countries = ("中国",) # 本质:countries = tuple("中国")
# 但凡能被for循环的遍历的数据类型都可以传给tuple()转换成元组类型
>>> tuple('wdad') # 结果:('w', 'd', 'a', 'd')
>>> tuple([1,2,3]) # 结果:(1, 2, 3)
>>> tuple({"name":"jason","age":18}) # 结果:('name', 'age')
>>> tuple((1,2,3)) # 结果:(1, 2, 3)
>>> tuple({1,2,3,4}) # 结果:(1, 2, 3, 4)
# tuple()会跟for循环一样遍历出数据类型中包含的每一个元素然后放到元组中
>>> tuple1 = (1, 'hhaha', 15000.00, 11, 22, 33)
# 1、按索引取值(正向取+反向取):只能取,不能改否则报错!
>>> tuple1[0]
1
>>> tuple1[-2]
22
>>> tuple1[0] = 'hehe' # 报错:TypeError:
# 2、切片(顾头不顾尾,步长)
>>> tuple1[0:6:2]
(1, 15000.0, 22)
# 3、长度
>>> len(tuple1)
6
# 4、成员运算 in 和 not in
>>> 'hhaha' in tuple1
True
>>> 'hhaha' not in tuple1
False
# 5、循环
>>> for line in tuple1:
... print(line)
1
hhaha
15000.0
11
22
336.集合
集合、list, tuple, dict-样都可以存放多个值,但是集合主要用于:去重、关系运算
"""
定义:在{}内用逗号分隔开多个元素,集合具备以下三个特点:
1:每个元素必须是不可变类型
2:集合内没有重复的元素
3:集合内元素无序
"""
s = {1,2,3,4} # 本质 s = set({1,2,3,4})
# 注意1:列表类型是索引对应值,字典是key对应值,均可以取得单个指定的值,而集合类型既没有索引也没有key与值对应,所以无法取得单个的值,而且对于集合来说,主要用于去重与关系元素,根本没有取出单个指定值这种需求。
# 注意2:{}既可以用于定义dict,也可以用于定义集合,但是字典内的元素必须是key:value的格式,现在我们想定义一个空字典和空集合,该如何准确去定义两者?
d = {} # 默认是空字典
s = set() # 这才是定义空集合
# 但凡能被for循环的遍历的数据类型(强调:遍历出的每一个值都必须为不可变类型)都可以传给set()转换成集合类型
>>> s = set([1,2,3,4])
>>> s1 = set((1,2,3,4))
>>> s2 = set({'name':'jason',})
>>> s3 = set('egon')
>>> s,s1,s2,s3
{1, 2, 3, 4} {1, 2, 3, 4} {'name'} {'e', 'o', 'g', 'n'}>>> friends1 = {"zero","kevin","jason","egon"} # 用户1的好友们
>>> friends2 = {"Jy","ricky","jason","egon"} # 用户2的好友们
# 1.合集/并集(|):求两个用户所有的好友(重复好友只留一个)
>>> friends1 | friends2
{'kevin', 'ricky', 'zero', 'jason', 'Jy', 'egon'}
# 2.交集(&):求两个用户的共同好友
>>> friends1 & friends2
{'jason', 'egon'}
# 3.差集(-):
>>> friends1 - friends2 # 求用户1独有的好友
{'kevin', 'zero'}
>>> friends2 - friends1 # 求用户2独有的好友
{'ricky', 'Jy'}
# 4.对称差集(^) # 求两个用户独有的好友们(即去掉共有的好友)
>>> friends1 ^ friends2
{'kevin', 'zero', 'ricky', 'Jy'}
# 5.值是否相等(==)
>>> friends1 == friends2
False
# 6.父集:一个集合是否包含另外一个集合
# 6.1 包含则返回True
>>> {1,2,3} > {1,2}
True
>>> {1,2,3} >= {1,2}
True
# 6.2 不存在包含关系,则返回False
>>> {1,2,3} > {1,3,4,5}
False
>>> {1,2,3} >= {1,3,4,5}
False
# 7.子集
>>> {1,2} < {1,2,3}
True
>>> {1,2} <= {1,2,3}
True集合的局限性:
1. 只能针对不可变类型
2. 集合本身是无序的,去重之后无法保留原来的顺序
>>> l=['a','b',1,'a','a']
>>> s=set(l)
>>> s # 将列表转成了集合
{'b', 'a', 1}
>>> l_new=list(s) # 再将集合转回列表
>>> l_new
['b', 'a', 1] # 去除了重复,但是打乱了顺序
# 针对不可变类型,并且保证顺序则需要我们自己写代码实现,例如
l=[
{'name':'lili','age':18,'sex':'male'},
{'name':'jack','age':73,'sex':'male'},
{'name':'tom','age':20,'sex':'female'},
{'name':'lili','age':18,'sex':'male'},
{'name':'lili','age':18,'sex':'male'},
]
new_l=[]
for dic in l:
if dic not in new_l:
new_l.append(dic)
print(new_l)
# 结果:既去除了重复,又保证了顺序,而且是针对不可变类型的去重
[
{'age': 18, 'sex': 'male', 'name': 'lili'},
{'age': 73, 'sex': 'male', 'name': 'jack'},
{'age': 20, 'sex': 'female', 'name': 'tom'}
]# 1.长度
>>> s={'a','b','c'}
>>> len(s)
3
# 2.成员运算
>>> 'c' in s
True
# 3.循环
>>> for item in s:
... print(item)
...
c
a
b7.字典
# 定义:在{}内用逗号分隔开多元素,每一个元素都是key:value的形式,其中value可以是任意类型,而key则必须是不可变类型,详见第八小节,通常key应该是str类型,因为str类型会对value有描述性的功能
info={'name':'tony','age':18,'sex':'male'} #本质info=dict({....})
# 也可以这么定义字典
info=dict(name='tony',age=18,sex='male') # info={'age': 18, 'sex': 'male', 'name': 'tony'}
# 转换1:
>>> info=dict([['name','tony'],('age',18)])
>>> info
{'age': 18, 'name': 'tony'}
# 转换2:fromkeys会从元组中取出每个值当做key,然后与None组成key:value放到字典中
>>> {}.fromkeys(('name','age','sex'),None)
{'age': None, 'sex': None, 'name': None}# 1、按key存取值:可存可取
# 1.1 取
>>> dic = {
... 'name': 'xxx',
... 'age': 18,
... 'hobbies': ['play game', 'basketball']
... }
>>> dic['name']
'xxx'
>>> dic['hobbies'][1]
'basketball'
# 1.2 对于赋值操作,如果key原先不存在于字典,则会新增key:value
>>> dic['gender'] = 'male'
>>> dic
{'name': 'tony', 'age': 18, 'hobbies': ['play game', 'basketball'],'gender':'male'}
# 1.3 对于赋值操作,如果key原先存在于字典,则会修改对应value的值
>>> dic['name'] = 'tony'
>>> dic
{'name': 'tony', 'age': 18, 'hobbies': ['play game', 'basketball']}
# 2、长度len
>>> len(dic)
3
# 3、成员运算in和not in
>>> 'name' in dic # 判断某个值是否是字典的key
True
# 4、删除
>>> dic.pop('name') # 通过指定字典的key来删除字典的键值对
>>> dic
{'age': 18, 'hobbies': ['play game', 'basketball']}
# 5、键keys(),值values(),键值对items()
>>> dic = {'age': 18, 'hobbies': ['play game', 'basketball'], 'name': 'xxx'}
# 获取字典所有的key
>>> dic.keys()
dict_keys(['name', 'age', 'hobbies'])
# 获取字典所有的value
>>> dic.values()
dict_values(['xxx', 18, ['play game', 'basketball']])
# 获取字典所有的键值对
>>> dic.items()
dict_items([('name', 'xxx'), ('age', 18), ('hobbies', ['play game', 'basketball'])])
# 6、循环
# 6.1 默认遍历的是字典的key
>>> for key in dic:
... print(key)
...
age
hobbies
name
# 6.2 只遍历key
>>> for key in dic.keys():
... print(key)
...
age
hobbies
name
# 6.3 只遍历value
>>> for key in dic.values():
... print(key)
...
18
['play game', 'basketball']
xxx
# 6.4 遍历key与value
>>> for key in dic.items():
... print(key)
...
('age', 18)
('hobbies', ['play game', 'basketball'])
('name', 'xxx')需要重点掌握的操作
1.get()
>>> dic= {'k1':'jason','k2':'Tony','k3':'JY'}
>>> dic.get('k1')
'jason' # key存在,则获取key对应的value值
>>> res=dic.get('xxx') # key不存在,不会报错而是默认返回None
>>> print(res)
None
>>> res=dic.get('xxx',666) # key不存在时,可以设置默认返回的值
>>> print(res)
666
# ps:字典取值建议使用get方法
2.pop()
>>> dic= {'k1':'jason','k2':'Tony','k3':'JY'}
>>> v = dic.pop('k2') # 删除指定的key对应的键值对,并返回值
>>> dic
{'k1': 'jason', 'kk2': 'JY'}
>>> v
'Tony'3.popitem()
>>> dic= {'k1':'jason','k2':'Tony','k3':'JY'}
>>> item = dic.popitem() # 随机删除一组键值对,并将删除的键值放到元组内返回
>>> dic
{'k3': 'JY', 'k2': 'Tony'}
>>> item
('k1', 'jason')4.update()
# 用新字典更新旧字典,有则修改,无则添加
>>> dic= {'k1':'jason','k2':'Tony','k3':'JY'}
>>> dic.update({'k1':'JN','k4':'xxx'})
>>> dic
{'k1': 'JN', 'k3': 'JY', 'k2': 'Tony', 'k4': 'xxx'}
5.fromkeys()
>>> dic = dict.fromkeys(['k1','k2','k3'],[])
>>> dic
{'k1': [], 'k2': [], 'k3': []}6.setdefault()
# key不存在则新增键值对,并将新增的value返回
>>> dic={'k1':111,'k2':222}
>>> res=dic.setdefault('k3',333)
>>> res
333
>>> dic # 字典中新增了键值对
{'k1': 111, 'k3': 333, 'k2': 222}
# key存在则不做任何修改,并返回已存在key对应的value值
>>> dic={'k1':111,'k2':222}
>>> res=dic.setdefault('k1',666)
>>> res
111
>>> dic # 字典不变
{'k1': 111, 'k2': 222}8.可变类型与不可变类型
可变数据类型:值发生改变时,内存地址不变,即id不变,证明在改变原值不可变类型:值发生改变时,内存地址也发生改变,即id也变,证明是没有在改变原值,是产生了新的值
数字类型
>>> x = 10
>>> id(x)
1830448896
>>> x = 20
>>> id(x)
1830448928
# 内存地址改变了,说明整型是不可变数据类型,浮点型也一样字符串
>>> x = "Jy"
>>> id(x)
938809263920
>>> x = "Ricky"
>>> id(x)
938809264088
# 内存地址改变了,说明字符串是不可变数据类型列表
>>> list1 = ['tom','jack','rice']
>>> id(list1)
486316639176
>>> list1[2] = 'kevin'
>>> id(list1)
486316639176
>>> list1.append('lili')
>>> id(list1)
486316639176
# 对列表的值进行操作时,值改变但内存地址不变,所以列表是可变数据类型元祖
>>> t1 = ("tom","jack",[1,2])
>>> t1[0]='TOM' # 报错:TypeError
>>> t1.append('lili') # 报错:TypeError
# 元组内的元素无法修改,指的是元组内索引指向的内存地址不能被修改
>>> t1 = ("tom","jack",[1,2])
>>> id(t1[0]),id(t1[1]),id(t1[2])
(4327403152, 4327403072, 4327422472)
>>> t1[2][0]=111 # 如果元组中存在可变类型,是可以修改,但是修改后的内存地址不变
>>> t1
('tom', 'jack', [111, 2])
>>> id(t1[0]),id(t1[1]),id(t1[2]) # 查看id仍然不变
(4327403152, 4327403072, 4327422472)字典
>>> dic = {'name':'egon','sex':'male','age':18}
>>>
>>> id(dic)
4327423112
>>> dic['age']=19
>>> dic
{'age': 19, 'sex': 'male', 'name': 'egon'}
>>> id(dic)
4327423112
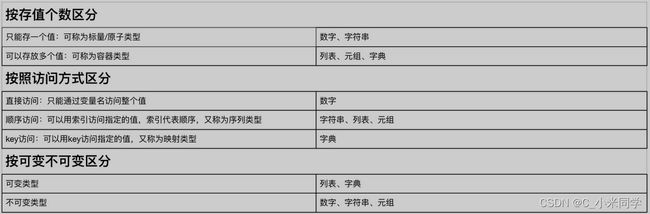
# 对字典进行操作时,值改变的情况下,字典的id也是不变,即字典也是可变数据类型9.数据类型总结
二、文件处理
1.文件的引入
应用程序运行过程中产生的数据最先都是存放于内存中的,若想永久保存下来,必须要保存于硬盘中。应用程序若想操作硬件必须通过操作系统,而文件就是操作系统提供给应用程序来操作硬盘的虚拟概念,用户或应用程序对文件的操作,就是向操作系统发起调用,然后由操作系统完成对硬盘的具体操作。
2.文件的基本操作流程
2.1基本流程
# 1. 打开文件,由应用程序向操作系统发起系统调用open(...),操作系统打开该文件,对应一块硬盘空间,并返回一个文件对象赋值给一个变量f
f=open('a.txt','r',encoding='utf-8') #默认打开模式就为r
# 2. 调用文件对象下的读/写方法,会被操作系统转换为读/写硬盘的操作
data=f.read()
# 3. 向操作系统发起关闭文件的请求,回收系统资源
f.close()2.2资源回收与with上下文管理
打开一个文件包含两部分资源:应用程序的变量和操作系统打开的文件。在操作完毕一个文件时,必须把与该文件的这两部分资源全部回收,回收方法为:
1、f.close() #回收操作系统打开的文件资源
2、del f #回收应用程序级的变量其中del f一定要发生在f.close0之后,否则就会导致操作系统打开的文件无法关闭,白白占用资源,而python自动的垃圾回收机制决定了我们无需考虑delf,这就要求我们,在操作完毕文件后,一定要记住f.close0,虽然我们如此强调,但是大多数读者还是会不由自主地忘记f.close0,考虑到这一点,python提供了with关键字来帮我们管理上下文
# 1、在执行完子代码块后,with 会自动执行f.close()
with open('a.txt','w') as f:
pass
# 2、可用用with同时打开多个文件,用逗号分隔开即可
with open('a.txt','r') as read_f,open('b.txt','w') as write_f:
data = read_f.read()
write_f.write(data)2.3指定操作文本文件的字符编码
f = open(...)是由操作系统打开文件,如果打开的是文本文件,会涉及到字符编码问题,如果没有为open指定编码,那么打开文本文件的默认编码很明显是操作系统说了算了,操作系统会用自己的默认编码去打开文件,在windows下是gbk,在linux下是utf-8。
这就用到了上节课讲的字符编码的知识:若要保证不乱码,文件以什么方式存的,就要以什么方式打开。
f = open('a.txt','r',encoding='utf-8')3.文件的操作模式
3.1控制文件读写操作的模式
r(默认的):只读
w:只写
a:只追加写
3.1.1案例1:r模式的使用
# r只读模式: 在文件不存在时则报错,文件存在文件内指针直接跳到文件开头
with open('a.txt',mode='r',encoding='utf-8') as f:
res=f.read() # 会将文件的内容由硬盘全部读入内存,赋值给res
# 小练习:实现用户认证功能
inp_name=input('请输入你的名字: ').strip()
inp_pwd=input('请输入你的密码: ').strip()
with open(r'db.txt',mode='r',encoding='utf-8') as f:
for line in f:
# 把用户输入的名字与密码与读出内容做比对
u,p=line.strip('\n').split(':')
if inp_name == u and inp_pwd == p:
print('登录成功')
break
else:
print('账号名或者密码错误')3.1.2案例二:w模式的使用
# w只写模式: 在文件不存在时会创建空文档,文件存在会清空文件,文件指针跑到文件开头
with open('b.txt',mode='w',encoding='utf-8') as f:
f.write('你好\n')
f.write('我好\n')
f.write('大家好\n')
f.write('111\n222\n333\n')
#强调:
# 1 在文件不关闭的情况下,连续的写入,后写的内容一定跟在前写内容的后面
# 2 如果重新以w模式打开文件,则会清空文件内容3.1.3案例三:a模式的使用
# a只追加写模式: 在文件不存在时会创建空文档,文件存在会将文件指针直接移动到文件末尾
with open('c.txt',mode='a',encoding='utf-8') as f:
f.write('44444\n')
f.write('55555\n')
#强调 w 模式与 a 模式的异同:
# 1 相同点:在打开的文件不关闭的情况下,连续的写入,新写的内容总会跟在前写的内容之后
# 2 不同点:以 a 模式重新打开文件,不会清空原文件内容,会将文件指针直接移动到文件末尾,新写的内容永远写在最后
# 小练习:实现注册功能:
name=input('username>>>: ').strip()
pwd=input('password>>>: ').strip()
with open('db1.txt',mode='a',encoding='utf-8') as f:
info='%s:%s\n' %(name,pwd)
f.write(info)3.1.4案例四:+模式的使用
# r+ w+ a+ :可读可写
#在平时工作中,我们只单纯使用r/w/a,要么只读,要么只写,一般不用可读可写的模式3.2控制文件读写内容的模式
大前提: tb模式均不能单独使用,必须与r/w/a之一结合使用
t(默认的):文本模式
1. 读写文件都是以字符串为单位的
2. 只能针对文本文件
3. 必须指定encoding参数
b:二进制模式:
1.读写文件都是以bytes/二进制为单位的
2. 可以针对所有文件
3. 一定不能指定encoding参数3.2.1案例一:t模式的使用
# t 模式:如果我们指定的文件打开模式为r/w/a,其实默认就是rt/wt/at
with open('a.txt',mode='rt',encoding='utf-8') as f:
res=f.read()
print(type(res)) # 输出结果为:
with open('a.txt',mode='wt',encoding='utf-8') as f:
s='abc'
f.write(s) # 写入的也必须是字符串类型
#强调:t 模式只能用于操作文本文件,无论读写,都应该以字符串为单位,而存取硬盘本质都是二进制的形式,当指定 t 模式时,内部帮我们做了编码与解码
3.2.2
# b: 读写都是以二进制位单位
with open('1.mp4',mode='rb') as f:
data=f.read()
print(type(data)) # 输出结果为:
with open('a.txt',mode='wb') as f:
msg="你好"
res=msg.encode('utf-8') # res为bytes类型
f.write(res) # 在b模式下写入文件的只能是bytes类型
#强调:b模式对比t模式
1、在操作纯文本文件方面t模式帮我们省去了编码与解码的环节,b模式则需要手动编码与解码,所以此时t模式更为方便
2、针对非文本文件(如图片、视频、音频等)只能使用b模式
# 小练习: 编写拷贝工具
src_file=input('源文件路径: ').strip()
dst_file=input('目标文件路径: ').strip()
with open(r'%s' %src_file,mode='rb') as read_f,open(r'%s' %dst_file,mode='wb') as write_f:
for line in read_f:
# print(line)
write_f.write(line) 案例二:b模式的使用
# b: 读写都是以二进制位单位
with open('1.mp4',mode='rb') as f:
data=f.read()
print(type(data)) # 输出结果为:
with open('a.txt',mode='wb') as f:
msg="你好"
res=msg.encode('utf-8') # res为bytes类型
f.write(res) # 在b模式下写入文件的只能是bytes类型
#强调:b模式对比t模式
1、在操作纯文本文件方面t模式帮我们省去了编码与解码的环节,b模式则需要手动编码与解码,所以此时t模式更为方便
2、针对非文本文件(如图片、视频、音频等)只能使用b模式
# 小练习: 编写拷贝工具
src_file=input('源文件路径: ').strip()
dst_file=input('目标文件路径: ').strip()
with open(r'%s' %src_file,mode='rb') as read_f,open(r'%s' %dst_file,mode='wb') as write_f:
for line in read_f:
# print(line)
write_f.write(line) 4.操作文件的方法
4.1重点掌握
# 读操作
f.read() # 读取所有内容,执行完该操作后,文件指针会移动到文件末尾
f.readline() # 读取一行内容,光标移动到第二行首部
f.readlines() # 读取每一行内容,存放于列表中
# 强调:
# f.read()与f.readlines()都是将内容一次性读入内容,如果内容过大会导致内存溢出,若还想将内容全读入内存,则必须分多次读入,有两种实现方式:
# 方式一
with open('a.txt',mode='rt',encoding='utf-8') as f:
for line in f:
print(line) # 同一时刻只读入一行内容到内存中
# 方式二
with open('1.mp4',mode='rb') as f:
while True:
data=f.read(1024) # 同一时刻只读入1024个Bytes到内存中
if len(data) == 0:
break
print(data)
# 写操作
f.write('1111\n222\n') # 针对文本模式的写,需要自己写换行符
f.write('1111\n222\n'.encode('utf-8')) # 针对b模式的写,需要自己写换行符
f.writelines(['333\n','444\n']) # 文件模式
f.writelines([bytes('333\n',encoding='utf-8'),'444\n'.encode('utf-8')]) #b模式4.2了解
f.readable() # 文件是否可读
f.writable() # 文件是否可读
f.closed # 文件是否关闭
f.encoding # 如果文件打开模式为b,则没有该属性
f.flush() # 立刻将文件内容从内存刷到硬盘
f.name5.主动控制文件内指针移动
#大前提:文件内指针的移动都是Bytes为单位的,唯一例外的是t模式下的read(n),n以字符为单位
with open('a.txt',mode='rt',encoding='utf-8') as f:
data=f.read(3) # 读取3个字符
with open('a.txt',mode='rb') as f:
data=f.read(3) # 读取3个Bytes
# 之前文件内指针的移动都是由读/写操作而被动触发的,若想读取文件某一特定位置的数据,则则需要用f.seek方法主动控制文件内指针的移动,详细用法如下:
# f.seek(指针移动的字节数,模式控制):
# 模式控制:
# 0: 默认的模式,该模式代表指针移动的字节数是以文件开头为参照的
# 1: 该模式代表指针移动的字节数是以当前所在的位置为参照的
# 2: 该模式代表指针移动的字节数是以文件末尾的位置为参照的
# 强调:其中0模式可以在t或者b模式使用,而1跟2模式只能在b模式下用5.1案例一:0模式
# a.txt用utf-8编码,内容如下(abc各占1个字节,中文“你好”各占3个字节)
abc你好
# 0模式的使用
with open('a.txt',mode='rt',encoding='utf-8') as f:
f.seek(3,0) # 参照文件开头移动了3个字节
print(f.tell()) # 查看当前文件指针距离文件开头的位置,输出结果为3
print(f.read()) # 从第3个字节的位置读到文件末尾,输出结果为:你好
# 注意:由于在t模式下,会将读取的内容自动解码,所以必须保证读取的内容是一个完整中文数据,否则解码失败
with open('a.txt',mode='rb') as f:
f.seek(6,0)
print(f.read().decode('utf-8')) #输出结果为: 好5.2案例二:1模式
# 1模式的使用
with open('a.txt',mode='rb') as f:
f.seek(3,1) # 从当前位置往后移动3个字节,而此时的当前位置就是文件开头
print(f.tell()) # 输出结果为:3
f.seek(4,1) # 从当前位置往后移动4个字节,而此时的当前位置为3
print(f.tell()) # 输出结果为:75.3案例三:2模式
# a.txt用utf-8编码,内容如下(abc各占1个字节,中文“你好”各占3个字节)
abc你好
# 2模式的使用
with open('a.txt',mode='rb') as f:
f.seek(0,2) # 参照文件末尾移动0个字节, 即直接跳到文件末尾
print(f.tell()) # 输出结果为:9
f.seek(-3,2) # 参照文件末尾往前移动了3个字节
print(f.read().decode('utf-8')) # 输出结果为:好
# 小练习:实现动态查看最新一条日志的效果
import time
with open('access.log',mode='rb') as f:
f.seek(0,2)
while True:
line=f.readline()
if len(line) == 0:
# 没有内容
time.sleep(0.5)
else:
print(line.decode('utf-8'),end='')6.文件的修改
# 文件a.txt内容如下
张一蛋 山东 179 49 12344234523
李二蛋 河北 163 57 13913453521
王全蛋 山西 153 62 18651433422
# 执行操作
with open('a.txt',mode='r+t',encoding='utf-8') as f:
f.seek(9)
f.write('<妇女主任>')
# 文件修改后的内容如下
张一蛋<妇女主任> 179 49 12344234523
李二蛋 河北 163 57 13913453521
王全蛋 山西 153 62 18651433422
# 强调:
# 1、硬盘空间是无法修改的,硬盘中数据的更新都是用新内容覆盖旧内容
# 2、内存中的数据是可以修改的
文件对应的是硬盘空间,硬盘不能修改对应着文件本质也不能修改,那我们看到文件的内容可以修改,是如何实现的呢?大致的思路是将硬盘中文件内容读入内存,然后在内存中修改完毕后再覆盖回硬盘具体的实现方式分为两种:
6.1文件修改方式1
# 实现思路:将文件内容发一次性全部读入内存,然后在内存中修改完毕后再覆盖写回原文件
# 优点: 在文件修改过程中同一份数据只有一份
# 缺点: 会过多地占用内存
with open('db.txt',mode='rt',encoding='utf-8') as f:
data=f.read()
with open('db.txt',mode='wt',encoding='utf-8') as f:
f.write(data.replace('kevin','SB'))6.2文件修改方式2
# 实现思路:以读的方式打开原文件,以写的方式打开一个临时文件,一行行读取原文件内容,修改完后写入临时文件...,删掉原文件,将临时文件重命名原文件名
# 优点: 不会占用过多的内存
# 缺点: 在文件修改过程中同一份数据存了两份
import os
with open('db.txt',mode='rt',encoding='utf-8') as read_f,\
open('.db.txt.swap',mode='wt',encoding='utf-8') as wrife_f:
for line in read_f:
wrife_f.write(line.replace('SB','kevin'))
os.remove('db.txt')
os.rename('.db.txt.swap','db.txt')