R-CNN史上最全讲解
文章目录
- 一:初识R-CNN
-
-
- [网络结构]
-
- 二:训练步骤
-
- 1.RP的确定
- 2.模型pre-training
- 3.Fine-Tunning
- 4.提取并保存RP的特征向量
- 5.SVM的训练
- 6.bbox regression的训练
- 三:测试步骤
-
- step1:Region proposal的确定
- step2:RP的Features提取
- step3:SVM分类
- step4:BoundingBox-Regression
- step5:Non-maximum suppression处理
- 四:R-CNN存在的问题
一:初识R-CNN
R-CNN系列论文(R-CNN,fast-RCNN,faster-RCNN)是使用深度学习进行物体检测的鼻祖论文,其中fast-RCNN 以及faster-RCNN都是沿袭R-CNN的思路。
R-CNN全称region with CNN features,其实它的名字就是一个很好的解释。用CNN提取出Region Proposals中的featues,然后进行SVM分类与bbox的回归。
[网络结构]
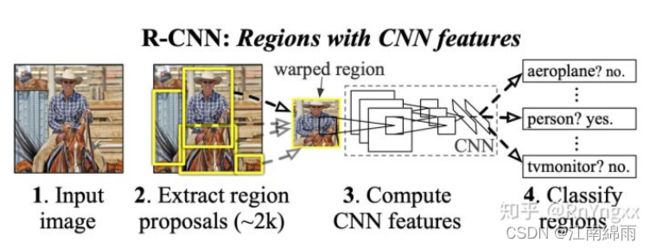
接下来我从 训练阶段 和 测试阶段 分别讲解R-CNN中的核心思路。
二:训练步骤
1.RP的确定
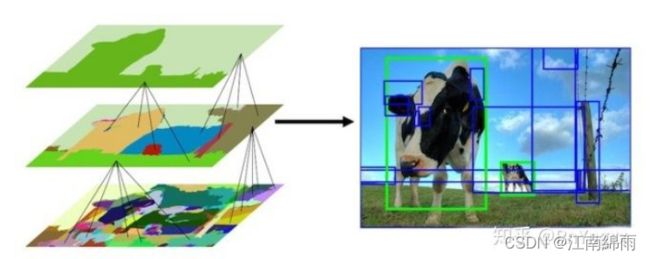
首先介绍一下Selective Search算法,训练过程中用于从输入图像中搜索出2000个Region Proposal。Selective Search算法主要步骤:
- 使用一种过分割手段,将图像分割成小区域 (1k~2k 个)
- 计算所有邻近区域之间的相似性,包括颜色、纹理、尺度等
- 将相似度比较高的区域合并到一起
- 计算合并区域和临近区域的相似度
- 重复3、4过程,直到整个图片变成一个区域
在每次迭代中,形成更大的区域并将其添加到区域提议列表中。这种自下而上的方式可以创建从小到大的不同scale的Region Proposal,如图所示:
2.模型pre-training
在实际测试的时候,模型需要通过CNN提取出RP中的特征,用于后面的分类与回归。所以,如何训练好CNN成为重中之重。
由于物体标签训练数据少,如果要直接采用随机初始化CNN参数的方法是不足以从零开始训练出一个好的CNN模型。基于此,采用有监督的预训练,使用一个大的数据集(ImageNet ILSVC 2012)来训练AlexNet,得到一个1000分类的预训练(Pre-trained)模型。
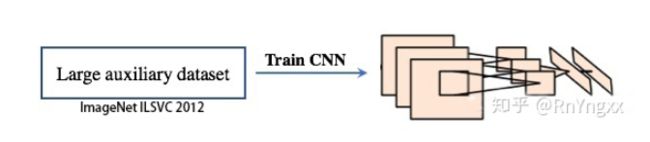
3.Fine-Tunning
因为R-CNN模型实际测试时,是通过CNN对VOC测试集中每张输入图像上搜索到的2000个Region Proposal提取特征的。而RP大小都不相同,且AlexNet要求输入图像大小是227×227,所以需要对RP进行resize操作,将它们变形为227×227。变形之前,我们先在候选框周围加上16的padding,再进行各向异性缩放。 这种形变使得mAp提高了3到5个百分点。
而原CNN模型针对ImageNet数据集且无变形的图像来提取特征,现在却是针对VOC检测数据集且变形的图像来提取特征。所以,为了让我们的CNN适应新的任务(即检测任务)和新的领域(变形后的推荐窗口),需要对CNN做特定领域的参数调优,也就是fine-tunning。用的是从每张VOC训练图像中搜索到的Region Proposal进行微调的。
( 备注:还有一个原因,如果不针对特定任务进行fine-tuning,而是把CNN当做特征提取器,卷积层所学到的特征其实就是基础的共享特征提取层,就类似于SIFT算法一样,可以用于提取各种图片的特征,而f6、f7所学习到的特征是用于针对特定任务的特征。打个比方:对于人脸性别识别来说,一个CNN模型前面的卷积层所学习到的特征就类似于学习人脸共性特征,然后全连接层所学习的特征就是针对性别分类的特征了)
首先对 PASCAL VOC数据集 进行Selective Search,搜索到2000个Region Proposal对Pre-trained模型进行fine-tuning。将原来预训练模型最后的1000-way的全连接层(分类层)换成21-way的分类层(20类物体+背景),然后计算每个region proposal和ground truth 的IoU,对于IoU>0.5的region proposal被视为正样本,否则为负样本(即背景)。另外,由于对于一张图片的多有候选区域来说,负样本是远远大于正样本数,所以需要将正样本进行上采样来保证样本分布均衡。在每次迭代的过程中,选择层次采样,每个mini-batch中采样两张图像,从中随机选取32个正样本和96个负样本组成一个mini-batch(128,正负比:1:3)。我们使用0.001的学习率和SGD来进行训练。

4.提取并保存RP的特征向量
提取特征的CNN网络经过了预训练和微调后不再训练,就固定不变了,只单纯的作为一个提特征的工具了。虽然文中训练了CNN网络对region proposal进行分类,但是实际中,这个CNN的作用只是提取每个region proposal的feature。
所以,我们输入VOC训练数据集,SS搜索出2000个RP后输入进CNN进行前向传播,然后保存AlexNet的FC7层4096维的features,以供后续的SVM分类使用。
5.SVM的训练
作者使用SVM进行分类。对于每一类都会训练一个SVM分类器,所以共有N(21)个分类器,我们来看一下是如何训练和使用SVM分类器的。

在SVM分类过程中,IOU<0.3被作为负例,ground-truth(即完全框住了物体,默认IOU>0.7时)是正例,其余的全部丢弃。然后SVM分类器也会输出一个预测的labels,然后用labels和truth labels比较,计算出loss,然后训练SVM。
其中,有一个细节,就是SVM由于是小样本训练,所以会存在负样本远多于正样本的情况。针对这种情况,作者使用了hard negative mining方法(初始时用所有样本训练,但是这样负样本可能远多王正样本,经过一轮训练后将score最高即最容易被误判的负样本加入新的样本训练集,进行训练,重复以上步骤至达到停止条件比如分类器性能不再提升),使得SVM适用于小样本训练,在样本不平衡时依然可以做到不会发生过拟合。
作者为什么要Hard Negatives?因为,负样本数目巨大,其中Pos样本数目占的比例特别低,负样本太多,直接导致优化过程很慢,因为很多负样本远离分界面对于优化几乎没有帮助(SVM分类最大间隔,只有支持向量比较有用)。Data-minig的作用就是去掉那些对优化作用很小的Easy-examples保留靠近分界面的Hard-examples。
前方核能:
有人会好奇为什么要专门使用SVM分类,而不是CNN最后的21层softmax层分类?这里我来重点讲解一下,仅个人理解:
细心的人会发现,之前在训练CNN提取特征时,设置的IOU是0.5以上为正样本,小于0.5的是负样本。但在SVM分类中,只有bbox完全包围了物体(也可以理解为IOU>0.7时)才是正样本,IOU小于0.3的是负样本。前者是大样本训练,后者是小样本训练。对于CNN的训练,需要大量的数据,不然容易过拟合,所以设置的阈值较低,比如一个bounding box可能只包含物体的一部分,那么我也把它标注为正样本,用于训练cnn;然而svm训练的时候,因为svm适用于少样本训练,所以对于训练样本数据的IOU要求比较严格,我们只有当bounding box把整个物体都包含进去了(IOU>0.7),我们才把它标注为物体类别,IOU<0.3的标注为负样本,然后训练svm。就因为这个特点,只能用低IOU来softmax分类,那么很可能导致最后的bbox框位置不准确(如果bbox和GT差距太大,通过线性回归会无法收敛),同时类识别精度也不高,根据实验MAP会下降几个百分点。如果硬要提高IOU,又会导致训练数据样本太少,发生过拟合。这就是真正的"鱼和熊掌不可得兼"啊,其实罪魁祸首就是Small VOC的训练量太少了,限制了太多优化操作。故最后选择了SVM完成分类,CNN只用来提取特征。
这样做后,精度也会有很大的提升,同时对于后面的bbox回归准确度也提高了。
6.bbox regression的训练
与GT的IOU>0.6的RP作为正样本,做回归训练。具体做法请看這篇文章
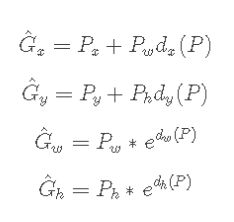
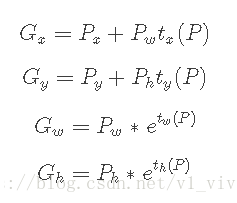
其实就是训练 d d d 矩阵向 t t t 矩阵靠齐的过程。
三:测试步骤
讲解完了R-CNN的训练过程,现在我们来讲一讲测试过程。我分以下五个步骤依次进行讲解:
step1:Region proposal的确定
VOC测试图像输入后,利用SS搜索方法,根据相似度从大到小排序,筛选出2000个region proposals 。
step2:RP的Features提取
将RP通过resize成227×227,然后分别输入进CNN特征提取网络,得到了2000个4096维features。
step3:SVM分类
将(2000,4096)维矩阵输入进SVM分类器中,最终得到(2000,21)矩阵。每一行的21个列值,分别代表了这个RP属于每一个类的可能性。通过提前设置好的backgroud阈值 α α α 和所属于类的阈值 β β β,筛选出满足条件的 m m m 个RP区域。
step4:BoundingBox-Regression
将(2000,4096)维矩阵输入进 (4096,4)的回归矩阵 d d d 中,最后输出(2000,4)偏移矩阵。代表RP中心点的位置偏移 和 bbox的尺寸变换。
将SVM筛选出的 m m m 个RP区域对应的特征向量,组成(m,2000)矩阵 代入 (2000,4)的回归矩阵 d d d 中,最后输出(m,4)偏移矩阵。
step5:Non-maximum suppression处理
只画出SVM筛选出的 m m m 个RP区域的修正后的检测框。考虑到bbox的大量累赘重叠,进行非极大值抑制(NMS),得到最终检测结果。
附上每一步处理的示例图,如下:

四:R-CNN存在的问题
- 训练时间长:主要原因是分阶段多次训练,而且对于每个region proposal都要单独计算一次feature map,导致整体的时间变长。
- 占用空间大:每个region proposal的feature map都要写入硬盘中保存,以供后续的步骤使用。
- multi-stage:文章中提出的模型包括多个模块,每个模块都是相互独立的,训练也是分开的。这会导致精度不高,因为整体没有一个训练联动性,都是不共享分割训练的,自然最重要的CNN特征提取也不会做的太好。
- 测试时间长,由于不共享计算,所以对于test image,也要为每个proposal单独计算一次feature map,因此测试时间也很长。
至此我对R-CNN全部流程与细节,进行了深度讲解,希望对大家有所帮助,有不懂的地方或者建议,欢迎大家在下方留言评论。
我是努力在CV泥潭中摸爬滚打的江南咸鱼,我们一起努力,不留遗憾!