springboot与mybatis plus开发瑞吉外卖项目实战项目优化
缓存
缓存短信验证码
实现思路
- 在服务端UserController中注入RedisTemplate对象,用于操作Redis
- 在服务端UserController的sendMsg方法中,将随机生成的验证码缓存到Redis中,并设置有效期为5分钟
- 在服务端UserController的login方法中,从Redis中获取缓存的验证码,如果登录成功则删除Redis中的验证码
代码改造
@PostMapping("/sendMsg")
public R<String> sendMsg(@RequestBody User user, HttpSession session){
// 获取手机号
String phone = user.getPhone();
if (StringUtils.isNotEmpty(phone)){
// 生成随机的4位验证码
String code = ValidateCodeUtils.generateValidateCode(4).toString();
log.info("code={}",code);
// 调用阿里云提供的短信服务API完成发送短信
// SMSUtils.sendMessage("瑞吉外卖","",phone,code);
// 需要将生成的验证码保存到session
// session.setAttribute(phone,code);
//将生成的验证码缓存到Redis中,并且设置有效期为5分钟
redisTemplate.opsForValue().set(phone,code,5, TimeUnit.MINUTES);
return R.success("手机验证码发送成功,验证码为:"+code);
}
return R.error("短信发送失败!");
}
/**
* 移动端用户登录
* @param map
* @return
*/
@PostMapping("/login")
public R<User> login(@RequestBody Map map, HttpSession session){
log.info("用户登录数据:{}",map.toString());
// 获取手机号
String phone = map.get("phone").toString();
// 获取验证码
String code = map.get("code").toString();
// 从session中获取验证码
// String codeInSession = session.getAttribute(phone).toString();
// 从Redis中获取缓存的验证码
Object codeInSession = redisTemplate.opsForValue().get(phone);
// 进行验证码比对,页面中的验证码和session中保存的验证码比对
if (codeInSession !=null && codeInSession.equals(code)){
// 比对成功就说明登录成功
LambdaQueryWrapper<User> queryWrapper=new LambdaQueryWrapper<>();
queryWrapper.eq(User::getPhone,phone);
User user = userService.getOne(queryWrapper);
if (user == null){
// 判断当前手机号对应的用户是否为新用户,如果是新用户就自动完成注册
user = new User();
user.setPhone(phone);
user.setStatus(1);
userService.save(user);
}
session.setAttribute("user",user.getId());
//如果用户登录成功,删除Rodis中缓存的验证码
redisTemplate.delete(phone);
return R.success(user);
}
return R.error("登录失败!");
}
缓存菜品数据(手动缓存)
实现思路
- 改造DishController的list方法,先从Redis中获取菜品数据,如果有则直接返回,无需查询数据库;如果没有则查询数据库,并将查询到的菜品数据放入Redis。
- 改造DishController的save和update方法,加入清理缓存的逻辑(如果不清理显示的数据就和数据库的数据不一致,产生脏数据)
注意事项
在使用缓存过程中,要注意保证数据库中的数据和缓存中的数据一致,如果数据库中的数据发生变化,需要及时清理缓存数据。
代码改造功能测试
@GetMapping("/list")
public R<List<DishDto>> list(Dish dish){
List<DishDto> dishDtoList=null;
// 动态构造key
String key = "dish_" + dish.getCategoryId() + "_" + dish.getStatus();
//先从redis中获取缓存数据
dishDtoList = (List<DishDto>) redisTemplate.opsForValue().get(key);
if (dishDtoList != null){
//如果存在,直接返回,无需查询数据库
return R.success(dishDtoList);
}
LambdaQueryWrapper<Dish>queryWrapper=new LambdaQueryWrapper<>();
queryWrapper.eq(dish.getCategoryId() !=null ,Dish::getCategoryId,dish.getCategoryId());
// 只查询起售的菜品
queryWrapper.eq(Dish::getStatus,1);
queryWrapper.orderByAsc(Dish::getSort).orderByDesc(Dish::getUpdateTime);
List<Dish> list = dishService.list(queryWrapper);
dishDtoList=list.stream().map((item)->{
DishDto dishDto=new DishDto();
Long categoryId = item.getCategoryId(); //分类id
// 根据id查询分类对象
Category category = categoryService.getById(categoryId);
if (category!=null){
dishDto.setCategoryName(category.getName());
}
BeanUtils.copyProperties(item,dishDto);
Long dishId = item.getId();
LambdaQueryWrapper<DishFlavor> wrapper=new LambdaQueryWrapper<>();
wrapper.eq(DishFlavor::getDishId,dishId);
List<DishFlavor> dishFlavorList = dishFlavorService.list(wrapper);
dishDto.setFlavors(dishFlavorList);
return dishDto;
}).collect(Collectors.toList());
//如果不存在,需要查询数据库,将查询到的菜品数据缓存到Redis
redisTemplate.opsForValue().set(key,dishDtoList,60, TimeUnit.MINUTES);
return R.success(dishDtoList);
}
@PutMapping
public R<String> update(@RequestBody DishDto dishDto){
dishService.updateWithFlavor(dishDto);
//清理所有菜品的缓存数据
/* 第一种粗略清理,清理所有
Set keys = redisTemplate.keys("dish_*"); //获取所有以 dish_ 开头的 key
redisTemplate.delete(keys);
*/
/* 第二种精确清理 */
String key = "dish_" + dishDto.getCategoryId() + "_1";
redisTemplate.delete(key);
return R.success("修改成功!");
}
缓存套餐数据(通过注解缓存)
实现思路
前面我们已经实现了移动端套餐查看功能,对应的服务端方法为SetmealController的list方法,此方法会根据前端提交的查询条件进行数据库查询操作。在高并发的情况下,频繁查询数据库会导致系统性能下降,服务端响应时间增长。现在需要对此方法进行缓存优化,提高系统的性能。
具体的实现思路如下:
-
导入Spring Cache和Redis相关maven坐标
<dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-cacheartifactId> dependency> <dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-data-redisartifactId> dependency> -
在application.yml中配置缓存数据的过期时间
spring: # redis 配置 redis: host: 192.168.200.180 port: 6379 password: 123456 database: 0 # 缓存配置 cache: redis: time-to-live: 1800000 # 设置缓存过期时间 -
在启动类上加入@EnableCaching注解,开启缓存注解功能
// 开启 Spring Cache 注解方式缓存功能 @EnableCaching // 扫描 servlet 注解 @ServletComponentScan // 开启事务 @EnableTransactionManagement @SpringBootApplication public class ReggieTakeOutApplication { public static void main(String[] args) { SpringApplication.run(ReggieTakeOutApplication.class, args); } } -
在SetmealController的list方法上加入@Cacheable注解(通过什么条件查询key就用这几个条件拼接)
@Cacheable(value = "setmealCache",key = "#setmeal.categoryId + '_' + #setmeal.status") @GetMapping("/list") public R<List<Setmeal>> list(Setmeal setmeal){ LambdaQueryWrapper<Setmeal> queryWrapper= new LambdaQueryWrapper<>(); queryWrapper.eq(setmeal.getCategoryId() !=null,Setmeal::getCategoryId,setmeal.getCategoryId()); queryWrapper.eq(setmeal.getStatus()!=null,Setmeal::getStatus,setmeal.getStatus()); queryWrapper.orderByDesc(Setmeal::getUpdateTime); List<Setmeal> list = setmealService.list(queryWrapper); return R.success(list); } -
在SetmealController的save和delete方法上加入CacheEvict注解
@PostMapping @CacheEvict(value = "setmealCache",allEntries = true) // allEntries:要删除 value为setmealCache下的所有缓存 public R<String> save(@RequestBody SetmealDto setmealDto){ log.info("套餐信息:{}",setmealDto); setmealService.saveWithDish(setmealDto); return R.success("新增套餐成功!"); } @DeleteMapping @CacheEvict(value = "setmealCache",allEntries = true) // allEntries:要删除 value为setmealCache下的所有缓存 public R<String> delete(@RequestParam List<Long> ids){ log.info("删除套餐ids:{}",ids); setmealService.removeWithDish(ids); return R.success("删除套餐成功!"); } @PostMapping("/status/{type}") @CacheEvict(value = "setmealCache",allEntries = true) // allEntries:要删除 value为setmealCache下的所有缓存 public R<String> status(@RequestParam List<Long> ids,@PathVariable int type){ LambdaUpdateWrapper<Setmeal> updateWrapper=new LambdaUpdateWrapper<>(); updateWrapper.in(Setmeal::getId,ids); updateWrapper.set(Setmeal::getStatus,type); setmealService.update(updateWrapper); if (type==0){ return R.success("套餐已停售!"); } return R.success("套餐已起售!"); } @PutMapping @CacheEvict(value = "setmealCache",allEntries = true) // allEntries:要删除 value为setmealCache下的所有缓存 public R<String> update(@RequestBody SetmealDto setmealDto){ log.info("更新套餐及其菜品数据:{}",setmealDto); setmealService.updateWithDish(setmealDto); return R.success("套餐数据修改成功!"); }
读写分离
Mysql主从复制
介绍
MySQL主从复制是一个异步的复制过程,底层是基于Mysql数据库自带的二进制日志功能。就是一台或多台MysQL数据库(slave,即从库)从另一台MySQL数据库(master,即主库)进行日志的复制然后再解析日志并应用到自身,最终实现从库的数据和主库的数据保持一致。MySQL主从复制是MysQL数据库自带功能,无需借助第三方工具。
MySQL复制过程分成三步:
- master将改变记录到二进制日志(binary log)
- slave将master的binary log拷贝到它的中继日志(relay log)
- slave重做中继日志中的事件,将改变应用到自己的数据库中
配置-前置条件
提前准备好两台服务器,分别安装Mysql并启动服务成功
- 主库aster 192.168.138.166
- 从库Slave 192.168.138.101
配置-主库Master
第一步:修改Mysql数据库的配置文件/etc/my.cnf
vim /etc/my.cnf
[mysqld]
# 增加
log-bin=mysql-bin # [必须]启用二进制日志
server-id=100 # [必须]服务器唯一ID
第二步:重启Mysql服务
systemctl restart mysqld
第三步:登录Mysql数据库,执行下面SQL
mysql -uroot -proot #-uroot,账号root,-proot,密码root
GRANT REPLICATION SLAVE ON *.* to 'xiaoming'@'%' identified by 'Root@123456';
注:上面SQL的作用是创建一个用户xiaoming,密码为Root@123456,并且给xiaoming用户授予REPLICATION SLAVE权限。常用于建立复制时所需要用到的用户权限,也就是slave必须被master授权具有该权限的用户,才能通过该用户复制。
第四步:登录Mysql数据库,执行下面SQL,记录下结果中File和Position的值
show master status;
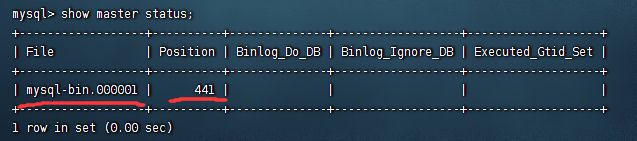
注:上面SQL的作用是查看Master的状态,执行完此SQL后不要再执行任何操作
配置-从库Slave
第一步:修改Mysql数据库的配置文件/etc/my.cnf
vim /etc/my.cnf
[mysqld]
# 增加
server-id=101 # [必须]服务器唯一ID
第二步:重启Mysql服务
systemctl restart mysqld
第三步:登录Mysql数据库,执行下面SQL(要对应主库的内容)
change master to
master_host='192.168.200.180', master_user='xiaoming',master_password='Root@123456',master_log_file='mysql-bin.000001' ,master_log_pos=441;
start slave;
第四步:登录Mysql数据库,执行下面sQL,查看从数据库的状态
show slave status;

读写分离案例
背景
面对日益增加的系统访问量,数据库的吞吐量面临着巨大瓶颈。对于同一时刻有大量并发读操作和较少写操作类型的应用系统来说,将数据库拆分为主库和从库,主库负责处理事务性的增删改操作,从库负责处理查询操作,能够有效的避免由数据更新导致的行锁,使得整个系统的查询性能得到极大的改善。
sharding-JDBC介绍
Sharding-JDBC定位为轻量级Java框架,在Java的JDBC层提供的额外服务。它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
使用Sharding-JDBC可以在程序中轻松的实现数据库读写分离。
- 适用于任何基于JDBC的ORM框架,如:JPA, Hibernate,Mybatis, Spring JDBC Template或直接使用JDBC。
- 支持任何第三方的数据库连接池,如:DBCP,C3P0,BoneCP, Druid, HikariCP等。
- 支持任意实现JDBC规范的数据库。目前支持MysQL,Oracle,sQLServer,PostgresQL以及任何遵循SQL92标准
的数据库。
<dependency>
<groupld>org.apache.shardingspheregroupld>
<artifactId>sharding-jdbc-spring-boot-starterartifactId>
<version>4.0.O-RC1version>
dependency>
入门案例
使用Sharding-JDBC实现读写分离步骤:
- 导入maven坐标
<dependencies> <dependency> <groupId>org.apache.shardingspheregroupId> <artifactId>sharding-jdbc-spring-boot-starterartifactId> <version>4.0.0-RC1version> dependency> ...... dependencies> - 在配置文件中配置读写分离规则
server: port: 8080 mybatis-plus: configuration: #在映射实体或者属性时,将数据库中表名和字段名中的下划线去掉,按照驼峰命名法映射 map-underscore-to-camel-case: true log-impl: org.apache.ibatis.logging.stdout.StdOutImpl global-config: db-config: id-type: ASSIGN_ID spring: shardingsphere: datasource: names: master,slave # 主数据源 master: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://192.168.200.180:3306/rw?characterEncoding=utf-8 username: root password: root # 从数据源 slave: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://192.168.200.130:3306/rw?characterEncoding=utf-8 username: root password: root masterslave: # 读写分离配置 load-balance-algorithm-type: round_robin #轮询 # 最终的数据源名称 name: dataSource # 主库数据源名称 master-data-source-name: master # 从库数据源名称列表,多个逗号分隔 slave-data-source-names: slave props: sql: show: true #开启SQL显示,默认false - 在配置文件中配置允许bean定义覆盖配置项
server: port: 8080 mybatis-plus: configuration: #在映射实体或者属性时,将数据库中表名和字段名中的下划线去掉,按照驼峰命名法映射 map-underscore-to-camel-case: true log-impl: org.apache.ibatis.logging.stdout.StdOutImpl global-config: db-config: id-type: ASSIGN_ID spring: shardingsphere: datasource: names: master,slave # 主数据源 master: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://192.168.200.180:3306/rw?characterEncoding=utf-8 username: root password: root # 从数据源 slave: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://192.168.200.130:3306/rw?characterEncoding=utf-8 username: root password: root masterslave: # 读写分离配置 load-balance-algorithm-type: round_robin #轮询 # 最终的数据源名称 name: dataSource # 主库数据源名称 master-data-source-name: master # 从库数据源名称列表,多个逗号分隔 slave-data-source-names: slave props: sql: show: true #开启SQL显示,默认false main: # 允许bean定义覆盖 allow-bean-definition-overriding: true
项目实现读写分离
-
导入maven坐标
<dependencies> <dependency> <groupId>org.apache.shardingspheregroupId> <artifactId>sharding-jdbc-spring-boot-starterartifactId> <version>4.0.0-RC1version> dependency> ...... dependencies> -
修改配置文件
# 文件上传路径 web: upload-path: F:\\images # 验证码方式,math 计算类型,char 字符串类型 captcha: type: math server: port: 8081 # springsSession过期时间 servlet: session: timeout: 30m spring: # redis 配置 redis: host: 192.168.200.180 port: 6379 password: 123456 database: 0 cache: redis: time-to-live: 1800000 # 设置缓存过期时间 shardingsphere: datasource: names: master,slave # 主数据源 master: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://192.168.200.180:3306/rw?characterEncoding=utf-8 username: root password: root # 从数据源 slave: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://192.168.200.130:3306/rw?characterEncoding=utf-8 username: root password: root masterslave: # 读写分离配置 load-balance-algorithm-type: round_robin #轮询 # 最终的数据源名称 name: dataSource # 主库数据源名称 master-data-source-name: master # 从库数据源名称列表,多个逗号分隔 slave-data-source-names: slave props: sql: show: true #开启SQL显示,默认false main: # 允许bean定义覆盖 allow-bean-definition-overriding: true # 配置mysql数据源 # datasource: # url: jdbc:mysql://192.168.200.180:3306/reggie?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&useSSL=false&allowPublicKeyRetrieval=true # username: root # password: root # driver-class-name: com.mysql.cj.jdbc.Driver # hikari: # max-lifetime: 60000 # connection-timeout: 60000 # validation-timeout: 3000 # idle-timeout: 60000 # login-timeout: 5 # maximum-pool-size: 10 # minimum-idle: 10 # read-only: false # 开启静态文件服务 web: resources: static-locations: classpath:/META-INF/resources/,classpath:/resources/,classpath:/static/,classpath:/public/,file:${web.upload-path},classpath:/front/** servlet: multipart: max-file-size: 20MB max-request-size: 100MB ## mybatis , 不是全注解开发就要配置 #mybatis: # mapper-locations: classpath:mapper/*Mapper.xml # mapper 映射文件路径 # type-aliases-package: com/liu/login/domain # # config-location: #指定mybatis的核心配置文件 mybatis-plus: mapper-locations: classpath*:/mapper/**/*.xml configuration: # address_book ------> AddressBook # 在映射实体或者属性时,将数据库中表名和字段名中的下划线去掉,按照驼峰命名法映射 map-underscore-to-camel-case: true log-impl: org.apache.ibatis.logging.stdout.StdOutImpl # global-config: # db-config: # id-type: ASSIGN_ID # table-prefix: tb_ # 日志配置 logging: file: path: F:/log/ # name: level: root: info pattern: console: '%d{yyyy/MM/dd-HH:mm:ss} [%thread] %-5level %logger- %msg%n' file: '%d{yyyy/MM/dd-HH:mm} [%thread] %-5level %logger- %msg%n'