Spring、MyBatis、Druid、MySQL执行SQL语句与事务监控
1. 前言
使用MySQL数据库时,使用事务与不使用事务相比,出现问题时排查更复杂。
不使用事务时,客户端只需要请求MySQL服务一次(只考虑显式执行的SQL语句);使用事务时,客户端至少需要请求MySQL服务四次(开启事务、执行SQL语句、提交/回滚事务、恢复自动提交)。
在Java中存在一些用法会导致事务失效,有的问题比较明显可以较快定位,有的问题隐藏较深可能需要较长时间排查。
因此需要对MySQL的事务执行原理进行分析,并整理用于排查事务相关问题的快速有效的方法。
可以根据MySQL客户端访问MySQL服务时的连接ID(MySQL服务线程ID),或MySQL客户端源端口,来判断事务执行情况。
在Java应用中访问MySQL服务时,涉及Java应用、网络传输、MySQL服务这三层,在每一层都可以对执行的SQL语句与事务操作进行监控与观测,涉及的内容如下图所示:
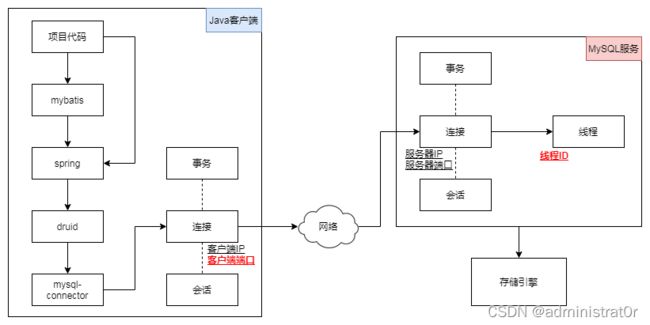
对于Java应用,可以使用Druid提供的监控功能,在自定义代码中对事务执行情况进行监控,根据使用的连接ID(线程ID)或客户端端口判断事务是否生效。
2. 示例项目
以下使用的示例项目下载地址为:https://github.com/Adrninistrator/DB-Transaction-test,使用说明可参考“README.md”,
相关的执行日志保存在DB-Transaction-test-log目录中,log-print_stack_trace_off目录中是未打印调用堆栈的日志,log-print_stack_trace_on目录中是打印调用堆栈的日志。
3. 验证环境
- JDK版本
1.8
- Spring版本
5.3.20
- Mybatis版本
org.mybatis:mybatis:3.2.8
org.mybatis:mybatis-spring:1.2.2
- Druid版本
1.2.10
- MySQL Connector版本
8.0.29
- MySQL版本
MariaDB 10.0.36
- Spring事务传播机制
默认值REQUIRED
4. Spring执行事务相关日志
在log4j2等日志组件的配置文件中,加入以下两个包名(或对应的完整类名),可打印Spring执行事务时的相关日志:
org.springframework.transaction.support
org.springframework.jdbc.datasource
以下为Spring执行事务相关日志示例:
AbstractPlatformTransactionManager.getTransaction(370) - Creating new transaction with name
DataSourceTransactionManager.doBegin(267) - Acquired Connection [] for JDBC transaction
DataSourceTransactionManager.doBegin(285) - Switching JDBC Connection [] to manual commit
AbstractPlatformTransactionManager.processCommit(740) - Initiating transaction commit
DataSourceTransactionManager.doCommit(330) - Committing JDBC transaction on Connection []
DataSourceTransactionManager.doCleanupAfterCompletion(389) - Releasing JDBC Connection [] after transaction
以上为执行提交事务操作时Spring的日志,日志中的关键字及对应含义如下:
| 日志中的关键字 | 含义 |
|---|---|
| Creating new transaction | 创建事务 |
| Acquired Connection | 获取连接 |
| Switching JDBC Connection to manual commit | 关闭连接自动提交 |
| Initiating transaction | 初始化事务 |
| Committing JDBC transaction | 提交事务 |
| Releasing JDBC Connection after transaction | 释放连接 |
在回滚事务时,日志中不会出现以上“DataSourceTransactionManager.doCommit”对应的提交事务内容,会显示为以下回滚事务的内容:
DataSourceTransactionManager.doRollback(345) - Rolling back JDBC transaction on Connection []
以上日志中相关的类如下:
org.springframework.transaction.support.AbstractPlatformTransactionManager
org.springframework.jdbc.datasource.DataSourceTransactionManager
5. MyBatis执行SQL语句相关日志
参考MyBatis关于日志的说明文档https://mybatis.org/mybatis-3/logging.html。
MyBatis支持多种不同的日志组件,通过日志组件的配置,可在日志中记录MyBatis的SQL语句执行信息,具体的配置方式取决于使用的日志组件。
在日志组件的配置中,可以添加MyBatis的Mapper的包名、完整类名,或语句(方法)名,可以指定在日志中需要记录信息的范围。
使用trace日志级别,可以将完整的SQL执行信息记录到日志中,包含了查询的结果集;假如只需要记录执行的SQL语句,不需要查询结果,可以使用debug日志级别。
假如存在org.mybatis.example包,在该名中存在BlogMapper接口,该接口中存在selectBlog方法,则可在日志配置中进行以下配置:
- 记录包中的SQL语句执行情况
org.mybatis.example
- 记录类中的SQL语句执行情况
org.mybatis.example.BlogMapper
- 记录方法中的SQL语句执行情况
org.mybatis.example.BlogMapper.selectBlog
以下为MyBatis执行SQL语句相关日志示例,日志级别为debug,可以看到执行的SQL语句、参数、执行结果行数等:
BaseJdbcLogger.debug(139) - ==> Preparing: select task_name, lock_flag, begin_time, end_time, process_info, now() as db_current_date from task_lock where task_name = ? for update
BaseJdbcLogger.debug(139) - ==> Parameters: TEST_DB_TRANSACTION(String)
BaseJdbcLogger.debug(139) - <== Total: 1
6. Druid连接池提供的监控功能
如上所述,MyBatis的日志可以记录执行的SQL语句信息,但没有记录事务的相关信息;Spring的日志可以记录事务的相关信息,但不够详细。
为了记录事务相关的详细执行信息,可以使用Druid连接池实现。
6.1. 使用Druid内置Filter监控SQL语句
6.1.1. Druid文档说明
以下为Druid文档中的说明:
- 配置_Filter配置
https://github.com/alibaba/druid/wiki/%E9%85%8D%E7%BD%AE_Filter%E9%85%8D%E7%BD%AE
DruidDataSource支持通过Filter-Chain模式进行扩展,类似Serlvet的Filter,扩分方便,你可以拦截任何JDBC的方法。
有两种配置Filter的方式,一种是配置filters属性,一种是配置proxyFilters属性。filters和proxyFilters的配置是组合关系,而不是替换关系。
配置filters属性比较简单,filters的类型是字符串,多个filter使用逗号隔开。例如:
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">
...
<property name="filters" value="stat,log4j" />
bean>
filters属性的配置使用别名或者全类名
proxyFilters的类型是List,使用proxyFilters配置,可以有更多的配置选项。
<bean id="stat-filter" class="com.alibaba.druid.filter.stat.StatFilter">
bean>
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">
...
<property name="proxyFilters">
<list>
<ref bean="stat-filter" />
list>
property>
bean>
- 内置Filter的别名
https://github.com/alibaba/druid/wiki/%E5%86%85%E7%BD%AEFilter%E7%9A%84%E5%88%AB%E5%90%8D
在META-INF/druid-filter.properties文件中配置Filter的别名。
| Filter实现类名 | 别名 |
|---|---|
| default | com.alibaba.druid.filter.stat.StatFilter |
| stat | com.alibaba.druid.filter.stat.StatFilter |
| mergeStat | com.alibaba.druid.filter.stat.MergeStatFilter |
| encoding | com.alibaba.druid.filter.encoding.EncodingConvertFilter |
| log4j | com.alibaba.druid.filter.logging.Log4jFilter |
| log4j2 | com.alibaba.druid.filter.logging.Log4j2Filter |
| slf4j | com.alibaba.druid.filter.logging.Slf4jLogFilter |
| commonlogging | com.alibaba.druid.filter.logging.CommonsLogFilter |
| wall | com.alibaba.druid.wall.WallFilter |
- 配置_StatFilter
https://github.com/alibaba/druid/wiki/%E9%85%8D%E7%BD%AE_StatFilter
Druid内置提供一个StatFilter,用于统计监控信息。
StatFilter的别名是stat,这个别名映射配置信息保存在druid-xxx.jar!/META-INF/druid-filter.properties。
- 配置_LogFilter
https://github.com/alibaba/druid/wiki/%E9%85%8D%E7%BD%AE_LogFilter
Druid内置提供了四种LogFilter(Log4jFilter、Log4j2Filter、CommonsLogFilter、Slf4jLogFilter),用于输出JDBC执行的日志。这些Filter都是Filter-Chain扩展机制中的Filter
在druid-xxx.jar!/META-INF/druid-filter.properties文件中描述了这四种Filter的别名
druid.filters.log4j=com.alibaba.druid.filter.logging.Log4jFilter
druid.filters.log4j2=com.alibaba.druid.filter.logging.Log4j2Filter
druid.filters.slf4j=com.alibaba.druid.filter.logging.Slf4jLogFilter
druid.filters.commonlogging=com.alibaba.druid.filter.logging.CommonsLogFilter
druid.filters.commonLogging=com.alibaba.druid.filter.logging.CommonsLogFilter
他们的别名分别是log4j、log4j2、slf4j、commonlogging和commonLogging。
loggerName配置
LogFilter都是缺省使用四种不同的Logger执行输出,看实现代码:
public abstract class LogFilter {
protected String dataSourceLoggerName = "druid.sql.DataSource";
protected String connectionLoggerName = "druid.sql.Connection";
protected String statementLoggerName = "druid.sql.Statement";
protected String resultSetLoggerName = "druid.sql.ResultSet";
}
log4j.properties配置
如果你使用log4j,可以通过log4j.properties文件配置日志输出选项,例如:
log4j.logger.druid.sql=warn,stdout
log4j.logger.druid.sql.DataSource=warn,stdout
log4j.logger.druid.sql.Connection=warn,stdout
log4j.logger.druid.sql.Statement=warn,stdout
log4j.logger.druid.sql.ResultSet=warn,stdout
6.1.2. Druid内置Filter使用方式
使用Druid内置Filter“druid.filters.stat=com.alibaba.druid.filter.stat.StatFilter”对SQL语句执行情况进行监控,假如使用的日志组件为log4j2,则需要与Druid内置Filter“druid.filters.log4j2=com.alibaba.druid.filter.logging.Log4j2Filter”一起使用,可在Spring XML中通过filters属性指定,如下所示:
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">
...
<property name="filters" value="stat,log4j2"/>
bean>
在log4j2的配置文件中,可指定以下包名的日志级别为debug,在日志中记录相关的执行信息,分别为:数据源、连接、SQL语句、执行结果。
druid.sql.DataSource
druid.sql.Connection
druid.sql.Statement
druid.sql.ResultSet
6.1.3. Druid内置Filter stat在日志中记录的信息
以下为Druid内置Filter stat的日志示例:
Log4j2Filter.connectionLog(132) - {conn-210001,procId-69} connected
Log4j2Filter.statementLog(137) - {conn-210001, stmt-220001} created
Log4j2Filter.statementLog(137) - {conn-210001, stmt-220001, rs-250001} query executed. 0.903187 millis. SELECT 'ds1'
Log4j2Filter.resultSetLog(142) - {conn-210001, stmt-220001, rs-250001} open
Log4j2Filter.resultSetLog(142) - {conn-210001, stmt-220001, rs-250001} Header: [ds1]
Log4j2Filter.resultSetLog(142) - {conn-210001, stmt-220001, rs-250001} closed
Log4j2Filter.statementLog(137) - {conn-210001, stmt-220001} closed
Log4j2Filter.connectionLog(132) - {conn-210001} pool-connect
Log4j2Filter.connectionLog(132) - {conn-210001} setAutoCommit false
Log4j2Filter.statementLog(137) - {conn-210001, pstmt-220002} created. select
task_name, lock_flag, begin_time, end_time, process_info, now() as db_current_date
from task_lock
where task_name = ? for update
Log4j2Filter.statementLog(137) - {conn-210001, pstmt-220002} Parameters : [TEST_DB_TRANSACTION]
Log4j2Filter.statementLog(137) - {conn-210001, pstmt-220002} Types : [VARCHAR]
Log4j2Filter.statementLog(137) - {conn-210001, pstmt-220002} executed. 2.721016 millis. select
task_name, lock_flag, begin_time, end_time, process_info, now() as db_current_date
from task_lock
where task_name = ? for update
Log4j2Filter.resultSetLog(142) - {conn-210001, pstmt-220002, rs-250002} open
Log4j2Filter.resultSetLog(142) - {conn-210001, pstmt-220002, rs-250002} Header: [task_name, lock_flag, begin_time, end_time, process_info, db_current_date]
Log4j2Filter.resultSetLog(142) - {conn-210001, pstmt-220002, rs-250002} Result: [xxx]
Log4j2Filter.resultSetLog(142) - {conn-210001, pstmt-220002, rs-250002} closed
Log4j2Filter.statementLog(137) - {conn-210001, pstmt-220002} closed
Log4j2Filter.connectionLog(132) - {conn-210001} commited
Log4j2Filter.connectionLog(132) - {conn-210001} setAutoCommit true
Log4j2Filter.connectionLog(132) - {conn-210001} pool-recycle
以上日志中的关键字及含义如下所示:
| 日志中的关键字 | 含义 |
|---|---|
| connected | 创建连接 |
| pool-connect | 从连接池借出连接 |
| setAutoCommit false | 关闭自动提交 |
| executed | 执行SQL语句 |
| commited | 提交事务 |
| setAutoCommit true | 开启自动提交 |
| pool-recycle | 归还连接至连接池 |
在回滚事务时,日志中不会出现以上“commited”对应的提交事务内容,会显示为“rollback”。
Druid日志显示的“conn-xxx”内容,xxx对应的数字为连接对象对应的一个数字,不是MySQL实际连接(线程)的ID。MySQL实际连接(线程)的ID为“procId-xx”对应的数字,如以上的“procId-69”,说明连接ID为69。
对于不经过Druid执行SQL语句等操作,不会调用Druid的Filter,也无法在Filter中监控相应的操作,例如mysql-connector中调用“SET sql_mode=‘STRICT_TRANS_TABLES’”SQL语句,此类SQL语句的情况情况可通过抓包等方式查看。
6.2. 使用Druid自定义Filter监控SQL语句与事务执行
Druid支持使用自定义Filter,可对SQL语句与事务执行按照需要进行监控。
使用Druid自定义Filter监控SQL语句与事务执行的效果,可参考“数据源使用错误导致MySQL事务失效分析”。
6.2.1. Druid自定义Filter配置方式
在Spring XML中,可通过以下方式,在“com.alibaba.druid.pool.DruidDataSource”对应的bean中配置Druid自定义Filter。
6.2.1.1. 通过proxyFilters属性配置
通过DruidMonitorFilter的proxyFilters属性配置Druid自定义Filter时,需要指定Filter的列表,在列表中指定自定义Filter对应的bean,如下所示:
<bean id="monitor-filter-bean" class="test.db.druid_filter.filter.DruidMonitorFilter" init-method="initFilter" destroy-method="destroyFilter"/>
<bean id="dataSource1" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">
...
<property name="proxyFilters">
<list>
<ref bean="monitor-filter-bean"/>
list>
property>
bean>
假如在Spring XML中,通过DruidDataSource指定了多个数据源时,通过proxyFilters属性进行配置,可以使不同的数据源使用同一个Filter实例。
6.2.1.2. 通过filters属性配置
- META-INF/druid-filter.properties配置
通过DruidDataSource的filters属性配置Druid自定义Filter时,首先需要在“META-INF/druid-filter.properties”配置文件中指定Filter别名,在以上配置文件中,每一行代表一个Filter,格式为:“druid.filters.Filter别名=Filter完整类名”,如下所示:
druid.filters.monitor_filter=test.db.druid_filter.filter.DruidMonitorFilter
- Spring XML配置
完成以上配置后,在Spring XML中,为DruidDataSource的filters属性指定Filter别名,如下所示:
<bean id="dataSource1" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">
...
<property name="filters" value="monitor_filter"/>
bean>
假如在Spring XML中,通过DruidDataSource指定了多个数据源时,通过filters属性进行配置,每个数据源使用的都是单独的Filter实例。
- Druid对META-INF/druid-filter.properties中的Filter初始化方式
Druid在com.alibaba.druid.filter.FilterManager类的loadFilterConfig()方法中对“META-INF/druid-filter.properties”配置文件中的Filter进行初始化。
在FilterManager类的loadFilterConfig()方法中,读取了classpath中的“META-INF/druid-filter.properties”配置文件;
在FilterManager类的static代码块中,对读取到的配置中,处理以“druid.filters.”开头的数据,并将“druid.filters.”前缀去除,将剩余内容作为Filter别名使用。
6.2.2. Druid自定义Filter开发实现
Druid中的Filter需要实现com.alibaba.druid.filter.Filter接口,为了简化自定义Filter开发工作,自定义Filter也可以继承以下Druid内置的Filter抽象类:
com.alibaba.druid.filter.FilterAdapter
com.alibaba.druid.filter.FilterEventAdapter
上类FilterEventAdapter为FilterAdapter的子类。
Druid在很多操作对应的方法中,会调用Filter链,在自定义Filter中重载对应的方法,可对相关操作进行接管与监控。
6.2.3. 示例项目中监控的信息处理方式
在示例项目中,对SQL语句与事务执行过程中的以下信息进行了监控。
6.2.3.1. SQL会话信息获取
获取的SQL会话信息包含如下内容,主要用于监控事务的执行情况,在示例项目中对应test.db.druid_filter.dto.SqlSessionInfo类:
com.mysql.cj.jdbc.ConnectionImpl对象HashCode
连接ID(MySQL服务线程ID)
连接的本地端口
自动提交开关
MySQL服务IP
MySQL服务端口
MySQL数据库名称
MySQL用户名
MySQL版本
通过MySQL Connector的com.mysql.cj.jdbc.ConnectionImpl连接对象,可以获取以上SQL会话信息。在示例项目的test.db.druid_filter.filter.DruidMonitorFilter类的getSqlSessionInfoFromConnectionImpl()方法中进行了获取,相关信息的获取方式如下(ConnectionImpl类型变量名称为connectionImpl):
| 信息名称 | 获取方式 |
|---|---|
| 连接ID(MySQL服务线程ID) | connectionImpl.getSession().getThreadId() |
| 连接的本地端口 | connectionImpl.getSession().getProtocol().getSocketConnection().getMysqlSocket().getLocalPort() |
| 自动提交开关 | connectionImpl.getSession().getProtocol().getServerSession().isAutoCommit() |
| MySQL服务IP | connectionImpl.getSession().getProtocol().getSocketConnection().getMysqlSocket().getInetAddress().getHostAddress() |
| MySQL服务端口 | connectionImpl.getSession().getProtocol().getSocketConnection().getMysqlSocket().getPort() |
| MySQL数据库名称 | connectionImpl.getDatabase() |
| MySQL用户名 | connectionImpl.getUser() |
| MySQL版本 | connectionImpl.getSession().getProtocol().getServerSession().getServerVersion().toString() |
在示例项目的Druid自定义Filter中,与SQL语句及事务执行相关方法的参数都可以获取到ConnectionImpl对象,可用于获取以上SQL会话信息。
6.2.3.2. 数据源名称获取与记录
在示例项目的Druid自定义Filter实现类中,为了使SQL语句与事务执行的监控效果更直观,会显示当前使用的连接对应的数据源名称。
在Druid自定义Filter实现类的方法中,只有从连接池借出连接的dataSource_getConnection()方法参数中包含了DruidDataSource对象(name属性为数据源名称),且该方法中可以获得对应的连接信息,可在Map中记录当前连接ID对应的数据源名称。
在Druid自定义Filter实现类的其他方法中,可从以上Map中根据当前连接ID获取对应数据源名称。
6.2.3.3. 开启事务与执行SQL语句时的连接ID对比
假如开启事务(关闭自动提交)与执行SQL语句时使用的连接不相同(即以上操作在MySQL服务的不同线程中执行),则事务不会生效。
对于以上事务失效的问题,通过以下方式进行监控:
在Druid自定义Filter实现类的关闭自动提交方法中,将连接ID记录在ThreadLocal中;
在执行SQL语句方法中,从ThreadLocal中获取关闭自动提交时使用的连接ID,判断与当前使用的连接ID是否相同;若关闭自动提交与执行SQL语句时使用的连接ID不同,则说明事务不会生效;
在关闭连接、提交事务、回滚事务、开启自动提交方法中,清理以上ThreadLocal。
6.2.3.4. 数据库连接执行的SQL语句次数获取与记录
在示例项目的Druid自定义Filter实现类中,为了使SQL语句与事务执行的监控效果更直观,会在提交事务及归还连接至连接池时,显示数据库连接执行的SQL语句次数。通过以下方式实现:
在示例项目的Druid自定义Filter实现类中,通过Map记录数据库连接ID,及对应的SQL语句执行次数。
执行SQL语句方法,在记录执行次数的Map中,将当前连接ID对应的次数加1(若是第一次执行则将次数设为1);
归还连接至连接池方法,在记录执行次数的Map中,将当前连接ID对应的数据清理。
通过以上方式对数据库连接执行的SQL语句次数记录的方式存在限制,仅在使用常见的事务提交/回滚方式时,才能保证显示的SQL语句执行次数准确。
6.2.4. 示例项目中Druid自定义Filter实现的监控功能
示例项目中的Druid自定义Filter实现类为test.db.druid_filter.filter.DruidMonitorFilter,重载了超类的以下方法,可用于对SQL语句与事务执行进行以下操作的监控。
6.2.4.1. 创建连接
Druid创建连接后,会调用FilterEventAdapter子类的connection_connectAfter()方法,参数中连接对象为ConnectionProxy connection,类型为com.alibaba.druid.proxy.jdbc.ConnectionProxy。
通过以下方式,可以根据ConnectionProxy获得ConnectionImpl连接对象,可用于获取SQL会话信息SqlSessionInfo:
(ConnectionImpl) connection.getRawObject()
在DruidMonitorFilter类的以上方法中,查询了information_schema.processlist表中,id等于当前连接ID的信息,即MySQL服务线程当前正在执行的操作。SQL语句如下所示:
select * from information_schema.processlist where id = CONNECTION_ID()
通过监控日志中的信息可知,通过连接对象ConnectionImpl connectionImpl,调用“connectionImpl.getSession().getThreadId()”获取的值,就是MySQL服务的连接ID/线程ID。
6.2.4.2. 从连接池借出连接
Druid从连接池借出连接前,会调用Filter实现类的dataSource_getConnection()方法,在调用父类的当前方法后,返回对象为DruidPooledConnection druidPooledConnection,类型为com.alibaba.druid.pool.DruidPooledConnection。
通过以下方式,可以根据DruidPooledConnection获得ConnectionImpl连接对象,可用于获取SQL会话信息SqlSessionInfo:
(ConnectionImpl) ((ConnectionProxyImpl) druidPooledConnection.getConnectionHolder().getConnection()).getRawObject()
6.2.4.3. 关闭自动提交
Druid关闭自动提交前,会调用Filter实现类的connection_setAutoCommit()方法,参数“boolean autoCommit”值为false,参数中连接对象为ConnectionProxy connection。
6.2.4.4. 执行SQL语句
Druid执行SQL语句前,会调用FilterEventAdapter子类的statementExecuteBefore()方法,参数中语句对象为StatementProxy statement,类型为com.alibaba.druid.proxy.jdbc.StatementProxy。
通过以下方式,可以根据StatementProxy获得ConnectionImpl连接对象,可用于获取SQL会话信息SqlSessionInfo:
(ConnectionImpl) statement.getConnectionProxy().getRawObject()
6.2.4.5. 提交事务
Druid提交事务前,会调用Filter实现类的connection_commit()方法,参数中连接对象为ConnectionProxy connection。
6.2.4.6. 回滚事务
Druid回滚事务前,会调用Filter实现类的connection_rollback()方法,参数中连接对象为ConnectionProxy connection。
6.2.4.7. 开启自动提交
Druid开启自动提交前,会调用Filter实现类的connection_setAutoCommit()方法,参数“boolean autoCommit”值为true,参数中连接对象为ConnectionProxy connection。
6.2.4.8. 归还连接至连接池
Druid归还连接至连接池前,会调用Filter实现类的dataSource_releaseConnection()方法,参数中连接对象为DruidPooledConnection connection。
6.2.4.9. 关闭连接
Druid关闭连接前,会调用Filter实现类的connection_close()方法,参数中连接对象为ConnectionProxy connection。
7. Java代码中判断是否开启事务的快速方法
7.1. 判断是否开启事务的方法
在某些情况下,需要知道当前代码执行时是否有开启事务。
在通过Spring使用事务的Java项目中,可在代码中通过以下方法快速分析是否有开启事务。
Spring的org.springframework.transaction.support.TransactionSynchronizationManager类中,存在静态方法isActualTransactionActive(),其返回类型为boolean。
调用以上方法返回true时,代表当前存在活动的事务。
以上方法通过ThreadLocal变量actualTransactionActive记录当前是否有开启事务。
示例项目的DruidMonitorFilter类中,在执行SQL语句时会执行的statementExecuteBefore()方法中,调用了以上TransactionSynchronizationManager.isActualTransactionActive(),用于监控执行SQL语句时是否有开启事务。
7.2. 判断是否开启事务的使用场景
使用Spring的TransactionSynchronizationManager.isActualTransactionActive()方法判断是否开启事务,包括但不限于以下使用场景。
7.2.1. 检查@Transactional注解的事务是否失效
通过@Transactional注解使用事务时,可能因为在当前类的方法中调用@Transactional注解所在方法,由于未调用AOP处理后的代理类,导致事务失效。
为了避免@Transactional注解对应事务失效,可在对应方法中通过以上方式判断事务是否生效。
通过TransactionTemplate使用事务时,不需要进行以上检查。
7.2.2. 避免RPC调用在事务中执行
在事务中需要避免进行RPC调用,以免因RPC调用超时或异常导致事务执行耗时太长或被回滚,可通过以上方式判断当前方法是否在事务中执行。
对于其他需要避免在事务中执行的方法,也可使用以上方式检查。
可参考示例项目中的TestCheckTransactionStatus_DiffTT、TestCheckTransactionStatus_SameTT类的执行日志。
7.3. Spring对actualTransactionActive的设置
在org.springframework.transaction.support.TransactionSynchronizationManager类的setActualTransactionActive()方法中,对ThreadLocal变量actualTransactionActive进行了设置。
使用Spring开启事务时,会调用AbstractPlatformTransactionManager.getTransaction()方法,该方法会调用到TransactionSynchronizationManager.setActualTransactionActive()方法,即开启事务时会将表示当前是否开启事务的变量actualTransactionActive设置为TRUE,调用堆栈如下:
org.springframework.transaction.support.AbstractPlatformTransactionManager.getTransaction(AbstractPlatformTransactionManager:373)
org.springframework.transaction.support.AbstractPlatformTransactionManager.startTransaction(AbstractPlatformTransactionManager:401)
org.springframework.transaction.support.AbstractPlatformTransactionManager.prepareSynchronization(AbstractPlatformTransactionManager:530)
org.springframework.transaction.support.TransactionSynchronizationManager.setActualTransactionActive(TransactionSynchronizationManager:422)
在TransactionSynchronizationManager.clear()方法中,对以上ThreadLocal变量actualTransactionActive进行了清理。
使用Spring提交事务或回滚事务时,会调用到TransactionSynchronizationManager.clear()方法,即提交事务或回滚事务时会将表示当前是否开启事务的变量设置为否。
提交事务时,调用TransactionSynchronizationManager.clear()方法的堆栈如下:
org.springframework.transaction.support.AbstractPlatformTransactionManager.commit(AbstractPlatformTransactionManager:711)
org.springframework.transaction.support.AbstractPlatformTransactionManager.processCommit(AbstractPlatformTransactionManager:790)
org.springframework.transaction.support.AbstractPlatformTransactionManager.cleanupAfterCompletion(AbstractPlatformTransactionManager:989)
org.springframework.transaction.support.TransactionSynchronizationManager.clear(TransactionSynchronizationManager:455)
回滚事务时,调用TransactionSynchronizationManager.clear()方法的堆栈如下:
org.springframework.transaction.support.AbstractPlatformTransactionManager.rollback(AbstractPlatformTransactionManager:809)
org.springframework.transaction.support.AbstractPlatformTransactionManager.processRollback(AbstractPlatformTransactionManager:875)
org.springframework.transaction.support.AbstractPlatformTransactionManager.cleanupAfterCompletion(AbstractPlatformTransactionManager:989)
org.springframework.transaction.support.TransactionSynchronizationManager.clear(TransactionSynchronizationManager:455)
8. 分析事务是否生效的其他方法
在IDE中对Java应用进行调试,在以上所述的提交事务的方法中设置断点(假如是服务器中运行的Java应用,可使用远程调试)
假如在事务中执行的SQL语句是select for update或update,则可启动一个MySQL客户端,在其中开启事务,执行相同的SQL语句,判断是否能加锁成功。
假如SQL语句执行后等待,说明Java应用中的事务是生效的;
假如SQL语句执行后立刻执行完毕,说明Java应用中的事务没有生效。