python基础练习(二)
文章目录
- 前言
- 一、实验目的
- 二、实验内容与结果:
-
- 2.1 题目分析
- 2.2 代码
- 2.3 结果与分析:(包含数据集分析、实验过程、结果截图、结果分析等)
- 三、实验总结
-
- 3.1 出现的问题与解决方法:
- 3.2 知识点总结:
- 3.3 个人总结:
前言
其实本次的博客是更在去找老师答辩后,老师提出了几点代码的改进,我觉得十分受益,但是由于时间受限的原因也不打算完善了,争取在下次实验中的思想更加完善吧。 (ps 希望我能在堆满实验的双周里好好存活下来O.O)一、实验目的
习题一:
- 用numpy随机生成一元(多元)数据;如线性、指数、三角函数,或者多种样式结合;
- 画出数据散点图和模型曲线。
a) 设置xy轴的坐标范围; b) 散点图和模型曲线用不同颜色;
习题二:
一个目录里面多个python程序文件,统计一下里面有多少行代码。
即分别列出:代码、空行、注释的行数。
二、实验内容与结果:
2.1 题目分析
Demo1分析:
先用numpy生成x的数据,再结合numpy库构造y的函数,画出模型曲线,再对y的值生成高斯分布的概率密度随机数,画出散点图
Demo2分析:
第一版本(代码加#注释的一行属于不算入注释行)
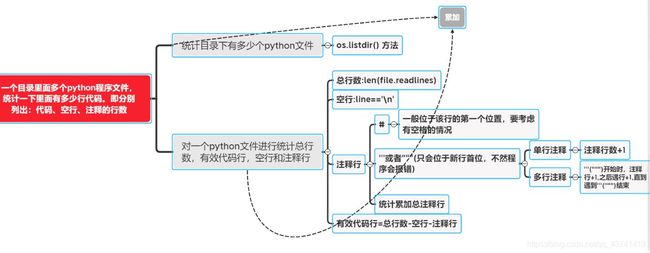
升级版本(代码加#注释的一行属于算入注释行)

2.2 代码
Demo1:
# -*- codeing =utf-8 -*-
# @Time : 2021/3/25 14:56
# @Author : ArLin
# @File : New_demo1.py
# @Software: PyCharm
import matplotlib.pyplot as plt
import numpy as np
import math
#x = np.arange(-10,10,0.1)
#x = np.linspace(-1,1,300)
#y = x**2+2*x+1
x=np.linspace(-2*np.pi,2*np.pi,300)
y = 0.5*x+1+np.cos(x)
new_y = y+np.random.normal(scale=0.4,size=300)
plt.title("demo1")
plt.plot(x, y)
plt.plot(x,new_y,'.')
plt.show()
Demo2:
第一版本(代码加#注释的一行属于不算入注释行):
# -*- codeing =utf-8 -*-
# @Time : 2021/3/25 15:30
# @Author : ArLin
# @File : demo4.py
# @Software: PyCharm
import os,sys
def Allfile(path):
allfile = []
for file in os.listdir(path):
if os.path.splitext(file)[1]=='.py':
allfile.append(path +'\\'+file)
print('文件目录添加',file)
return allfile
def find1(lines):
Space = 0
Notes = 0
for line in lines:
if line == '\n':
Space = Space + 1
else:
a = line.strip()
if a[0] == '#':
Notes = Notes + 1
return Space,Notes
def find2(p,lines,Notes,pp):
index = 0
while index < len(lines):
if lines[index].startswith(p):
if lines[index].count(p) != 2:
index = index + 1
Notes = Notes + 1
while lines[index].startswith(p) != True:
if lines[index].endswith(pp) != True:
index = index + 1
Notes = Notes + 1
else:
break
index = index + 1
Notes = Notes + 1
else:
index = index + 1
return Notes
def onedemo(path):
fo=open(path,'r',encoding='utf8')
lines=fo.readlines()
Notes=find1(lines)[1]
ANotes=find2("'''",lines,Notes,"'''\n")+find2('"""',lines,Notes,'"""\n')-Notes
Space=find1(lines)[0]
#print("该文件总行数:%d,其中有效代码行数:%d,空行行数:%d,注释行数:%d"%(len(lines),len(lines)-ANotes-Space,Space,ANotes))
return(len(lines),len(lines)-ANotes-Space,Space,ANotes)
if __name__ =='__main__':
path = 'D:\python\pytharm\demo\pythonProject\pythonProject1'
All_file = Allfile(path)
Count=[]
All_lines=0
All_Space=0
All_Notes=0
j=0
for i in All_file:
j=j+1
Count.append(onedemo(i))
All_lines=All_lines+onedemo(i)[0]
All_Space=All_Space+onedemo(i)[2]
All_Notes=All_Notes+onedemo(i)[3]
print("文件%d总行数:%d,其中有效代码行数:%d,空行行数:%d,注释行数:%d" % (j,onedemo(i)[0], onedemo(i)[1], onedemo(i)[2], onedemo(i)[3]))
print(Count)
print("该目录下所有文件总代码行数:%d,其中有效代码行数:%d,空行行数:%d,注释行数:%d" % (All_lines,All_lines-All_Space-All_Notes,All_Space,All_Notes))
升级版本(代码加#注释的一行属于算入注释行):
#-*- codeing =utf-8 -*-
#@Time : 2021/4/3 16:32
#@Author : ArLin
#@File : demo6.py
#@Software: PyCharm
import os,sys
def Allfile(path):
allfile = []
for file in os.listdir(path):
if os.path.splitext(file)[1]=='.py':
allfile.append(path +'\\'+file)
print('文件目录添加',file)
return allfile
def find1(lines):
Space = 0
Notes = 0
S_Notes = 0
for line in lines:
if line == '\n':
Space = Space + 1
else:
a = line.strip()
if a[0] == '#':
Notes = Notes + 1
else:
j=1
while j<len(a):
if a[j]=='#':
S_Notes = S_Notes + 1
j=j+1
return Space,Notes,S_Notes
def find2(p,lines,Notes,pp):
index = 0
while index < len(lines):
if lines[index].startswith(p):
if lines[index].count(p) != 2:
index = index + 1
Notes = Notes + 1
while lines[index].startswith(p) != True:
if lines[index].endswith(pp) != True:
index = index + 1
Notes = Notes + 1
else:
break
index = index + 1
Notes = Notes + 1
else:
index = index + 1
return Notes
def onedemo(path):
fo=open(path,'r',encoding='utf8')
lines=fo.readlines()
Notes=find1(lines)[1]
SNotes = find1(lines)[2]
ANotes=find2("'''",lines,Notes,"'''\n")+find2('"""',lines,Notes,'"""\n')-Notes
Space=find1(lines)[0]
#print("该文件总行数:%d,其中有效代码行数:%d,空行行数:%d,注释行数:%d"%(len(lines),len(lines)-ANotes-Space,Space,ANotes))
return(len(lines),len(lines)-ANotes-Space,Space,ANotes,SNotes)
if __name__ =='__main__':
path = 'D:\python\pytharm\demo\pythonProject\pythonProject1'
All_file = Allfile(path)
Count=[]
All_lines=0
All_Space=0
All_Notes=0
j=0
for i in All_file:
j=j+1
Count.append(onedemo(i))
All_lines = All_lines+onedemo(i)[0]
All_V_lines = All_lines + onedemo(i)[1]
All_Space=All_Space+onedemo(i)[2]
All_Notes=All_Notes+onedemo(i)[3]+onedemo(i)[4]
print("文件%d总行数:%d,其中有效代码行数:%d,空行行数:%d,注释行数:%d" % (j,onedemo(i)[0], onedemo(i)[1], onedemo(i)[2], onedemo(i)[3]+onedemo(i)[4]))
print(Count)
print("该目录下所有文件总代码行数:%d,其中有效代码行数:%d,空行行数:%d,注释行数:%d" % (All_lines, All_V_lines,All_Space,All_Notes))
2.3 结果与分析:(包含数据集分析、实验过程、结果截图、结果分析等)
Demo1:


如图是两种不同函数组合出来的效果
Demo2:
第一版本(代码加#注释的一行属于不算入注释行)

测试了带有多种注释,空行和有效代码行的单独情况以及组合情况,
均是验证测试成功。
升级版本(代码加#注释的一行属于算入注释行):


三、实验总结
3.1 出现的问题与解决方法:
问题1:
一开始在demo1中生成随机数据拟合好曲线后,散点图和曲线重叠,看不出散点图
解决方法:
用np.random.norma生成高斯分布的概率密度随机数,就可以得到明显的散点图
问题2:
刚开始未考虑到有空格的#注释的情况,就会导致有空格的#不算入空格行
解决方法:
通过line.strip()的方法判断首字符是否是#,即可解决
问题3:
刚开始未考虑#加在代码后单行是否算注释行的情况
解决方法:
问了老师后,老师说都可以,就写了两个版本,在对注释行的#判断情况里面,用遍历单行查找匹配值的方法来多记录这个值,在最后算注释行的时候加入进去
3.2 知识点总结:
1. np.random.normal()
np是numpy包的缩写,np.random.normal()的意思是一个正态分布,normal是正态的意思
语法:
numpy.random.normal(loc,scale,size)
参数loc(float):正态分布的均值,对应着这个分布的中心。loc=0说明这一个以Y轴为对称轴的正态分布,
参数scale(float):正态分布的标准差,对应分布的宽度,scale越大,正态分布的曲线越矮胖,scale越小,曲线越高瘦。
参数size(int 或者整数元组):输出的值赋在shape里,默认为None。
2. os.listdir()
os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表。
它不包括 . 和 … 即使它在文件夹中。
只支持在 Unix, Windows 下使用。
语法:
os.listdir(path) – path – 需要列出的目录路径
返回指定路径下的文件和文件夹列表。
3. File readlines()
readlines() 方法用于读取所有行(直到结束符 EOF)并返回列表,该列表可以由 Python 的 for… in … 结构进行处理。如果碰到结束符 EOF 则返回空字符串。
语法:
fileObject.readlines( );
返回值-返回列表,包含所有的行
4. strip()
Python strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
语法
str.strip([chars]); chars – 移除字符串头尾指定的字符序列。
5. startswith()
Python startswith() 方法用于检查字符串是否是以指定子字符串开头,如果是则返回 True,否则返回 False。如果参数 beg 和 end 指定值,则在指定范围内检查。
语法:
str.startswith(str, beg=0,end=len(string));
str – 检测的字符串。
strbeg – 可选参数用于设置字符串检测的起始位置。
strend – 可选参数用于设置字符串检测的结束位置。如果检测到字符串则返回True,否则返回False。
6. endswith()
Python endswith() 方法用于判断字符串是否以指定后缀结尾,如果以指定后缀结尾返回True,否则返回False。可选参数"start"与"end"为检索字符串的开始与结束位置。
语法
str.endswith(suffix[, start[, end]])
参数
suffix – 该参数可以是一个字符串或者是一个元素。
start – 字符串中的开始位置。
end – 字符中结束位置。
如果字符串含有指定的后缀返回True,否则返回False。
3.3 个人总结:
终于要写完本次的实验报告了,感觉自己花费了很多的时间。在习题二中刚开始一头雾水,后来经过网上查阅资料后了解了基本的知识,但是由于上节课被老师指出最好不要写出千篇一律的代码,于是还是决定按照自己的思路来慢慢的写,这就导致会在过程中发现很多的bug,一遍遍的调试,尝试,写了好几版的代码,最后算是写出了一个完善的代码,但是觉得自己的思路一直都是比较按部就班的写法,这就导致多频率出现双重循环和if/else的情况判断,觉得有机会的话,或许能够通过代码量的累积,可以形成一些比较新颖的写法。