数据匿名化
本文为转载焉知智能汽车内容
一、什么是数据匿名化?
数据匿名化(data anonymization)是通过消除或加密将个人与存储数据联系起来的标识符,以保护私人或敏感信息的过程。匿名化后的数据应该不能从中识别出自然人或车牌等信息。

图1:数据匿名化示意图
类似的术语还有数据脱敏、假名化、去标识化等。简而言之,数据脱敏主要是指对敏感数据处理的技术手段,一般很少出现在法律条文中。而敏感数据除了个人数据,还有军事敏感数据、国家地理信息等。假名化是匿名化的其中一种技术实现手段。去标识化和匿名化则有重合的地方,有些国家也会替换使用。但在中国,去标识化的程度低于匿名化。例如去标识化后的数据仍然属于个人信息,而匿名化后的数据则不属于个人信息。当然这个高度概括只是为了大家能初步理解,实际上涉及到法律法规的问题,都需要咬文嚼字。
例如以下法规都是与数据匿名化息息相关的:
-
《中华人民共和国个人信息保护法》
-
《汽车数据安全管理若干规定(征求意见稿)》
-
GB/T35273-2020《个人信息安全规范》
-
《信息安全技术 汽车采集数据的安全要求》
V2X和AI时代下,车载数据与互联网及云端交互是大势所趋。而从社会人文及管理等角度出发,个人隐私数据的保护和管理则是这个趋势下的必然要求。因此数据匿名化在汽车领域出现得越来越多,也越来越受重视。
二、数据匿名化的好处和坏处
好处1: 让数据的非敏感部分仍然能比广泛利用
相比直接删除敏感数据,匿名化可以保留相关信息供其他功能应用。例如买家的私人生日信息可以匿名化处理,但是他们的生日总体分布可以保留,供产品开发部门分析不同年龄层消费者对产品的喜爱程度。
好处2:避免数据滥用和隐私数据泄露
无论多么值得信任的员工,都不能总是保证他们的意图。为了防止内部人员和外部攻击者之间可能的合作,数据匿名化可以增强信息安全性。
好处3:强化数据管理和一致性
统一、准确的数据能够支持应用程序和服务的同时,保护大数据分析和隐私。它通过提供受保护的数据用于产生新的市场价值,为数字转型提供助力
当然数据匿名化的最大坏处就是损害数据内涵的丰富程度。
收集匿名数据并从数据库中删除身份,将限制从结果中提取有意义信息的能力。例如,匿名信息不能用于定位目的或个性化的用户体验。
因此很多时候我们并不想数据实现真正完全的匿名化,只是希望数据对“一般人”和“一般情况下”匿名化。例如正常情况下,智能驾驶车辆摄像头收集的人脸数据和车牌号数据,从个人隐私的角度,都希望做到匿名化。但是如果这个摄像头刚好拍到了犯罪分子的脸和犯罪经过又或者拍到交通肇事逃逸的车牌号,我们则希望能得到原始数据,助于破案。
 图2:数据匿名化背后的天平
图2:数据匿名化背后的天平
匿名化背后是信息保护和数据可用性之间的天平。天平在什么时候该往哪边调整,是一个社会、哲学和文化等复杂系统问题。但从技术实施手段上来看,数据加密方法无疑为调整天平增加了自由度。加密后的数据能对“一般人”和“一般情况”匿名化。而重点保护和管理“密钥”等关键安全数据的权限,就可以控制反匿名化的范围和影响。例如刚才例子中,一种平衡方法就是摄像头数据都要经过加密处理后存储和传输,确保隐私,但是在公安部等几个部门及相关个人联合授权下可以允许数据反匿名化还原。
三、数据匿名化的几种技术手段
技术1: 遮蔽 Masking
数据掩蔽指的是披露具有修改过的数值的数据,可以通过创建一个数据库的镜像并实施改变策略来完成的,比如常见的字符替换和脸部遮蔽等。例如,一个人的生日日期可以被 //****的符号取代。又或者图像数据中的人脸用固定图形遮蔽。

技术2: 假名化 Pseudonymization
假名化就是用假的标识符或假名来代替私人标识符,例如用“鲁迅”标识符来替换“周树人”的标识符。它可以保持统计的精确性和数据的保密性,允许改变后的数据用于创建、训练、测试和分析,同时保持数据的隐私。
技术3: 泛化 Generalization
泛化包括有目的地排除一些数据,使其不那么容易识别。数据可以被修改成一系列的范围或一个具有合理边界的大区域。例如,一个地址的门牌号可以被删除使其不能从中识别处自然人,但街道的名称可以保留。泛化也可以理解为在保持数据准确性的前提下,删除一些标识符。
技术4: 混排 Scrambling
数据混排就是一个对数据集进行洗牌以重新排列的过程。这样一来,原始数据库和结果记录之间就没有任何相似之处了。这种操作一般就是调乱数据库中的“列”,例如将个人的年龄、生日日期、月份各列打乱。
技术5: 加扰 Perturbation
数据扰动通过应用圆周率方法或者添加随机噪声,对初始数据集进行小幅修改。这组数值必须与扰动成正比。一个小的基数可能会导致匿名化效果不佳,而一个广泛的基数会降低数据集的效用。例如,年龄或门牌号等数值可以加入5为基数的随机数值,而人脸图像也可以打上随机噪声生成的马赛克。

图4:人脸数据加扰示意图
四、一个用于V2X的匿名化方案例子
在V2X的应用场景中,涉及到车辆与车辆(V2V)的通讯。通讯传输中肯定不是随便一辆车都能与其他车通讯,否则这样黑客就很容易假冒车辆批量攻击正常行驶的车辆。其中不可避免地需要应用到身份鉴权和数据加密技术,目前最主流的就是应用PKI非对称加密体制。
这里简单说下PKI。在这机制下密钥都是一对一对地生成的。一对密钥包含一把公钥和一把私钥,两者之间有内在的数学关系,实现了公钥加密的信息只能用对应的私钥来解密,而私钥加密的信息只能用对应公钥来解密。而“公”是公开给大家所见的,“私”指只有自己知道。虽然公钥可以公开,但需要防止有人假冒,所以需要有公信力的证书颁发机构(CA)来管理密钥信息和证书。CA主要作用就是证明这把公钥真的是属于这辆车的。
而在CA管理密钥和证书过程中,需要将这些信息和具体车辆绑定,一一对应。其中车辆的标识可以采用车辆唯一标识码(VIN)和车牌号。但出于个人信息保护的要求,VIN和车牌号这样的信息并不能随意泄露或体现在终端车辆的数字证书之中。这就是数据匿名化的需求。在总体架构上,可以如下图所示,在根CA和从属车辆管理CA之间加入假名化CA。
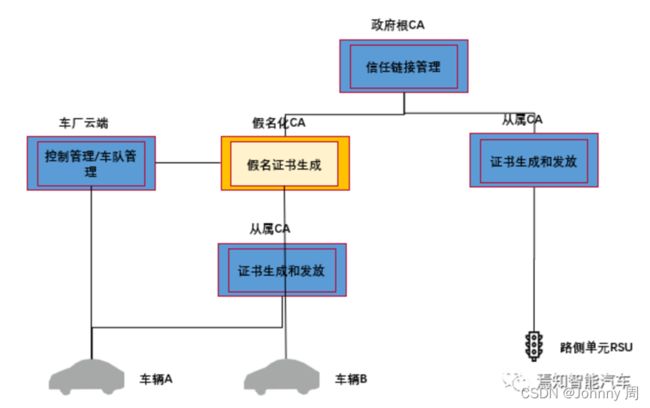
图5:V2X的PKI总体架构
假名化CA可以对接根CA和车厂云端,验证车辆个人信息之后,再为对应车辆生成一个假名化的唯一标识,也就是每辆车都通过该CA生成一个假名。从属CA再基于假名生成数字证书及公私密钥对,用于V2V的鉴权和加密。
与从属CA类似,假名化CA为了增强信息安全能力,也涉及到假名的生命周期管理。一种抽象化的生命周期管理框架如下图所示。
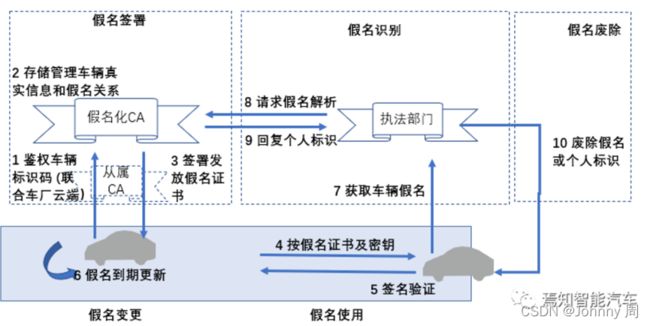
1.车辆通过VIN和车牌号等身份标识,途经从属CA,向假名化CA申请证书
2.假名化CA在鉴权车辆信息外,还会存储和管理车辆真实识别信息和生成的假名的关系数据库
3.4.5. 将基于假名的数字证书发放给车辆后,车辆利用假名化数字证书及公私密钥对,完成V2V的通讯鉴权和加密
6.数字证书到期后,重新申请新的假名化数字证书
7.8.9.在特殊情况下,执法部门可以通过车辆假名,向假名化CA申请获取车辆的真实标识
10.在特殊情况下,执法部门也可以废除对应车辆的假名和数字证书等
这种方案通过对假名化CA及执法部门的集中监管,可以在保证信息安全的前提下,维持假名与真实标识信息的可逆化,赋能了特殊情况下的数据可用性。
五、写在最后
数据匿名化在汽车新四化的时代背景下,还有很多应用场景。例如特斯拉牵起的“影子模式”或者“数据驱动改进”等方案,都会通过车端传感器采集的数据上传云端,用于优化训练神经网络模型。其中摄像头等传感器采集的数据也会包含诸如人脸、车牌等个人标识,数据也必须进行匿名化处理后才能进一步传输。而匿名化后的数据还需要保留相应特征,例如车牌信息的形状、颜色等,以保证其对神经网络模型的有效性。这就对汽车数据匿名化提出了更高的算法要求。
智能驾驶汽车被誉为车轮上的数据中心,产生、收集和分析大量复杂的数据,这使得数据的隐私和安全成为用户关注的问题。希望在政府、立法等综合管理框架下,数据匿名化技术能在保护个人信息的同时,还能保障数据的可用性,以促进智能驾驶汽车本身的发展。
参考来源:
-
Anonymization,https://www.imperva.com/learn/data-security/anonymization/
-
Data Anonymization,https://corporatefinanceinstitute.com/resources/knowledge/other/data-anonymization/
-
3 Types of Data Anonymization Techniques and Tools to Consider,https://www.techfunnel.com/information-technology/3-types-of-data-anonymization-techniques-and-tools-to-consider/
-
Accountable De-anonymization in V2X Communication,https://helda.helsinki.fi/bitstream/handle/10138/234249/Accountable_De-anonymization_in_V2X_Communication.pdf?sequence=2