一、什么是宏函数?通过宏定义的函数是宏函数。如下,编译器在预处理阶段会将Add(x,y)替换为((x)*(y))#defineAdd(x,y)((x)*(y))#defineAdd(x,y)((x)*(y))intmain(){inta=10;intb=20;intd=10;intc=Add(a+d,b)*2;cout<
C语言如何定义宏函数?
小九格物
c语言
在C语言中,宏函数是通过预处理器定义的,它在编译之前替换代码中的宏调用。宏函数可以模拟函数的行为,但它们不是真正的函数,因为它们在编译时不会进行类型检查,也不会分配存储空间。宏函数的定义通常使用#define指令,后面跟着宏的名称和参数列表,以及宏展开后的代码。宏函数的定义方式:1.基本宏函数:这是最简单的宏函数形式,它直接定义一个表达式。#defineSQUARE(x)((x)*(x))2.带参
libyuv之linux编译
jaronho
Linuxlinux运维服务器
文章目录一、下载源码二、编译源码三、注意事项1、银河麒麟系统(aarch64)(1)解决armv8-a+dotprod+i8mm指令集支持问题(2)解决armv9-a+sve2指令集支持问题一、下载源码到GitHub网站下载https://github.com/lemenkov/libyuv源码,或者用直接用git克隆到本地,如:gitclonehttps://github.com/lemenko
在Ubuntu中编译含有JSON的文件出现报错
芝麻糊76
Linuxkill_buglinuxubuntujson
在ubuntu中进行JSON相关学习的时候,我发现了一些小问题,决定与大家进行分享,减少踩坑时候出现不必要的时间耗费截取部分含有JSON部分的代码进行展示char*str="{\"title\":\"JSONExample\",\"author\":{\"name\":\"JohnDoe\",\"age\":35,\"isVerified\":true},\"tags\":[\"json\",\"
openssl+keepalived安装部署
_小亦_
项目部署keepalivedopenssl
文章目录OpenSSL安装下载地址编译安装修改系统配置版本Keepalived安装下载地址安装遇到问题安装完成配置文件keepalived运行检查运行状态查看系统日志修改服务service重新加载systemd检查配置文件语法错误OpenSSL安装下载地址考虑到后面设备可能没法连接到外网,所以采用安装包的方式进行部署,下载地址:https://www.openssl.org/source/old/
Python编译器
鹿鹿~
Python编译器Pythonpython开发语言后端
嘿嘿嘿我又来了啊有些小盆友可能不知道Python其实是有编译器的,也就是PyCharm。你们可能会问到这个是干嘛的又不可以吃也不可以穿好像没有什么用,其实你还说对了这个还真的不可以吃也不可以穿,但是它用来干嘛的呢。用来编译你所打出的代码进行运行(可能这里说的有点不对但是只是个人认为)现在我们来说说PyCharm是用来干嘛的。PyCharm是一种PythonIDE,带有一整套可以帮助用户在使用Pyt
JAVA·一个简单的登录窗口
MortalTom
java开发语言学习
文章目录概要整体架构流程技术名词解释技术细节资源概要JavaSwing是Java基础类库的一部分,主要用于开发图形用户界面(GUI)程序整体架构流程新建项目,导入sql.jar包(链接放在了文末),编译项目并运行技术名词解释一、特点丰富的组件提供了多种可视化组件,如按钮(JButton)、文本框(JTextField)、标签(JLabel)、下拉列表(JComboBox)等,可以满足不同的界面设计
ESP32-C3入门教程 网络篇⑩——基于esp_https_ota和MQTT实现开机主动升级和被动触发升级的OTA功能
小康师兄
ESP32-C3入门教程https服务器esp32OTAMQTT
文章目录一、前言二、软件流程三、部分源码四、运行演示一、前言本文基于VSCodeIDE进行编程、编译、下载、运行等操作基础入门章节请查阅:ESP32-C3入门教程基础篇①——基于VSCode构建HelloWorld教程目录大纲请查阅:ESP32-C3入门教程——导读ESP32-C3入门教程网络篇⑨——基于esp_https_ota实现史上最简单的ESP32OTA远程固件升级功能二、软件流程
sublime个人设置
bawangtianzun
sublimetext编辑器
如何拥有jiangly蒋老师同款编译器(sublimec++配置竞赛向)_哔哩哔哩_bilibiliSublimeText4的安装教程(新手竞赛向)-知乎(zhihu.com)创建文件自动保存为c++打开SublimeText软件。转到"Tools"(工具)>"Developer"(开发者)>"NewPlugin"(新建插件)。在打开的新文件中,粘贴以下代码:importsublimeimport
编译Windows平台的Nginx+ngx_http_proxy_connect_module
Grovvy_Deng
windowsnginxhttp
编译Windows平台的Nginx+ngx_http_proxy_connect_module背景:由于公司的正向出局代理是windows机器。机器上的Squid不稳定,打算替换成nginx+ngx_http_proxy_connect_module实现。通过几天痛苦的尝试,最后参考了github大神项目通过在线CICD工具编译window平台可用的ng。步骤:获取git可识别的patch由于CI
【nginx】ngx_http_proxy_connect_module 正向代理
等风来不如迎风去
网络服务入门与实战nginxhttp运维
50.65无法访问服务器,(403错误)50.196可以访问服务器。那么,配置65通过196访问。需要一个nginx作为代理【nginx】搭配okhttp配置反向代理发送原生的nginx是不支持okhttp的CONNECT请求的。大神竟然给出了一个java工程GINX编译ngx_http_proxy_connect_module及做正向代理是linux构建的。是windows构建的:编译Windo
Go编程语言前景怎么样?参加培训好就业吗
QFdongdong
Go语言专门针对多处理器系统应用程序的编程进行了优化,使用Go编译的程序可以媲美C或C++代码的速度,而且更加安全、支持并行进程。不仅可以开发web,可以开发底层,目前知乎就是用golang开发。区块链首选语言就是go,以-太坊,超级账本都是基于go语言,还有go语言版本的btcd.Go的目标是希望提升现有编程语言对程序库等依赖性(dependency)的管理,这些软件元素会被应用程序反复调用。由
linux gcc 格式,Linux下gcc与gdb简介
神奇的战士
linuxgcc格式
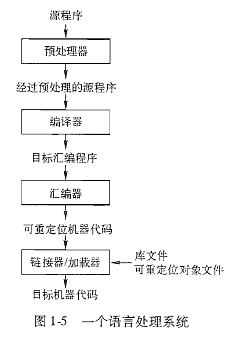
gcc编译器可以将C、C++等语言源程序、汇编程序编译、链接成可执行程序。gdb是GNU开发的一个Unix/Linux下强大的程序调试工具。linux下没有后缀名的概念。但gcc根据文件的后缀来区别输入文件的类别:.cC语言源代码文件.a由目标文件构成的库文件.C、.cc、.cppC++源码文件.h头文件.i经过预处理之后的C语言文件.ii经过预处理之后的C++文件.o编译后的目标文件.s汇编源码
Linux中GCC与GDB 常用命令详解
Dijkstra's Monk-ey
Linux与安全linuxgdbshell安全c语言
GCC和GDB常用命令详解GCC常用的选项GDBLINUX下编程,少不了和GCC,GDB打交道,现在总结下常用命令,掌握这些足够用了。GCC常用的选项选项语义-o指定生成的输出文件-E仅执行编译预处理gcc的-E选项,可以让编译器在预处理后停止,并输出预处理结果。-S将C代码转换为汇编代码gcc的-S选项,表示在程序编译期间,在生成汇编代码后停止-wall显示警告信息-c生成目标文件(.o),仅执
Java【泛型】
SkyrimCitadelValinor
Java基础java
Java泛型的概述不同类的数据如果封装方法相同,不必为每一种类单独定义一个类,只需定义一个泛型类,减少类的声明,提高编程效率。通过准确定义泛型类,可避免对象类型转换时产生的错误。泛型又提供了一种类型安全检测机制,只有数据类型相匹配的变量才能正常的赋值,否则编译器就不通过。Java中的泛型与C++类模板的作用相同,但是编译方式不同,Java泛型类只会生成一部分目标代码,牺牲运行速度,而C++的类模板
Makefile问答之 04 优化异常与警告设置
捕鲸叉
Linux使用Linux系统编程Makefilelinux
Makefile怎样指定优化选项,包括编译和链接优化,常用的选项有哪些?在Makefile中,你可以通过设置编译器和链接器的选项来指定优化选项。优化选项可以分为编译优化和链接优化,以下是如何在Makefile中指定这些选项,以及一些常用的选项。示例Makefile#编译器CC=gcc#编译选项CFLAGS=-Wall-O2#链接选项LDFLAGS=-O2#需要链接的库LDLIBS=#目标文件TAR
MacOS Catalina 从源码构建Qt6.2开发库之01: 编译Qt6.2源代码
捕鲸叉
QTmacosc++QT
安装xcode,cmake,ninjabrewinstallnodemac下安装OpenGL库并使之对各项目可见在macOS上安装OpenGL通常涉及到安装一些依赖库,如MGL、GLUT或者是GLEW等,同时确保LLVM的OpenGL框架和相关工具链的兼容性。以下是一个基本的安装步骤,你可以在终端中执行:安装Homebrew(如果还没有安装的话):/bin/bash-c"$(curl-fsSLht
Linux命令行基础——软件包管理
HHwxtx
linux运维服务器
1.软件包管理的发展初始阶段最早的软件包管理可以追溯到Unix系统的早期版本。在那时,软件通常以源代码的形式分发,并由系统管理员手动编译和安装。这种方式的管理比较原始和繁琐,因为每次安装都需要手动解决依赖关系和编译问题。软件包的引入为了简化安装过程,软件包被引入Linux,它将软件及其所有文件和资源打包在一起的集合,通常包括可执行文件、库文件、配置文件、文档和元数据(如软件名称、版本号、依赖关系等
【编译原理】方舟编译技术课程 — 词法分析
CSU_THU_SUT
编译原理编译器编译原理llvm
打开目录阅读更佳参考视频:方舟·编译技术入门与实战以及西交冯博琴老师的相关视频编译的过程包括词法分析(分析程序符号)、语法分析(分析语法单位)、中间代码生成、代码优化和目标代码生成。一、编译过程各部分的任务(1)词法分析:输入源程序,扫描分解源程序字符串,识别五类符号,包括定义符、标识符、运算符、界符和常数,转为单词符号。(2)语法分析:在词法分析基础上,将单词符号转为语法单位(如短句、子句、句子
JVM简介
林小果呀
jvmjvmjava开发语言
JVM简介JVM本质上是一个运行在计算机上的程序,他的职责是运行Java字节码文件。JVM功能解释和运行:对字节码文件中的指令,实时的解释成机器码,让计算机执行内存管理:自动为对象、方法等分配内存自动的垃圾回收机制,回收不再使用的对象即时编译:对热点代码进行优化,提升执行效率常见的JVM
Orange Pi编译脚本的分析
点点吃得太多了
linuxlinuxbash
脚本的运行流程/scripts/main.sh变量设置DEST=“${SRC}”/outputREVISION=“2.2.2”DOWNLOAD_MIRROR==“china”NTP_SERVER=“cn.pool.ntp.org”通过网络校准您计算机上的时钟BUILD_ALLCOLUMNS,LINESTTY_X,TTY_YLANGUAGE=“en_US:en”CONSOLE_CHAR=“UTF-8
Java泛型编程
shymoy
java开发语言
文章目录为什么需要泛型如何实现技术细节泛型数组泛型类型实现接口接收参数小结为什么需要泛型如果为每一种类型都写一个类来适配,会造成code冗长且难读,所以需要写一个同一的抽象的方法来实现,并让编译器自动的传入这些类型。如何实现通常放在类后面的尖括号里publicclassGenertic{}也可以指代多个publicclassGenertic{}这个类中的变量都可以用K和V来表示了泛型不仅可以应用在
【Unity基础】如何选择脚本编译方式Mono和IL2CPP?
tealcwu
Unity基础unity游戏引擎
Edit->ProjectSettings->Player在Unity中,ScriptingBackend决定了项目的脚本编译方式,即如何将C#代码转换为可执行代码。Unity提供了两种主要的ScriptingBackend选项:Mono和IL2CPP。它们之间的区别影响了项目的性能、平台支持、编译时间和调试体验。以下是两者的详细对比:1.Mono简介:Mono是Unity最早使用的脚本后端,基于
C# Tuple、ValueTuple
語衣
C#知识补充c#
栏目总目录TupleTuple是C#4.0引入的一个新特性,主要用于存储一个固定数量的元素序列,且这些元素可以具有不同的类型。Tuple是一种轻量级的数据结构,非常适合用于临时存储数据,而无需定义完整的类或结构体。优点简便性:可以快速创建一个包含多个不同类型数据的对象,而无需定义新的类或结构体。灵活性:元素数量和类型在编译时确定,但可以在不同上下文中重复使用不同元素的Tuple。缺点性能:作为引用
树莓派交叉编译基础操作(带wiringPi库)
小小匠IT
树莓派linuxubuntu
一:交叉编译是什么,为什么要交叉编译(1)交叉编译是什么?交叉编译:是在一个平台上生成另一个平台上的可执行代码。我们在windows上面编写C51代码,并编译成可执行代码,如xx.hex,是在c51上面运行,不是在windows上面运行我们在ubuntu上面编写树莓派的代码,并编译成可执行代码,如a.out,是在树莓派上面运行,不是在ubuntulinux上面运行编译:是在一个平台上生成在该平台上
python 编译器spyder 安装_离线安装spyder的Python环境
weixin_39552037
python编译器spyder安装
一、介绍:要求在不联网、无法使用anaconda的情况下,在一台离线的win7设备上配置Spyder的python的开发环境,用于提高数据处理效率,且安装方法在win732位和64位的各种设备上均可流畅安装。二、问题难点总结:1.离线安装Python的第三方函数库Python在联网情况下安装第三方包很容易,但离线安装操作比较复杂,如某第三方库a,联网状态下仅一行代码pipinstalla,然而离线
C++快速入门扫盲总结
六竹书生__wa
C/C++Qt
C++快速入门扫盲总结C++语言新特性C++的新特性C++的输入输出方式C++之命名空间namespaceC++面向对象类和对象构造函数与析构函数this指针继承重载函数重载运算符重载多态数据封装数据抽象接口(抽象类)C++语言新特性C++的新特性C++比C语言新增的数据类型是布尔类型(bool)。但是在新的C语言标准里已经有布尔类型了,但是在旧的C语言标准里是没有布尔类型的,编译器也无法解释布尔
C++多线程的简单使用
好学松鼠
C++C++多线程asyncpromise
多线程的使用,本文主要简单介绍使用多线程的几种方式,并使用几个简单的例子来介绍多线程,使用编译器为visualstudio。一、AsyncFuture使用的知识点有std::async和std::future1、std::async函数原型templatefuture::type>async(launchpolicy,Fn&&fn,Args&&...args);功能:第二个参数接收一个可调用对象(
GO Govaluate
qq_17280559
golang开发语言后端go
govaluate是一个用于在Go语言中动态求值表达式的库。它允许你解析和评估字符串形式的表达式,这些表达式可以包含变量、函数以及逻辑、算术和比较操作。它非常适合在运行时处理复杂的逻辑规则和条件表达式,而不需要重新编译代码。安装govaluategogetgithub.com/Knetic/govaluate基本使用govaluate的核心是Evaluate方法,它接受表达式字符串和变量值,并返回
Java 入门基础篇05 - Java的关键字
仔仔 v1.0
Java基础java开发语言intellij-idea
什么是关键字?就是被java语言赋予特殊含义的单词。关键字的特点组成关键的字母都是小写。常见关键字class,public,static,void.....。关键字注意事项goto和const是java语言的保留字,关键字在IDEA编译器中有明确的颜色变化。关键字列表ABSTRACTCONTINUEFORNEWSWITCHassertdefaultgotopackagesynchronizedbo
开发者关心的那些事
圣子足道
ios游戏编程apple支付
我要在app里添加IAP,必须要注册自己的产品标识符(product identifiers)。产品标识符是什么?
产品标识符(Product Identifiers)是一串字符串,它用来识别你在应用内贩卖的每件商品。App Store用产品标识符来检索产品信息,标识符只能包含大小写字母(A-Z)、数字(0-9)、下划线(-)、以及圆点(.)。你可以任意排列这些元素,但我们建议你创建标识符时使用
负载均衡器技术Nginx和F5的优缺点对比
bijian1013
nginxF5
对于数据流量过大的网络中,往往单一设备无法承担,需要多台设备进行数据分流,而负载均衡器就是用来将数据分流到多台设备的一个转发器。
目前有许多不同的负载均衡技术用以满足不同的应用需求,如软/硬件负载均衡、本地/全局负载均衡、更高
LeetCode[Math] - #9 Palindrome Number
Cwind
javaAlgorithm题解LeetCodeMath
原题链接:#9 Palindrome Number
要求:
判断一个整数是否是回文数,不要使用额外的存储空间
难度:简单
分析:
题目限制不允许使用额外的存储空间应指不允许使用O(n)的内存空间,O(1)的内存用于存储中间结果是可以接受的。于是考虑将该整型数反转,然后与原数字进行比较。
注:没有看到有关负数是否可以是回文数的明确结论,例如
画图板的基本实现
15700786134
画图板
要实现画图板的基本功能,除了在qq登陆界面中用到的组件和方法外,还需要添加鼠标监听器,和接口实现。
首先,需要显示一个JFrame界面:
public class DrameFrame extends JFrame { //显示
linux的ps命令
被触发
linux
Linux中的ps命令是Process Status的缩写。ps命令用来列出系统中当前运行的那些进程。ps命令列出的是当前那些进程的快照,就是执行ps命令的那个时刻的那些进程,如果想要动态的显示进程信息,就可以使用top命令。
要对进程进行监测和控制,首先必须要了解当前进程的情况,也就是需要查看当前进程,而 ps 命令就是最基本同时也是非常强大的进程查看命令。使用该命令可以确定有哪些进程正在运行
Android 音乐播放器 下一曲 连续跳几首歌
肆无忌惮_
android
最近在写安卓音乐播放器的时候遇到个问题。在MediaPlayer播放结束时会回调
player.setOnCompletionListener(new OnCompletionListener() {
@Override
public void onCompletion(MediaPlayer mp) {
mp.reset();
Log.i("H
java导出txt文件的例子
知了ing
javaservlet
代码很简单就一个servlet,如下:
package com.eastcom.servlet;
import java.io.BufferedOutputStream;
import java.io.IOException;
import java.net.URLEncoder;
import java.sql.Connection;
import java.sql.Resu
Scala stack试玩, 提高第三方依赖下载速度
矮蛋蛋
scalasbt
原文地址:
http://segmentfault.com/a/1190000002894524
sbt下载速度实在是惨不忍睹, 需要做些配置优化
下载typesafe离线包, 保存为ivy本地库
wget http://downloads.typesafe.com/typesafe-activator/1.3.4/typesafe-activator-1.3.4.zip
解压r
phantomjs安装(linux,附带环境变量设置) ,以及casperjs安装。
alleni123
linuxspider
1. 首先从官网
http://phantomjs.org/下载phantomjs压缩包,解压缩到/root/phantomjs文件夹。
2. 安装依赖
sudo yum install fontconfig freetype libfreetype.so.6 libfontconfig.so.1 libstdc++.so.6
3. 配置环境变量
vi /etc/profil
JAVA IO FileInputStream和FileOutputStream,字节流的打包输出
百合不是茶
java核心思想JAVA IO操作字节流
在程序设计语言中,数据的保存是基本,如果某程序语言不能保存数据那么该语言是不可能存在的,JAVA是当今最流行的面向对象设计语言之一,在保存数据中也有自己独特的一面,字节流和字符流
1,字节流是由字节构成的,字符流是由字符构成的 字节流和字符流都是继承的InputStream和OutPutStream ,java中两种最基本的就是字节流和字符流
类 FileInputStream
Spring基础实例(依赖注入和控制反转)
bijian1013
spring
前提条件:在http://www.springsource.org/download网站上下载Spring框架,并将spring.jar、log4j-1.2.15.jar、commons-logging.jar加载至工程1.武器接口
package com.bijian.spring.base3;
public interface Weapon {
void kil
HR看重的十大技能
bijian1013
提升能力HR成长
一个人掌握何种技能取决于他的兴趣、能力和聪明程度,也取决于他所能支配的资源以及制定的事业目标,拥有过硬技能的人有更多的工作机会。但是,由于经济发展前景不确定,掌握对你的事业有所帮助的技能显得尤为重要。以下是最受雇主欢迎的十种技能。 一、解决问题的能力 每天,我们都要在生活和工作中解决一些综合性的问题。那些能够发现问题、解决问题并迅速作出有效决
【Thrift一】Thrift编译安装
bit1129
thrift
什么是Thrift
The Apache Thrift software framework, for scalable cross-language services development, combines a software stack with a code generation engine to build services that work efficiently and s
【Avro三】Hadoop MapReduce读写Avro文件
bit1129
mapreduce
Avro是Doug Cutting(此人绝对是神一般的存在)牵头开发的。 开发之初就是围绕着完善Hadoop生态系统的数据处理而开展的(使用Avro作为Hadoop MapReduce需要处理数据序列化和反序列化的场景),因此Hadoop MapReduce集成Avro也就是自然而然的事情。
这个例子是一个简单的Hadoop MapReduce读取Avro格式的源文件进行计数统计,然后将计算结果
nginx定制500,502,503,504页面
ronin47
nginx 错误显示
server {
listen 80;
error_page 500/500.html;
error_page 502/502.html;
error_page 503/503.html;
error_page 504/504.html;
location /test {return502;}}
配置很简单,和配
java-1.二叉查找树转为双向链表
bylijinnan
二叉查找树
import java.util.ArrayList;
import java.util.List;
public class BSTreeToLinkedList {
/*
把二元查找树转变成排序的双向链表
题目:
输入一棵二元查找树,将该二元查找树转换成一个排序的双向链表。
要求不能创建任何新的结点,只调整指针的指向。
10
/ \
6 14
/ \
Netty源码学习-HTTP-tunnel
bylijinnan
javanetty
Netty关于HTTP tunnel的说明:
http://docs.jboss.org/netty/3.2/api/org/jboss/netty/channel/socket/http/package-summary.html#package_description
这个说明有点太简略了
一个完整的例子在这里:
https://github.com/bylijinnan
JSONUtil.serialize(map)和JSON.toJSONString(map)的区别
coder_xpf
jqueryjsonmapval()
JSONUtil.serialize(map)和JSON.toJSONString(map)的区别
数据库查询出来的map有一个字段为空
通过System.out.println()输出 JSONUtil.serialize(map): {"one":"1","two":"nul
Hibernate缓存总结
cuishikuan
开源sshjavawebhibernate缓存三大框架
一、为什么要用Hibernate缓存?
Hibernate是一个持久层框架,经常访问物理数据库。
为了降低应用程序对物理数据源访问的频次,从而提高应用程序的运行性能。
缓存内的数据是对物理数据源中的数据的复制,应用程序在运行时从缓存读写数据,在特定的时刻或事件会同步缓存和物理数据源的数据。
二、Hibernate缓存原理是怎样的?
Hibernate缓存包括两大类:Hib
CentOs6
dalan_123
centos
首先su - 切换到root下面1、首先要先安装GCC GCC-C++ Openssl等以来模块:yum -y install make gcc gcc-c++ kernel-devel m4 ncurses-devel openssl-devel2、再安装ncurses模块yum -y install ncurses-develyum install ncurses-devel3、下载Erang
10款用 jquery 实现滚动条至页面底端自动加载数据效果
dcj3sjt126com
JavaScript
无限滚动自动翻页可以说是web2.0时代的一项堪称伟大的技术,它让我们在浏览页面的时候只需要把滚动条拉到网页底部就能自动显示下一页的结果,改变了一直以来只能通过点击下一页来翻页这种常规做法。
无限滚动自动翻页技术的鼻祖是微博的先驱:推特(twitter),后来必应图片搜索、谷歌图片搜索、google reader、箱包批发网等纷纷抄袭了这一项技术,于是靠滚动浏览器滚动条
ImageButton去边框&Button或者ImageButton的背景透明
dcj3sjt126com
imagebutton
在ImageButton中载入图片后,很多人会觉得有图片周围的白边会影响到美观,其实解决这个问题有两种方法
一种方法是将ImageButton的背景改为所需要的图片。如:android:background="@drawable/XXX"
第二种方法就是将ImageButton背景改为透明,这个方法更常用
在XML里;
<ImageBut
JSP之c:foreach
eksliang
jspforearch
原文出自:http://www.cnblogs.com/draem0507/archive/2012/09/24/2699745.html
<c:forEach>标签用于通用数据循环,它有以下属性 属 性 描 述 是否必须 缺省值 items 进行循环的项目 否 无 begin 开始条件 否 0 end 结束条件 否 集合中的最后一个项目 step 步长 否 1
Android实现主动连接蓝牙耳机
gqdy365
android
在Android程序中可以实现自动扫描蓝牙、配对蓝牙、建立数据通道。蓝牙分不同类型,这篇文字只讨论如何与蓝牙耳机连接。
大致可以分三步:
一、扫描蓝牙设备:
1、注册并监听广播:
BluetoothAdapter.ACTION_DISCOVERY_STARTED
BluetoothDevice.ACTION_FOUND
BluetoothAdapter.ACTION_DIS
android学习轨迹之四:org.json.JSONException: No value for
hyz301
json
org.json.JSONException: No value for items
在JSON解析中会遇到一种错误,很常见的错误
06-21 12:19:08.714 2098-2127/com.jikexueyuan.secret I/System.out﹕ Result:{"status":1,"page":1,&
干货分享:从零开始学编程 系列汇总
justjavac
编程
程序员总爱重新发明轮子,于是做了要给轮子汇总。
从零开始写个编译器吧系列 (知乎专栏)
从零开始写一个简单的操作系统 (伯乐在线)
从零开始写JavaScript框架 (图灵社区)
从零开始写jQuery框架 (蓝色理想 )
从零开始nodejs系列文章 (粉丝日志)
从零开始编写网络游戏
jquery-autocomplete 使用手册
macroli
jqueryAjax脚本
jquery-autocomplete学习
一、用前必备
官方网站:http://bassistance.de/jquery-plugins/jquery-plugin-autocomplete/
当前版本:1.1
需要JQuery版本:1.2.6
二、使用
<script src="./jquery-1.3.2.js" type="text/ja
PLSQL-Developer或者Navicat等工具连接远程oracle数据库的详细配置以及数据库编码的修改
超声波
oracleplsql
在服务器上将Oracle安装好之后接下来要做的就是通过本地机器来远程连接服务器端的oracle数据库,常用的客户端连接工具就是PLSQL-Developer或者Navicat这些工具了。刚开始也是各种报错,什么TNS:no listener;TNS:lost connection;TNS:target hosts...花了一天的时间终于让PLSQL-Developer和Navicat等这些客户
数据仓库数据模型之:极限存储--历史拉链表
superlxw1234
极限存储数据仓库数据模型拉链历史表
在数据仓库的数据模型设计过程中,经常会遇到这样的需求:
1. 数据量比较大; 2. 表中的部分字段会被update,如用户的地址,产品的描述信息,订单的状态等等; 3. 需要查看某一个时间点或者时间段的历史快照信息,比如,查看某一个订单在历史某一个时间点的状态, 比如,查看某一个用户在过去某一段时间内,更新过几次等等; 4. 变化的比例和频率不是很大,比如,总共有10
10点睛Spring MVC4.1-全局异常处理
wiselyman
spring mvc
10.1 全局异常处理
使用@ControllerAdvice注解来实现全局异常处理;
使用@ControllerAdvice的属性缩小处理范围
10.2 演示
演示控制器
package com.wisely.web;
import org.springframework.stereotype.Controller;
import org.spring