ECCV2022 Oral | MaskCLIP
【写在前面】
对比语言图像预训练(CLIP)在开放词汇零样本图像识别方面取得了显着突破。许多最近的研究利用预训练的 CLIP 模型进行图像级分类和操作。在本文中,作者希望检验 CLIP 在像素级密集预测方面的内在潜力,特别是在语义分割方面。为此,作者通过最少的修改展示了 MaskCLIP 在没有注释和微调的情况下,在跨各种数据集的开放概念上产生了令人信服的分割结果。通过添加伪标签和自训练,MaskCLIP+ 大大超过了 SOTA 转导零样本语义分割方法,例如,PASCAL VOC/PASCAL Context/COCO Stuff 上未见类的 mIoU 从 35.6/20.7/30.3 提高到 86.1/66.7 /54.7。作者还测试了 MaskCLIP 在输入损坏下的鲁棒性,并评估了它在区分细粒度对象和新概念方面的能力。本文的发现表明,MaskCLIP 可以作为密集预测任务的新可靠监督来源,以实现无注释分割。
1. 论文和代码地址

Extract Free Dense Labels from CLIP
论文地址:https://arxiv.org/abs/2112.01071
代码地址:https://github.com/chongzhou96/MaskCLIP
2. 动机
诸如 CLIP之类的大规模视觉语言预训练模型捕获富有表现力的视觉和语言特征。各种下游视觉任务,例如文本驱动的图像处理、图像字幕、视图合成和对象检测,都试图利用这些特征来提高通用性和鲁棒性。例如,基于原始 CLIP 特征进行零样本图像分类会导致一种与完全监督对应物的性能相匹配的竞争方法。
在本文中,作者进一步探索了 CLIP 特征在语义分割等像素级密集预测任务中的适用性。这项调查是有意义的,因为以前的研究主要利用 CLIP 特征作为全局图像表示。相比之下,本文的探索希望确定 CLIP 特征在封装对象级和局部语义以进行密集预测的程度。与对标志性图像进行图像分类的传统预训练任务不同,CLIP 从复杂场景的图像及其自然语言描述中学习,这(1)鼓励它将局部图像语义嵌入其特征中,(2)使其能够学习开放词汇表中的概念,以及(3)捕获丰富的上下文信息,例如某些对象的共现/关系和空间位置的先验。作者相信所有这些优点都极大地促进了其在密集预测任务中的潜力。
在本文中,总结了利用 CLIP 特征进行密集预测的成功和失败经验。作者发现不破坏原始 CLIP 特征空间中的视觉语言关联至关重要。在本文早期的探索中,作者在尝试微调 CLIP 的图像编码器以进行分割任务时遇到了失败,例如,使用 CLIP 的图像编码器的权重初始化 DeepLab并微调分割的主干。此外,作者发现避免任何不必要的尝试操纵 CLIP 的文本嵌入是至关重要的。这种方法在分割看不见的类时会失败。
在名为 MaskCLIP 的成功模型中,作者展示了可以简单地从 CLIP 的图像编码器中提取密集的patch级特征,即最后一个注意层的值特征,而不会破坏视觉语言关联。密集预测的分类权重,本质上是 1×1 卷积,可以直接从 CLIP 文本编码器的文本嵌入中获得,无需任何刻意的映射。在实证研究中,MaskCLIP 在通过 mIoU 度量和定性结果测量的定量性能方面产生了合理的预测。此外,MaskCLIP 可以基于 CLIP 的所有变体,包括 ResNets 和 ViTs。作者提供了两个流行的骨干网络之间的并排比较。作者还为 MaskCLIP 提出了两种掩码细化技术以进一步提高其性能,即key smoothing和prompt denoising,两者都不需要训练。具体来说,键平滑(key smoothing)计算不同块的键特征(最后一个注意层)之间的相似性,用于平滑预测。提示去噪(prompt denoising)去除了图像中不太可能存在的类别的提示,因此干扰更少,预测变得更准确。
然而,MaskCLIP 的分割能力很难进一步提高,因为它的架构仅限于 CLIP 的图像编码器。为了从架构约束中放松 MaskCLIP 并结合更高级的架构,例如 PSPNet和 DeepLab,作者注意到,可以在训练时部署它,而不是在推理时部署 MaskCLIP,它用作提供高质量伪标签的通用且稳健的注释器。与标准的自训练策略一起生成的模型,称为 MaskCLIP+,实现了惊人的性能。

除了无注释和开放词汇分割之外,MaskCLIP+ 还可以应用于零样本语义分割任务,其中 MaskCLIP 只为看不见的类生成伪标签。在三个标准分割基准上,即 PASCAL VOC 、PASCAL Context 和 COCO Stuff,MaskCLIP+ 在未见类的 mIoU 方面将最先进的结果提高了50.5%,46% 和 24.4%(35.6 → 86.1、20.7 → 66.7 和 30.3 → 54.7)。由于 CLIP 特征的通用性和鲁棒性,MaskCLIP+ 可以很容易地应用于语义分割的各种扩展设置,包括细粒度类(例如,白色汽车和红色巴士等属性条件类)或新概念(例如蝙蝠侠和小丑如上图所示),以及中度损坏输入的分割。
语义分割因其对标记训练数据的高度依赖而被限制。已经探索了许多方法来绕过这种严格的要求,例如,通过使用图像标签、边界框和涂鸦等弱标签。本文的研究首次表明,通过大规模视觉语言预训练学习的特征可以很容易地用于促进开放词汇密集预测。所提出的模型 MaskCLIP 在为训练现有方法提供丰富且有意义的密集伪标签方面显示出巨大的潜力。
3. 方法
本文的研究是探索 CLIP 特征对像素级密集预测任务的适用性的早期尝试。作者首先简要介绍 CLIP 和一个简单的解决方案作为初步,然后详细介绍提议的 MaskCLIP。
3.1 Preliminary on CLIP
CLIP是一种视觉语言预训练方法,它从大规模的原始网络策划的图像-文本对中学习视觉和语言表示。它由一个图像编码器 $\mathcal{V}(\cdot)$和一个文本编码器$\mathcal{T}(\cdot)$组成,两者联合训练以分别将输入图像和文本映射到一个统一的表示空间中。CLIP采用对比学习作为其训练目标,将ground-truth图文对视为正样本,将不匹配的图文对构造为负样本。在实践中,文本编码器被实现为 Transformer。至于图像编码器,CLIP 提供了两种替代实现,即 Transformer 和具有全局注意力池化层的 ResNet。本文的方法可以基于两种编码器架构。
作者认为 CLIP 在学习将图像内容与自然语言描述相关联时,在其特征中固有地嵌入了局部图像语义,后者包含跨多个粒度的复杂而密集的语义指导。例如,为了正确识别图像对应于当裁判看着时击球手准备挥杆的描述,CLIP 必须将图像语义划分为局部片段,并将图像语义与单个提到的概念(如人)正确对齐, bat, swing, patch, man at bat, man at patch 和 man ready to swing,而不是将图像作为一个整体来处理。这种独特性在仅使用图像标签的训练中是不存在的。
3.2 Conventional Fine-Tuning Hinders Zero-Shot Ability
当前训练分割网络的实际管道是(1)使用 ImageNet 预训练的权重初始化主干网络,(2)添加具有随机初始化权重的特定于分割的网络模块,以及(3)联合微调调整主干和新添加的模块。
遵循这些标准步骤来调整 CLIP 进行分割是很自然的。在这里,作者通过在 DeepLab上应用这个管道和两个特定于 CLIP 的修改来开始本文的探索。具体来说,作者首先将 ImageNet 预训练的权重替换为 CLIP 图像编码器的权重。其次,采用映射器 M 将 CLIP 的文本嵌入映射到 DeepLab 分类器(最后一个 1×1 卷积层)的权重。修改后的模型可以表述如下:
$$ \begin{aligned} \operatorname{DeepLab}(x) &=\mathcal{C}_{\phi}\left(\mathcal{H}\left(\mathcal{V}_{* l}(x)\right)\right), \\ \phi &=\mathcal{M}(t), \end{aligned} $$
其中$\mathcal{V}_{* l}(\cdot)$表示 DeepLab 主干,它是一个扩大了 l 倍的 ResNet。$ H(·) $表示随机初始化的ASPP模块,$\mathcal{C}_{\phi}(\cdot)$是DeepLab分类器,其权重记为$\phi$,由CLIP的文本嵌入通过映射器M确定。理想情况下,通过更新分类器权重与相应的文本嵌入,适应的 DeepLab 能够在不重新训练的情况下分割不同的类。
为了评估这个修改后的 DeepLab 在可见和不可见类上的分割性能,作者在数据集中的一个类子集上对其进行训练,将其余类视为不可见类。作者已经尝试了一系列映射器架构。尽管它们在可见类上表现良好,但在所有这些情况下,修改后的 DeepLab 都未能以令人满意的性能分割不可见的类。
作者假设这主要是因为 CLIP 特征的原始视觉语言关联已被打破:(1)主干在网络架构方面与图像编码器略有不同; (2) 从图像编码器初始化的权重在微调期间已经更新; (3) 引入了一个额外的映射器,它仅在所见类的数据上进行训练,因此导致通用性不足。
3.3 MaskCLIP
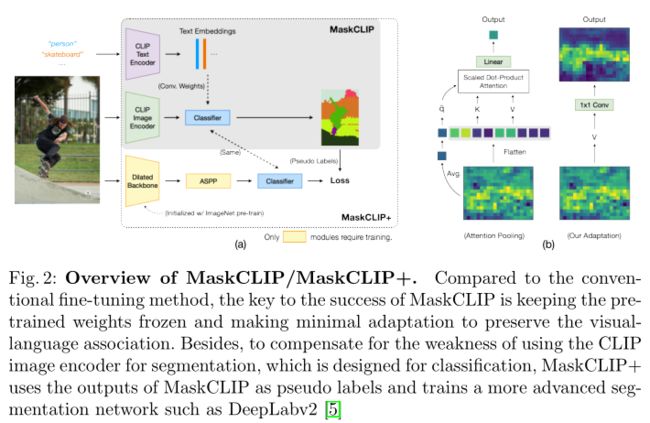
微调尝试失败,作者转向避免引入额外参数和修改 CLIP 特征空间的解决方案。为此,重新审视了 CLIP 的图像编码器,尤其是其独特的全局注意力池化层。如上图(b) 所示,与传统的全局平均池化不同,CLIP 的图像编码器采用 Transformer 式的多头注意力层,其中全局平均池化的特征作为查询,每个空间位置的特征生成一个 key-value对。因此,该层的输出是输入特征图的空间加权和,然后是线性层 $F(·)$:
$$ \begin{aligned} \operatorname{AttnPool}(\bar{q}, k, v) &=\mathcal{F}\left(\sum_{i} \operatorname{softmax}\left(\frac{\bar{q} k_{i}^{\top}}{C}\right) v_{i}\right) \\ &=\sum_{i} \operatorname{softmax}\left(\frac{\bar{q} k_{i}^{\top}}{C}\right) \mathcal{F}\left(v_{i}\right), \\ \bar{q}=\operatorname{Emb}_{\mathrm{q}}(\bar{x}), k_{i} &=\operatorname{Emb}_{\mathrm{k}}\left(x_{i}\right), v_{i}=\operatorname{Emb}_{\mathrm{v}}\left(x_{i}\right), \end{aligned} $$
其中 C 是一个常数比例因子,而 Emb(·) 表示一个线性嵌入层。$x_{i}$表示空间位置 i 的输入特征,$\bar{x}$是所有$x_{i}$的平均值。 Transformer 层的输出作为整个图像的综合表示。作者认为这是可能的,因为在每个空间位置计算的$\mathcal{F}\left(v_{i}\right)$已经捕获了丰富的局部语义响应,这些响应与 CLIP 文本嵌入中的标记很好地对应。
基于这样的假设,如上图(b) 所示,作者在新尝试中直接修改 CLIP 的图像编码器:(1) 删除查询和关键嵌入层; (2) 将值嵌入层和最后一个线性层重新组合成两个各自的 1×1 卷积层。此外,保持文本编码器不变,它以目标类的提示作为输入。每个类的结果文本嵌入用作分类器。作者将生成的模型命名为 MaskCLIP,因为它产生像素级掩码预测,而不是全局图像级预测。然后,作者在各种标准分割基准以及网络爬取图像上评估 MaskCLIP。MaskCLIP 无需任何微调或注释即可输出合理的结果。更多关于 mIoU 指标的定性结果和定量结果包含在实验部分。
有人可能会争辩说,由于全局注意力池是一个自注意力层,即使没有修改,它也可以生成密集的特征。然而,由于查询$\bar{q}$ 是在 CLIP 预训练期间训练的唯一查询,因此这种朴素的解决方案失败了。作者将此解决方案视为基线,并在实验中将其结果与本文的结果进行比较。此外,ViT 中的 Transformer 层与全局注意力池非常相似。实际上,仅有的两个区别是:(1)全局查询是由一个特殊的 [CLS] token生成的,而不是所有空间位置的平均值; (2) Transformer 层有残差连接。因此,通过用$q[\mathrm{cls}]$替换$\bar{q}$并将输入 x 添加到输出中,MaskCLIP 可以与 ViT 主干一起工作。
尽管与现有分割方法相比,MaskCLIP 很简单,但所提出的方法具有继承自 CLIP 的多个独特优点。首先,MaskCLIP 可用作自由分割标注器,为使用有限标签的分割方法提供丰富而新颖的监督信号。其次,由于在MaskCLIP中保留了CLIP的视觉语言关联,它自然具有分割开放词汇类的能力,以及由自由形式的短语描述的细粒度类,如白车和红巴士。第三,由于 CLIP 是在原始网络策划图像上训练的,因此 CLIP 对自然分布偏移和输入损坏表现出极大的鲁棒性。作者验证 MaskCLIP 在一定程度上保留了这种鲁棒性。
为了进一步提高 MaskCLIP 的性能,作者提出了两种细化策略,即键平滑和prompt去噪。除了$\bar{q}$,关键特征$k_i$也在CLIP预训练期间得到训练。然而,在原始的 MaskCLIP 中,$k_i$是简单地丢弃。因此,作者在这里寻求利用这些信息来改进最终输出。键特征可以看作是对应patch的描述符,因此具有相似键特征的patch应该产生相似的预测。有了这个假设,作者提出通过以下方式平滑预测:
$$ \operatorname{pred}_{i}=\sum_{j} \cos \left(\frac{k_{i}}{\left\|k_{i}\right\|_{2}}, \frac{k_{j}}{\left\|k_{j}\right\|_{2}}\right) \operatorname{pred}_{i} $$
此外,作者还观察到,在处理许多目标类别时,由于只有一小部分类别出现在单个图像中,其余类别实际上是干扰因素并破坏了性能。因此,作者提出了提示去噪,如果它在所有空间位置的类置信度都小于阈值 t = 0.5,则删除带有目标类的提示。
3.4 MaskCLIP+
虽然 MaskCLIP 不需要任何训练,但它的网络架构是刚性的,因为它采用了 CLIP 的图像编码器。为了从这种约束中放松它并受益于为分割量身定制的更先进的架构,例如 DeepLab和 PSPNet,作者提出了 MaskCLIP+。 MaskCLIP+ 不是直接应用 MaskCLIP 进行测试时间预测,而是将其预测视为训练时间伪真实标签。结合采用的自训练策略,MaskCLIP+ 不受其骨干架构的限制。如上图(a) 所示,作者将 DeepLabv2作为 MaskCLIP+ 的主干,以确保与以前的分割方法进行公平比较。
在 MaskCLIP+ 中,作者利用 MaskCLIP 的预测来指导另一个目标网络的训练,该目标网络包含为分割任务量身定制的架构。与目标网络并行,作者将相同的预处理图像输入提供给 MaskCLIP,并使用 MaskCLIP 的预测作为伪真实标签来训练目标网络。此外,作者将目标网络的分类器替换为 MaskCLIP 的分类器,以保留网络对开放词汇预测的能力。
MaskCLIP 引导学习也适用于零样本分割设置。具体来说,虽然观察到可见和不可见类的像素,但只有可见类的注释可用。在这种情况下,只使用 MaskCLIP 为未标记的像素生成伪标签。与 SOTA 方法相比,MaskCLIP+ 在三个标准基准(即 PASCAL VOC 2012、PASCAL Context 和 COCO Stuff)中获得了显着更好的结果,其中 MaskCLIP+ 的结果甚至与完全-监督基线。
作者注意到一些相关的尝试,针对目标检测,在 CLIP 的图像级视觉特征和目标模型的特征之间进行知识蒸馏。与这样的特征级指导不同,作者在本文中采用伪标签。这是因为本文的目标网络具有分段定制的架构,在结构上与 CLIP 的图像编码器不同。因此,通过特征匹配进行蒸馏可能是一种次优策略。事实上,在零样本设置下,这种特征级指导确实会导致可见类和不可见类的性能之间存在冲突。相反,通过在 MaskCLIP+ 中采用伪标签,作者没有观察到所见类的任何性能下降。
4.实验
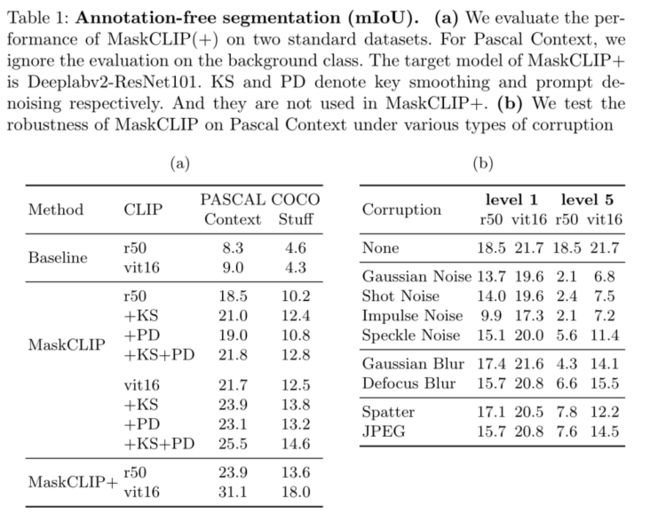
上表展示了无标注分割的实验结果。

PASCAL上的定性实验结果。

网络图片上的定性结果。
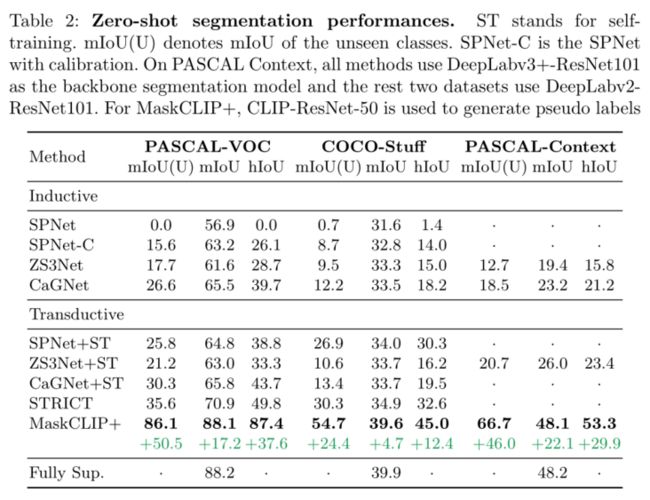
零样本分割性能。
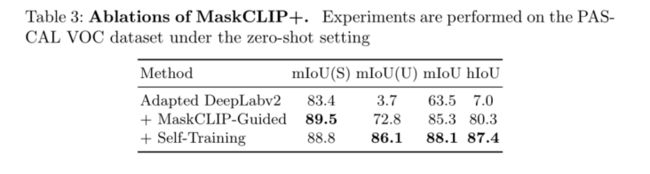
MaskCLIP+的消融。
5. 总结
本文介绍了作者在语义分割中应用 CLIP 的探索,作为研究预训练视觉语言模型在像素级密集预测任务中的适用性的早期尝试。虽然传统的微调范式无法从 CLIP 中受益,但作者发现 CLIP 的图像编码器已经具备直接作为分割模型工作的能力。由此产生的模型,称为 MaskCLIP,可以很容易地部署在各种语义分割设置上,而无需重新训练。在 MaskCLIP 的成功之上,作者进一步提出了 MaskCLIP+,它利用 MaskCLIP 为未标记的像素提供训练时间伪标签,因此可以应用于更多的分割定制架构,而不仅仅是 CLIP 的图像编码器。在标准的换能零样本分割基准上,MaskCLIP+ 显着改进了之前的 SOTA 结果。更重要的是,MaskCLIP+ 可以很容易地用于分割更具挑战性的看不见的类别,例如名人和动画角色。
【技术交流】
已建立深度学习公众号——FightingCV,关注于最新论文解读、基础知识巩固、学术科研交流,欢迎大家关注!!!
请关注FightingCV公众号,并后台回复ECCV2022即可获得ECCV中稿论文汇总列表。
推荐加入FightingCV交流群,每日会发送论文解析、算法和代码的干货分享,进行学术交流,加群请添加小助手wx:FightngCV666,备注:地区-学校(公司)-名称
面向小白的顶会论文核心代码库:https://github.com/xmu-xiaoma666/External-Attention-pytorch
面向小白的YOLO目标检测库:https://github.com/iscyy/yoloair
面向小白的顶刊顶会的论文解析:https://github.com/xmu-xiaoma666/FightingCV-Paper-Reading

【赠书活动】
为感谢各位老粉和新粉的支持,FightingCV公众号将在9月10日包邮送出4本《深度学习与目标检测:工具、原理与算法》来帮助大家学习,赠书对象为当日阅读榜和分享榜前两名。想要参与赠书活动的朋友,请添加小助手微信FightngCV666(备注“城市-方向-ID”),方便联系获得邮寄地址。

本文由mdnice多平台发布