java入门笔记——老王笔记--IT隐匿者
Java笔记
类只是为所有的对象定义了抽象的属性与行为。
(1)Java中finally与return的执行顺序
在 Java 的异常处理中,try、catch 和 finally 是按顺序执行的。如果 try 中没有异常,则顺序为 try→finally,如果 try 中有异常,则顺序为 try→catch→finally。但是当 try、catch、finally 中加入 return 之后,return 和 finally 的执行顺序让很多人混淆不清。下面来分别说明一下。
1. try 和 catch 中带有 return
1)try 中带有 return
public class tryDemo {
public static int show() {
try {
return 1; }
finally {
System.out.println("执行finally模块");
}
}
public static void main(String args[]) {
System.out.println(show());
}
}
输出结果如下:
执行finally模块
1
2)try 和 catch 中都带有 return
public class tryDemo {
public static int show() {
try {
int a = 8 / 0;
return 1; }
catch (Exception e) {
return 2; }
finally {
System.out.println("执行finally模块"); }
}
public static void main(String args[]) {
System.out.println(show());
}
}
输出结果为:
执行finally模块
2
当 try 代码块或者 catch 代码块中有 return 时,finally 中的代码总会被执行,且 finally 语句 return 返回之前执行。
注意:可以使用编译器的 Debug 功能查看详细过程。如果不了解如何使用 Debug 功能可参考《Java Eclipse如何调试代码》一节。
2. finally 中带有 return
public class tryDemo {
public static int show() {
try {
int a = 8 / 0;
return 1; }
catch (Exception e)
{
return 2;
}
finally {
System.out.println("执行finally模块");
return 0;
}
}
public static void main(String args[]) {
System.out.println(show());
}
}
输出结果如下:
执行finally模块
0
当 finally 有返回值时,会直接返回该值,不会去返回 try 代码块或者 catch 代码块中的返回值。
注意:finally 代码块中最好不要包含 return 语句,否则程序会提前退出。
3. finally 中改变返回值
下面先来看 try 代码块或者 catch 代码块中的返回值是普通变量时,代码如下:
public class tryDemo {
public static int show() {
int result = 0;
try {
return result; }
finally {
System.out.println("执行finally模块");
result = 1; }
}
public static void main(String args[]) {
System.out.println(show()); }
}
输出结果为:
执行finally模块
0
由输出结果可以看出,在 finally 代码块中改变返回值并不会改变最后返回的内容。
当返回值类型是引用类型时,结果也是一样的,代码如下:
public class tryDemo {
public static Object show() {
Object obj = new Object();
try {
return obj; }
finally {
System.out.println("执行finally模块");
obj = null;
}
}
public static void main(String args[]) {
System.out.println(show()); }}
输出结果为:
执行finally模块
java.lang.Object@15db9742
当 try 代码块或 catch 代码块中的 return 返回值类型为普通变量或引用变量时,即使在后面 finally 代码块中对返回值的变量重新赋值,也不会影响最后返回的值。
总结为以下几条:
- 当 try 代码块和 catch 代码块中有 return 语句时,finally 仍然会被执行。
- 执行 try 代码块或 catch 代码块中的 return 语句之前,都会先执行 finally 语句。
- 无论在 finally 代码块中是否修改返回值,返回值都不会改变,仍然是执行 finally 代码块之前的值。
- finally 代码块中的 return 语句一定会执行。
(2)为什么使用向上转型而不直接创建子类对象?
初学者在学习向上转型可能会很难理解,向上转型并不能调用子类特有属性和方法,我们必须先生成子类实例再赋值给父类引用(向上转型),然后将父类引用向下强制转换给子类引用(向下转型),这样才能调用子类中的所有成员。这看起来像是多次一举,还不如直接创建子类实例。
随着技术的提升,我们在学习其它开源项目时会发现很多地方都用了向上转型和向下转型的技术。本节将带大家了解向上转型和向下转型的意义及使用场景。
例 1
定义父类 Animal,代码如下:
public class Animal {
public void sleep() {
System.out.println("小动物在睡觉"); }
public static void doSleep(Animal animal) {
// 此时的参数是父类对象,但是实际调用时传递的是子类对象,就是向上转型。
//为何doSleep(Animal animal),为何参数是Animal,因为想用向上转型(Animal animal=new Cat();)
//向下转型:Cat cat=(Cat)new Animal();
//如果不用向上转型,那就得写两个doSleep办法,一个参数为Cat cat 一个参数为Dog dog,那代码就重复了
//向上转型更好的体现了类的多态性
animal.sleep(); }
public static void main(String[] args) {
Animal animal1=new Cat();//向上转型
Animal animal2=new Dog();//向上转型
animal.doSleep(animal1);
animal.doSleep(animal2);
}
}
子类 Cat 代码如下:
public class Cat extends Animal {
@Override
public void sleep() {
System.out.println("猫正在睡觉"); }}
子类 Dog 代码如下:
public class Dog extends Animal {
@Override public void sleep() {
System.out.println("狗正在睡觉");
}}
输出结果为:
猫正在睡觉
狗正在睡觉
如果不用向上转型则必须写两个 doSleep 方法,一个传递 Cat 类对象,一个传递 Dog 类对象。这还是两个子类,如果有多个子类就要写很多相同的方法,造成重复。可以看出向上转型更好的体现了类的多态性,增强了程序的间接性以及提高了代码的可扩展性。当需要用到子类特有的方法时可以向下转型,这也就是为什么要向下转型。
比如设计一个父类 FileRead 用来读取文件,ExcelRead 类和 WordRead 类继承 FileRead 类。在使用程序的时候,往往事先不知道我们要读入的是 Excel 还是 Word。所以我们向上转型用父类去接收,然后在父类中实现自动绑定,这样无论你传进来的是 Excel 还是 Word 就都能够完成文件读取。
总结如下:
- 把子类对象直接赋给父类引用是向上转型,向上转型自动转换。如 Father father = new Son();
- 指向子类对象的父类引用赋给子类引用是向下转型,要强制转换。使用向下转型,必须先向上转型,为了安全可以用 instanceof 运算符判断。 如 father 是一个指向子类对象的父类引用,把 father 赋给子类引用 son,即
Son son =(Son)father;。其中 father 前面的(Son)必须添加,进行强制转换。 - 向上转型不能使用子类特有的属性和方法,只能引用父类的属性和方法,但是子类重写父类的方法是有效的。
- 向上转型时会优先使用子类中重写父类的方法,如例 1 中调用的 sleep 方法。
- 向上转型的作用是减少重复代码,可以将父类作为参数,这样使代码变得简洁,也更好的体现了多态。
(3)Java抽象类和接口的区别
1)抽象类
在 Java 中,被关键字 abstract 修饰的类称为抽象类;被 abstract 修饰的方法称为抽象方法,抽象方法只有方法声明没有方法体。
抽象类有以下几个特点:
- 抽象类不能被实例化,只能被继承。
- 包含抽象方法的类一定是抽象类,但抽象类不一定包含抽象方法(抽象类可以包含普通方法)。
- 抽象方法的权限修饰符只能为 public、protected 或 default,默认情况下为 public。
- 一个类继承于一个抽象类,则子类必须实现抽象类的抽象方法,如果子类没有实现父类的抽象方法,那子类必须定义为抽象类。
- 抽象类可以包含属性、方法、构造方法,但构造方法不能用来实例化对象,只能被子类调用。
2)接口
接口可以看成是一种特殊的类,只能用 interface 关键字修饰。
Java 中的接口具有以下几个特点:
- 接口中可以包含变量和方法,变量被隐式指定为 public static final,方法被隐式指定为 public abstract(JDK 1.8 之前)。
- 接口支持多继承,即一个接口可以继承(extends)多个接口,间接解决了 Java 中类不能多继承的问题。
- 一个类可以同时实现多个接口,一个类实现某个接口则必须实现该接口中的抽象方法,否则该类必须被定义为抽象类。
3)抽象类和接口的区别
接口和抽象类很像,它们都具有如下特征。
- 接口和抽象类都不能被实例化,主要用于被其他类实现和继承。
- 接口和抽象类都可以包含抽象方法,实现接口或继承抽象类的普通子类都必须实现这些抽象方法。
但接口和抽象类之间的差别非常大,这种差别主要体现在二者设计目的上。下面具体分析二者的差别。
接口作为系统与外界交互的窗口,接口体现的是一种规范。对于接口的实现者而言,接口规定了实现者必须向外提供哪些服务(以方法的形式来提供);对于接口的调用者而言,接口规定了调用者可以调用哪些服务,以及如何调用这些服务(就是如何来调用方法)。当在一个程序中使用接口时,接口是多个模块间的耦合标准;当在多个应用程序之间使用接口时,接口是多个程序之间的通信标准。
从某种程度上来看,接口类似于整个系统的“总纲”,它制定了系统各模块应该遵循的标准,因此一个系统中的接口不应该经常改变。一旦接口被改变,对整个系统甚至其他系统的影响将是辐射式的,会导致系统中大部分类都需要改写。
抽象类则不一样,抽象类作为系统中多个子类的共同父类,它所体现的是一种模板式设计。抽象类作为多个子类的抽象父类,可以被当成系统实现过程中的中间产品,这个中间产品已经实现了系统的部分功能(那些已经提供实现的方法),但这个产品依然不能当成最终产品,必须有更进一步的完善,这种完善可能有几种不同方式。
除此之外,接口和抽象类在用法上也存在差别,如下表所示:
| 参数 | 抽象类 | 接口 |
|---|---|---|
| 实现 | 子类使用 extends 关键字来继承抽象类,如果子类不是抽象类,则需要提供抽象类中所有声明的方法的实现。 | 子类使用 implements 关键字来实现接口,需要提供接口中所有声明的方法的实现。 |
| 访问修饰符 | 可以用 public、protected 和 default 修饰 | 默认修饰符是 public,不能使用其它修饰符 |
| 方法 | 完全可以包含普通方法 | 只能包含抽象方法、静态方法、默认方法和私有方法,不能为普通方法提供方法实现 |
| 变量 | 既可以定义普通成员变量,也可以定义静态常量 | 只能定义静态常量,不能定义普通成员变量 |
| 构造方法 | 抽象类里的构造方法并不是用于创建对象,而是让其子类调用这些构造方法来完成属于抽象类的初始化操作 | 没有构造方法 |
| 初始化块 | 可以包含初始化块 | 不能包含初始化块 |
| main 方法 | 可以有 main 方法,并且能运行 | 没有 main 方法 |
| 与普通Java类的区别 | 抽象类不能实例化,除此之外和普通 Java 类没有任何区别 | 是完全不同的类型 |
| 运行速度 | 比接口运行速度要快 | 需要时间去寻找在类种实现的方法,所以运行速度稍微有点慢 |
一个类最多只能有一个直接父类,包括抽象类,但一个类可以直接实现多个接口,通过实现多个接口可以弥补 Java 单继承的不足。
4)抽象类和接口的应用场景
抽象类的应用场景:
- 父类只知道其子类应该包含怎样的方法,不能准确知道这些子类如何实现这些方法的情况下,使用抽象类。
- 从多个具有相同特征的类中抽象出一个抽象类,以这个抽象类作为子类的模板,从而避免了子类设计的随意性。
接口的应用场景:
- 一般情况下,实现类和它的抽象类之前具有 “is-a” 的关系,但是如果我们想达到同样的目的,但是又不存在这种关系时,使用接口。
- 由于 Java 中单继承的特性,导致一个类只能继承一个类,但是可以实现一个或多个接口,此时可以使用接口。
什么时候使用抽象类和接口:
- 如果拥有一些方法并且想让它们有默认实现,则使用抽象类。
- 如果想实现多重继承,那么必须使用接口。因为 Java 不支持多继承,子类不能继承多个类,但可以实现多个接口,因此可以使用接口。
- 如果基本功能在不断改变,那么就需要使用抽象类。如果使用接口并不断需要改变基本功能,那么就需要改变所有实现了该接口的类。
(4)Java File类(文件操作类)详解
在 Java 中,File 类是 java.io 包中唯一代表磁盘文件本身的对象,也就是说,如果希望在程序中操作文件和目录,则都可以通过 File 类来完成。File 类定义了一些方法来操作文件,如新建、删除、重命名文件和目录等。
File 类不能访问文件内容本身,如果需要访问文件内容本身,则需要使用输入/输出流。
File 类提供了如下三种形式构造方法。
- File(String path):如果 path 是实际存在的路径,则该 File 对象表示的是目录;如果 path 是文件名,则该 File 对象表示的是文件。
- File(String path, String name):path 是路径名,name 是文件名。
- File(File dir, String name):dir 是路径对象,name 是文件名。
使用任意一个构造方法都可以创建一个 File 对象,然后调用其提供的方法对文件进行操作。在表 1 中列出了 File 类的常用方法及说明。
| 方法名称 | 说明 |
|---|---|
| boolean canRead() | 测试应用程序是否能从指定的文件中进行读取 |
| boolean canWrite() | 测试应用程序是否能写当前文件 |
| boolean delete() | 删除当前对象指定的文件 |
| boolean exists() | 测试当前 File 是否存在 |
| String getAbsolutePath() | 返回由该对象表示的文件的绝对路径名 |
| String getName() | 返回表示当前对象的文件名或路径名(如果是路径,则返回最后一级子路径名) |
| String getParent() | 返回当前 File 对象所对应目录(最后一级子目录)的父目录名 |
| boolean isAbsolute() | 测试当前 File 对象表示的文件是否为一个绝对路径名。该方法消除了不同平台的差异,可以直接判断 file 对象是否为绝对路径。在 UNIX/Linux/BSD 等系统上,如果路径名开头是一条斜线/,则表明该 File 对象对应一个绝对路径;在 Windows 等系统上,如果路径开头是盘符,则说明它是一个绝对路径。 |
| boolean isDirectory() | 测试当前 File 对象表示的文件是否为一个路径 |
| boolean isFile() | 测试当前 File 对象表示的文件是否为一个“普通”文件 |
| long lastModified() | 返回当前 File 对象表示的文件最后修改的时间 |
| long length() | 返回当前 File 对象表示的文件长度 |
| String[] list() | 返回当前 File 对象指定的路径文件列表 |
| String[] list(FilenameFilter) | 返回当前 File 对象指定的目录中满足指定过滤器的文件列表 |
| boolean mkdir() | 创建一个目录,它的路径名由当前 File 对象指定 |
| boolean mkdirs() | 创建一个目录,它的路径名由当前 File 对象指定 |
| boolean renameTo(File) | 将当前 File 对象指定的文件更名为给定参数 File 指定的路径名 |
File 类中有以下两个常用常量:
- public static final String pathSeparator:指的是分隔连续多个路径字符串的分隔符,Windows 下指
;。例如java -cp test.jar;abc.jar HelloWorld。 - public static final String separator:用来分隔同一个路径字符串中的目录的,Windows 下指
/。例如C:/Program Files/Common Files。
注意:可以看到 File 类的常量定义的命名规则不符合标准命名规则,常量名没有全部大写,这是因为 Java 的发展经过了一段相当长的时间,而命名规范也是逐步形成的,File 类出现较早,所以当时并没有对命名规范有严格的要求,这些都属于 Java 的历史遗留问题。
Windows 的路径分隔符使用反斜线“\”,而 Java 程序中的反斜线表示转义字符,所以如果需要在 Windows 的路径下包括反斜线,则应该使用两条反斜线或直接使用斜线“/”也可以。Java 程序支持将斜线当成平台无关的路径分隔符。
假设在 Windows 操作系统中有一文件 D:\javaspace\hello.java,在 Java 中使用的时候,其路径的写法应该为 D:/javaspace/hello.java 或者 D:\\javaspace\\hello.java。
1)获取文件属性
在 Java 中获取文件属性信息的第一步是先创建一个 File 类对象并指向一个已存在的文件, 然后调用表 1 中的方法进行操作。
假设有一个文件位于 C:\windows\notepad.exe。编写 Java 程序获取并显示该文件的长度、是否可写、最后修改日期以及文件路径等属性信息。实现代码如下:
public class Test02 {
public static void main(String[] args) {
String path = "C:/windows/"; // 指定文件所在的目录
File f = new File(path, "notepad.exe"); // 建立File变量,并设定由f变量引用 System.out.println("C:\\windows\\notepad.exe文件信息如下:"); System.out.println("============================================");
System.out.println("文件长度:" + f.length() + "字节");
System.out.println("文件或者目录:" + (f.isFile() ? "是文件" : "不是文件"));
System.out.println("文件或者目录:" + (f.isDirectory() ? "是目录" : "不是目录"));
System.out.println("是否可读:" + (f.canRead() ? "可读取" : "不可读取"));
System.out.println("是否可写:" + (f.canWrite() ? "可写入" : "不可写入"));
System.out.println("是否隐藏:" + (f.isHidden() ? "是隐藏文件" : "不是隐藏文件"));
System.out.println("最后修改日期:" + new Date(f.lastModified()));
System.out.println("文件名称:" + f.getName());
System.out.println("文件路径:" + f.getPath());
System.out.println("绝对路径:" + f.getAbsolutePath()); }}
在上述代码中 File 类构造方法的第一个参数指定文件所在位置,这里使用C:/作为文件的实际路径;第二个参数指定文件名称。创建的 File 类对象为 f,然后通过 f 调用方法获取相应的属性,最终运行效果如下所示。
C:\windows\notepad.exe文件信息如下:
============================================
文件长度:193536字节
文件或者目录:是文件
文件或者目录:不是目录
是否可读:可读取
是否可写:可写入
是否隐藏:不是隐藏文件
最后修改日期:Mon Dec 28 02:55:19 CST 2016
文件名称:notepad.exe
文件路径:C:\windows\notepad.exe
绝对路径:C:\windows\notepad.exe
2)创建和删除文件
File 类不仅可以获取已知文件的属性信息,还可以在指定路径创建文件,以及删除一个文件。创建文件需要调用 createNewFile() 方法,删除文件需要调用 delete() 方法。无论是创建还是删除文件通常都先调用 exists() 方法判断文件是否存在。
假设要在 C 盘上创建一个 test.txt 文件,程序启动时会检测该文件是否存在,如果不存在则创建;如果存在则删除它再创建。
实现代码如下:
public class Test03 { public static void main(String[] args) throws IOException { File f = new File("C:\\test.txt"); // 创建指向文件的File对象 if (f.exists()) // 判断文件是否存在 { f.delete(); // 存在则先删除 } f.createNewFile(); // 再创建 }}
运行程序之后可以发现,在 C 盘中已经创建好了 test.txt 文件。但是如果在不同的操作系统中,路径的分隔符是不一样的,例如:
- Windows 中使用反斜杠
\表示目录的分隔符。 - Linux 中使用正斜杠
/表示目录的分隔符。
那么既然 Java 程序本身具有可移植性的特点,则在编写路径时最好可以根据程序所在的操作系统自动使用符合本地操作系统要求的分隔符,这样才能达到可移植性的目的。要实现这样的功能,则就需要使用 File 类中提供的两个常量。
代码修改如下:
public static void main(String[] args) throws IOException {
String path = "C:" + File.separator + "test.txt"; // 拼凑出可以适应操作系统的路径
File f = new File(path);
if (f.exists()) // 判断文件是否存在 {
f.delete(); // 存在则先删除 }
f.createNewFile(); // 再创建}
程序的运行结果和前面程序一样,但是此时的程序可以在任意的操作系统中使用。
注意:在操作文件时一定要使用 File.separator 表示分隔符。在程序的开发中,往往会使用 Windows 开发环境,因为在 Windows 操作系统中支持的开发工具较多,使用方便,而在程序发布时往往是直接在 Linux 或其它操作系统上部署,所以这时如果不使用 File.separator,则程序运行就有可能存在问题。关于这一点我们在以后的开发中一定要有所警惕。
2)创建和删除目录
File 类除了对文件的创建和删除外,还可以创建和删除目录。创建目录需要调用 mkdir() 方法,删除目录需要调用 delete() 方法。无论是创建还是删除目录都可以调用 exists() 方法判断目录是否存在。
编写一个程序判断 C 盘根目录下是否存在 config 目录,如果存在则先删除再创建。实现代码如下:
public class Test04 {
public static void main(String[] args) {
String path = "C:/config/"; // 指定目录位置
File f = new File(path); // 创建File对象
if (f.exists()) {
f.delete(); }
f.mkdir(); // 创建目录 }}
3)遍历目录
通过遍历目录可以在指定的目录中查找文件,或者显示所有的文件列表。File 类的 list() 方法提供了遍历目录功能,该方法有如下两种重载形式。
1. String[] list()
该方法表示返回由 File 对象表示目录中所有文件和子目录名称组成的字符串数组,如果调用的 File 对象不是目录,则返回 null。
提示:list() 方法返回的数组中仅包含文件名称,而不包含路径。但不保证所得数组中的相同字符串将以特定顺序出现,特别是不保证它们按字母顺序出现。
2. String[] list(FilenameFilter filter)
该方法的作用与 list() 方法相同,不同的是返回数组中仅包含符合 filter 过滤器的文件和目录,如果 filter 为 null,则接受所有名称。
假设要遍历 C 盘根目录下的所有文件和目录,并显示文件或目录名称、类型及大小。使用 list() 方法的实现代码如下:
public class Test05 {
public static void main(String[] args) {
File f = new File("C:/"); // 建立File变量,并设定由f变量变数引用
System.out.println("文件名称\t\t文件类型\t\t文件大小"); System.out.println("===================================================");
String fileList[] = f.list(); // 调用不带参数的list()方法
for (int i = 0; i < fileList.length; i++) { // 遍历返回的字符数组
System.out.print(fileList[i] + "\t\t");
System.out.print((new File("C:/", fileList[i])).isFile() ? "文件" + "\t\t" : "文件夹" + "\t\t"); System.out.println((new File("C:/", fileList[i])).length() + "字节"); } }}
由于 list() 方法返回的字符数组中仅包含文件名称,因此为了获取文件类型和大小,必须先转换为 File 对象再调用其方法。如下所示的是实例的运行效果:
文件名称 文件类型 文件大小
===================================================
$Recycle.Bin 文件夹 4096字节
Documents and Settings 文件夹 0字节
Download 文件夹 0字节
DRIVERS 文件夹 0字节
FibocomLog 文件夹 0字节
Gateface 文件夹 0字节
GFPageCache 文件夹 0字节
hiberfil.sys 文件 3375026176字节
Intel 文件夹 0字节
KuGou 文件夹 0字节
logs 文件夹 0字节
msdia80.dll 文件 904704字节
MSOCache 文件夹 0字节
MyDownloads 文件夹 0字节
MyDrivers 文件夹 0字节
news.template 文件 417字节
NVIDIA 文件夹 0字节
OneDriveTemp 文件夹 0字节
opt 文件夹 0字节
pagefile.sys 文件 6442450944字节
PerfLogs 文件夹 0字节
Program Files 文件夹 12288字节
Program Files (x86) 文件夹 8192字节
ProgramData 文件夹 12288字节
QMDownload 文件夹 0字节
Recovery 文件夹 0字节
swapfile.sys 文件 268435456字节
System Volume Information 文件夹 12288字节
Users 文件夹 4096字节
Windows 文件夹 16384字节
假设希望只列出目录下的某些文件,这就需要调用带过滤器参数的 list() 方法。首先需要创建文件过滤器,该过滤器必须实现 java.io.FilenameFilter 接口,并在 accept() 方法中指定允许的文件类型。
如下所示为允许 SYS、TXT 和 BAK 格式文件的过滤器实现代码:
public class ImageFilter implements FilenameFilter { // 实现 FilenameFilter 接口 @Override public boolean accept(File dir, String name) { // 指定允许的文件类型 return name.endsWith(".sys") || name.endsWith(".txt") || name.endsWith(".bak"); }}
上述代码创建的过滤器名称为 ImageFilter,接下来只需要将该名称传递给 list() 方法即可实现筛选文件。如下所示为修改后的 list() 方法,其他代码与例 4 相同,这里不再重复。
String fileList[] = f.list(new ImageFilter());
再次运行程序,遍历结果如下所示:
文件名称 文件类型 文件大小
===================================================
offline_FtnInfo.txt 文件 296字节
pagefile.sys 文件 8436592640字节
(5)Java Collections类:sort()升序排序、reverse()降序排序、copy()复制、fill()填充
Collections 类提供了许多操作集合的静态方法,借助这些静态方法可以实现集合元素的排序、填充和复制等操作。下面介绍 Collections 类中操作集合的常用方法。
1)正向排序
使用 Collections 类的静态方法 sort() 可以对集合中的元素进行升序排序。这要求列表中的所有元素都必须实现 Comparable 接口,而且所有元素都必须是使用指定比较器可相互比较的。
sort() 方法主要有如下两种重载形式。
- void sort(List list):根据元素的自然顺序对集合中的元素进行升序排序。
- void sort(List list,Comparator comparator):按 comparator 参数指定的排序方式对集合中的元素进行排序。
编写一个程序,对用户输入的 5 个商品价格进行排序后输出。这里要求使用 Collections 类中 sort() 方法按从低到局的顺序对其进行排序,最后将排序后的成绩输出。
具体实现代码如下:
public class Test10 {
public static void main(String[] args) {
Scanner input = new Scanner(System.in);
List prices = new ArrayList();
for (int i = 0; i < 5; i++) {
System.out.println("请输入第 " + (i + 1) + " 个商品的价格:");
int p = input.nextInt();
prices.add(Integer.valueOf(p)); // 将录入的价格保存到List集合中 }
Collections.sort(prices); // 调用sort()方法对集合进行排序
System.out.println("价格从低到高的排列为:");
for (int i = 0; i < prices.size(); i++) {
System.out.print(prices.get(i) + "\t"); } }}
如上述代码,循环录入 5 个价格,并将每个价格都存储到已定义好的 List 集合 prices 中,然后使用 Collections 类的 sort() 方法对该集合元素进行升序排序。最后使用 for 循环遍历 users 集合,输出该集合中的元素。
该程序的执行结果如下所示。
请输入第 1 个商品的价格:
85
请输入第 2 个商品的价格:
48
请输入第 3 个商品的价格:
66
请输入第 4 个商品的价格:
80
请输入第 5 个商品的价格:
18
价格从低到高的排列为:
18 48 66 80 85
2)逆向排序
与 sort() 方法的作用相反,调用 reverse() 静态方法可以对指定集合元素进行逆向排序。该方法的定义如下:
void reverse(List list) // 对集合中的元素进行反转排序
循环录入 5 个商品的名称,并按录入时间的先后顺序进行降序排序,即后录入的先输出。
下面编写程序,使用 Collections 类的 reverse() 方法对保存到 List 集合中的 5 个商品名称进行反转排序,并输出排序后的商品信息。具体的实现代码如下:
public class Test11 {
public static void main(String[] args) {
Scanner input = new Scanner(System.in);
List students = new ArrayList();
System.out.println("******** 商品信息 ********");
for (int i = 0; i < 5; i++) {
System.out.println("请输入第 " + (i + 1) + " 个商品的名称:");
String name = input.next();
students.add(name); // 将录入的商品名称存到List集合中 }
Collections.reverse(students); // 调用reverse()方法对集合元素进行反转排序
System.out.println("按录入时间的先后顺序进行降序排列为:");
for (int i = 0; i < 5; i++) {
System.out.print(students.get(i) + "\t"); } }}
如上述代码,首先循环录入 5 个商品的名称,并将这些名称保存到 List 集合中,然后调用 Collections 类中的 reverse() 方法对该集合元素进行反转排序。最后使用 for 循环将排序后的集合元素输出。
执行该程序,输出结果如下所示。
******** 商品信息 ********
请输入第 1 个商品的名称:
果粒橙
请输入第 2 个商品的名称:
冰红茶
请输入第 3 个商品的名称:
矿泉水
请输入第 4 个商品的名称:
软面包
请输入第 5 个商品的名称:
巧克力
按录入时间的先后顺序进行降序排列为:
巧克力 软面包 矿泉水 冰红茶 果粒橙
3)复制
Collections 类的 copy() 静态方法用于将指定集合中的所有元素复制到另一个集合中。执行 copy() 方法后,目标集合中每个已复制元素的索引将等同于源集合中该元素的索引。
copy() 方法的语法格式如下:
void copy(List dest,List src)
其中,dest 表示目标集合对象,src 表示源集合对象。
注意:目标集合的长度至少和源集合的长度相同,如果目标集合的长度更长,则不影响目标集合中的其余元素。如果目标集合长度不够而无法包含整个源集合元素,程序将抛出 IndexOutOfBoundsException 异常。
在一个集合中保存了 5 个商品名称,现在要使用 Collections 类中的 copy() 方法将其中的 3 个替换掉。具体实现的代码如下:
public class Test12 {
public static void main(String[] args) {
Scanner input = new Scanner(System.in);
List srcList = new ArrayList();
List destList = new ArrayList();
destList.add("苏打水");
destList.add("木糖醇");
destList.add("方便面");
destList.add("火腿肠");
destList.add("冰红茶");
System.out.println("原有商品如下:");
for (int i = 0; i < destList.size(); i++) {
System.out.println(destList.get(i)); }
System.out.println("输入替换的商品名称:");
for (int i = 0; i < 3; i++) {
System.out.println("第 " + (i + 1) + " 个商品:");
String name = input.next();
srcList.add(name); }
// 调用copy()方法将当前商品信息复制到原有商品信息集合中
Collections.copy(destList, srcList);
System.out.println("当前商品有:");
for (int i = 0; i < destList.size(); i++) {
System.out.print(destList.get(i) + "\t"); } }}
如上述代码,首先创建了两个 List 对象 srcList 和 destList,并向 destList 集合中添加了 5 个元素,向 srcList 集合中添加了 3 个元素,然后调用 Collections 类中 copy() 方法将 srcList 集合中的全部元素复制到 destList 集合中。由于 destList 集合中含有 5 个元素,故最后两个元素不会被覆盖。
运行该程序,具体的执行结果如下所示。
原有商品如下:
苏打水
木糖醇
方便面
火腿肠
冰红茶
输入替换的商品名称:
第 1 个商品:
燕麦片
第 2 个商品:
八宝粥
第 3 个商品:
软面包
当前商品有:
燕麦片 八宝粥 软面包 火腿肠 冰红茶
4)填充
Collections 类的 fill() 静态方法可以对指定集合的所有元素进行填充操作。fill() 方法的定义如下:
void fill(List list,T obj) // 使用指定元素替换指定列表中的所有元素
其中,list 表示要替换的集合对象,obj 表示用来替换指定集合的元素值。
编写一个程序,要求用户输入 3 个商品名称,然后使用 Collections 类中的 fill() 方法对商品信息进行重置操作,即将所有名称都更改为“未填写”。具体的实现代码如下:
public class Test13 {
public static void main(String[] args) {
Scanner input = new Scanner(System.in);
List products = new ArrayList();
System.out.println("******** 商品信息 ********");
for (int i = 0; i < 3; i++) {
System.out.println("请输入第 " + (i + 1) + " 个商品的名称:");
String name = input.next();
products.add(name); // 将用户录入的商品名称保存到List集合中 }
System.out.println("重置商品信息,将所有名称都更改为'未填写'");
Collections.fill(products, "未填写");
System.out.println("重置后的商品信息为:");
for (int i = 0; i < products.size(); i++) {
System.out.print(products.get(i) + "\t");
} }}
如上述代码,首先循环录入 3 个商品名称,并将这些商品信息存储到 List 集合中,然后调用 Collections 类中的 fill() 方法将该集合中的所有元素值替换为“未填写”。最后使用 for 循环将替换后的集合元素输出。
运行该程序,执行结果如下所示。
******** 商品信息 ********
请输入第 1 个商品的名称:
苏打水
请输入第 2 个商品的名称:
矿泉水
请输入第 3 个商品的名称:
冰红茶
重置商品信息,将所有名称都更改为'未填写'
重置后的商品信息为:
未填写 未填写 未填写
(6)Java Map集合详解
Map 是一种键-值对(key-value)集合,Map 集合中的每一个元素都包含一个键对象和一个值对象。其中,键对象不允许重复,而值对象可以重复,并且值对象还可以是 Map 类型的,就像数组中的元素还可以是数组一样。
Map 接口主要有两个实现类:HashMap 类和 TreeMap 类。其中,HashMap 类按哈希算法来存取键对象,而 TreeMap 类可以对键对象进行排序。
Map 接口中提供的常用方法如表 1 所示。
| 方法名称 | 说明 |
|---|---|
| V get(Object key) | 返回 Map 集合中指定键对象所对应的值。V 表示值的数据类型 |
| V put(K key, V value) | 向 Map 集合中添加键-值对,返回 key 以前对应的 value,如果没有, 则返回 null |
| V remove(Object key) | 从 Map 集合中删除 key 对应的键-值对,返回 key 对应的 value,如果没有,则返回null |
| Set entrySet() | 返回 Map 集合中所有键-值对的 Set 集合,此 Set 集合中元素的数据类型为 Map.Entry |
| Set keySet() | 返回 Map 集合中所有键对象的 Set 集合 |
例 1
每名学生都有属于自己的唯一编号,即学号。在毕业时需要将该学生的信息从系统中移除。
下面编写 Java 程序,使用 HashMap 来存储学生信息,其键为学生学号,值为姓名。毕业时,需要用户输入学生的学号,并根据学号进行删除操作。具体的实现代码如下:
public class Test09 {
public static void main(String[] args) {
HashMap users = new HashMap();
users.put("11", "张浩太"); // 将学生信息键值对存储到Map中
users.put("22", "刘思诚");
users.put("33", "王强文");
users.put("44", "李国量");
users.put("55", "王路路");
System.out.println("******** 学生列表 ********");
Iterator it = users.keySet().iterator();
while (it.hasNext()) { // 遍历 Map
Object key = it.next();
Object val = users.get(key);
System.out.println("学号:" + key + ",姓名:" + val); }
Scanner input = new Scanner(System.in);
System.out.println("请输入要删除的学号:");
int num = input.nextInt();
if (users.containsKey(String.valueOf(num))) { // 判断是否包含指定键 users.remove(String.valueOf(num)); // 如果包含就删除 }
else { System.out.println("该学生不存在!"); }
System.out.println("******** 学生列表 ********");
it = users.keySet().iterator();
while (it.hasNext()) {
Object key = it.next();
Object val = users.get(key);
System.out.println("学号:" + key + ",姓名:" + val); } }}
在该程序中,两次使用 while 循环遍历 HashMap 集合。当有学生毕业时,用户需要输入该学生的学号,根据学号使用 HashMap 类的 remove() 方法将对应的元素删除。程序运行结果如下所示。
******** 学生列表 ********
学号:44,姓名:李国量
学号:55,姓名:王路路
学号:22,姓名:刘思诚
学号:33,姓名:王强文
学号:11,姓名:张浩太
请输入要删除的学号:
22
******** 学生列表 ********
学号:44,姓名:李国量
学号:55,姓名:王路路
学号:33,姓名:王强文
学号:11,姓名:张浩太
******** 学生列表 ********
学号:44,姓名:李国量
学号:55,姓名:王路路
学号:22,姓名:刘思诚
学号:33,姓名:王强文
学号:11,姓名:张浩太
请输入要删除的学号:
44
******** 学生列表 ********
学号:55,姓名:王路路
学号:22,姓名:刘思诚
学号:33,姓名:王强文
学号:11,姓名:张浩太
注意:TreeMap 类的使用方法与 HashMap 类相同,唯一不同的是 TreeMap 类可以对键对象进行排序,这里不再赘述。
(7)Java Set集合详解:HashSet类、TreeSet 类
Set 集合也实现了 Collection 接口,它主要有两个实现类:HashSet 类和 TreeSet类。Set 集合中的对象不按特定的方式排序,只是简单地把对象加入集合,集合中不能包含重复的对象,并且最多只允许包含一个 null 元素。
HashSet 类
HashSet 类是按照哈希算法来存储集合中的元素,使用哈希算法可以提高集合元素的存储速度,当向 Set 集合中添加一个元素时,HashSet 会调用该元素的 hashCode() 方法,获取其哈希码,然后根据这个哈希码计算出该元素在集合中的存储位置。
在 HashSet 类中实现了 Collection 接口中的所有方法。HashSet 类的常用构造方法重载形式如下。
- HashSet():构造一个新的空的 Set 集合。
- HashSet(Collectionc):构造一个包含指定 Collection 集合元素的新 Set 集合。其中,“< >”中的 extends 表示 HashSet 的父类,即指明该 Set 集合中存放的集合元素类型。c 表示其中的元素将被存放在此 Set 集合中。
下面的代码演示了创建两种不同形式的 HashSet 对象。
HashSet hs = new HashSet(); // 调用无参的构造函数创建HashSet对象HashSet hss = new HashSet(); // 创建泛型的 HashSet 集合对象
例 1
编写一个 Java 程序,使用 HashSet 创建一个 Set 集合,并向该集合中添加 5 本图书名称。具体实现代码如下:
public static void main(String[] args) {
HashSet bookSet = new HashSet(); // 创建一个空的 Set 集合 String book1 = new String("如何成为 Java 编程高手");
String book2 = new String("Java 程序设计一百例");
String book3 = new String("从零学 Java 语言");
String book4 = new String("论 java 的快速开发");
bookSet.add(book1); // 将 book1 存储到 Set 集合中
bookSet.add(book2); // 将 book2 存储到 Set 集合中
bookSet.add(book3); // 将 book3 存储到 Set 集合中
bookSet.add(book4); // 将 book4 存储到 Set 集合中
System.out.println("新进图书有:");
Iterator it = bookSet.iterator();
while (it.hasNext()) {
System.out.println("《" + (String) it.next() + "》"); // 输出 Set 集合中的元素 }
System.out.println("共采购 " + bookSet.size() + " 本图书!");}
如上述代码,首先使用 HashSet 类的构造方法创建了一个 Set 集合,接着创建了 4 个 String 类型的对象,并将这些对象存储到 Set 集合中。使用 HashSet 类中的 iterator() 方法获取一个 Iterator 对象,并调用其 hasNext() 方法遍历集合元素,再将使用 next() 方法读取的元素强制转换为 String 类型。最后调用 HashSet 类中的 size() 方法获取集合元素个数。
运行该程序,输出的结果如下:
新进图书有:
《如何成为 Java 编程高手》
《从零学 Java 语言》
《Java 程序设计一百例》
《论 java 的快速开发》
共采购 4 本图书!
注意:在该示例中,如果再向 bookSet 集合中添加一个名称为“Java 程序设计一百例”的 String 对象,则输出的结果与上述执行结果相同。也就是说,如果向 Set 集合中添加两个相同的元素,则后添加的会覆盖前面添加的元素,即在 Set 集合中不会出现相同的元素。
TreeSet 类
TreeSet 类同时实现了 Set 接口和 SortedSet 接口。SortedSet 接口是 Set 接口的子接口,可以实现对集合进行自然排序,因此使用 TreeSet 类实现的 Set 接口默认情况下是自然排序的,这里的自然排序指的是升序排序。
TreeSet 只能对实现了 Comparable 接口的类对象进行排序,因为 Comparable 接口中有一个 compareTo(Object o) 方法用于比较两个对象的大小。例如 a.compareTo(b),如果 a 和 b 相等,则该方法返回 0;如果 a 大于 b,则该方法返回大于 0 的值;如果 a 小于 b,则该方法返回小于 0 的值。
表 1 列举了 JDK 类库中实现 Comparable 接口的类,以及这些类对象的比较方式。
| 类 | 比较方式 |
|---|---|
| 包装类(BigDecimal、Biglnteger、 Byte、Double、 Float、Integer、Long 及 Short) | 按数字大小比较 |
| Character | 按字符的 Unicode 值的数字大小比较 |
| String | 按字符串中字符的 Unicode 值的数字大小比较 |
TreeSet 类除了实现 Collection 接口的所有方法之外,还提供了如表 2 所示的方法。
| 方法名称 | 说明 |
|---|---|
| E first() | 返回此集合中的第一个元素。其中,E 表示集合中元素的数据类型 |
| E last() | 返回此集合中的最后一个元素 |
| E poolFirst() | 获取并移除此集合中的第一个元素 |
| E poolLast() | 获取并移除此集合中的最后一个元素 |
| SortedSet subSet(E fromElement,E toElement) | 返回一个新的集合,新集合包含原集合中 fromElement 对象与 toElement 对象之间的所有对象。包含 fromElement 对象,不包含 toElement 对象 |
SortedSet headSet| 返回一个新的集合,新集合包含原集合中 toElement 对象之前的所有对象。 不包含 toElement 对象 |
|
| SortedSet tailSet(E fromElement) | 返回一个新的集合,新集合包含原集合中 fromElement 对象之后的所有对 象。包含 fromElement 对象 |
例 2
本次有 5 名学生参加考试,当老师录入每名学生的成绩后,程序将按照从低到高的排列顺序显示学生成绩。此外,老师可以查询本次考试是否有满分的学生存在,不及格的成绩有哪些,90 分以上成绩的学生有几名。
下面使用 TreeSet 类来创建 Set 集合,完成学生成绩查询功能。具体的代码如下:
public class Test08 { public static void main(String[] args) { TreeSet scores = new TreeSet(); // 创建 TreeSet 集合 Scanner input = new Scanner(System.in); System.out.println("------------学生成绩管理系统-------------"); for (int i = 0; i < 5; i++) { System.out.println("第" + (i + 1) + "个学生成绩:"); double score = input.nextDouble(); // 将学生成绩转换为Double类型,添加到TreeSet集合中 scores.add(Double.valueOf(score)); } Iterator it = scores.iterator(); // 创建 Iterator 对象 System.out.println("学生成绩从低到高的排序为:"); while (it.hasNext()) { System.out.print(it.next() + "\t"); } System.out.println("\n请输入要查询的成绩:"); double searchScore = input.nextDouble(); if (scores.contains(searchScore)) { System.out.println("成绩为: " + searchScore + " 的学生存在!"); } else { System.out.println("成绩为: " + searchScore + " 的学生不存在!"); } // 查询不及格的学生成绩 SortedSet score1 = scores.headSet(60.0); System.out.println("\n不及格的成绩有:"); for (int i = 0; i < score1.toArray().length; i++) { System.out.print(score1.toArray()[i] + "\t"); } // 查询90分以上的学生成绩 SortedSet score2 = scores.tailSet(90.0); System.out.println("\n90 分以上的成绩有:"); for (int i = 0; i < score2.toArray().length; i++) { System.out.print(score2.toArray()[i] + "\t"); } }}
如上述代码,首先创建一个 TreeSet 集合对象 scores,并向该集合中添加 5 个 Double 对象。接着使用 while 循环遍历 scores 集合对象,输出该对象中的元素,然后调用 TreeSet 类中的 contains() 方法获取该集合中是否存在指定的元素。最后分别调用 TreeSet 类中的 headSet() 方法和 tailSet() 方法获取不及格的成绩和 90 分以上的成绩。
运行该程序,执行结果如下所示。
------------学生成绩管理系统-------------
第1个学生成绩:
53
第2个学生成绩:
48
第3个学生成绩:
85
第4个学生成绩:
98
第5个学生成绩:
68
学生成绩从低到高的排序为:
48.0 53.0 68.0 85.0 98.0
请输入要查询的成绩:
90
成绩为: 90.0 的学生不存在!
不及格的成绩有:
48.0 53.0
90 分以上的成绩有:
98.0
注意:在使用自然排序时只能向 TreeSet 集合中添加相同数据类型的对象,否则会抛出 ClassCastException 异常。如果向 TreeSet 集合中添加了一个 Double 类型的对象,则后面只能添加 Double 对象,不能再添加其他类型的对象,例如 String 对象等。
(8)Java final修饰符:final修饰属性、final修饰方法及final修饰类
final 关键字表示对象是最终形态的,对象是不可改变的意思。final 应用于类、方法和变量时意义是不同的,但本质是一样的:final 表示不可改变。
final 用在变量的前面表示变量的值不可以改变,此时该变量可以被称为常量;final 用在方法的前面表示方法不可以被重写;final 用在类的前面表示类不可以被继承,即该类是最终形态,如常见的 java.lang.String 类。
final 修饰符使用在如下方面:
1. final 修饰类中的属性
表示该属性一旦被初始化便不可改变,这里不可改变的意思对基本类型来说是其值不可变,而对对象属性来说其引用不可再变。其初始化可以在两个地方:一是其定义处,也就是说在 final 属性定义时直接给其赋值;二是在构造函数中。这两个地方只能选其一,要么在定义时给值,要么在构造函数中给值,不能同时既在定义时赋值,又在构造函数中赋予另外的值。
2. final 修饰类中的方法
说明这种方法提供的功能已经满足当前要求,不需要进行扩展,并且也不允许任何从此类继承的类来重写这种方法,但是继承仍然可以继承这个方法,也就是说可以直接使用。在声明类中,一个 final 方法只被实现一次。
3. final 修饰类
表示该类是无法被任何其他类继承的,意味着此类在一个继承树中是一个叶子类,并且此类的设计已被认为很完美而不需要进行修改或扩展。
对于 final 类中的成员,可以定义其为 final,也可以不是 final。而对于方法,由于所属类为 final 的关系,自然也就成了 final 型。也可以明确地给 final 类中的方法加上一个 final,这显然没有意义。
例 1
下面创建一个示例演示 final 修饰符的具体使用。首先新建 FinalTest.java 文件,在该文件中创建 FinalTest 类,定义一个声明为 final 的 count 属性和一个声明为 final 的 sum() 方法。
FinalTest 类的代码如下:
public class FinalTest {
final int count = 1;
public int updateCount() {
count = 4; // 修改final属性值,提示错误 因为final 用在变量的前面表示变量的值不可以改变,此时该变量可以被称为常量,赋值一次就不能赋值第二次了
return count; }
public final int sum() {
int number = count+10;
return number;
}}
创建 FinalTest 类的子类 FinalExtendTest,在该类中重写父类 FinalTest 中的 sum() 方法,并继承父类中的 sum() 方法。代码如下:
public class FinalExtendTest extends FinalTest {
public int sum(){}; // 重写父类 FinalTest 中的 sum()方法,出错 父类 sum()被final修饰就不能被子类重新,但是可以继承直接调用该办法
int count = sum(); // 继承父类 FinalTest 中的 sum()方法
}
最后在 FinalExtend 类中新建程序主方法——main() 方法,实例化 FinalExtendTest 类并访问该类的 count 属性,代码如下所示。
public static void main(String[] args) {
FinalExtendTest fet = new FinalExtendTest();
System.out.println(fet.count);}
在编译该文件时,会出现两处错误:一是代码“count=4;”处,此处试图给 count 变量重新赋值,会产生错误,因为 final 变量只能被初始化一次。第二处是代码“public int sum(){};”,此处试图重写 final 修饰的方法,会出现错误,因为 final 修饰的方法可以被继承但不能被任何类重写。
将两处的错误语句都注释掉,程序运行后输出的结果如下:
11
(9)接口的定义和接口的实现,定义接口,实现接口
切记接口不需要修饰符:String findById(int id);不必要写成 public String findById(int id);,因为它默认 public abstract String findById(int id);
- 在 Java 接口中声明的变量其实都是常量,接口中的变量声明,将隐式地声明为 public、static 和 final,即常量,所以接口中定义的变量必须初始化。
- 接口中:办法默认是 :public abstract 属性是 public abstract final 也就是接口的属性都是常量,办法都是抽象办法
接口类似于类,但接口的成员没有执行体,它只是方法、属性、事件和索引符的组合而已。接口不能被实例化,接口没有构造方法,没有字段。在应用程序中,接口就是一种规范,它封装了可以被多个类继承的公共部分。
定义接口
接口继承和实现继承的规则不同,一个类只有一个直接父类,但可以实现多个接口。Java 接口本身没有任何实现,只描述 public 行为,因此 Java 接口比 Java 抽象类更抽象化。Java 接口的方法只能是抽象的和公开的,Java 接口不能有构造方法,Java 接口可以有 public、static 和 final 属性。
接口把方法的特征和方法的实现分隔开来,这种分隔体现在接口常常代表一个角色,它包装与该角色相关的操作和属性,而实现这个接口的类便是扮演这个角色的演员。一个角色由不同的演员来演,而不同的演员之间除了扮演一个共同的角色之外,并不要求其他的共同之处。
接口对于其声明、变量和方法都做了许多限制,这些限制作为接口的特征归纳如下:
- 具有 public 访问控制符的接口,允许任何类使用;没有指定 public 的接口,其访问将局限于所属的包。
- 方法的声明不需要其他修饰符,在接口中声明的方法,将隐式地声明为公有的(public)和抽象的(abstract)。
- 在 Java 接口中声明的变量其实都是常量,接口中的变量声明,将隐式地声明为 public、static 和 final,即常量,所以接口中定义的变量必须初始化。
- 接口没有构造方法,不能被实例化。例如:
public interface A {
publicA(){…} // 编译出错,接口不允许定义构造方法}
- 一个接口不能够实现另一个接口,但它可以继承多个其他接口。子接口可以对父接口的方法和常量进行重写。例如:
public interface StudentInterface extends PeopleInterface {
// 接口 StudentInterface 继承 PeopleInterface
int age = 25; // 常量age重写父接口中的age常量
void getInfo(); // 方法getInfo()重写父接口中的getInfo()方法
}
Java 接口的定义方式与类基本相同,不过接口定义使用的关键字是 interface,接口定义由接口声明和接口体两部分组成。语法格式如下:
[public] interface interface_name [
extends interface1_name[, interface2_name,…]] {
// 接口体,其中可以包含定义常量和声明方法
[public] [static] [final] type constant_name = value; // 定义常量
[public] [abstract] returnType method_name(parameter_list); // 声明方法
}
其中,public 表示接口的修饰符,当没有修饰符时,则使用默认的修饰符,此时该接口的访问权限仅局限于所属的包;interfaCe_name 表示接口的名称,可以是任何有效的标识符;extends 表示接口的继承关系;interface1_name 表示要继承的接口名称;constant_name 表示变量名称,一般是 static 和 final 型的;returnType 表示方法的返回值类型;parameter_list 表示参数列表,在接口中的方法是没有方法体的。
提示:如果接口本身被定义为 public,则所有的方法和常量都是 public 型的。
例如,定义一个接口 MyInterface,并在该接口中声明常量和方法,如下:
public interface MyInterface { // 接口myInterface
String name; // 不合法,变量name必须初始化
int age = 20; // 合法,等同于 public static final int age=20;
void getInfo(); // 方法声明,等同于 public abstract void getInfo();}
实现接口
接口被定义后,一个或者多个类都可以实现该接口,这需要在实现接口的类的定义中包含 implements 子句,然后实现由接口定义的方法。实现接口的一般形式如下:
class [extends superclass_name] [implements interface[, interface…]] {
//主体
}
如果一个类实现多个接口,这些接口需要使用逗号分隔。如果一个类实现两个声明了同样方法的接口,那么相同的方法将被其中任一个接口使用。实现接口的方法必须声明为 public,而且实现方法的类型必须严格与接口定义中指定的类型相匹配。
例 1
在程序的开发中,需要完成两个数的求和运算和比较运算功能的类非常多。那么可以定义一个接口来将类似功能组织在一起。下面创建一个示例,具体介绍接口的实现方式。
1)创建一个名称为 IMath 的接口,代码如下:
public interface IMath { public int sum(); // 完成两个数的相加 public int maxNum(int a,int b); // 获取较大的数}
2)定义一个 MathClass 类并实现 IMath 接口,MathClass 类实现代码如下:
public class MathClass implements IMath {
private int num1; // 第 1 个操作数
private int num2; // 第 2 个操作数
public MathClass(int num1,int num2) {
// 构造方法 this.num1 = num1;
this.num2 = num2; } // 实现接口中的求和方法
public int sum() {
return num1 + num2; } // 实现接口中的获取较大数的方法
public int maxNum(int a,int b) {
if(a >= b) {
return a; }
else {
return b;
}
}}
在实现类中,所有的方法都使用了 public 访问修饰符声明。无论何时实现一个由接口定义的方法,它都必须实现为 public,因为接口中的所有成员都显式声明为 public。
3)最后创建测试类 NumTest,实例化接口的实现类 MathClass,调用该类中的方法并输出结果。该类内容如下:
public class NumTest {
public static void main(String[] args) {
// 创建实现类的对象
MathClass calc = new MathClass(100, 300);
System.out.println("100 和 300 相加结果是:" + calc.sum());
System.out.println("100 比较 300,哪个大:" + calc.maxNum(100, 300));
}}
程序运行结果如下所示。
100 和 300 相加结果是:400
100 比较 300,哪个大:300
在该程序中,首先定义了一个 IMath 的接口,在该接口中只声明了两个未实现的方法,这两个方法需要在接口的实现类中实现。在实现类 MathClass 中定义了两个私有的属性,并赋予两个属性初始值,同时创建了该类的构造方法。因为该类实现了 MathClass 接口,因此必须实现接口中的方法。在最后的测试类中,需要创建实现类对象,然后通过实现类对象调用实现类中的方法。
(10)Java利用内部类实现多重继承
多重继承指的是一个类可以同时从多于一个的父类那里继承行为和特征,然而我们知道 Java 为了保证数据安全,只允许单继承。
有些时候我们会认为如果系统中需要使用多重继承,那往往都是糟糕的设想,这时开发人员往往需要思考的不是怎么使用多重继承,而是他的设计是否存在问题。但是,有时候开发人员确实需要实现多重继承,而且现实生活中真正地存在这样的情况,例如遗传,我们既继承了父亲的行为和特征,也继承了母亲的行为和特征。
Java 提供的两种方法让我们实现多重继承:接口和内部类。
例 1
本节我们以生活中常见的遗传例子进行介绍,如儿子(或者女儿)是如何利用多重继承来继承父亲和母亲的优良基因的。
1)创建 Father 类,在该类中添加 strong() 方法。代码如下:
public class Father {
public int strong() {
// 强壮指数
return 9;
}}
2)创建 Mother 类,在该类中添加 kind() 方法。代码如下:
public class Mother {
public int kind() { // 友好指数
return 8; }}
3)重点在于儿子类的实现,创建 Son 类,在该类中通过内部类实现多重继承。代码如下:
public class Son { // 内部类继承Father类
class Father_1 extends Father {
public int strong() {
return super.strong() + 1;
}
}
class Mother_1 extends Mother {
public int kind() {
return super.kind() - 2;
}
}
public int getStrong() {
return new Father_1().strong();
}
public int getKind() {
return new Mother_1().kind();
}}
上述代码定义两个内部类,这两个内部类分别继承 Father(父亲)类和 Mother(母亲)类,且都可以获取各自父类的行为。这是内部类一个很重要的特性:内部类可以继承一个与外部类无关的类,从而保证内部类的独立性。正是基于这一点,多重继承才会成为可能。
4)创建 Test 类进行测试,在 main() 方法中实例化 Son 类的对象,然后分别调用该对象的 getStrong() 方法和 getKind() 方法。代码如下:
public class Test {
public static void main(String[] args) {
Son son = new Son();
System.out.println("Son 的强壮指数:" + son.getStrong());
System.out.println("Son 的友好指数:" + son.getKind());
}}
执行上述代码,输出结果如下:
Son 的强壮指数:10
Son 的友好指数:6
从实现代码和输出结果可以发现,儿子继承父类,变得比父亲更加强壮;同时也继承了母类,只不过友好指数下降。
(11)toCharArray(),split()
1)数组转换为字符串
1)Java String 类中的 toCharArray() 方法将字符串转换为字符数组,具体代码如下所示。
String str = "123abc";char[] arr = str.toCharArray(); // char数组for (int i = 0; i < arr.length; i++) { System.out.println(arr[i]); // 输出1 2 3 a b c}
2)Java.lang 包中有 String.split() 方法,Java 中通常用 split() 分割字符串,返回的是一个数组。
String str = "123abc";String[] arr = str.split("");for (int i = 0; i < arr.length; i++) { // String数组 System.out.print(arr[i]); // 输出 1 2 3 a b c}
使用 split() 方法注意如下:
- 如果用“.”或“|”作为分隔的话,必须是如下写法,String.split(".") 或 String.split("|"),这样才能正确的分隔开,不能用 String.split(".") 或 String.split("|")。
- 如果在一个字符串中有多个分隔符,可以用“|”作为连字符,如“acount=? and uu =? or n=?”,把三个都分隔出来,可以用 String.split(“and|or”);
- 如果想在串中使用“”字符,则也需要转义。首先要表达“aaaa\bbbb”这个串就应该用"aaaa\bbbb”,这样分隔才能得到正确结果。
3)如果要返回 byte 数组就直接使用 getBytes 方法就可以了。
String str = "123abc" ;
byte [] arr = str.getBytes();
2),数组转换为字符串
1)char 字符数组转化为字符串,使用 String.copyValueOf(charArray) 函数实现,具体代码如下所示。
char[] arr = { 'a', 'b', 'c' };String string = String.copyValueOf(arr);System.out.println(string); // 输出abc
2)String 字符串数组转化为字符串,代码如下所示。
纯文本复制
String[] arr = { "123", "abc" };StringBuffer sb = new StringBuffer();for (int i = 0; i < arr.length; i++) { sb.append(arr[i]); // String并不拥有append方法,所以借助 StringBuffer}String sb1 = sb.toString();System.out.println(sb1); // 输出123abc
(12)Java声明和抛出异常:throws声明异常、throw抛出异常、throw和throws的区别
Java 中的异常处理除了包括捕获异常和处理异常之外,还包括声明异常和拋出异常,可以通过 throws 关键字在方法上声明该方法要拋出的异常,然后在方法内部通过 throw 拋出异常对象。本节详细介绍在 Java 中如何声明异常和拋出异常。
throws 关键字和 throw 关键字在使用上的几点区别如下:
- throws 用来声明一个方法可能抛出的所有异常信息,throw 则是指拋出的一个具体的异常类型。
- 通常在一个方法(类)的声明处通过 throws 声明方法(类)可能拋出的异常信息,而在方法(类)内部通过 throw 声明一个具体的异常信息。
- throws 通常不用显示地捕获异常,可由系统自动将所有捕获的异常信息抛给上级方法; throw 则需要用户自己捕获相关的异常,而后再对其进行相关包装,最后将包装后的异常信息抛出。
1),throws 声明异常
当一个方法产生一个它不处理的异常时,那么就需要在该方法的头部声明这个异常,以便将该异常传递到方法的外部进行处理。可以使用 throws 关键字在方法的头部声明一个异常,其具体格式如下:
returnType method_name(paramList) throws Exception 1,Exception2,…{…}
其中,returnType 表示返回值类型,method_name 表示方法名,Exception 1,Exception2,… 表示异常类。如果有多个异常类,它们之间用逗号分隔。这些异常类可以是方法中调用了可能拋出异常的方法而产生的异常,也可以是方法体中生成并拋出的异常。
例 1
创建一个 readFile() 方法,该方法用于读取文件内容,在读取的过程中可能会产生 IOException 异常,但是在该方法中不做任何的处理,而将可能发生的异常交给调用者处理。在 main() 方法中使用 try catch 捕获异常,并输出异常信息。代码如下:
import java.io.FileInputStream;
import java.io.IOException;
public class Test04 {
public void readFile() throws IOException { // 定义方法时声明异常
FileInputStream file = new FileInputStream("read.txt"); // 创建 FileInputStream 实例对象
int f;
while ((f = file.read()) != -1) {
System.out.println((char) f);
f = file.read(); }
file.close(); }
public static void main(String[] args) {
Throws t = new Test04();
try {
t.readFile(); // 调用 readFHe()方法
}
catch (IOException e) { // 捕获异常
System.out.println(e);
}
}}
以上代码,首先在定义 readFile() 方法时用 throws 关键字声明在该方法中可能产生的异常,然后在 main() 方法中调用 readFile() 方法,并使用 catch 语句捕获产生的异常。
注意:在编写类继承代码时要注意,子类在覆盖父类带 throws 子句的方法时,子类的方法声明中的 throws 子句不能出现父类对应方法的 throws 子句中没有的异常类型,因此 throws 子句可以限制子类的行为。也就是说,子类方法拋出的异常不会超过父类定义的范围。
2),throw 拋出异常
throw 语句用来直接拋出一个异常,后接一个可拋出的异常类对象,其语法格式如下:
throw ExceptionObject;
其中,ExceptionObject 必须是 Throwable 类或其子类的对象。如果是自定义异常类,也必须是 Throwable 的直接或间接子类。例如,以下语句在编译时将会产生语法错误:
throw new String("拋出异常"); // 因为String类不是Throwable类的子类
当 throw 语句执行时,它后面的语句将不执行,此时程序转向调用者程序,寻找与之相匹配的 catch 语句,执行相应的异常处理程序。如果没有找到相匹配的 catch 语句,则再转向上一层的调用程序。这样逐层向上,直到最外层的异常处理程序终止程序并打印出调用栈情况。
例 2
在某仓库管理系统中,要求管理员的用户名需要由 8 位以上的字母或者数字组成,不能含有其他的字符。当长度在 8 位以下时拋出异常,并显示异常信息;当字符含有非字母或者数字时,同样拋出异常,显示异常信息。代码如下:
import java.util.Scanner;
public class Test05 {
public boolean validateUserName(String username) {
boolean con = false;
if (username.length() > 8) { // 判断用户名长度是否大于8位
for (int i = 0; i < username.length(); i++) {
char ch = username.charAt(i); // 获取每一位字符
if ((ch >= '0' && ch <= '9') || (ch >= 'a' && ch <= 'z') || (ch >= 'A' && ch <= 'Z')) {
con = true; }
else {
con = false;
throw new IllegalArgumentException("用户名只能由字母和数字组成!");
}
}
}
else {
throw new IllegalArgumentException("用户名长度必须大于 8 位!");
}
return con;
}
public static void main(String[] args) {
Test05 te = new Test05();
Scanner input = new Scanner(System.in);
System.out.println("请输入用户名:");
String username = input.next();
try {
boolean con = te.validateUserName(username);
if (con) {
System.out.println("用户名输入正确!");
}
}
catch (IllegalArgumentException e) {
System.out.println(e);
}
}}
如上述代码,在 validateUserName() 方法中两处拋出了 IllegalArgumentException 异常,即当用户名字符含有非字母或者数字以及长度不够 8 位时。在 main() 方法中,调用了 validateUserName() 方法,并使用 catch 语句捕获该方法可能拋出的异常。
(13)Java利用内部类实现多重继承
多重继承指的是一个类可以同时从多于一个的父类那里继承行为和特征,然而我们知道 Java 为了保证数据安全,只允许单继承。
有些时候我们会认为如果系统中需要使用多重继承,那往往都是糟糕的设想,这时开发人员往往需要思考的不是怎么使用多重继承,而是他的设计是否存在问题。但是,有时候开发人员确实需要实现多重继承,而且现实生活中真正地存在这样的情况,例如遗传,我们既继承了父亲的行为和特征,也继承了母亲的行为和特征。
Java 提供的两种方法让我们实现多重继承:接口和内部类。
例 1
本节我们以生活中常见的遗传例子进行介绍,如儿子(或者女儿)是如何利用多重继承来继承父亲和母亲的优良基因的。
1)创建 Father 类,在该类中添加 strong() 方法。代码如下:
public class Father {
public int strong() {
// 强壮指数
return 9;
}}
2)创建 Mother 类,在该类中添加 kind() 方法。代码如下:
public class Mother {
public int kind() {
// 友好指数
return 8;
}}
3)重点在于儿子类的实现,创建 Son 类,在该类中通过内部类实现多重继承。代码如下:
public class Son { // 内部类继承Father类
class Father_1 extends Father {
public int strong() {
return super.strong() + 1;
}
}
class Mother_1 extends Mother {
public int kind() {
return super.kind() - 2;
}
}
public int getStrong() {
return new Father_1().strong();
}
public int getKind() {
return new Mother_1().kind();
}}
上述代码定义两个内部类,这两个内部类分别继承 Father(父亲)类和 Mother(母亲)类,且都可以获取各自父类的行为。这是内部类一个很重要的特性:内部类可以继承一个与外部类无关的类,从而保证内部类的独立性。正是基于这一点,多重继承才会成为可能。
4)创建 Test 类进行测试,在 main() 方法中实例化 Son 类的对象,然后分别调用该对象的 getStrong() 方法和 getKind() 方法。代码如下:
public class Test {
public static void main(String[] args) {
Son son = new Son();
System.out.println("Son 的强壮指数:" + son.getStrong());
System.out.println("Son 的友好指数:" + son.getKind());
}}
执行上述代码,输出结果如下:
Son 的强壮指数:10
Son 的友好指数:6
从实现代码和输出结果可以发现,儿子继承父类,变得比父亲更加强壮;同时也继承了母类,只不过友好指数下降。
(14)Java查找字符串(indexOf()、lastlndexOf()和charAt())
字符串查找分为两种形式:一种是在字符串中获取匹配字符(串)的索引值,另一种是在字符串中获取指定索引位置的字符。
1),根据字符查找
String 类的 indexOf() 方法和 lastlndexOf() 方法用于在字符串中获取匹配字符(串)的索引值。
1. indexOf() 方法
indexOf() 方法用于返回字符(串)在指定字符串中首次出现的索引位置,如果能找到,则返回索引值,否则返回 -1。该方法主要有两种重载形式:
str.indexOf(value)str.indexOf(value,int fromIndex)
其中,str 表示指定字符串;value 表示待查找的字符(串);fromIndex 表示查找时的起始索引,如果不指定 fromIndex,则默认从指定字符串中的开始位置(即 fromIndex 默认为 0)开始查找。
例如,下列代码在字符串“Hello Java”中查找字母 v 的索引位置。
纯文本复制
String s = "Hello Java";int size = s.indexOf('v'); // size的结果为8
上述代码执行后 size 的结果为 8,它的查找过程如图 1 所示。
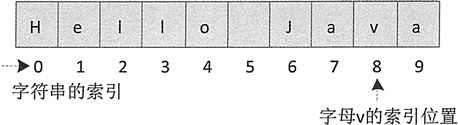
图1 indexOf() 方法查找字符过程
例 1
编写一个简单的 Java 程序,演示 indexOf() 方法查找字符串的用法,并输出结果。代码如下:
public static void main(String[] args) {
String words = "today,monday,sunday";
System.out.println("原始字符串是'"+words+"'");
System.out.println("indexOf(\"day\")结果:"+words.indexOf("day"));
System.out.println("indexOf(\"day\",5)结果:"+words.indexOf("day",5));
System.out.println("indexOf(\"o\")结果:"+words.indexOf("o"));
System.out.println("indexOf(\"o\",6)结果:"+words.indexOf("o",6));
}
运行后的输出结果如下:
原始字符串是'today,monday,sunday'
indexOf("day")结果:2
indexOf("day",5)结果:9
indexOf("o")结果:1
indexOf("o",6)结果:7
2.lastlndexOf() 方法
lastIndexOf() 方法用于返回字符(串)在指定字符串中最后一次出现的索引位置,如果能找到则返回索引值,否则返回 -1。该方法也有两种重载形式:
str.lastIndexOf(value)str.lastlndexOf(value, int fromIndex)
注意:lastIndexOf() 方法的查找策略是从右往左查找,如果不指定起始索引,则默认从字符串的末尾开始查找。
例 2
编写一个简单的 Java 程序,演示 lastIndexOf() 方法查找字符串的用法,并输出结果。代码如下:
public static void main(String[] args) {
String words="today,monday,Sunday";
System.out.println("原始字符串是'"+words+"'");
System.out.println("lastIndexOf(\"day\")结果:"+words.lastIndexOf("day")); System.out.println("lastIndexOf(\"day\",5)结果:"+words.lastIndexOf("day",5)); System.out.println("lastIndexOf(\"o\")结果:"+words.lastIndexOf("o"));
System.out.println("lastlndexOf(\"o\",6)结果:"+words.lastIndexOf("o",6));
}
运行后的输出结果如下:
原始字符串是'today,monday,Sunday'
lastIndexOf("day")结果:16
lastIndexOf("day",5)结果:2
lastIndexOf("o")结果:7
lastlndexOf("o",6)结果:1
3),根据索引查找
String 类的 charAt() 方法可以在字符串内根据指定的索引查找字符,该方法的语法形式如下:
字符串名.charAt(索引值)
charAt() 方法的使用示例如下:
String words = "today,monday,sunday";
System.out.println(words.charAt(0)); //结果:
tSystem.out.println(words.charAt(1)); // 结果:o
System.out.println(words.charAt(8)); // 结果:n
(15)Java break语句详解
在 Java 中,break 语句有 3 种作用,分别是:在 switch 语句中终止一个语句序列、使用 break 语句直接强行退出循环和使用 break 语句实现 goto 的功能。
1)在 switch 语句中终止一个语句序列
在 switch 语句中终止一个语句序列,就是在每个 case 子句块的最后添加语句“break;”,
2)使用 break 语句直接强行退出循环
可以使用 break 语句强行退出循环,忽略循环体中的任何其他语句和循环的条件判断。在循环中遇到 break 语句时,循环被终止,在循环后面的语句重新开始。
小明参加了一个 1000 米的长跑比赛,在 100 米的跑道上,他循环地跑着,每跑一圈,剩余路程就会减少 100 米,要跑的圈数就是循环的次数。但是,在每跑完一圈时,教练会问他是否要坚持下去,如果回答 y,则继续跑,否则表示放弃。
使用 break 语句直接强行退出循环的示例如下:
import java.util.Scanner;
public class Test24
{
public static void main(String[] args)
{
Scanner input=new Scanner(System.in); //定义变量存储小明的回答
String answer=""; //一圈100米,1000米为10圈,即为循环的次数
for(int i=0;i<10;i++)
{
System.out.println("跑的是第"+(i+1)+"圈");
System.out.println("还能坚持吗?"); //获取小明的回答
answer=input.next(); //判断小明的回答是否为y?如果不是,则放弃,跳出循环
if(!answer.equals("y"))
{
System.out.println("放弃");
break;
}
// 循环之后的代码
System.out.println("加油!继续!");
}
}
}
该程序运行后的效果如下所示:
跑的是第1圈
还能坚持吗?
y
加油!继续!
跑的是第2圈
还能坚持吗?
y
加油!继续!
跑的是第3圈
还能坚持吗?
n
放弃
尽管 for 循环被设计为从 0 执行到 10,但是当小明的回答不是 y 时,break 语句终止了程序的循环,继续执行循环体外的代码,输出“加油!继续!”。
break 语句能用于任何 Java循环中,包括人们有意设置的无限循环。在一系列嵌套循环中使用 break 语句时,它将仅仅终止最里面的循环。例如:
import java.util.Scanner;
public class Test24
{
public static void main(String[] args)
{
Scanner input=new Scanner(System.in); //定义变量存储小明的回答
String answer=""; //一圈100米,1000米为10圈,即为循环的次数
for(int i=0;i<10;i++)
{
System.out.println("跑的是第"+(i+1)+"圈");
System.out.println("还能坚持吗?"); //获取小明的回答
answer=input.next(); //判断小明的回答是否为y?如果不是,则放弃,跳出循环
if(!answer.equals("y"))
{
System.out.println("放弃");
break;
}
// 循环之后的代码
System.out.println("加油!继续!");
}
}
}
该程序运行结果如下所示:
第1次循环:内循环的第1次循环 内循环的第2次循环 内循环的第3次循环
第2次循环:内循环的第1次循环 内循环的第2次循环 内循环的第3次循环
第3次循环:内循环的第1次循环 内循环的第2次循环 内循环的第3次循环
第4次循环:内循环的第1次循环 内循环的第2次循环 内循环的第3次循环
第5次循环:内循环的第1次循环 内循环的第2次循环 内循环的第3次循环
从程序运行结果来看,在内部循环中的 break 语句仅仅终止了所在的内部循环,外部循环没有受到任何的影响。
注意:一个循环中可以有一个以上的 break 语句,但是过多的 break 语句会破坏代码结构。switch 循环语句中的 break 仅影响 switch 语句,不会影响循环。
编写一个 Java 程序,允许用户输入 6 门课程成绩,如果录入的成绩为负则跳出循环;如果录入 6 门合法成绩,则计算已有成绩之和。
使用 break 语句的实现代码如下:
public class Test25
{
public static void main(String[] args)
{
int score; //每门课的成绩
int sum=0; //成绩之和
boolean con=true; //记录录入的成绩是否合法
Scanner input=new Scanner(System.in);
System.out.println("请输入学生的姓名:");
String name=input.next(); //获取用户输入的姓名
for(int i=1;i<=6;i++)
{
System.out.println("请输入第"+i+"门课程的成绩:");
score=input.nextInt();//获取用户输入的成绩
if(score<0)
{ //判断用户输入的成绩是否为负数,如果为负数,终止循环
con=false;
break;
}
sum=sum+score; //累加求和
}
if(con)
{
System.out.println(name+"的总成绩为:"+sum);
}
else
{
System.out.println("抱歉,分数录入错误,请重新录入!");
}
}
}
运行程序,当用户录入的分数低于 0 时,则输出“抱歉,分数录入错误,请重新录入!”信息,否则打印学生的总成绩。输出结果如下所示。
请输入学生的姓名:
zhangpu
请输入第1门课程的成绩:
100
请输入第2门课程的成绩:
75
请输入第3门课程的成绩:
-8
抱歉,分数录入错误,请重新录入!
请输入学生的姓名:
zhangpu
请输入第1门课程的成绩:
100
请输入第2门课程的成绩:
68
请输入第3门课程的成绩:
73
请输入第4门课程的成绩:
47
请输入第5门课程的成绩:
99
请输入第6门课程的成绩:
84
zhangpu的总成绩为:471
在该程序中,当录入第 3 门课的成绩时,录入的成绩为负数,判断条件“score<0”为 true,执行“con=false”,用 con 来标记录入是否有误。接着执行 break 语句,执行完之后程序并没有继续执行条件语句后面的语句,而是直接退出 for 循环。之后执行下面的条件判断语句,判断 boolean 变量的 con 是否为 true,如果为 true,则打印总成绩;否则打印“抱歉,分数录入错误,请重新录入!”。
3)使用 break 语句实现 goto 的功能
break 语句可以实现 goto 的功能,并且 Java 定义了 break 语句的一种扩展形式来处理退出嵌套很深的循环这个问题。
通过使用扩展的 break 语句,可以终止执行一个或者几个任意代码块,这些代码块不必是一个循环或一个 switch 语句的一部分。同时这种扩展的 break 语句带有标签,可以明确指定从何处重新开始执行。
break 除了具有 goto 退出深层循环嵌套作用外,还保留了一些程序结构化的特性。
标签 break 语句的通用格式如下:
break label;
label 是标识代码块的标签。当执行这种形式的 break 语句时,控制权被传递出指定的代码块。被加标签的代码块必须包围 break 语句,但是它不需要直接包围 break 的块。也就是说,可以使用一个加标签的 break 语句来退出一系列的嵌套快,但是不能使用 break 语句将控制权传递到不包含 break 语句的代码块。
用标签(label)可以指定一个代码块,标签可以是任何合法有效的 Java 标识符,后跟一个冒号。加上标签的代码块可以作为 break 语句的对象,使程序在加标签的块的结尾继续执行。
下面是使用带标签的break 语句的示例。
public class GotoDemo
{
public static void main(String[] args)
{
label:for(int i=0;i<10;i++)
{
for(int j=0;j<8;j++)
{
System.out.println(j);
if(j%2!=0)
{
break label;
}
}
}
}
}
以上程序的执行结果为:
0
1
这里的 label 是标签的名称,可以为 Java 语言中任意合法的标识符。标签语句必须和循环匹配使用,使用时书写在对应的循环语句的上面,标签语句以冒号结束。如果需要中断标签语句对应的循环,可以采用 break 后面跟标签名的方式。
如在上面代码中,当 j 为 1 时,“j%2!=0”条件表达式成立,则 label 标签所代表的最外层循环终止。
(16)关于Java static的常见问题和使用误区
1)为什么要用”static“关键字?
通常来说,用 new 创建类的对象时,数据存储空间才被分配,方法才供外界调用。有时候我们只想为特定域分配单一存储空间,不考虑要创建多少对象或者说根本就不创建任何对象,有时候我们想在没有创建对象的情况下也想调用方法。在这两种情况下,static 关键字,满足了我们的需求。
2)”static“关键字是什么意思?Java 中是否可以覆盖(子类中如果创建了一个与父类中相同名称、相同返回值类型、相同参数列表的方法,只是方法体中的实现不同,以实现不同于父类的功能,这种方式被称为方法重写,又称为方法覆盖。这里了解即可,教程后面我们会详细讲解)一个 private 或者是 static 的方法?
“static”关键字表明一个成员变量或者是成员方法可以在没有所属的类的实例变量的情况下被访问。
Java 中 static 方法不能被覆盖,因为方法覆盖是基于运行时动态绑定的,而 static 方法是编译时静态绑定的。static 方法跟类的任何实例都不相关,所以概念上不适用。
3)是否可以在 static 环境中访问非 static 变量?
static 变量在 Java 中是属于类的,它在所有的实例中的值是一样的。当类被 Java 虚拟机载入的时候,会对 static 变量进行初始化。如果你的代码尝试不用实例来访问非 static 的变量,编译器会报错,因为这些变量还没有被创建出来,还没有跟任何实例关联上。
4)static 静态方法能不能引用非静态资源?
不能,new 的时候才会产生的东西,对于初始化后就存在的静态资源来说,不能引用它。
5)static 静态方法里面能不能引用静态资源?
可以,因为都是类初始化的时候加载的。
6)非静态方法里面能不能引用静态资源?
可以,非静态方法就是实例方法,那是 new 之后才产生的,那么属于类的内容它都认识。
使用误区
1)static 关键字会改变类中成员的访问权限吗?
有些初学者会将 Java 中的 static 与 C/C++ 中的 static 关键字的功能混淆了。在这里只需要记住一点,与 C/C++ 中的 static 不同,Java 中的 static 关键字不会影响到变量或者方法的作用域。在 Java 中能够影响到访问权限的只有 private、public、protected、friendly 这几个关键字。看下面的例子就明白了:
定义一个 Student 类,代码如下:
public class Student {
public static String name = "张三";
private static int age = 10;
}
定义 Main 类调用 Student 类的 age 属性,代码如下:
public class Main {
public static void main(String[] args) {
System.out.println(Student.name);
System.out.println(Student.age);
}
}
代码第 4 行会提示错误“Student.age 不可视(The field Student.age is not visible)”,这说明 static 关键字并不会改变变量和方法的访问权限。
2)能通过 this 访问静态成员变量吗?
虽然对于静态方法来说没有 this,那么在非静态方法中能够通过 this 访问静态成员变量吗?先看下面的一个例子,这段代码输出的结果是什么?
public class Main {
static int value = 33;
public static void main(String[] args) throws Exception {
new Main().printValue();
}
private void printValue() {
int value = 3;
System.out.println(this.value); // 输出 33
}
}
这里面主要考察 this 和 static 的理解。this 代表什么?this 代表当前对象,那么通过 new Main() 来调用 printValue 的话,当前对象就是通过 new Main() 生成的对象。而 static 变量是被对象所享有的,因此在 printValue 中的 this.value 的值毫无疑问是 33。在 printValue 方法内部的 value 是局部变量,根本不可能与 this 关联,所以输出结果是 33。在这里永远要记住一点:静态成员变量虽然独立于对象,但是不代表不可以通过对象去访问,所有的静态方法和静态变量都可以通过对象访问(只要访问权限足够)。
3)static 能作用于局部变量么?
在 C/C++ 中 static 是可以作用域局部变量的,但是在 Java 中切记,Java 语法规定 static 是不允许用来修饰局部变量。
(17)笔记
(18)笔记
(19)笔记
(20)常见问题
1)Java空字符串和null的区别
“”是一个长度为 0 且占内存的空字符串,在内存中分配一个空间,可以使用 Object 对象中的方法。例如:“”.toString() 等。
null 是空引用,表示一个对象的值,没有分配内存,调用 null 的字符串的方法会抛出空指针异常。例如如下代码:
String str = null;
System.out.println(str.length());
new String() 创建一个字符串对象的默认值为 “”,String 类型成员变量的初始值为 null。
空字符串 “” 是长度为 0 的字符串。可以调用以下代码检查一个字符串是否为空:
if (str.length() == 0)
或
if (str.equals(""))
空字符串是一个 Java 对象,有自己的串长度(0)和内容(空)。不过,String 变量还可以存放一个特殊的值,名为 null,这表示目前没有任何对象与该变量关联。要检查一个字符串是否为 null,要使用以下条件:
if (str == null)
有时要检查一个字符串既不是 null 也不为空串,这种情况下就需要使用以下条件:
if (str != null && str.length() != 0)
注意:首先要检查 str 不为 null。如果在一个 null 值上调用方法,会出现错误。
2) Java校验文件名和邮箱地址
public static void main(String[] args) {
boolean filecon = false; // 判断文件名是否合法
boolean emailcon = false; // 判断邮箱地址是否合法
System.out.println("************ 欢迎进入作业提交系统 ************");
Scanner input = new Scanner(System.in);
System.out.println("请输入要提交的Java文件名称:");
String name = input.next(); // 获取输入的Java文件名
System.out.println("请输入要提交到的邮箱地址:");
String email = input.next(); // 获取输入的邮箱地址
// 检查输入的文件名是否合法
int index = name.lastIndexOf('.'); // 获取"n"所在的位置
// 判断合法
if (index != -1 && name.charAt(index + 1) == 'j' && name.charAt(index + 2) == 'a'
&& name.charAt(index + 3) == 'v' && name.charAt(index + 4) == 'a') {
filecon = true;
} else {
System.out.println("输入的文件名无效!");
}
// 检查邮箱地址是否合法
if (email.indexOf('@') != 1 && email.indexOf('.') > email.indexOf('@')) {
emailcon = true;
} else {
System.out.println("输入的邮箱地址无效!");
}
// 输出校验的结果
if (filecon && emailcon) {
System.out.println("作业提交成功!");
} else {
System.out.println("作业提交失败!");
}
}
3) Java根据出生日期计算(判断)星座
白羊:0321~0420 天秤:0924~1023
金牛:0421~0521 天蝎:1024~1122
双子:0522~0621 射手:1123~1221
巨蟹:0622~0722 摩羯:1222~0120
狮子:0723~0823 水瓶:0121~0219
处女:0824~0923 双鱼:0220~0320
public static void main(String[] args) {
System.out.println("请输入您的出生年月(如 0123 表示 1 月 23 日):");
Scanner sc = new Scanner(System.in);
int monthday = sc.nextInt();
int month = monthday/100;
int day = monthday%100;
String xingzuo = "";
switch (month) {
case 1:
xingzuo = day<21?"摩羯座":"水瓶座";
break;
case 2:
xingzuo = day<20? "水瓶座":"双鱼座";
break;
case 3:
xingzuo = day<21?"双鱼座":"白羊座";
break;
case 4:
xingzuo = day<21?"白羊座":"金牛座";
break;
case 5:
xingzuo = day<22?"金牛座":"双子座";
break;
case 6:
xingzuo = day<22?"双子座":"巨蟹座";
break;
case 7:
xingzuo = day<23?"巨蟹座":"狮子座";
break;
case 8:
xingzuo = day<24?"狮子座":"处女座";
break;
case 9:
xingzuo = day<24?"处女座":"天秤座";
break;
case 10:
xingzuo = day<24?"天秤座":"天蝎座";
break;
case 11:
xingzuo = day<23?"天蝎座":"射手座";
break;
case 12:
xingzuo = day<22?"射手座":"摩羯座";
break;
}
System.out.println("您的星座是:" +xingzuo);
}
4) Java判断闰年平年并输出某月的天数
所谓闰年,就是指 2 月有 29 天的那一年。闰年同时满足以下条件:
- 年份能被 4 整除。
- 年份若是 100 的整数倍,须被 400 整除,否则是平年。
例如,1900 年能被 4 整除,但是因为其是 100 的整数倍,却不能被 400 整除,所以是平年;而 2000 年就是闰年;1904 年和 2004 年、2008 年等直接能被 4 整除且不能被 100 整除,都是闰年;2014 是平年。
下面综合本章学习的知识来编写一个判断闰年的案例,其主要功能如下:
- 判断用户输入的年份是不是闰年。
- 根据年份和月份输出某年某月的天数。
实现步骤分为以下几步:
(1) 新建一个类并在该类中导入需要的 java.util.Scanner 类,同时需要创建该类的入口方法 main(),其实现代码如下:
import java.util.Scanner;
public class Test27 {
public static void main(String[] args) {
// 在这里编写其他代码
}
}
(2) 在 main() 方法中编写 Java 代码,获取用户输入的年份和月份,其实现代码如下:
Scanner sc=new Scanner(System.in);
System.out.println("请输入年份(注: 必须大于 1990 年):");
int year=sc.nextInt();
System.out.println("请输入月份:");
int month=sc.nextInt();
(3) 根据用户输入的年份,判断该年份是闰年还是平年,其实现代码如下:
boolean isRen;
if((year%4==0&&year%100!=0)||(year%400==0)) {
System.out.println(year+"闰年");
isRen=true;
} else {
System.out.println(year+"平年");
isRen=false;
}
(4) 根据用户输入的月份,判断该月的天数,其实现代码如下:
int day=0;
switch(month) {
case 1:
case 3:
case 5:
case 7:
case 8:
case 10:
case 12:
day=31;
break;
case 4:
case 6:
case 9:
case 11:
day=30;
break;
default:
if(isRen) {
day=29;
} else {
day=28;
}
break;
}
System.out.println(year+"年"+month+"月共有"+day+"天");
```# 系列文章目录
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
例如:第一章 Python 机器学习入门之pandas的使用
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
@[TOC](文章目录)
# 前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
提示:以下是本篇文章正文内容,下面案例可供参考
# 一、pandas是什么?
示例:pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。
# 二、使用步骤
## 1.引入库
代码如下(示例):
```c
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
2.读入数据
代码如下(示例):
data = pd.read_csv(
'https://labfile.oss.aliyuncs.com/courses/1283/adult.data.csv')
print(data.head())
该处使用的url网络请求的数据。
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。