词向量Word Embedding原理及生成方法
前言
Word Embedding是整个自然语言处理(NLP)中最常用的技术点之一,广泛应用于企业的建模实践中。我们使用Word Embedding能够将自然文本语言映射为计算机语言,然后输入到神经网络模型中学习和计算。如何更深入地理解以及快速上手生成Word Embedding呢?本文对Word Embedding原理和生成方法进行了讲解。
一、Word Embedding初探
什么是Word Embedding
一句话概述,Word Embedding即词向量,是一种函数映射关系。我们知道,在机器学习中,特征都是以数值的形式进行传递的。同样的,在NLP中,文本特征也需要被映射成数值向量。例如,我们将单词“你好”进行Word Embedding后,可以把其映射成一个5维向量:你好 ——> (0.1, 0.5, 0.3, 0.2, 0.2)。
词向量的映射过程
一般来说,我们采用“词 ——> 向量空间1 ——> 向量空间2”的映射过程实现文本单词向量化。整个映射过程可以分为两步:
1、词 ——> 向量空间1
该步骤解决把一个词转换成vector(数值向量)的问题。例如,将文本单词转换成One-Hot向量。
2、向量空间1 ——> 向量空间2
该步骤解决vector的优化问题,即在已经有了一个vector的情况下,寻求更好的办法优化它。
二、使用One-Hot和SVD求Word Embedding方法
One-Hot(词——>向量空间1)
One-Hot是目前最常见的用于提取文本特征的方法之一。本文使用One-Hot完成映射过程的第一步,即词——>向量空间1。
我们将语料库中的每一个词都作为一个特征列,如果语料库中有V个词,则有V个特征列,例如:

在这一映射过程中,One-Hot存在以下缺点:1)容易产生稀疏特征;2)容易引发维度爆炸;3)使得词间失去语义关系。
例如,按照常识,旅店(hotel)和汽车旅店(motel)间应该是具备某种相似性的,但是我们的映射结果却表明他们的向量积为0。旅店(hotel)和汽车旅店(motel)之间的相似性等于其和猫(cat)之间的相似性,这显然是不合理的。
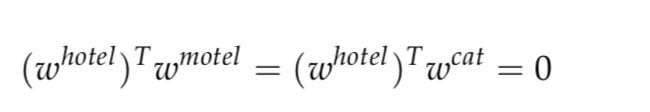
改进方向:
1)尝试将词向量映射到一个更低维的空间;
2)同时保持词向量在该低维空间中具备语义相似性,如此,越相关的词,它们的向量在这个低维空间里就能靠得越近。
SVD(向量空间1——>向量空间2)
1、如何表示出词和词间的关系
SVD,即奇异值分解(Singular Value Decomposition),是在机器学习领域广泛应用的算法,它不仅可以用于降维算法中的特征分解,也广泛应用于推荐系统,以及自然语言处理等领域,是很多机器学习算法的基石。本文使用SVD来解决vector的优化问题。
我们首先构造了一个亲和矩阵(affinity matrix),先保证在不降维的情况下,能够反映出词和词间的关系。构造亲和矩阵的方式有很多种,这里列举较常见的两种方式。
✦方式一
假设你有N篇文章,一共有M个去重词,则可以构造亲和矩阵如下:

其中每一个值表示单词在某篇文章中的出现次数。这个矩阵可以反映词的一些性质。比如一个词是“播种”,那么它可能在“农学”类的文章里出现得多一些;一个词是“电影”,那么它可能在“艺术”类的文章中出现得多一些。
✦方式二
假设我们有M个去重单词,则可构造M*M的矩阵,其中每个值表示相应的两个单词在一篇文章里共同出现的次数,例如:

2、对亲和矩阵进行分解
有了亲和矩阵,就可以对其进行SVD分解,这个目的就是进行降维了,结果如下:

我们把原亲和矩阵X(左边)分解成了右边的三部分,右边的三个部分从左到右可以这么理解:
✦U矩阵:从旧的高维向量空间到低维向量空间的一种转换关系;
✦ σ矩阵:方差矩阵。每一列表示低维空间中每一个坐标轴的信息蕴含量。方差越大,说明在该坐标轴上数据波动显著,则信息蕴含量越丰富。在降维时,我们首先考虑保留方差最大的若干个坐标轴;
✦ V矩阵:每个词向量的新表示方式。在和前两个矩阵相乘后,得到最终的词向量表示方式。
此时,右边的矩阵依然是V维的,还没有实现降维。因此,正如前文所说,我们取top k大的方差列,将U,σ和V三个矩阵按照方差从大到小的顺序排列好,这样就能得到最终的降维后的结果了:

3、SVD缺点
1)亲和矩阵的维度可能经常变,因为总有新的单词加进来,每加进来一次就要重新做SVD分解,因此这个方法不太通用;2)亲和矩阵可能很稀疏,因为很多单词并不会成对出现。
改进思路:
1)在降低稀疏性方面,可以不仅仅关注和一个单词有上下文关系的那些词;2)对于一个模型从没有见过一个单词,则考虑从上下文关系中猜到它的信息,以增加通用性。
沿着这两个思路,我们可以考虑引入CBOW和Skip-Gram,来求word embedding。
三、CBOW和Skip-Gram求Word Embedding
CBOW的全称是continuous bag of words(连续词袋模型),其本质也是通过context word(背景词)来预测一个单词是否是中心词(center word)。Skip-Gram算法则是在给定中心词(center word)的情况下,预测一个单词是否是它的上下文(context)。
本文主题是embedding,这里我们提到预测中心词和上下文的最终目的还是通过中心词和上下文,去训练得到单词语义上的关系,同时把降维做了,这样就可以得到最终想要的embedding了。
CBOW
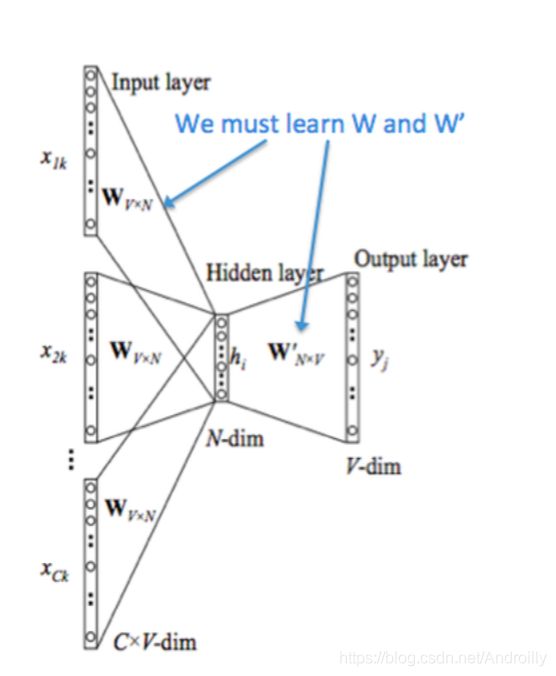
思路:
假设已知一个center word和一串context
可尝试训练一个矩阵V,它的作用是把单词映射到新的向量空间中去(这就是我们想要的embedding!)
同时还可训练一个矩阵U,它的作用是把embedding后的向量映射到概率空间,计算一个词是center word的概率
训练过程:

过程详述:
(1)假设X的C次方是中间词,且context的长度为m,那么context样本可以表示成

其中每一个元素都是一个One-Hot vector。
(2)对于这些One-Hot变量,我们希望可以用Word Embedding将它映射到一个更低维的空间。这里要补充介绍一下,Word Embedding是一种function,映射到更低维的空间是为了降低稀疏性,并保持词中的语义关系。

(3)取得embedding后输入 vector的平均值。之所以要取平均值,是因为这些单词都具有上下文联系,为了训练方便,我们可以用一个更紧凑的方法表示它们。
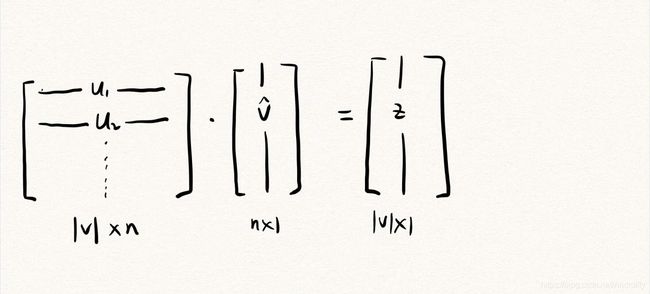

(4)这样,我们就实现了一个文本在低维空间中的平均embedding。
接下来,我们需要训练一个参数矩阵,对这个平均embedding进行计算,从而输出平均embedding中每一个词是中心词的概率。
CBOW一条龙训练过程回顾
softmax训练打分参数矩阵
交叉熵:
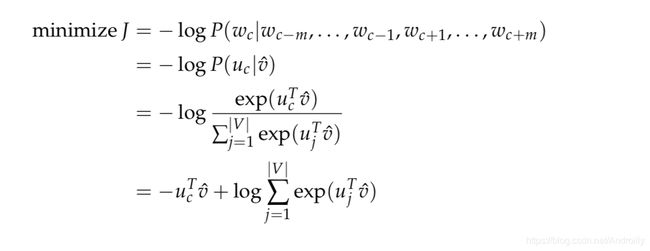
skip-gram

skip-gram 已知中心词,预测context。此处不再赘述。
总结
本文对Word Embedding原理和生成方法进行了讲解,对Word Embedding生成过程中的相关问题进行了解答,希望能帮助读者提升Word Embedding的实践效率。
如今,机器学习快速发展,并应用到众多行业场景。作为一家数据智能企业,个推在大规模机器学习和自然语言处理领域持续探索,也将Word Embedding应用到标签建模等方面。目前,个推已经构建起覆盖数千种标签的立体画像体系,为移动互联网、品牌营销、公共服务等领域的客户开展用户洞察、人口分析、数据化运营等持续提供助力。
后续个推还将继续分享在算法建模、机器学习等领域的干货内容,请保持关注哦。