Java常用类的使用
Java常用类
1. Optional
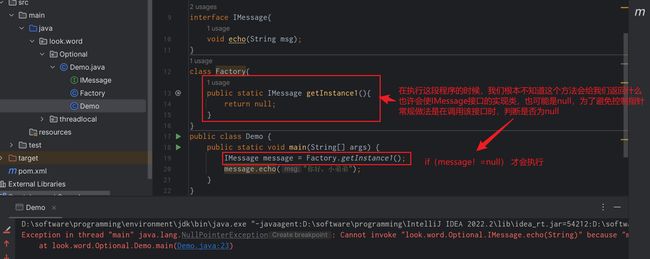
在我们的开发中,NullPointerException可谓是随时随处可见,为了避免空指针异常,我们常常需要进行 一
些防御式的检查,所以在代码中常常可见if(obj != null) 这样的判断。幸好在JDK1.8中,java为我们提供了
一个Optional类,Optional类能让我们省掉繁琐的非空的判断。下面先说一下Optional中为我们提供的方法。

反面示例:
interface IMessage{
void echo(String msg);
}
class Factory{
public static IMessage getInstance1(){
return (msg -> System.out.println("msg = " + msg)); // 正常
}
}
public class Demo {
public static void main(String[] args) {
IMessage message = Factory.getInstance1();
if(message!=null){ // 不为null才调用
message.echo("你好,小弟弟");
}
}
}
正面示例:
interface IMessage {
void echo(String msg);
}
class Factory {
public static Optional<IMessage> getInstance2() {
return Optional.of((msg -> System.out.println(msg))); // 保存到 Optional中 如果保存的为null的话,还是会发生空指针异常
}
}
public class Demo {
public static void main(String[] args) {
IMessage message = Factory.getInstance2().get();// 取出 Optional中的数据
message.echo("你好,小弟弟");
}
}
这里想要表达的意思就是,保存到Optional中的数据为null,只会在赋值是出现空指针异常,而不会等到调用是才出现,增强了业务的健壮性。
2. ThreadLocal
从名字我们就可以看到
ThreadLocal叫做本地线程变量,意思是说,ThreadLocal中填充的的是当前线程的变量,该变量对其他线程而言是封闭且隔离的,ThreadLocal为变量在每个线程中创建了一个副本,这样每个线程都可以访问自己内部的副本变量。 从字面意思很容易理解,但是实际角度就没那么容易了,作为一个面试常问的点,使用场景也是很丰富。
- 1、在进行对象跨层传递的时候,使用ThreadLocal可以避免多次传递,打破层次间的约束。
- 2、线程间数据隔离
- 3、进行事务操作,用于存储线程事务信息。
- 4、数据库连接,
Session会话管理。
1. 常用方法

2. ThreadLocal怎么用?
下面我先举一个反面例子,加深大家的理解。
启动三个线程,遍历values数组,然后看他们的输出结果。
@Data
class Message {
public String content;
}
class MessagePrint { // 输出结果
public static void print() {
System.out.println("【MessagePrint】" + Resource.message.content);
}
}
/**
* 中间类
*/
class Resource {
static Message message;
}
/**
* 测试
* @author jiejie
* @date 2022/09/01
*/
public class Demo1 {
public static void main(String[] args) {
String[] values = {"你好,弟弟", "你好,妹妹", "你好,姐姐"};
for (String value : values) {
new Thread(() -> {
Resource.message = new Message();
Resource.message.setContent(value);
MessagePrint.print();
}).start();
}
}
结果:

可以看到,输出的结果怎么是一样的呢,我们不是遍历输出的吗。这就要谈到我们的线程安全的问题,简单来说,多个线程同时对某个对象进行赋值就会存在线程安全的问题,其实相对于这个问题,我们可以加锁来解决这个问题。今天我们使用另外一个方法,就是上面提到的ThreadLocal。请看:
修改Resource:
/**
* 中间类
*/
class Resource {
private static ThreadLocal<Message> threadLocal = new ThreadLocal<>();
public static Message getMessage() {
return threadLocal.get();
}
public static void setMessage(Message message) {
threadLocal.set(message);
}
public static void removeMessage() {
threadLocal.remove();
}
}
class MessagePrint { // 输出
public static void print() {
System.out.println("【MessagePrint】" + Resource.getMessage().content);
}
}
public class Demo1 {
public static void main(String[] args) {
String[] values = {"你好,弟弟", "你好,妹妹", "你好,姐姐"};
for (String value : values) {
new Thread(() -> {
Resource.setMessage(new Message());
Resource.getMessage().setContent(value);
MessagePrint.print();
}).start();
}
}
}
程序执行结果:

可以看到,我们的目的实现了,有没有发现输出的顺序与values数组的顺序并不一致,这是由于我们线程启动的顺序决定的。
我们这里就体现了线程间对于变量的隔离。
3. 定时任务
在开发过程中,经常性需要一些定时或者周期性的操作。而在Java中则使用Timer对象完成定时计划任务功能。
定时计划任务功能在Java中主要使用的就是Timer对象,它在内部使用多线程的方式进行处理,所以Timer对象一般又和多线程技术结合紧密。
由于Timer是Java提供的原生Scheduler(任务调度)工具类,不需要导入其他jar包,使用起来方便高效,非常快捷。

参数说明:
- task:所要执行的任务,需要extends TimeTask override run()
- time/firstTime:首次执行任务的时间
- period:周期性执行Task的时间间隔,单位是毫秒
- delay:执行task任务前的延时时间,单位是毫秒 很显然,通过上述的描述,我们可以实现: 延迟多久后执行一次任务;指定时间执行一次任务;延迟一段时间,并周期性执行任务;指定时间,并周期性执行任务;
1. timer
- 实现TimerTask**(需要执行什么任务**)的run方法, 明确要做什么
可以继承实现, 也可用匿名内部类- new 一个Timer
- 调用Timer实例的 schedule 或 scheduleAtFixedRate 方法
将TimerTask放入Timer,并指定开始时间 和 间隔时间
简单用法
public class Demo {
public static void main(String[] args) {
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run() {
System.out.println("【定时任务】定时执行");
}
}, 1000, 2000);
}
}
执行结果:
【定时任务】定时执行
【定时任务】定时执行
【定时任务】定时执行
1.2 schedule和scheduleAtFixedRate有什么区别?
scheduleAtFixedRate:每次执行时间为上一次任务开始起向后推一个period间隔,也就是说下次执行时间相对于上一次任务开始的时间点,因此执行时间不会延后,但是存在任务并发执行的问题(简单来说,就是当任务阻塞,下次任务开始的时间不会受阻塞影响,而推迟下次任务执行时间。)。
schedule:每次执行时间为上一次任务结束后推一个period间隔,也就是说下次执行时间相对于上一次任务结束的时间点,因此执行时间会不断延后(回受阻塞影响)。
1.3:如果执行task发生异常,是否会影响其他task的定时调度?
如果TimeTask抛出RuntimeException,那么Timer会停止所有任务的运行!
1.4 Timer的一些缺陷?
前面已经提及到Timer背后是一个单线程,因此Timer存在管理并发任务的缺陷:所有任务都是由同一个线程来调度,所有任务都是串行执行,意味着同一时间只能有一个任务得到执行,而前一个任务的延迟或者异常会影响到之后的任务。 其次,Timer的一些调度方式还算比较简单,无法适应实际项目中任务定时调度的复杂度。
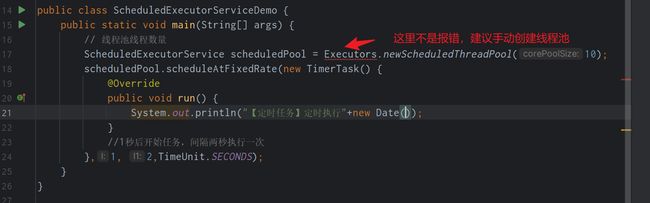
2 JDK对定时任务调度的线程池支持:ScheduledExecutorService
由于Timer存在的问题,JDK5之后便提供了基于线程池的定时任务调度:ScheduledExecutorService。 设计理念:每一个被调度的任务都会被线程池中的一个线程去执行,因此任务可以并发执行,而且相互之间不受影响。
我们直接看例子:
执行结果:
【定时任务】定时执行Fri Sep 02 12:54:02 CST 2022
【定时任务】定时执行Fri Sep 02 12:54:04 CST 2022
【定时任务】定时执行Fri Sep 02 12:54:06 CST 2022
3 定时任务大哥:Quartz
虽然ScheduledExecutorService对Timer进行了线程池的改进,但是依然无法满足复杂的定时任务调度场景。因此OpenSymphony提供了强大的开源任务调度框架:Quartz。Quartz是纯Java实现,而且作为Spring的默认调度框架,由于Quartz的强大的调度功能、灵活的使用方式、还具有分布式集群能力,可以说Quartz出马,可以搞定一切定时任务调度!
3.1 核心:
任务 Job
我们想要调度的任务都必须实现 org.quartz.job 接口,然后实现接口中定义的 execute( ) 方法即可,类似于TimerTask。
触发器 Trigger
Trigger 作为执行任务的调度器。我们如果想要凌晨1点执行备份数据的任务,那么 Trigger 就会设置凌晨1点执行该任务。其中 Trigger 又分为 SimpleTrigger 和 CronTrigger 两种
调度器 Scheduler
Scheduler 为任务的调度器,它会将任务 Job 及触发器 Trigger 整合起来,负责基于 Trigger 设定的时间来执行 Job
3.2 使用Quartz
导入依赖:
<!--quartz-->
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz</artifactId>
<version>2.3.2</version>
</dependency>
创建任务类:
public class TestJob implements Job{
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
System.out.println("【定时任务】定时执行"+new Date());
}
}
测试
class TestScheduler {
public static void main(String[] args) throws SchedulerException {
// 获取默认任务调度器
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
// 定义Job(任务)实例
JobDetail testJob = JobBuilder.newJob(TestJob.class)
.withIdentity("测试任务").build();
// 定义触发器
Trigger simpleTrigger = TriggerBuilder.newTrigger()
.withIdentity("测试任务的触发器")
.startNow()
.withSchedule(SimpleScheduleBuilder.repeatSecondlyForever(1))
.build();
// 使用触发器调度任务的执行
scheduler.scheduleJob(testJob, simpleTrigger);
scheduler.start();
}
}
经过上面的简单使用,我们再来了解下它的结构吧
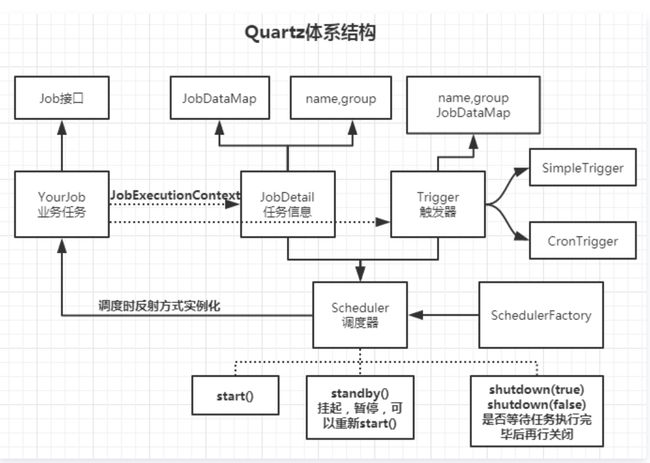
图中可知,还有一种触发器 CronTrigger,下面简单使用一下吧。
Cron表达式用法
测试类 任务类不变,修改测试类即可
class TestScheduler {
public static void main(String[] args) throws SchedulerException {
// 获取默认任务调度器
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
// 定义Job(任务)实例
JobDetail testJob = JobBuilder.newJob(TestJob.class)
.withIdentity("测试任务").build();
// 定义触发器
CronTrigger cronTrigger = TriggerBuilder.newTrigger()
.withIdentity("name", "group")
.withSchedule(CronScheduleBuilder.cronSchedule("0/2 * * ? * *")).build();
// 使用触发器调度任务的执行
scheduler.scheduleJob(testJob, cronTrigger);
scheduler.start();
}
}
4 Arrays
Arrays类位于 java.util 包中,主要包含了操纵数组的各种方法。
常用方法:

1 排序
升序排序
public class Demo {
public static void main(String[] args) {
int[] arr = {1, 2, 19, 4, 5, 6, 7, 8, 9};
System.out.printf("【未排序前的数组:】%s \n", Arrays.toString(arr)); // Arrays.toString(arr) 数组转换成字符串
Arrays.sort(arr);
System.out.printf("【排序后的数组:】%s", Arrays.toString(arr));
}
}
// 执行结果
//【未排序前的数组:】[1, 2, 19, 4, 5, 6, 7, 8, 9]
//【排序后的数组:】[1, 2, 4, 5, 6, 7, 8, 9, 19]
2 判断是否相等
需要一模一样的数组,执行结果才会为True
判断大小关系:大于(1)、等于(0)、小于(-1)
public class Demo2 {
public static void main(String[] args) {
int[] arrA = {1, 5, 7};
int[] arrB = {7, 5, 1};
System.out.println("【判断是否相等 -未排序】" + Arrays.equals(arrA, arrB));
Arrays.sort(arrA);
Arrays.sort(arrB);
System.out.println("【判断是否相等 -排序后】" + Arrays.equals(arrA, arrB));
System.out.println("【判断数组的大小关系 -排序后】" + Arrays.compare(arrA, arrB));
System.out.println("【判断数组的大小关系 -随机数组】" + Arrays.compare(new int[]{1, 2, 3}, arrB));
System.out.println("【判断数组的大小关系 -随机数组】" + Arrays.compare(new int[]{7, 8, 9}, arrB));
}
}
// 执行结果
//【判断是否相等 -未排序】false
//【判断是否相等 -排序后】true
//【判断数组的大小关系 -排序后】0
//【判断数组的大小关系 -随机数组】-1
//【判断数组的大小关系 -随机数组】1
3 二分查找
二分查找在大数据量的场景下,性能非常好。
下面举个栗子:
- 试想一下,要是我们的arrA数组的数据量非常大,达到了百万级别甚至更多,我们想要在里面找到某个数据,会遍历数组很多次,时间复杂度O(n)
public class Demo3 {
public static void main(String[] args) {
int[] arrA = {1, 3, 5, 7, 9};// 模拟数组
int key = 9;// 需要查找的数据
int index = search(arrA, key);
System.out.println("index = " + index);
}
// 普通 循环查询,未查找到返回-1
private static int search(int[] arrA, int key) {
for (int i = 0; i < arrA.length; i++) {
if (arrA[i] == key) {
return i;
}
}
return -1;
}
}
然后我们再来看看,二分查找。
注意,使用二分查找的前提下,要保证数组的有序性(先排序)
- Arrays.binarySearch(数组,key);(Arrays提供的二分查找)
/**
* 二分查找
*/
private static int twoPoints(int[] arrA, int key) {
Arrays.sort(arrA);
System.out.println("【排序后的数组:】"+Arrays.toString(arrA));
// 开始索引
int start = 0;
// 结束索引
int end = arrA.length - 1;
while (start <= end) {
// 位运算 这里以5为例 101(5) >>>1 10(2) mid(中间的下标)
int mid = start+end >>> 1;
int midVal = arrA[mid];
// 用中间值的key比较,中间值小的话,说明我们需要查找的数据在右边,中间值+1赋值start
if (midVal < key) {
start = mid + 1;
}// 用中间值的key比较,中间值打的话,说明我们需要查找的数据在右边,中间值-1赋值end
else if (midVal > key) {
end = mid - 1;
} else {
return mid;
}
}
// 未找到
return -1;
}

4 比较器
4.1 比较器出现的原因
在Java项目开发的机制之中,比较器是一种最为常见的功能,同时在整个的Java类集实现架构之中,比较器都有着非常重要的地位,但是首先应该知道为什么要使用比较器?﹒通过之前的讲解应该已经发现在Java里面提供有一个所谓的Arrays类,这个Arrays类提供有大量的数组有关的操作方法,而其中,可以发现这样的一个方法定义:
public static void sort(Object[] a)
发现Arrays类也可以直接实现对象数组的排序处理,于是下面就按照此方法的规则进行程序的编写。范例:实现一个对象数组的排序﹐
@AllArgsConstructor
@Data
class Book{
String name;
double price;
}
public class 比较器 {
public static void main(String[] args) {
Book[] books= new Book[] {
new Book("Java入门到入土",89.0),
new Book("Python入门到入土",78.0),
new Book("前端入门到入土",68.0)
};
Arrays.sort(books);
}
}
执行程序: 可以发现,程序执行报错了。类转换异常
Exception in thread "main" java.lang.ClassCastException: class look.word.arrays.Book cannot be cast to class java.lang.Comparable (look.word.arrays.Book is in unnamed module of loader 'app'; java.lang.Comparable is in module java.base of loader 'bootstrap')
at java.base/java.util.ComparableTimSort.countRunAndMakeAscending(ComparableTimSort.java:320)
at java.base/java.util.ComparableTimSort.sort(ComparableTimSort.java:188)
at java.base/java.util.Arrays.sort(Arrays.java:1041)
at look.word.arrays.比较器.main(比较器.java:26)
在程序执行的过程之中出现有一个“ClassCastException”异常,这种异常所描述的就是对象转换异常,这里面直接提示给用户“不能够将Book类的对象实例转为Comparable”。那么为什么现在会出现这样的异常呢?
如果说现在给定的是一个整型数组,那么如果要想确定数组之中的元素彼此之间的大小关系,直接利用各种关系运算符即可,但是问题是此时所给出的是一个对象数组,对象数组里面所包含的内容一个个堆内存的信息,那么请问堆内存的信息如何进行大小关系的比较呢?。
很明显,堆内存无法直接进行大小关系的比较,如果要的进行排序处理,严格意义上来讲应该使用是堆内存中属性的内容来进行大小关系确认,而这个属性内容的确认就必须采用比较器来支持,而在Java里面支持有两种比较器:Comparable、Comparator。
4.2 Comparable
要想自定义的类,实现可以比的效果,可以实现我们的Comparable接口,实现其compareTo方法。定义比较规则。
示例:
@AllArgsConstructor
@Data
class Book implements Comparable<Book>{
String name;
double price;
@Override
public int compareTo(Book book) {
if (this.price > book.price){
return 1;
} else if (this.price < book.price) {
return -1;
}
return 0;
}
}
执行程序:
可以看到,这次程序执行没有出错,并且是升序排序的。如若修改排序规则,修改每次判断的返回值即可。
- String类就实现了Comparable这个接口,也就是说String类支持排序。
【Book类继承比较器比较后的结果】
[Book(name=前端入门到入土, price=68.0),
Book(name=Python入门到入土, price=78.0),
Book(name=Java入门到入土, price=89.0)]
4.3 Comparator
需要使用 Comparator 是一个带有@FunctionalInterface,也就是说它是一个函数式接口,可以使用Lambda表达式,也可以使用匿名类部类的方式去定义我们的比较规则。
示例代码:
@AllArgsConstructor
@Data
class books {
String name;
double price;
}
public class 比较器2 {
public static void main(String[] args) {
books[] books = new books[]{
new books("Java入门到入土", 89.0),
new books("Python入门到入土", 78.0),
new books("前端入门到入土", 68.0)
};
Comparator<books> comparator = (books1, books2) -> {
if (books1.price > books2.price) {
return 1;
} else if (books1.price < books2.price) {
return -1;
}
return 0;
};
Arrays.sort(books, comparator.reversed()); // comparator.reversed() 是反转的意思
System.out.println("【books类继承比较器比较后的结果】\n" + Arrays.toString(bookss));
}
}
程序执行结果:
【books类继承比较器比较后的结果】
[books(name=Java入门到入土, price=89.0),
books(name=Python入门到入土, price=78.0),
books(name=前端入门到入土, price=68.0)]
Comparator 除了基本的排序支持之外,其内部实际上也存在有大量的数据排序的处理操作,例如: reversed(),如果现在使用的是Comparable接口实现这样的反转那么必须进行大量系统源代码的修改,法来进行配置,所以灵活度更高。
总结:请解释两种比较器的区别?
- java.Jang.Comparable:是在类定义的时候实现的接口,该接口只存在有一个compareTo()方法用于确定大小关系;
- java.utilComparator:是属于挽救的比较器,除了可以实现排序的功能之外,在JDK 1.8之后的版本里面还提供有更多方便的数组操作的处理功能。
5 StringBuffer
定义一个 StringBuffer类对象,然后通过append()方法向对象中添加26个小写字母,要求每次只添加一次,共添加26次,然后按照逆序的方式输出,并且可以删除前5个字符。
传统面向过程做法
/**
* 传统面向过程实现
**/
public class Demo {
public static void main(String[] args) {
StringBuffer buffer = new StringBuffer(26);
for (int i = 'a'; i <= 'z'; i++) {
buffer.append((char) i);
}
System.out.println("【初始的数据】" + buffer);
System.out.println("【逆序输出】" + buffer);
System.out.println("【删除前5个】" + buffer.delete(0, 5));
}
}
虽然这个时候已经完成了所对应的处理功能,但是如果仅仅是以一位所谓的初学者的角度来讲肯定是没有问题的,但问题是现在需要讨论的不是能否实现的问题了,而是属于如何实现更好的问题.如果按照面向对象的设计形式以上的操作代码明显是不合理的,主要体现在对于当前给定的程序模型应该以接口的设计先行,而后定义具体的操作子类。
**范例:**通过面向对象的方式进行程序的开发
interface IContent { // 接口先行
String content();
String reverse();
String delete(int start, int end);
}
class StringContent implements IContent {
private StringBuffer buffer = new StringBuffer(26);
public StringContent() {
for (int i = 'a'; i <= 'z'; i++) {
buffer.append((char) i);
}
}
public String content() {
return buffer.toString();
}
public String reverse() {
return buffer.reverse().toString();
}
public String delete(int start, int end) {
return buffer.delete(start, end).toString();
}
}
class Factory { // 工厂获取实例
private Factory() {}
public static StringContent getInstance() {
return new StringContent();}
}
public class Demo2 {
public static void main(String[] args) {
StringContent content = Factory.getInstance();
System.out.println("【初始的数据】" + content.content());
System.out.println("【逆序输出】" + content.reverse());
System.out.println("【删除前5个】" + content.delete(0, 5));
}
}
在面向对象的设计结构之中所有的程序代码必须首先定义出公共的处理标准(定义接口),随后再依据此标准进行项目的具体实现,对于接口子类的获取也需要考虑到工厂设计模式。
6 反射
1. 出现的原因
Java编程开发之所以会存在有反射机制,最为重要的原因是可以使Java编写代码更加的灵活,而这种灵活如果要想彻底的领悟,那么也需要通过大量的苦练才可以得到,当你已经可以熟练使用反射之后,那么就可以设计出更加结构性强,且可重用性更高的程序代码,在Java里面存在有很多的开发框架,而之所以可以提供大量开发框架,主要的原因也在于反射机制。
Java的反射机制指的是通过“反方向”的操作来实现类的相关处理,那么既然要有“反”则一定会有“正”,按照传统的开发的行为模式来讲,如果要想进行一个类的操作,那么是需要根据类进行对象的实例化,随后再通过实例化对象实现类中方法的调用处理,现在给出如下代码。
范例:观察传统的类的使用行为
class Book{
public void read(){
System.out.println("认真学习java书籍!");
}
}
public class Demo {
public static void main(String[] args) {
Book book = new Book(); // 实例化对象
book.read(); // 调用实例的方法
}
}
// 执行结果: 认真学习java书籍!
以上的处理操作是一种正向的处理行为,但是如果是反向操作,则就意味着可以根据实例化对象获取相关的信息来源,在Java里面所有的类实际上都属于Object子类,那么在Object类中就提供有一个重要的方法,这个方法可以获取“反”的信息:
2. 反射的入口
java.lang.Class
对每一种对象,JVM 都会实例化一个 java.lang.Class 的实例,java.lang.Class 为我们提供了在运行时访问对象的属性和类型信息的能力。Class 还提供了创建新的类和对象的能力。最重要的是,Class 是调用其他反射 API 的入口,我们必须先获得一个 Class 实例才可以进行接下来的操作。
获取类Class对象的四种方式:
- 调用运行时类本身的.class属性
Class<String> stringClass = String.class;
- 通过运行时类的对象获取
Class<? extends String> aClass = new String().getClass();
- 通过Class的静态方法获取:体现反射的动态性
try {
Class<?> aClass1 = Class.forName("java.lang.String");
} catch (ClassNotFoundException e) {
throw new RuntimeException(e);
}
- 通过类的加载器
ClassLoader classLoader = this.getClass().getClassLoader(); // 获取类加载器
Class<?> aClass1 = classLoader.loadClass("java.lang.String");
3. 获取成员变量
java.lang.Class也提供了许多获取成员变量的方法:
- public Field[] getDeclaredFields() 获取所有的属性(包括私有的)
- public Field[] getFields() 获取所有public 修饰的属性
当然每个成员变量有类型和值。
java.lang.reflect.Field为我们提供了获取当前对象的成员变量的类型,和重新设值的方法。提供了两个方法获去变量的类型:
field.getModifiers(): 获取属性的修饰符
Field.getName():获取属性的的名称
Field.getType():返回这个属性的类型
Field.getGenericType():如果当前属性有签名属性类型就返回,否则就返回
Field.getType()
@Data
class Books{
String name;
public Integer age;
private Integer gender;
protected String salt;
}
public class 属性 {
public static void main(String[] args) {
Class<Books> booksClass = Books.class;
// 获取所有属性 包括私有的
Field[] fields = booksClass.getDeclaredFields();
for (Field field : fields) {
// 设置访问无障碍
field.setAccessible(true);
System.out.print("【修饰符】" + Modifier.toString(field.getModifiers()));
System.out.print("【\t变量的类型】" + field.getType());
System.out.print("【\t属性的的名称】 = " + field.getName()+"\n");
}
}
}
4. 调用方法
- Class.getMethods(): 获取所有的方法
- Class.getMethod(“方法名”,“方法的参数列表数据类型”);
- Class.getParmenterTypes(); // 获取参数列表
- Class.getReturnType();//返回类型
class Book1 {
public void init() {
System.out.println("初始图书" );
}
public void read(String name) {
System.out.println("读了" + name);
}
}
public class 方法 {
public static void main(String[] args) throws Exception {
Class<Book1> bookClass = Book1.class; // 获取Class对象
Method init = bookClass.getMethod("init"); // 获取指定方法
init.invoke(bookClass.newInstance(),null); // 执行实例无参方法
Method read = bookClass.getMethod("read", String.class); // 获取指定方法
read.invoke(bookClass.newInstance(),"java图书"); // 执行实例有参方法
Method[] methods = bookClass.getMethods();
for (Method method : methods) { // 遍历所有方法
System.out.println("method = " + method);
}
}
}