java面试题
这里写目录标题
-
-
- 1、string、StringBuffer 和StringBuilder的区别
- 2、接口和抽象类的区别?
- 3、java的形参和实参?
- 4、java值传递和引用传递的区别?
- 5、io流分类?
- 6、公司代码开发规范是什么?
- 7、为什么要重写equals()方法?
- 8、为什么重写equal必须要重写hashcode?
- 9、final、finally、finalize的区别
- 10、在什么情况下需要考虑线程安全问题
- 11、如何解决线程安全问题
- 12、线程的实现方式
- 13、什么是线程池?
- 14、创建线程池的优势、为什么要使用线程池?
- 15、线程池有哪些?
- 16、线程池满载了怎么处理?
- 17、线程和进程有什么区别?
- 18、线程生命周期
- 19、启动一个线程用start()还是run()
- 20、什么是死锁
- 21、死锁的原因?
- 22、线程死锁的条件?
- 23、如何避免死锁?
- 24、java常见的容器,与其继承关系。
- 25、vector、ArrayList、LinkedList
- 26、ThreadLocal
- 27、线程安全的容器?
- 28、hashMap和hashTable的区别?
- 29、hashMap如何实现同步?
- 30、Collection和Collections的区别?
- 31、Spring创建的对象是什么模式的
- 32、Spring容器创建对象的方式
- 33、mybatis和hibernate的区别
- 34、什么是微服务
- 35、springboot配置
- 36、同时存在yml和properties文件
- 37、springboot配置文件加载顺序
- 38、对springboot的框架的理解
- 39、StringMVC的流程
- 40、解析器和拦截器?
- 41、StringMVC的优点
- 42、说说什么是IOC和AOP
- 43、Linux基本操作命令
- 44、Linux上怎么打war包
- 45、Linux上打tar包
- 46、Linux上打rar包
- 47、定时任务
- 48、jdbc PreparedStatement的优点
- 49、jdbc Statement特点
- 50、数据库优化
- 51、数据库左连接、右连接、内连接、全连接
- 52、对一个数据量很大的表格进行查询
- 53、数据库索引
- 54、mysql的select语句执行过程?
- 55、mysql的select语句执行顺序?
- 56、mysql的having语句?
- 57、having和where的区别?
- 58、mybatis的wehere标签作用是什么?
- 59、mysql数据库表格什么情况下用到索引?
- 60、物理分页和逻辑分页。
- 61、pagehelper是逻辑分页还是物理分页?
- 62、mysql事务。
- 63、项目中用到了哪些事务?
- 64、redis是什么?
- 65、redis为什么这么快?
- 66、redis的几种类型
- 67、redis持久化的方法?
- 68、redis是如何同步数据库中的数据的?
- 69、缓存穿透、缓存雪崩、缓存击穿?
- 70、Redis里面如果有1亿条数据,如何取出其中指定的1000条数据?
- 71、es倒排索引
- 72、jQuery选择器
- 73、jQuery添加样式
- 74、前端定时器
- 75、请求转发forward,请求重定向redirect
- 76、request生命周期
- 77、session的生命周期
- 78、页面间对象传递的方法
- 79、wsdl文件(网络服务描述语言)
- 80、Tomcat的目录及作用?
-
1、string、StringBuffer 和StringBuilder的区别
首先都存储字符串的类,String是不可变的字符串,而stringbuffer,stringbuilder操作的字符串内容可变。
不同的是Stringbuffer是线程安全的,而Stringbuilder是线程不安全的。
但是StringBuilder的效率相较于Stringbuffer要更高一些(因为没有加锁),所以在不考虑线程安全的情况下,建议是使用Stringbuilder。
https://www.zhihu.com/question/20101840
2、接口和抽象类的区别?
接口其实就是在抽象类基础上添加了更加苛刻的条件。
1、抽象类中可以有普通方法,但是接口中只能有抽象方法
2、抽象类中可以有常量,可以有变量,但是接口中只能有静态常量
3、抽象类中有构造方法,接口中没有构造方法
4、接口可以多继承,但是类的继承只能是单继承
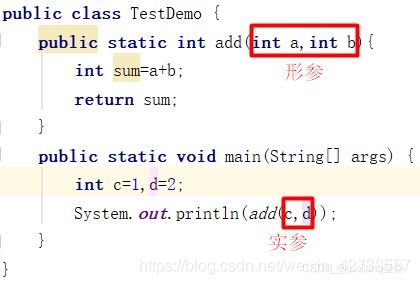
3、java的形参和实参?
形参:就是形式参数,用于定义方法的时候使用的参数,是用来接收调用者传递的参数的。只有在方法被调用的时候,虚拟机才会分配内存单元,在方法调用结束之后便会释放所分配的内存单元。形参只在方法内部有效,所以针对引用对象的改动也无法影响到方法外。
实参 :就是实际参数,用于调用时传递给方法的参数。实参在传递给别的方法之前是要被预先赋值的。
4、java值传递和引用传递的区别?
5、io流分类?
字符流和字节流。
字节流:可以处理文本、图片、音视频等。
InputStream:字节输入流父类
OutputStream:字节输出流父类
字符流:只可以处理文本
Writer
Reader
6、公司代码开发规范是什么?
命名规范:包名用公司名称缩写,类名首字母大写,方法名用驼峰命名法,参数名要见名知意,逗号、分号只在后面加空格,运算符号要在前后加空格等。
数据库命名时使用下划线
7、为什么要重写equals()方法?
因为object中的equals()方法比较的是对象的引用地址是否相等,如何你需要判断对象里的内容是否相等,则需要重写equals()方法。
8、为什么重写equal必须要重写hashcode?
equals相等的对象hashcode一定相等。如果重写了equals而没有重写hashcode,会出现一种情况,两个对象equals重写了之后判断是相等的,但是hashcode值不等,这就违背了java定义里的规则。
在一种情况下可以不考虑重写hashcode,即在对象不涉及到HashMap、HashSet和Hashtable集合时,因为这些集合是不可重复集,在添加数据时,会先根据hashcode值判断是否相等,如果相等再调用equals对比,所以如果hashcode值不相等,那程序就默认两个对象不相等,即便我们重写了equals方法,也无法判定为相同的对象。
9、final、finally、finalize的区别
final 用于声明属性,方法和类的修饰符,分别表示属性不可变,方法不可覆盖,类不可继承。内部类要访问局部变量,局部变量必须定义成 final 类型。
finally 是异常处理语句结构的一部分,表示无论是否出现异常总是执行。
finalize 是 Object 类的一个方法,在垃圾收集器执行的时候会调用被回收对象的此方法,可以覆盖此方法提供垃圾收集时的其他资源回收,例如关闭文件等。JVM 不保证此方法总被调用。
10、在什么情况下需要考虑线程安全问题
多线程的时候。
多线程处理业务逻辑的时候,有可能因为共享了参数、对象等,由于运行是的先后顺序之类的问题,导致类似于数据不一致、数据污染这样的问题。
11、如何解决线程安全问题
加锁synchronized,同步方法、同步代码块,这样一个线程在进入锁的时候,其他的线程只能等待,等这个线程执行完之后,其他线程才能进入。但是也有一个弊端,加了锁的方法或代码块,性能会比不用时要低一些,所以一般考虑的就是尽量减少锁的作用域。
12、线程的实现方式
实现Runnable接口,继承Thread类,创建线程池
13、什么是线程池?
顾名思义,就是实现创建若干个可执行的线程放在一个池子中,需要的时候从池子中获取线程,不用自己重新创建,使用完之后,不需要销毁线程而是重新放入池子中。
14、创建线程池的优势、为什么要使用线程池?
减少资源的消耗,不用重复的创建和销毁线程;
提高效率,有任务来了可以直接执行,不需要再重新创建再执行;
提高可管理型,可以进行统一分配调优监控。
在我们平时java的编程中,创建和销毁对象很消耗资源,因为每次创建一个对象之后,虚拟机就需要对其进行跟踪,在对象销毁之后进行回收,所以应该尽量减少创建和销毁对象的次数,特别是一些很耗资源的对象的创建和销毁,这就是“池化资源”产生的原因。
15、线程池有哪些?
newSingleThreadExecutor:单线程的线程池。线程池中只有一个线程,执行任务是按照单线程串行执行的方式,保证了任务是按照顺序来执行的,如果这个唯一的线程因为异常结束了,那么会有一个新的线程来替代它。
newFiexedThreadPool:指定大小的线程池。每次提交一个任务就会创建一个线程出来执行任务,一直到能够达到线程池的最大数量(即我们指定的数量),如果线程数量达到线程池初始的最大数,则将提交的任务存入到池队列中。
newCachedThreadPool:可缓存的线程池。如果线程池的大小大于需要处理的任务数,此时就会对部分空闲线程池进行部分回收(60s内未执行任务);当任务量增加时,线程池又会新建线程来处理任务。 此线程池不会对线程池的大小做限制,线程池的大小完全依赖于系统(或jvm)能够创建的最大线程数量。
newScheduleThreadPool:大小无限的线程池。此线程池支持定时以及周期性执行任务的需求。
16、线程池满载了怎么处理?
如果内存够用,就是线程池满了,就在创建线程池时增大池的容量上限;
如果内存不够,就加物理内存;
如果物理内存还是不够,考虑分布式系统,用云计算那一套东西。
17、线程和进程有什么区别?
线程是多个进程的集合。
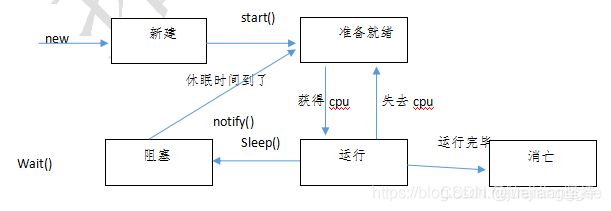
18、线程生命周期
1.新建: 线程被new出来
2.就绪:线程具有执行的资格,即线程调用了start(),没有执行的权利
3.运行:具备执行的资格和具备执行的权利
4.阻塞:没有执行的资格和执行权利
5.销毁: 线程的对象变成垃圾,释放资源。
19、启动一个线程用start()还是run()
启动一个线程用start(),run()是要运行线程中的代码
20、什么是死锁
多个线程,因为竞争资源,最终陷入的一种僵局。
两个进程都在等待对方执行完毕,才能继续往下执行的时候就发生了死锁。结果就是两个进程都陷入了无限的等待中。
例子:给一个类加锁,创建了两个对象之后,两个对象都是带锁的,此时线程1正在执行对象1,线程2正在执行对象2,所以线程1持有对象1的锁,线程2持有对象2的锁,然后双方都在等待对方释放锁,就陷入了死锁。
21、死锁的原因?
系统资源的竞争;进程推进顺序非法;互斥;请求与保持;不可剥夺;循环等待。
22、线程死锁的条件?
1、 互斥:一个资源每次只能被一个线程使用
2、 请求与保持:一个进程因为请求资源而阻塞,对已获得的资源保持不放
3、 不可剥夺:进程已经获取的资源,在未使用完之前,不可强行剥夺
4、 循环等待:两个进程之间形成的循环等待对方释放资源
23、如何避免死锁?
加锁,1、顺序加锁:线程按照一定的顺序依次加锁
2、加锁限时:线程在每次获取资源的时候加上时间限制,超出时间限制,放弃自己占用的资源。。。
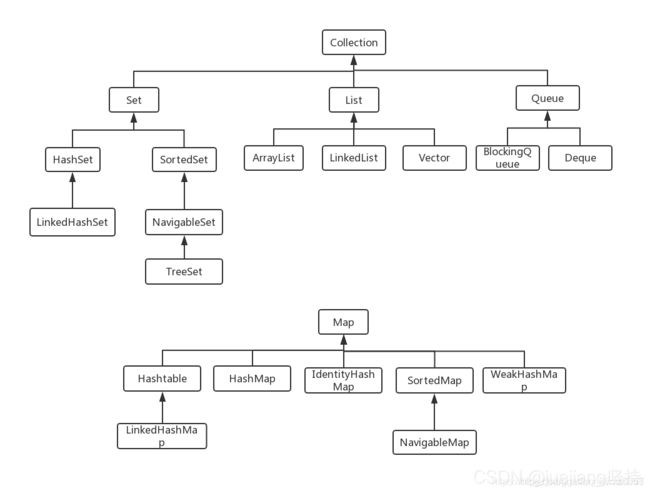
24、java常见的容器,与其继承关系。
java容器类类库的用途是"保存对象"。
Java集合类是一种特别有用的工具类,可以用于存储数量不等的对象,并可以实现常用的数据结构,如栈,队列等.
Java集合就像一种容器,可以把多个对象(实际上是对象的引用,但习惯上都称对象) “丢进” 该容器中
java中的容器也叫集合,是专门用来管理对象的对象
25、vector、ArrayList、LinkedList
26、ThreadLocal
ThreadLocal
用在多线程处理业务时。
27、线程安全的容器?
hashTable。
28、hashMap和hashTable的区别?
1) 继承不同
Hashtable是基于陈旧的Dictionary类的,HashMap是Java 1.2引进的Map接口的一个实现。
2) 线程安全不同。
hashTable是线程安全的,因为底层的方法做了线程同步,给get、put、remove方法方法加了同步锁,所有每次只能有一个线程来操作hashtable,效率比较低。
hashMap中的方法默认都是非同步的,所以是线程不安全的。
3) null值。
hashtable中的键值都不允许为null,否则会抛出空指针异常
hsahmap里的键值都允许为null,key只允许存在一个为null的数据,但是value允许存在多个null值,调用get(key)方法来获取到的结果为null时,既可以表示key不存在,也可以表示key对应的value值为null。 所以在hashMap里,判断某个key是否存在,不能用get()方法,而是应给用containsKey()方法来判断
4) 哈希值的使用不同
HashTable直接使用对象的hashCode。而HashMap重新计算hash值。
5) 遍历方式的内部实现上不同
Hashtable、HashMap都使用了 Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。
29、hashMap如何实现同步?
30、Collection和Collections的区别?
Collection 是一个集合接口(集合类的一个顶级接口);
Collections则是集合类的一个工具类/帮助类,其中提供了一系列静态方法,用于对集合中元素进行排序、搜索以及线程安全等各种操作。
1)排序Collections.sort(list)
2)最大最小值Collections.max(list),Collections.min(list)等。
31、Spring创建的对象是什么模式的
单例模式或者多例模式。
singleton(单例):只有一个共享的实例存在,所有对这个bean的请求都会返回这个唯一的实例。
prototype(多例):对这个bean的每次请求都会创建一个新的bean实例,类似于new。
spring默认创建的bean对象是单例的,但是可以修改为多例模式,在我们使用的时候,大多时候的都还是多例模式。
将xml配置文件中的关键字修改一下
<bean id="hi" class="com.test.Hi" init-method="init" scope="singleton">
<bean id="hi" class="com.test.Hi" init-method="init" scope="prototype">
32、Spring容器创建对象的方式
无参构造器创建对象
有参构造器创建对象 - 需要在xml文件中配置一下
工厂类创建对象
<bean id="personFactory" class="com.mc.base.learn.spring.factory.PersonFactory">bean>
<bean id="person2" factory-bean="personFactory" factory-method="createInstance">bean>
33、mybatis和hibernate的区别
1)hibernate的sql语句都已经封装起来了可以直接拿来使用,是开发更方便,mybatis的sql语句需要自己手动去写;
2)但是因为mybatis是手写的sql语句,所以可以自己调整、控制查询的语句,能够避免一些不必要的查询,提高效率;
3)但是mybatis要自己去做映射文件等,比较繁琐;hibernate是一个更完整的框架,开发过程中,不需要做这些管理。
34、什么是微服务
一个应用可以拆分成多个核心功能。每个功能都被称为一项服务,可以单独构建和部署,这意味着各项服务在工作(和出现故障)时不会相互影响。
比如网购时,商品列表和购物车之间,是互相不联系,都可以实现购物需求,相对独立的功能。
35、springboot配置
application.yml文件、application.properties文件。
区别:yml文件就是用:链接参数内容,properties文件是直接用等号;properties的参数是全部写完整,yml文件里同一级别下的配置,只需要用空格回退对齐就行。
主要的配置就是:
端口号server.port,
不同环境配置文件选择profiles.active,
配置中心config
数据库连接池datasource(url,username,password),
消息队列参数配置RabbitMQ(host,port,username,password)等等
36、同时存在yml和properties文件
spring boot项目中同时存在application.properties和application.yml文件时,两个文件都有效,但是properties文件的优先级会比yml文件高;各自私有的内容会互补。
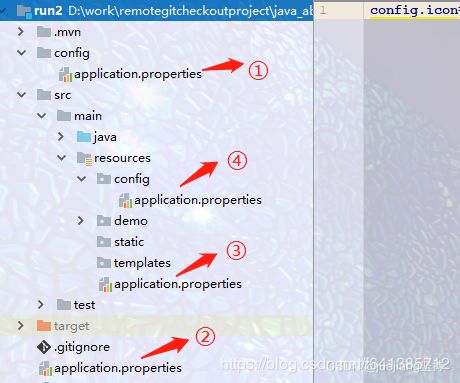
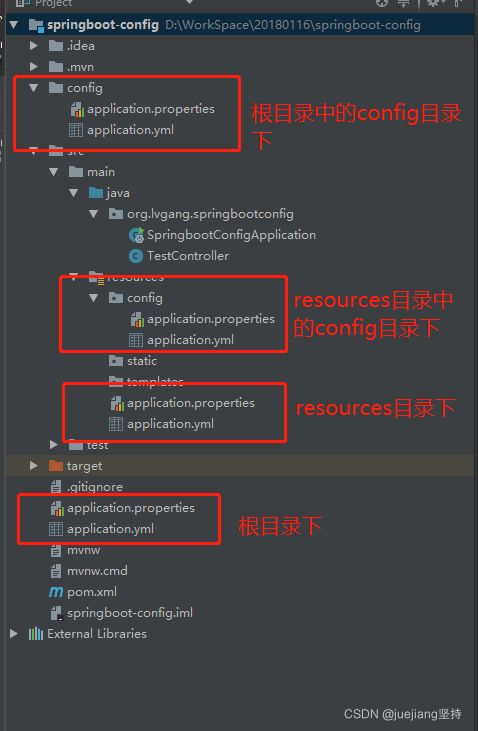
37、springboot配置文件加载顺序
工程根目录:./config/
工程根目录:./
classpath:/config/
classpath:/
加载的优先级顺序是从上向下加载,并且所有的文件都会被加载,高优先级的内容会覆盖底优先级的内容,形成互补配置。
38、对springboot的框架的理解
SpringBoot是一个微服务框架,可以很快速的构建起来这个框架;
他不用像ssm之类的其他框架一样需要去处理很多的配置文件,springboot是自动化配置,主要是依靠注解来实现,使配置简单化;
Springboot内嵌有tomcat和Maven,不需要我们单独的在去外部配置,使部署和启动都变得简单。
39、StringMVC的流程
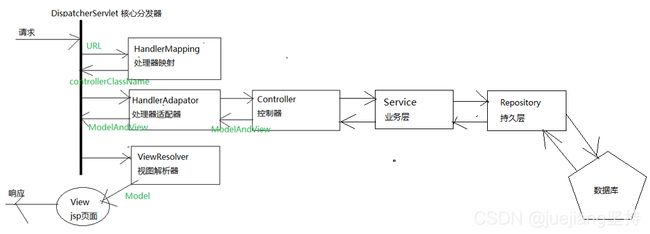
客服端发送来一个请求,先经过映射文件,目的就是解析URL,根据我们方法的注解找到具体的controller层的方法,从controller方法再进入到具体的Service业务层去处理业务逻辑,包括持久层数据库层面,然后再一步步的return,将数据传输给视图解析去,最后再响应到客户端。
40、解析器和拦截器?
解析器:
拦截器:
41、StringMVC的优点
降低耦合,将各个层次分开来处理,清晰明了每个层面的任务。
42、说说什么是IOC和AOP
IOC即控制反转(Inversionof Control)是Spring的核心,即将创建当前类实例的工作的控制权交给第三来完成并交给spring容器进行管理。新建一个类,并在pring的xml配置文件中配置,之后使用该类就不用再new对象。就是将对象实例的控制权交给spring来管理。
AOP即面向切面编程,可用于抽象具有非业务,以及通用这两大特点的代码统一应用于业务代码,比如实现统一的日志管理。
在项目中用aop做过日志记录的功能,①首先定义一个aop切面类;②配置自定义注解;③配置切入点URL;④写切入之后业务逻辑,配合自定义注解和反射,实现日志记录;
43、Linux基本操作命令
ls,ll,cd,pwd,cat,vim查看命令
mkdir:新建目录,mkdir -p:新建多级目录,rmdir:删除目录,rm -f删除文件,rm -rf dir:删除一个目录及其所有内容
mv dir new_dir:移动/重命名一个目录
cp file1 file2:复制一个文件,
find:查询文件等等
44、Linux上怎么打war包
1)需要有java环境
2)进入到需要打包的目录
3)使用jar -cvf 需要打包的目录名.war ./*
打成war包的好处是不会缺少目录。
45、Linux上打tar包
压缩:tar -zcvf 目标文件(.tar/.tar.gz) 源文件或目录
解压:tar -zxvf 目标文件 解压目录
46、Linux上打rar包
压缩:rar a FileName.rar 源文件或目录
解压:rar x etc.rar 解压目录
47、定时任务
1、 用注解,corn表达式
2、
48、jdbc PreparedStatement的优点
批量处理sql语句;
带参和不带参的sql语句都能执行;
预编译处理,防止sql注入,安全性比较高。
49、jdbc Statement特点
只执行不带参的sql语句;
只执行单条的sql语句,执行效率比preparedstatement要高
50、数据库优化
合理设计表格;
优化我们的sql语句(尽量减少子查询,因为子查询需要在内存中建立临时表,消耗资源;可以使用中间表,使用jion查询);
建立有效的索引(主键,唯一,组合索引等)选择在where,group by,order by,on从句中出现的列作为索引项;
再有就是在高并发的时候用到的,主从服务器读写分离。
主从同步:就是一个集群里,一个主库,若干从库,主库负责增删改,从库负责读,因为高并发的时候大多数都是在读取数据,此时集群需要确保的就是每个数据库服务器的数据是一致的。
51、数据库左连接、右连接、内连接、全连接
左连接:left jion
左连接是左边表的所有数据都有显示出来,右边的表数据只显示共同有的那部分,没有对应的部分只能补空显示,所以影响到的是右边的表
右连接:rigth jion
右连接是右边表的所有数据都有显示出来,左边的表数据只显示共同有的那部分,没有对应的部分只能补空显示,所以影响到的是左边的表
内连接:inner jion
内连接是一种一一映射关系,就是两张表都有的才能显示出来
全连接(全连接):outer jion
查询出左表和右表所有数据,但是去除两表的重复数据

52、对一个数据量很大的表格进行查询
使用索引查询;
需要查询几列select关键字后边就直接写出来,不用*;
where后边跟的查询条件,他的前后顺序也会对查询效率有一定影响;
应该避免在where子语句后边使用一些!=、<>,null。
如果是在程序里面的话,可以使用jdbc来链接数据库,效率更高一些。
53、数据库索引
我接触过的就是建表的时候会建立一些表格的索引:主键、唯一、组合索引等等,利用索引在做查询的时候,效率会提高很多;但是索引是存在磁盘上的,所以并不是建立的越多越好,一般一个表里建议最多不要超过6个索引。
54、mysql的select语句执行过程?
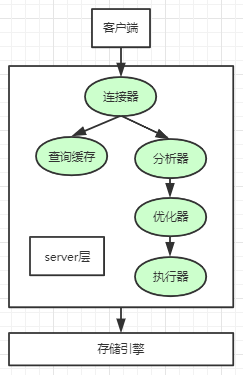
55、mysql的select语句执行顺序?
基础语法: select 字段列表 from 数据源;
完整语法: select 去重选项 字段列表 [as 字段别名] from 数据源 [where子句] [group by 子句] [having子句] [order by 子句] [limit子句];
执行顺序:
FROM: FROM table负责把数据库的表文件加载到内存中去
WHERE: 把表中的数据进行过滤,取出符合条件的记录行,生成一张临时表
GROUP BY: 按照指定的列名切分成若干临时表
HAVING: 根据HAVING子句中出现的谓词对虚拟表进行分组进行筛选
SELECT: 投影的过程,处理SELECT子句提到的元素
ORDER BY: 根据ORDER BY子句中指定的字段进行排序
LIMIT: 取出指定行的记录,产生临时表,并返回给查询用户
56、mysql的having语句?
having语句作用于分组和聚合之后的条件筛选。
57、having和where的区别?
having和where都有条件筛选的作用。
where作用在分组和聚合之前;having需要结合group by使用,作用在分组和聚合之后。
WHERE 子句不能包含聚集函数;having函数基本上都包含聚合函数,因为如果是不使用聚合的函数的having子句,没有意义,这种情况完全可以用where来实现。
58、mybatis的wehere标签作用是什么?
where元素只会在至少有一个子元素的条件返回 SQL 子句的情况下才去插入“WHERE”子句。而且,若语句的开头为“AND”或“OR”,where 元素也会将它们去除。
1)where标签里,至少有一个条件可以返回sql子句时,才会插入where子句;
2)如果where标签里,返回的语句开头是and或or,where标签可以将其去除。
也可以使用trim标签:
<trim prefix="WHERE" prefixOverrides="AND |OR ">
...
trim>
prefix:前缀,prefixoverride:去掉第一个“and”或者是“or”
suffixoverride:去掉最后标记的字符(就像是上面的and一样),suffix:后缀
59、mysql数据库表格什么情况下用到索引?
mysql的索引包括:主键索引、唯一索引、组合索引。
60、物理分页和逻辑分页。
物理分页:利用mysql的limit关键字分页。
逻辑分页:一次查询到所有数据,利用程序代码进行分页。
61、pagehelper是逻辑分页还是物理分页?
物理分页,因为pagehelper本质用到的还是数据库的limit关键字。
先在maven里引入pagehelper包
<dependency>
<groupId>com.github.pagehelpergroupId>
<artifactId>pagehelperartifactId>
<version>4.1.6version>
dependency>
PageHelper.startPage(productInfoBo.getCurPage(), productInfoBo.getPageSize());
PageBo

62、mysql事务。
ACID指事务的四大特性,原子性,一致性,隔离性,持久性。
原子性:要么同时成功,要么同时失败
一致性:所有库的操作需要一起处理
隔离性:单位时间内,对一个数据的操作,只能有一个
持久性:结束后写入数据库存储
63、项目中用到了哪些事务?
新增、修改、删除时,加事务的注解。
64、redis是什么?
redis是一种运行速度很快、流行使用的nosql数据库。可以作为缓存数据库,当然也可以对数据做做持久化,这样就不用担心关机数据丢失的问题了。
redis存储的数据是一种半结构化数据,不会像mysql一样,需要建表,规定字段和大小,如果数据大小超出了指定的量存储就会报错,redis不会。
65、redis为什么这么快?
首先,采用了多路复用io阻塞机制
然后,数据结构简单,操作节省时间
最后,运行在内存中,自然速度快
66、redis的几种类型
String、Hash、List、Set、ZSet
(字符串、哈希、列表、集合、有序集合)
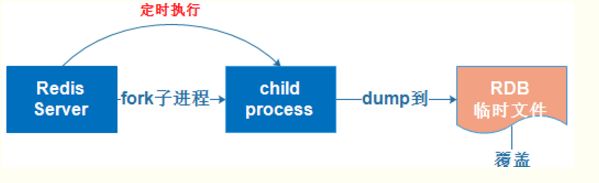
67、redis持久化的方法?
快照方式RDB:将某一个时刻的内存数据,以二进制的方式写入磁盘;
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。
文件追加方式AOF:记录所有的操作命令,并以文本的形式追加到文件中;
AOF持久化以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。

68、redis是如何同步数据库中的数据的?
1、更新数据库后,删除redis对应的数据,让下次请求的时候来写入redis
2、更新数据库后,异步更新redis
69、缓存穿透、缓存雪崩、缓存击穿?
缓存穿透: 就是客户持续向服务器发起对不存在服务器中数据的请求。客户先在Redis中查询,查询不到后去数据库中查询。
缓存击穿: 就是一个很热门的数据,突然失效,大量请求到服务器数据库中
缓存雪崩: 就是大量数据同一时间失效。
打个比方,你是个很有钱的人,开满了百度云,腾讯视频各种杂七杂八的会员,但是你就是没有netflix的会员,然后你把这些账号和密码发布到一个你自己做的网站上,然后你有一个朋友每过十秒钟就查询你的网站,发现你的网站没有Netflix的会员后打电话向你要。你就相当于是个数据库,网站就是Redis。这就是缓存穿透。
大家都喜欢看腾讯视频上的《水果传》,但是你的会员突然到期了,大家在你的网站上看不到腾讯视频的账号,纷纷打电话向你询问,这就是缓存击穿
你的各种会员突然同一时间都失效了,那这就是缓存雪崩了。
解决办法:
缓存穿透:
1.接口层增加校验,对传参进行个校验,比如说我们的id是从1开始的,那么id<=0的直接拦截;
2.缓存中取不到的数据,在数据库中也没有取到,这时可以将key-value对写为key-null,这样可以防止攻击用户反复用同一个id暴力攻击
注:会浪费内存,所以给这个数据,设置上过期时间(1min、5min…)。
缓存击穿:
最好的办法就是设置热点数据永不过期,拿到刚才的比方里,那就是你买腾讯一个永久会员
缓存雪崩:
1.缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
2.如果缓存数据库是分布式部署,将热点数据均匀分布在不同服务器的缓存数据库中。
70、Redis里面如果有1亿条数据,如何取出其中指定的1000条数据?
这1000条数据如果是存在一些相似性,可以用keys来查询:KEYS hello*
如果没有任何的相关性,只能遍历查询get key
71、es倒排索引
在es接收到文档存储时,会自动对文档内容进行分词,所以就有了文档、文档id、单词、单词id。
正排索引的指向是从文档id->单词id;
倒排索引的指向是从单词id->文档id。【B+树】
当我们进行关键字检索时,正排索引会将所有的文档遍历一遍去匹配有没有关键字,而倒排索引能根据关键字直接找到相关的文档,所以倒排索引会更快速。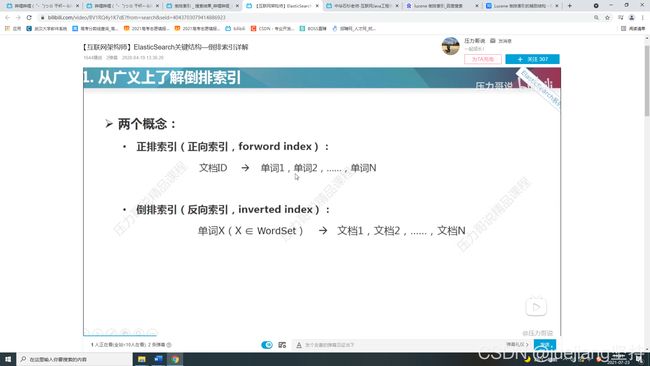
72、jQuery选择器
id:#,class:.;标签:标签名
73、jQuery添加样式
1)最简单的就是在标签里,直接用style属性来控制;
2)根据选择器定位到页面上想要调整的部分,直接设置css样式。
74、前端定时器
不太了解,我只记得项目中用到过一个setTimeout()关键字,举例一个button在点击的时候需要延迟3秒,就在按钮标签里定义一个方法,在js代码里,实现方法的时候,为setTimeout设置一个时间参数。
75、请求转发forward,请求重定向redirect
forward是,服务端的行为;redirect是,客服端的行为。
forward是只发送一次请求,转发后请求对象会保存,地址栏的URL地址不会改变。是服务器内部转发,客户端看不到地址栏的改变,他也不关心是如何转发的。
redirect浏览器发出了2次请求,得到了2次响应,地址栏地址会变。服务端根据第一次请求逻辑,发送一个状态码,告诉浏览器重新去请求那个地址,一般来说浏览器会用刚才请求的所有参数重新请求,他可以重新定向访问其他Web应用下的资源。
76、request生命周期
request生命周期简单来做就是request请求域,一个请求结束,则request结束。
创建:一个请求访问开始
结束:
1)转发:在得到页面响应的结果之后,会继续传递下去。就是例如一个请求转发到一个新的jsp页面之后,他依旧可以拿到上一个jsp页面中的request里的参数,因为这是同一个request。
2)重定向:在得到响应结果就结束了。我的理解是,重定向有2次请求,第一次请求的时候已经把参数返回给客户端了,客户端拿着这些参数重新发送了一个请求,这之后,页面才算真正的响应出来。为什么设计的这么麻烦,可能就是为了让request结束掉,这样在之后的请求中就不用一直带着这些request参数一直留在客户端,因为占用网络是肯定的。
77、session的生命周期
简单来说就是,从打开浏览器到关闭浏览器。
Session创建:在你打开一个浏览器开始访问的时候,就创建了。
Session关闭:他在你关闭浏览器的时候或者默认时间(Tomcat是30分钟)后会销毁。
78、页面间对象传递的方法
request,session,application,cookie 等
79、wsdl文件(网络服务描述语言)
是一门基于 XML的语言,用于描述 Web 服务以及如何对它们进行访问。
80、Tomcat的目录及作用?
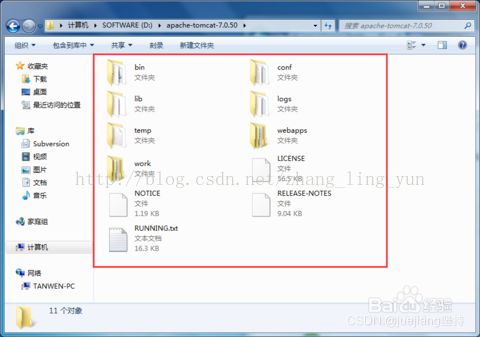
① 主目录下有bin,conf,lib,logs,temp,webapps,work 7个文件夹
② bin目录主要是用来存放tomcat的命令,启动、结束文件;环境变量的设置也是选在bin目录;
③ conf目录主要是用来存放tomcat的一些配置文件:server.xml设置端口号、域名或IP等;web.xml可以设置tomcat支持的文件类型;context.xml可以用来配置数据源之类的;
④ lib目录主要用来存放tomcat运行需要加载的jar包;
⑤ logs目录用来存放tomcat在运行过程中产生的日志文件,非常重要的是在控制台输出的日志。(清空不会对tomcat运行带来影响)。在windows环境中,控制台的输出日志在catalina.xxxx-xx-xx.log文件中;在linux环境中,控制台的输出日志在catalina.out文件中
⑥ temp目录用户存放tomcat在运行过程中产生的临时文件。
⑦ webapps目录用来存放应用程序,当tomcat启动时会去加载webapps目录下的应用程序。可以以文件夹、war包、jar包的形式发布应用。当然,你也可以把应用程序放置在磁盘的任意位置,在配置文件中映射好就行;
⑧ work目录用来存放tomcat在运行时的编译后文件,例如JSP编译后的文件。清空work目录,然后重启tomcat,可以达到清除缓存的作用。