大家好,这篇文章主要跟大家聊下 Java 线程池面试中可能会问到的一些问题。
全程干货,耐心看完,你能轻松应对各种线程池面试。
相信各位 Javaer 在面试中或多或少肯定被问到过线程池相关问题吧,线程池是一个相对比较复杂的体系,基于此可以问出各种各样、五花八门的问题。
若你很熟悉线程池,如果可以,完全可以滔滔不绝跟面试官扯一个小时线程池,一般面试也就一个小时左右,那么这样留给面试官问其他问题的时间就很少了,或者其他问题可能问的也就不深入了,那你通过面试的几率是不就更大点了呢。

下面我们开始列下线程池面试可能会被问到的问题以及该怎么回答,以下只是参考答案,你也可以加入自己的理解。
1. 面试官:日常工作中有用到线程池吗?什么是线程池?为什么要使用线程池?
一般面试官考察你线程池相关知识前,大概率会先问这个问题,如果你说没用过,不了解,ok,那就没以下问题啥事了,估计你的面试结果肯定也凶多吉少了。
作为 JUC 包下的门面担当,线程池是名副其实的 JUC 一哥,不了解线程池,那说明你对 JUC 包其他工具也了解的不咋样吧,对 JUC 没深入研究过,那就是没掌握到 Java 的精髓,给面试官这样一个印象,那结果可想而知了。
所以说,这一分一定要吃下,那我们应该怎么回答好这问题呢?
可以这样说:
计算机发展到现在,摩尔定律在现有工艺水平下已经遇到难易突破的物理瓶颈,通过多核 CPU 并行计算来提升服务器的性能已经成为主流,随之出现了多线程技术。
线程作为操作系统宝贵的资源,对它的使用需要进行控制管理,线程池就是采用池化思想(类似连接池、常量池、对象池等)管理线程的工具。
JUC 给我们提供了 ThreadPoolExecutor 体系类来帮助我们更方便的管理线程、并行执行任务。
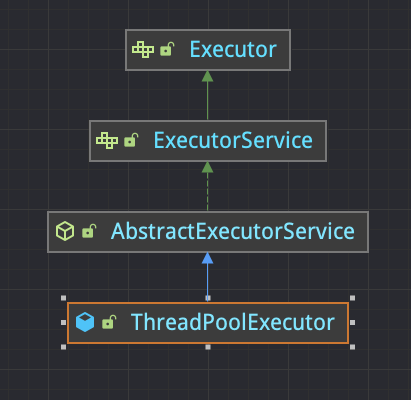
下图是 Java 线程池继承体系:
使用线程池可以带来以下好处:
- 降低资源消耗。降低频繁创建、销毁线程带来的额外开销,复用已创建线程
- 降低使用复杂度。将任务的提交和执行进行解耦,我们只需要创建一个线程池,然后往里面提交任务就行,具体执行流程由线程池自己管理,降低使用复杂度
- 提高线程可管理性。能安全有效的管理线程资源,避免不加限制无限申请造成资源耗尽风险
- 提高响应速度。任务到达后,直接复用已创建好的线程执行
线程池的使用场景简单来说可以有:
- 快速响应用户请求,响应速度优先。比如一个用户请求,需要通过 RPC 调用好几个服务去获取数据然后聚合返回,此场景就可以用线程池并行调用,响应时间取决于响应最慢的那个 RPC 接口的耗时;又或者一个注册请求,注册完之后要发送短信、邮件通知,为了快速返回给用户,可以将该通知操作丢到线程池里异步去执行,然后直接返回客户端成功,提高用户体验。
- 单位时间处理更多请求,吞吐量优先。比如接受 MQ 消息,然后去调用第三方接口查询数据,此场景并不追求快速响应,主要利用有限的资源在单位时间内尽可能多的处理任务,可以利用队列进行任务的缓冲

2. 面试官:ThreadPoolExecutor 都有哪些核心参数?
其实一般面试官问你这个问题并不是简单听你说那几个参数,而是想要你描述下线程池执行流程。
青铜回答:
包含核心线程数(corePoolSize)、最大线程数(maximumPoolSize),空闲线程超时时间(keepAliveTime)、时间单位(unit)、阻塞队列(workQueue)、拒绝策略(handler)、线程工厂(ThreadFactory)这7个参数。
钻石回答:
回答完包含这几个参数之后,会再主动描述下线程池的执行流程,也就是 execute() 方法执行流程。
execute()方法执行逻辑如下:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}可以总结出如下主要执行流程,当然看上述代码会有一些异常分支判断,可以自己顺理加到下述执行主流程里
- 判断线程池的状态,如果不是RUNNING状态,直接执行拒绝策略
- 如果当前线程数 < 核心线程池,则新建一个线程来处理提交的任务
- 如果当前线程数 > 核心线程数且任务队列没满,则将任务放入阻塞队列等待执行
- 如果 核心线程池 < 当前线程池数 < 最大线程数,且任务队列已满,则创建新的线程执行提交的任务
- 如果当前线程数 > 最大线程数,且队列已满,则执行拒绝策略拒绝该任务
王者回答:
在回答完包含哪些参数及 execute 方法的执行流程后。然后可以说下这个执行流程是 JUC 标准线程池提供的执行流程,主要用在 CPU 密集型场景下。
像 Tomcat、Dubbo 这类框架,他们内部的线程池主要用来处理网络 IO 任务的,所以他们都对 JUC 线程池的执行流程进行了调整来支持 IO 密集型场景使用。
他们提供了阻塞队列 TaskQueue,该队列继承 LinkedBlockingQueue,重写了 offer() 方法来实现执行流程的调整。
@Override
public boolean offer(Runnable o) {
//we can't do any checks
if (parent==null) return super.offer(o);
//we are maxed out on threads, simply queue the object
if (parent.getPoolSize() == parent.getMaximumPoolSize()) return super.offer(o);
//we have idle threads, just add it to the queue
if (parent.getSubmittedCount()<=(parent.getPoolSize())) return super.offer(o);
//if we have less threads than maximum force creation of a new thread
if (parent.getPoolSize()可以看到他在入队之前做了几个判断,这里的 parent 就是所属的线程池对象
1.如果 parent 为 null,直接调用父类 offer 方法入队
2.如果当前线程数等于最大线程数,则直接调用父类 offer()方法入队
3.如果当前未执行的任务数量小于等于当前线程数,仔细思考下,是不是说明有空闲的线程呢,那么直接调用父类 offer() 入队后就马上有线程去执行它
4.如果当前线程数小于最大线程数量,则直接返回 false,然后回到 JUC 线程池的执行流程回想下,是不是就去添加新线程去执行任务了呢
5.其他情况都直接入队
具体可以看之前写过的这篇文章
动态线程池(DynamicTp),动态调整Tomcat、Jetty、Undertow线程池参数篇
可以看出当当前线程数大于核心线程数时,JUC 原生线程池首先是把任务放到队列里等待执行,而不是先创建线程执行。
如果 Tomcat 接收的请求数量大于核心线程数,请求就会被放到队列中,等待核心线程处理,这样会降低请求的总体响应速度。
所以 Tomcat并没有使用 JUC 原生线程池,利用 TaskQueue 的 offer() 方法巧妙的修改了 JUC 线程池的执行流程,改写后 Tomcat 线程池执行流程如下:
- 判断如果当前线程数小于核心线程池,则新建一个线程来处理提交的任务
- 如果当前当前线程池数大于核心线程池,小于最大线程数,则创建新的线程执行提交的任务
- 如果当前线程数等于最大线程数,则将任务放入任务队列等待执行
- 如果队列已满,则执行拒绝策略
然后还可以再说下线程池的 Worker 线程模型,继承 AQS 实现了锁机制。线程启动后执行 runWorker() 方法,runWorker() 方法中调用 getTask() 方法从阻塞队列中获取任务,获取到任务后先执行 beforeExecute() 钩子函数,再执行任务,然后再执行 afterExecute() 钩子函数。若超时获取不到任务会调用 processWorkerExit() 方法执行 Worker 线程的清理工作。
详细源码解读可以看之前写的文章:

3. 面试官:什么是阻塞队列?说说常用的阻塞队列有哪些?
阻塞队列 BlockingQueue 继承 Queue,是我们熟悉的基本数据结构队列的一种特殊类型。
当从阻塞队列中获取数据时,如果队列为空,则等待直到队列有元素存入。当向阻塞队列中存入元素时,如果队列已满,则等待直到队列中有元素被移除。提供 offer()、put()、take()、poll() 等常用方法。
JDK 提供的阻塞队列的实现有以下几种:
1)ArrayBlockingQueue:由数组实现的有界阻塞队列,该队列按照 FIFO 对元素进行排序。维护两个整形变量,标识队列头尾在数组中的位置,在生产者放入和消费者获取数据共用一个锁对象,意味着两者无法真正的并行运行,性能较低。
2)LinkedBlockingQueue:由链表组成的有界阻塞队列,如果不指定大小,默认使用 Integer.MAX_VALUE 作为队列大小,该队列按照 FIFO 对元素进行排序,对生产者和消费者分别维护了独立的锁来控制数据同步,意味着该队列有着更高的并发性能。
3)SynchronousQueue:不存储元素的阻塞队列,无容量,可以设置公平或非公平模式,插入操作必须等待获取操作移除元素,反之亦然。
4)PriorityBlockingQueue:支持优先级排序的无界阻塞队列,默认情况下根据自然序排序,也可以指定 Comparator。
5)DelayQueue:支持延时获取元素的无界阻塞队列,创建元素时可以指定多久之后才能从队列中获取元素,常用于缓存系统或定时任务调度系统。
6)LinkedTransferQueue:一个由链表结构组成的无界阻塞队列,与LinkedBlockingQueue相比多了transfer和tryTranfer方法,该方法在有消费者等待接收元素时会立即将元素传递给消费者。
7)LinkedBlockingDeque:一个由链表结构组成的双端阻塞队列,可以从队列的两端插入和删除元素。

4. 面试官:你刚说到了 Worker 继承 AQS 实现了锁机制,那 ThreadPoolExecutor 都用到了哪些锁?为什么要用锁?
1)mainLock 锁
ThreadPoolExecutor 内部维护了 ReentrantLock 类型锁 mainLock,在访问 workers 成员变量以及进行相关数据统计记账(比如访问 largestPoolSize、completedTaskCount)时需要获取该重入锁。
面试官:为什么要有 mainLock?
private final ReentrantLock mainLock = new ReentrantLock();
/**
* Set containing all worker threads in pool. Accessed only when
* holding mainLock.
*/
private final HashSet workers = new HashSet();
/**
* Tracks largest attained pool size. Accessed only under
* mainLock.
*/
private int largestPoolSize;
/**
* Counter for completed tasks. Updated only on termination of
* worker threads. Accessed only under mainLock.
*/
private long completedTaskCount; 可以看到 workers 变量用的 HashSet 是线程不安全的,是不能用于多线程环境的。largestPoolSize、completedTaskCount 也是没用 volatile 修饰,所以需要在锁的保护下进行访问。
面试官:为什么不直接用个线程安全容器呢?
其实 Doug 老爷子在 mainLock 变量的注释上解释了,意思就是说事实证明,相比于线程安全容器,此处更适合用 lock,主要原因之一就是串行化 interruptIdleWorkers() 方法,避免了不必要的中断风暴
面试官:怎么理解这个中断风暴呢?
其实简单理解就是如果不加锁,interruptIdleWorkers() 方法在多线程访问下就会发生这种情况。一个线程调用interruptIdleWorkers() 方法对 Worker 进行中断,此时该 Worker 出于中断中状态,此时又来一个线程去中断正在中断中的 Worker 线程,这就是所谓的中断风暴。
面试官:那 largestPoolSize、completedTaskCount 变量加个 volatile 关键字修饰是不是就可以不用 mainLock 了?
这个其实 Doug 老爷子也考虑到了,其他一些内部变量能用 volatile 的都加了 volatile 修饰了,这两个没加主要就是为了保证这两个参数的准确性,在获取这两个值时,能保证获取到的一定是修改方法执行完成后的值。如果不加锁,可能在修改方法还没执行完成时,此时来获取该值,获取到的就是修改前的值。
2)Worker 线程锁
刚也说了 Worker 线程继承 AQS,实现了 Runnable 接口,内部持有一个 Thread 变量,一个 firstTask,及 completedTasks 三个成员变量。
基于 AQS 的 acquire()、tryAcquire() 实现了 lock()、tryLock() 方法,类上也有注释,该锁主要是用来维护运行中线程的中断状态。在 runWorker() 方法中以及刚说的 interruptIdleWorkers() 方法中用到了。
面试官:这个维护运行中线程的中断状态怎么理解呢?
protected boolean tryAcquire(int unused) {
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
public void lock() { acquire(1); }
public boolean tryLock() { return tryAcquire(1); }在runWorker() 方法中获取到任务开始执行前,需要先调用 w.lock() 方法,lock() 方法会调用 tryAcquire() 方法,tryAcquire() 实现了一把非重入锁,通过 CAS 实现加锁。

interruptIdleWorkers() 方法会中断那些等待获取任务的线程,会调用 w.tryLock() 方法来加锁,如果一个线程已经在执行任务中,那么 tryLock() 就获取锁失败,就保证了不能中断运行中的线程了。
所以 Worker 继承 AQS 主要就是为了实现了一把非重入锁,维护线程的中断状态,保证不能中断运行中的线程。

5. 面试官:你在项目中是怎样使用线程池的?Executors 了解吗?
这里面试官主要想知道你日常工作中使用线程池的姿势,现在大多数公司都在遵循阿里巴巴 Java 开发规范,该规范里明确说明不允许使用
Executors 创建线程池,而是通过 ThreadPoolExecutor 显示指定参数去创建
你可以这样说,知道 Executors 工具类,很久之前有用过,也踩过坑,Executors 创建的线程池有发生 OOM 的风险。
Executors.newFixedThreadPool 和 Executors.SingleThreadPool 创建的线程池内部使用的是无界(Integer.MAX_VALUE)的 LinkedBlockingQueue 队列,可能会堆积大量请求,导致 OOM
Executors.newCachedThreadPool 和Executors.scheduledThreadPool 创建的线程池最大线程数是用的Integer.MAX_VALUE,可能会创建大量线程,导致 OOM
自己在日常工作中也有封装类似的工具类,但是都是内存安全的,参数需要自己指定适当的值,也有基于 LinkedBlockingQueue 实现了内存安全阻塞队列 MemorySafeLinkedBlockingQueue,当系统内存达到设置的剩余阈值时,就不在往队列里添加任务了,避免发生 OOM
我们一般都是在 Spring 环境中使用线程池的,直接使用 JUC 原生 ThreadPoolExecutor 有个问题,Spring 容器关闭的时候可能任务队列里的任务还没处理完,有丢失任务的风险。
我们知道 Spring 中的 Bean 是有生命周期的,如果 Bean 实现了 Spring 相应的生命周期接口(InitializingBean、DisposableBean接口),在 Bean 初始化、容器关闭的时候会调用相应的方法来做相应处理。
所以最好不要直接使用 ThreadPoolExecutor 在 Spring 环境中,可以使用 Spring 提供的 ThreadPoolTaskExecutor,或者 DynamicTp 框架提供的 DtpExecutor 线程池实现。
也会按业务类型进行线程池隔离,各任务执行互不影响,避免共享一个线程池,任务执行参差不齐,相互影响,高耗时任务会占满线程池资源,导致低耗时任务没机会执行;同时如果任务之间存在父子关系,可能会导致死锁的发生,进而引发 OOM。
更多使用姿势参考之前发的文章:

6. 面试官:刚你说到了通过 ThreadPoolExecutor 来创建线程池,那核心参数设置多少合适呢?
这个问题该怎么回答呢?
可能很多人都看到过《Java 并发编程事件》这本书里介绍的一个线程数计算公式:
Ncpu = CPU 核数
Ucpu = 目标 CPU 利用率,0 <= Ucpu <= 1
W / C = 等待时间 / 计算时间的比例
要程序跑到 CPU 的目标利用率,需要的线程数为:
Nthreads = Ncpu Ucpu (1 + W / C)
这公式太偏理论化了,很难实际落地下来,首先很难获取准确的等待时间和计算时间。再着一个服务中会运行着很多线程,比如 Tomcat 有自己的线程池、Dubbo 有自己的线程池、GC 也有自己的后台线程,我们引入的各种框架、中间件都有可能有自己的工作线程,这些线程都会占用 CPU 资源,所以通过此公式计算出来的误差一定很大。
所以说怎么确定线程池大小呢?
其实没有固定答案,需要通过压测不断的动态调整线程池参数,观察 CPU 利用率、系统负载、GC、内存、RT、吞吐量 等各种综合指标数据,来找到一个相对比较合理的值。
所以不要再问设置多少线程合适了,这个问题没有标准答案,需要结合业务场景,设置一系列数据指标,排除可能的干扰因素,注意链路依赖(比如连接池限制、三方接口限流),然后通过不断动态调整线程数,测试找到一个相对合适的值。

7. 面试官:你们线程池是咋监控的?
因为线程池的运行相对而言是个黑盒,它的运行我们感知不到,该问题主要考察怎么感知线程池的运行情况。
可以这样回答:
我们自己对线程池 ThreadPoolExecutor 做了一些增强,做了一个线程池管理框架。主要功能有监控告警、动态调参。主要利用了 ThreadPoolExecutor 类提供的一些 set、get方法以及一些钩子函数。
动态调参是基于配置中心实现的,核心参数配置在配置中心,可以随时调整、实时生效,利用了线程池提供的 set 方法。
监控,主要就是利用线程池提供的一些 get 方法来获取一些指标数据,然后采集数据上报到监控系统进行大盘展示。也提供了 Endpoint 实时查看线程池指标数据。
同时定义了5中告警规则。
- 线程池活跃度告警。活跃度 = activeCount / maximumPoolSize,当活跃度达到配置的阈值时,会进行事前告警。
- 队列容量告警。容量使用率 = queueSize / queueCapacity,当队列容量达到配置的阈值时,会进行事前告警。
- 拒绝策略告警。当触发拒绝策略时,会进行告警。
- 任务执行超时告警。重写 ThreadPoolExecutor 的 afterExecute() 和 beforeExecute(),根据当前时间和开始时间的差值算出任务执行时长,超过配置的阈值会触发告警。
- 任务排队超时告警。重写 ThreadPoolExecutor 的 beforeExecute(),记录提交任务时时间,根据当前时间和提交时间的差值算出任务排队时长,超过配置的阈值会触发告警
通过监控+告警可以让我们及时感知到我们业务线程池的执行负载情况,第一时间做出调整,防止事故的发生。

8. 面试官:你在使用线程池的过程中遇到过哪些坑或者需要注意的地方?
这个问题其实也是在考察你对一些细节的掌握程度,就全甩锅给年轻刚毕业没经验的自己就行。可以适当多说些,也证明自己对线程池有着丰富的使用经验。
1)OOM 问题。刚开始使用线程都是通过 Executors 创建的,前面说了,这种方式创建的线程池会有发生 OOM 的风险。
2)任务执行异常丢失问题。可以通过下述4种方式解决
- 在任务代码中增加 try、catch 异常处理
- 如果使用的 Future 方式,则可通过 Future 对象的 get 方法接收抛出的异常
- 为工作线程设置 setUncaughtExceptionHandler,在 uncaughtException 方法中处理异常
- 可以重写 afterExecute(Runnable r, Throwable t) 方法,拿到异常 t
3)共享线程池问题。整个服务共享一个全局线程池,导致任务相互影响,耗时长的任务占满资源,短耗时任务得不到执行。同时父子线程间会导致死锁的发生,今儿导致 OOM
4)跟 ThreadLocal 配合使用,导致脏数据问题。我们知道 Tomcat 利用线程池来处理收到的请求,会复用线程,如果我们代码中用到了 ThreadLocal,在请求处理完后没有去 remove,那每个请求就有可能获取到之前请求遗留的脏值。
5)ThreadLocal 在线程池场景下会失效,可以考虑用阿里开源的 Ttl 来解决
以上提到的线程池动态调参、通知告警在开源动态线程池项目 DynamicTp 中已经实现了,可以直接引入到自己项目中使用。
关于 DynamicTp
DynamicTp 是一个基于配置中心实现的轻量级动态线程池管理工具,主要功能可以总结为动态调参、通知报警、运行监控、三方包线程池管理等几大类。

经过多个版本迭代,目前最新版本 v1.0.8 具有以下特性
特性 ✅
- 代码零侵入:所有配置都放在配置中心,对业务代码零侵入
- 轻量简单:基于 springboot 实现,引入 starter,接入只需简单4步就可完成,顺利3分钟搞定
- 高可扩展:框架核心功能都提供 SPI 接口供用户自定义个性化实现(配置中心、配置文件解析、通知告警、监控数据采集、任务包装等等)
- 线上大规模应用:参考美团线程池实践,美团内部已经有该理论成熟的应用经验
- 多平台通知报警:提供多种报警维度(配置变更通知、活性报警、容量阈值报警、拒绝触发报警、任务执行或等待超时报警),已支持企业微信、钉钉、飞书报警,同时提供 SPI 接口可自定义扩展实现
- 监控:定时采集线程池指标数据,支持通过 MicroMeter、JsonLog 日志输出、Endpoint 三种方式,可通过 SPI 接口自定义扩展实现
- 任务增强:提供任务包装功能,实现TaskWrapper接口即可,如 MdcTaskWrapper、TtlTaskWrapper、SwTraceTaskWrapper,可以支持线程池上下文信息传递
- 兼容性:JUC 普通线程池和 Spring 中的 ThreadPoolTaskExecutor 也可以被框架监控,@Bean 定义时加 @DynamicTp 注解即可
- 可靠性:框架提供的线程池实现 Spring 生命周期方法,可以在 Spring 容器关闭前尽可能多的处理队列中的任务
- 多模式:参考Tomcat线程池提供了 IO 密集型场景使用的 EagerDtpExecutor 线程池
- 支持多配置中心:基于主流配置中心实现线程池参数动态调整,实时生效,已支持 Nacos、Apollo、Zookeeper、Consul、Etcd,同时也提供 SPI 接口可自定义扩展实现
- 中间件线程池管理:集成管理常用第三方组件的线程池,已集成Tomcat、Jetty、Undertow、Dubbo、RocketMq、Hystrix等组件的线程池管理(调参、监控报警)