Kubernetes 架构基础 核心控制平面组件
Kubernetes 核心架构
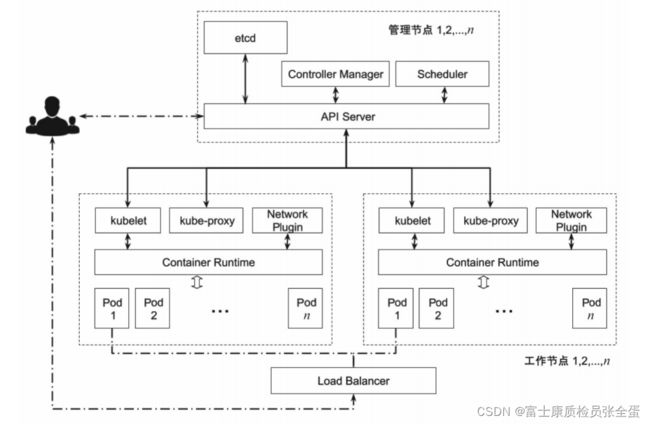
与传统的高性能计算及虚拟化云平台类似,Kubernetes 也遵循主从结构。通常将固定规模的计算节点组成一个集群,在集群中挑选数台计算节点作为管理节点(Master),其余的计算节点作为工作节点(Minion)。针对较大规模的集群,建议将独占节点作为管理节点,而针对较小规模的集群,可以将管理节点和工作节点混用。
核心控制平面组件
控制平面组件是由集群管理员部署和维护的,用来支撑平台运行的组件,Kubernetes的主要控制平面组件包括API Server、etcd、Scheduler 和Controller Manager。通常将控制平面组件安装在多个主节点上,彼此协同工作,保证平台的高可用性。
是否需要进行高可用配置,以及创建多少个高可用副本,是依据具体生产化需求而定的,具体细节会在第构建高可用集群中详述,本章将介绍单节点上控制平面组件的细节。
etcd
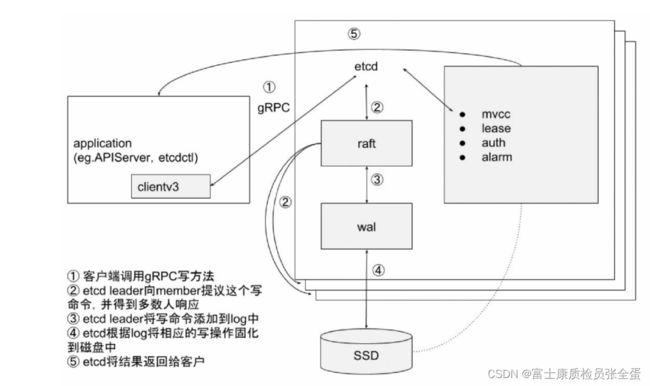
etcd 是高可用的键值对的分布式安全存储系统,用于持久化存储集群中所有的资源对象,例如集群中的Node、Service、Pod 的状态和元数据,以及配置数据等。为了持久性和高可用性,生产环境中的etcd 集群成员需分别在多个节点上运行,并定期对其进行备份。
API Server
API Server,也就是常说的kube-API Server。它承担API 的网关职责,是用户请求及其他系统组件与集群交互的唯一入口。所有资源的创建、更新和删除都需要通过调用API Server 的API 接口来完成。
- 对内,API Server 是各个模块之间数据交互的通信枢纽,提供了etcd 的封装接口API,这些API 能够让其他组件监听到集群中资源对象的增、删、改的变化。
- 对外,它充当着网关的作用,拥有完整的集群安全机制,完成客户端的身份验证(Authentication)和授权(Authorization),并对资源进行准入控制(Admission Control)。
kubernetes API Server的功能:
- 提供了集群管理的REST API接口(包括认证授权、数据校验以及集群状态变更);
- 提供其他模块之间的数据交互和通信的枢纽(其他模块通过API Server查询或修改数据,只有API Server才直接操作etcd);
- 是资源配额控制的入口;
- 拥有完备的集群安全机制.
kube-apiserver工作原理图

用户可以通过kubectl 命令行或RESTful 来调用HTTP 客户端(例如curl、wget 和浏览器)并与API Server 通信。通常,API Server 的HTTPS 安全端口默认为6443(可以通过--secure-port 参数指定),HTTP 非安全端口(可以通过--insecure-port 参数指定,默认值为8080)在新版本中已经被弃用。Kubernetes 集群可以是包含几个节点的小集群,也可以扩展到成千节点的规模。作为集群的 “大脑”,API Server 的高可用性是至关重要的。
controlPlaneEndpoint:
domain: lb.kubesphere.local
address: ""
port: 6443在图1-11中,我们通过10.2.1.4:443 或者API Server.cluster.example.io:443,就能访问到集群中的某个 API Server。具体是哪个实例,根据负载均衡器的转发策略(例如 round-robin、least-connection 等)来定。不管是用Haproxy 还是负载均衡器(软件或硬件)的方式,都需要支持Health Check,以防某API Server 所在的Master 节点宕机,其上的流量能够迅速转移到其API Server 上。
livenessProbe:
failureThreshold: 8
httpGet:
host: 192.168.100.8
path: /livez
port: 6443
scheme: HTTPS
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 15
name: kube-apiserver
readinessProbe:
failureThreshold: 3
httpGet:
host: 192.168.100.8
path: /readyz
port: 6443
scheme: HTTPS
periodSeconds: 1
timeoutSeconds: 15
图1-11 API Server 的高可用架构
[root@ks-master ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.233.0.1 443/TCP 42d
[root@ks-master ~]# kubectl get ep
NAME ENDPOINTS AGE
kubernetes 192.168.100.8:6443 42d
[root@ks-master ~]# kubectl describe svc kubernetes
Name: kubernetes
Namespace: default
Labels: component=apiserver
provider=kubernetes
Annotations:
Selector:
Type: ClusterIP
IP Families:
IP: 10.233.0.1
IPs: 10.233.0.1
Port: https 443/TCP
TargetPort: 6443/TCP
Endpoints: 192.168.100.8:6443
Session Affinity: None
Events: Pod 到API Server 的流量只会在集群内部转发,而不会被转发到外部的负载均衡器上。值得注意的是,此Endpoint 对象的Subnets Addresses 数组长度有限制,由API Server 的参数--API Server-count 来指定,默认是1。 也就是说,只需添加保留一个API Server 实例的IP 地址。如果集群中有多个API Server实例,需将此值设置为实际值,否则集群内部通过此Service 访问API Server 的所有流量只会转到一个API Server 实例上。
Controller Manager
控制器是Kubernetes 集群的自动化管理控制中心,里面包含30 多个控制器,有Pod管理的(Replication 控制器、Deployment 控制器等)、有网络管理的(Endpoints 控制器、Service 控制器等)、有存储相关的(Attachdetach 控制器等),等等。在1.2.5 节的例子中,我们已经见识到部分控制器是如何工作的。大多数控制器的工作模式雷同,都是通过API Server 监听其相应的资源对象,根据对象的状态来决定接下来的动作,使其达到预期的状态。
假设Controller Manager 出现问题导致Endpoint 对象无法及时更新,并且kube-proxy 设置的转发规则也无法及时更新,那么将造成业务数据流向异常,进而影响业务的可用性。

图1-12 Leader Election 的工作机制
[root@master ~]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
kube-apiserver-master 1/1 Running 2 3d2h
kube-controller-manager-master 1/1 Running 2 3d2h
kube-scheduler-master 1/1 Running 2 3d2h
[root@master ~]# kubectl get ep -n kube-system
NAME ENDPOINTS AGE
coredns 3d1h
etcd 192.168.100.8:2379 3d1h
kube-controller-manager-svc 192.168.100.8:10257 3d1h
kube-scheduler-svc 192.168.100.8:10259 3d1h
kubelet 192.168.100.8:10250,192.168.100.10:10250,192.168.100.8:10255 + 3 more... 3d1h
metrics-server 3d1h
openebs.io-local 3d1h
Scheduler
集群中的调度器负责Pod 在集群节点中的调度分配。我们常说Kubernetes 是一个强大的编排工具,能够提高每台机器的资源利用率,将压力分摊到各个机器上,这主要归功于调度器。调度器是拓扑和负载感知的,通过调整单个和集体的资源需求、服务质量需求、硬件和软件的策略约束、亲和力和反亲和力规范、数据位置、工作负载间的干扰、期限等,来提升集群的可用性、性能和容量。