vue实现多行数据提交_2020年大厂面试指南 Vue篇


点击蓝字 「前端小苑」关注我
导读
vue的一些基础知识,以及相关实现原理,一直是面试中比较热门的题目,本文梳理了常见的Vue面试题。
注意:关于底层实现原理,建议最好还是参照源码进行学习,有些原理相对比较复杂,很难通过一篇文章去深入理解,最终可能只是一知半解,面试时一深入提问,就露馅了。
本文主要是对Vue可能的面试点进行梳理,平时还是要注重知识的积累和储备,才能游刃有余的应对工作和面试,部分题目会给出相关链接供详细学习。
组件通信相关问题
1. 组件通信方式有哪些?
父子组件通信:
props 和 event、v-model、 .sync、 ref、 $parent 和 $children
非父子组件通信:
$attr 和 $listeners、 provide 和 inject、eventbus、通过根实例$root访问、vuex、dispatch 和 brodcast
通信方式属于较基础的面试题,具体的可参考我的文章—— vue 组件通信看这篇就够了

2. 子组件为什么不可以修改父组件传递的Prop?
Vue提倡单向数据流,即父级 props 的更新会流向子组件,但是反过来则不行。这是为了防止意外的改变父组件状态,使得应用的数据流变得难以理解。如果破坏了单向数据流,当应用复杂时,debug 的成本会非常高。
3. v-model是如何实现双向绑定的?
v-model 是用来在表单控件或者组件上创建双向绑定的,他的本质是 v-bind 和 v-on 的语法糖,在一个组件上使用 v-model,默认会为组件绑定名为 value 的 prop 和名为 input 的事件。
文章—— vue 组件通信看这篇就够了 中也有其详细介绍
4. Vuex和单纯的全局对象有什么区别?
Vuex和全局对象主要有两大区别:
- Vuex 的状态存储是响应式的。当 Vue 组件从 store 中读取状态的时候,若 store 中的状态发生变化,那么相应的组件也会相应地得到高效更新。
不能直接改变 store 中的状态。改变 store 中的状态的唯一途径就是显式地提交 (commit) mutation。这样使得我们可以方便地跟踪每一个状态的变化,从而让我们能够实现一些工具帮助我们更好地了解我们的应用。
5. 为什么 Vuex 的 mutation 中不能做异步操作?
Vuex中所有的状态更新的唯一途径都是mutation,异步操作通过 Action 来提交 mutation实现,这样使得我们可以方便地跟踪每一个状态的变化,从而让我们能够实现一些工具帮助我们更好地了解我们的应用。
每个mutation执行完成后都会对应到一个新的状态变更,这样devtools就可以打个快照存下来,然后就可以实现 time-travel 了。如果mutation支持异步操作,就没有办法知道状态是何时更新的,无法很好的进行状态的追踪,给调试带来困难。 参考尤大大回答:
https://www.zhihu.com/question/48759748/answer/112823337
声明周期相关问题
1. vue组件有哪些声明周期钩子?
beforeCreate、created、beforeMount、mounted、beforeUpdate、updated、beforeDestroy、destroyed。
有自己独立的钩子函数 activated 和 deactivated。
2. Vue 的父组件和子组件生命周期钩子执行顺序是什么?
渲染过程:
父组件挂载完成一定是等子组件都挂载完成后,才算是父组件挂载完,所以父组件的mounted在子组件mouted之后。
父beforeCreate -> 父created -> 父beforeMount -> 子beforeCreate -> 子created -> 子beforeMount -> 子mounted -> 父mounted
子组件更新过程:
影响到父组件: 父beforeUpdate -> 子beforeUpdate->子updated -> 父updted
不影响父组件: 子beforeUpdate -> 子updated
父组件更新过程:
影响到子组件: 父beforeUpdate -> 子beforeUpdate->子updated -> 父updted
不影响子组件: 父beforeUpdate -> 父updated
销毁过程:
父beforeDestroy -> 子beforeDestroy -> 子destroyed -> 父destroyed
看起来很多好像很难记忆,其实只要理解了,不管是哪种情况,都一定是父组件等待子组件完成后,才会执行自己对应完成的钩子,就可以很容易记住。
相关属性的作用 & 相似属性对比
1. v-show 和 v-if 有哪些区别?
v-if 会在切换过程中对条件块的事件监听器和子组件进行销毁和重建,如果初始条件是false,则什么都不做,直到条件第一次为true时才开始渲染模块。
v-show 只是基于css进行切换,不管初始条件是什么,都会渲染。
所以,v-if 切换的开销更大,而 v-show 初始化渲染开销更大,在需要频繁切换,或者切换的部分dom很复杂时,使用 v-show 更合适。渲染后很少切换的则使用 v-if 更合适。
2. computed 和 watch 有什么区别?
computed 计算属性,是依赖其他属性的计算值,并且有缓存,只有当依赖的值变化时才会更新。
watch 是在监听的属性发生变化时,在回调中执行一些逻辑。
所以,computed 适合在模板渲染中,某个值是依赖了其他的响应式对象甚至是计算属性计算而来,而 watch 适合监听某个值的变化去完成一段复杂的业务逻辑。
3. computed vs methods
计算属性是基于他们的响应式依赖进行缓存的,只有在依赖发生变化时,才会计算求值,而使用 methods,每次都会执行相应的方法。
4. keep-alive 的作用是什么?
keep-alive 可以在组件切换时,保存其包裹的组件的状态,使其不被销毁,防止多次渲染。
其拥有两个独立的生命周期钩子函数 actived 和 deactived,使用 keep-alive 包裹的组件在切换时不会被销毁,而是缓存到内存中并执行 deactived 钩子函数,命中缓存渲染后会执行 actived 钩子函数。
5. Vue 中 v-html 会导致什么问题
在网站上动态渲染任意 HTML,很容易导致 XSS 攻击。所以只能在可信内容上使用 v-html,且永远不能用于用户提交的内容上。
原理分析相关题目
这部分的面试题,只看答案部分是不够的,最好结合源码来分析,可以有更深的理解。我在之前的文章对某些源码做过分析的,会给出链接。
1. Vue 的响应式原理
如果面试被问到这个问题,又描述不清楚,可以直接画出 Vue 官方文档的这个图,对着图来解释效果会更好。
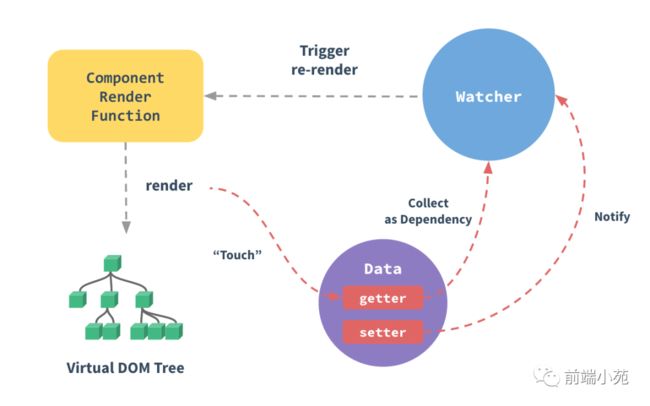
Vue 的响应式是通过 Object.defineProperty 对数据进行劫持,并结合观察者模式实现。Vue 利用 Object.defineProperty 创建一个 observe 来劫持监听所有的属性,把这些属性全部转为 getter 和 setter。Vue 中每个组件实例都会对应一个 watcher 实例,它会在组件渲染的过程中把使用过的数据属性通过 getter 收集为依赖。之后当依赖项的 setter 触发时,会通知 watcher,从而使它关联的组件重新渲染。
2. Object.defineProperty有哪些缺点?
这道题目也可以问成 “为什么vue3.0使用proxy实现响应式?” 其实都是对Object.defineProperty 和 proxy实现响应式的对比。
Object.defineProperty只能劫持对象的属性,而Proxy是直接代理对象由于Object.defineProperty只能对属性进行劫持,需要遍历对象的每个属性。而Proxy可以直接代理对象。Object.defineProperty对新增属性需要手动进行Observe, 由于Object.defineProperty劫持的是对象的属性,所以新增属性时,需要重新遍历对象,对其新增属性再使用Object.defineProperty进行劫持。 也正是因为这个原因,使用 Vue 给data中的数组或对象新增属性时,需要使用vm.$set才能保证新增的属性也是响应式的。Proxy支持13种拦截操作,这是defineProperty所不具有的。新标准性能红利
Proxy作为新标准,长远来看,JS引擎会继续优化Proxy,但getter和setter基本不会再有针对性优化。Proxy兼容性差 目前并没有一个完整支持Proxy所有拦截方法的Polyfill方案
更详细的对比,可以查看我的文章 为什么Vue3.0不再使用defineProperty实现数据监听?
3. Vue中如何检测数组变化?
Vue 的 Observer 对数组做了单独的处理,对数组的方法进行编译,并赋值给数组属性的 __proto__ 属性上,因为原型链的机制,找到对应的方法就不会继续往上找了。编译方法中会对一些会增加索引的方法(push,unshift,splice)进行手动 observe。具体同样可以参考我的这篇文章 为什么Vue3.0不再使用defineProperty实现数据监听?,里面有详细的源码分析。
4. 组件的 data 为什么要写成函数形式?
Vue 的组件都是可复用的,一个组件创建好后,可以在多个地方复用,而不管复用多少次,组件内的 data 都应该是相互隔离,互不影响的,所以组件每复用一次,data 就应该复用一次,每一处复用组件的 data 改变应该对其他复用组件的数据不影响。
为了实现这样的效果,data 就不能是单纯的对象,而是以一个函数返回值的形式,所以每个组件实例可以维护独立的数据拷贝,不会相互影响。
5. nextTick是做什么用的,其原理是什么?
能回答清楚这道问题的前提,是清楚 EventLoop 过程。
在下次 DOM 更新循环结束后执行延迟回调,在修改数据之后立即使用 nextTick 来获取更新后的 DOM。
nextTick 对于 micro task 的实现,会先检测是否支持 Promise,不支持的话,直接指向 macro task,而 macro task 的实现,优先检测是否支持 setImmediate(高版本IE和Etage支持),不支持的再去检测是否支持 MessageChannel,如果仍不支持,最终降级为 setTimeout 0;
默认的情况,会先以 micro task 方式执行,因为 micro task 可以在一次 tick 中全部执行完毕,在一些有重绘和动画的场景有更好的性能。
但是由于 micro task 优先级较高,在某些情况下,可能会在事件冒泡过程中触发,导致一些问题(可以参考 Vue 这个 issue:https://github.com/vuejs/vue/issues/6556),所以有些地方会强制使用 macro task (如 v-on)。
注意:之所以将
nextTick的回调函数放入到数组中一次性执行,而不是直接在nextTick中执行回调函数,是为了保证在同一个tick内多次执行了nextTcik,不会开启多个异步任务,而是把这些异步任务都压成一个同步任务,在下一个tick内执行完毕。
6. Vue 的模板编译原理
vue模板的编译过程分为3个阶段:
第一步:解析
将模板字符串解析生成 AST,生成的AST 元素节点总共有 3 种类型,1 为普通元素, 2 为表达式,3为纯文本。
第二步:优化语法树
Vue 模板中并不是所有数据都是响应式的,有很多数据是首次渲染后就永远不会变化的,那么这部分数据生成的 DOM 也不会变化,我们可以在 patch 的过程跳过对他们的比对。
此阶段会深度遍历生成的 AST 树,检测它的每一颗子树是不是静态节点,如果是静态节点则它们生成 DOM 永远不需要改变,这对运行时对模板的更新起到极大的优化作用。
第三步:生成代码
const code = generate(ast, options)
通过 generate 方法,将ast生成 render 函数。更多关于 AST,Vue 模板编译原理,以及和 AST 相关的 Babel 工作原理等,我在 掌握了AST,再也不怕被问babel,vue编译,Prettier等原理 中做了详细介绍。
7. v-for 中 key 的作用是什么?
清晰回答这道问题,需要先清楚 Vue 的 diff 过程。关于 diff 原理,推荐一篇文章:
https://my.oschina.net/u/3060934/blog/3103711/print。
key 是给每个 vnode 指定的唯一 id,在同级的 vnode diff 过程中,可以根据 key 快速的对比,来判断是否为相同节点,并且利用 key 的唯一性可以生成 map 来更快的获取相应的节点。
另外指定 key 后,就不再采用“就地复用”策略了,可以保证渲染的准确性。
8. 为什么 v-for 和 v-if 不建议用在一起
当 v-for 和 v-if 处于同一个节点时,v-for 的优先级比 v-if 更高,这意味着 v-if 将分别重复运行于每个 v-for 循环中。如果要遍历的数组很大,而真正要展示的数据很少时,这将造成很大的性能浪费。
这种场景建议使用 computed,先对数据进行过滤。
路由相关问题
1. Vue-router 导航守卫有哪些
全局前置/钩子:beforeEach、beforeResolve、afterEach
路由独享的守卫:beforeEnter
组件内的守卫:beforeRouteEnter、beforeRouteUpdate、beforeRouteLeave
完整的导航解析流程如下:
- 导航被触发。
- 在失活的组件里调用离开守卫。
- 调用全局的 beforeEach 守卫。
- 在重用的组件里调用 beforeRouteUpdate 守卫 (2.2+)。
- 在路由配置里调用 beforeEnter。
- 解析异步路由组件。
- 在被激活的组件里调用 beforeRouteEnter。
- 调用全局的 beforeResolve 守卫 (2.5+)。
- 导航被确认。
- 调用全局的 afterEach 钩子。
- 触发 DOM 更新。
- 用创建好的实例调用 beforeRouteEnter 守卫中传给 next 的回调函数。
2. vue-router hash 模式和 history 模式有什么区别?
区别:
- url 展示上,hash 模式有“#”,history 模式没有
- 刷新页面时,hash 模式可以正常加载到 hash 值对应的页面,而 history 没有处理的话,会返回 404,一般需要后端将所有页面都配置重定向到首页路由。
- 兼容性。hash 可以支持低版本浏览器和 IE。
3. vue-router hash 模式和 history 模式是如何实现的?
hash 模式:
#后面 hash 值的变化,不会导致浏览器向服务器发出请求,浏览器不发出请求,就不会刷新页面。同时通过监听 hashchange 事件可以知道 hash 发生了哪些变化,然后根据 hash 变化来实现更新页面部分内容的操作。
history 模式:
history 模式的实现,主要是 HTML5 标准发布的两个 API,pushState 和 replaceState,这两个 API 可以在改变 url,但是不会发送请求。这样就可以监听 url 变化来实现更新页面部分内容的操作。
关于 vue-router 部分,推荐文章:
https://juejin.im/post/5b10b46df265da6e2a08a724
本文是系列文章《2020年大厂面试指南》的第一篇文章,后续系列文章更新,请关注公众号【前端小苑】。
 更多文章请点击“阅读原文” 喜欢本文点个“在看”哟!
更多文章请点击“阅读原文” 喜欢本文点个“在看”哟!