目录
写在前面
一、 torch.optim.SGD 随机梯度下降
SGD代码
SGD算法解析
1.MBGD(Mini-batch Gradient Descent)小批量梯度下降法
2.Momentum动量
3.NAG(Nesterov accelerated gradient)
SGD总结
二、torch.optim.ASGD随机平均梯度下降
三、torch.optim.Rprop
四、torch.optim.Adagrad 自适应梯度
Adagrad 代码
Adagrad 算法解析
AdaGrad总结
写在前面
优化器时深度学习中的重要组件,在深度学习中有举足轻重的地位。在实际开发中我们并不用亲手实现一个优化器,很多框架都帮我们实现好了,但如果不明白各个优化器的特点,就很难选择适合自己任务的优化器。接下来我会开一个系列,以Pytorch为例,介绍所有主流的优化器,如果都搞明白了,对优化器算法的掌握也就差不多了。
作为系列的第一篇文章,本文介绍Pytorch中的SGD、ASGD、Rprop、Adagrad,其中主要介绍SGD和Adagrad。因为这四个优化器出现的比较早,都存在一些硬伤,而作为现在主流优化器的基础又跳不过,所以作为开端吧。
我们定义一个通用的思路框架,方便在后面理解各算法之间的关系和改进。首先定义待优化参数  ,目标函数
,目标函数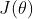 ,学习率为
,学习率为  ,然后我们进行迭代优化,假设当前的epoch为
,然后我们进行迭代优化,假设当前的epoch为 ,参数更新步骤如下:
,参数更新步骤如下:
1. 计算目标函数关于当前参数的梯度:
 (1)
(1)
2. 根据历史梯度计算一阶动量和二阶动量:
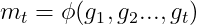 (2)
(2)
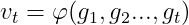 (3)
(3)
3. 计算当前时刻的下降梯度:
 (4)
(4)
4. 根据下降梯度进行更新:
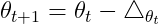 (5)
(5)
下面介绍的所有优化算法基本都能套用这个流程,只是式子(4)的形式会有变化。
一、 torch.optim.SGD 随机梯度下降
该类可实现 SGD 优化算法,带动量 的SGD 优化算法和带 NAG(Nesterov accelerated gradient)的 SGD 优化算法,并且均可拥有 weight_decay(权重衰减) 项。
SGD代码
'''
params(iterable)- 参数组,优化器要优化的那部分参数。
lr(float)- 初始学习率,可按需随着训练过程不断调整学习率。
momentum(float)- 动量,通常设置为 0.9,0.8
dampening(float)- dampening for momentum ,暂时不了其功能,在源码中是这样用的:buf.mul_(momentum).add_(1 - dampening, d_p),值得注意的是,若采用nesterov,dampening 必须为 0.
weight_decay(float)- 权值衰减系数,也就是 L2 正则项的系数
nesterov(bool)- bool 选项,是否使用 NAG(Nesterov accelerated gradient)
'''
class torch.optim.SGD(params, lr=