hash,bloomfilter,分布式一致性hash
场景
-
使用word 文档时,判断某个单词是否拼写正确
-
垃圾邮件过滤算法
-
Redis缓存穿透
-
bitcoin core中交易校验
需求
从海量数据中查询某个字符串是否存在?
平衡二叉搜索树
增删改查时间复杂度是O( l o g 2 n log_2n log2n)。
平衡的目的是保证操作的时间复杂度稳定,保证下次搜索能够稳定排除一半的数据。
O( l o g 2 n log_2n log2n)的直观理解:100万个节点,最多比较20次;10亿个节点,最多比较30次。
总结:通过比较保证有序,使用二分查找,通过每次排除一般的元素达到快速索引的目的。

散列表(HashMap)
根据key计算key在hash map数组中的位置的数据结构。
hash函数
映射函数 Hash(key)=addr;hash 函数可能会把两个或两个以上的不同 key 映射到同一地址,这种情况称之为冲突(或者 hash 碰撞);
hash 函数实现过程当中 为什么 会出现 i*31?
- i * 31 = i * (32-1) = i * (1<<5 -1) = i << 5 - i;可以将乘法转换为位运算,速度快。
- 31是质数,hash 随机分布性是最好的。
选择hash函数
-
计算速度快
-
强随机分布(等概率、均匀地分布在整个地址空间)
-
murmurhash1,murmurhash2,murmurhash3,siphash(redis6.0当中使⽤,rust等大多数语言选用的hash算法来实现hashmap),cityhash 都具备强随机分布性;测试地址如下:https://github.com/aappleby/smhasher
-
siphash 主要解决字符串接近的强随机分布性
负载因子
负载因子 = 数组存储元素的个数 / 数据长度
用来形容散列表的存储密度;负载因子越小,冲突越小,负载因子越大,冲突越大;
冲突处理
- 链表法
引用链表来处理哈希冲突;也就是将冲突元素用链表链接起来;这也是常用的处理冲突的⽅式;但是可能出现一种极端情况,冲突元素比较多,该冲突链表过长,这个时候可以将这个链表转换为红黑树;由原来链表时间复杂度O(n) 转换为红黑树时间复杂度O( l o g 2 n log_2n log2n);那么判断该链表过长的依据是多少?可以采⽤超过 256(经验值)个节点的时候将链表结构转换为红黑树结构;
- 开放寻址法
将所有的元素都存放在哈希表的数组中,不使用额外的数据结构;一般使用线性探查的思路解决。
布隆过滤器
是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,能确定某个字符串一定不存在或者可能存在。
布隆过滤器不存储具体数据,所以占用空间小,查询结果存在误差,但是误差可控,同时不支持删除操作。
为什么不用HashMap
key映射到HashMap 的数组,然后可以在 O(1) 的时间复杂度内返回结果,效率也非常高。

HashMap的问题:size增加,内存占用比较大
测试结果:
unordered_map
main_key=“https://www.alibaba.com/”
sub_key=to_string(i);
Key = main_key+sub_key;

二叉树也跟hashmap类似,而且还需要比较字符串,不适用于海量数据中字符串的查找。
而bloomfilter,不比较字符串,不存储具体的元素,可以查询海量数据。
Bloomfilter构成
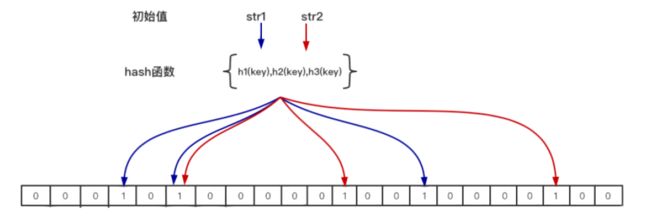
布隆过滤器是一个bit 数组(bitmap) + n个hash函数
m % 2n = m & (2n - 1)

原理
布隆过滤器的原理是,当一个元素被加入bitmap时,通过K 个 Hash 函数将这个元素映射成bitmap中的 K 个点,把它们置为 1;检索时,再通过 k 个 hash 函数运算检测bitmap的 k 个点是否都为1; 如果这些点有任何一个不为1,则该key一定不存在; 如果全部为 1 ,则该key 很可能(我们期望存在的概率是多少可以设置) 存在。

(1) 例如针对值 baidu 和三个不同的哈希函数分别生成了哈希值 1 、 4 、 7 ,则上图转变为
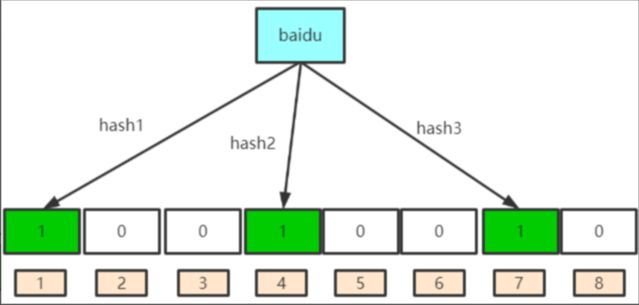
(2) 再存一个值 tencent,如果哈希函数返回 3 、 4 、 8 的话,图继续变为:

4这个 bit 位由于两个哈希函数都返回了这个 bit 位,因此它被覆盖了。现在我们如果想查询 alibaba 这个值是否存在,哈希函数返回了 1 、 5 、 8 三个值,结果我们发现 5 这个 bit 位上的值为 0 说明没有任何一个值映射到这个 bit 位上 ,因此我们可以很确定地说 alibaba 这个值不存在。而当我们需要查询 baidu 这个值是否存在的话,那么哈希函数必然会返回 1 、 4 、 7 ,然后我们检查发现这三个 bit 位上的值均为 1 ,那么我们可以说 baidu存在了么?答案是不可以,只能是 baidu 这个值可能存在。会存在误判。
Bloomfilter为什么不支持删除元素?
在bitmap中每个bit只有两种状态(0 或者 1),一个bit被设置为 1 状态,但不确定它被设置了多少次;也就是不知道被多少个 key 哈希映射而来以及是被具体哪个 hash 函数映射而来;
应用场景
布隆过滤器通常用于判断某个 key 一定不存在的场景,同时允许判断存在时有误差的情况;
常用于解决数据库的缓存穿透问题。
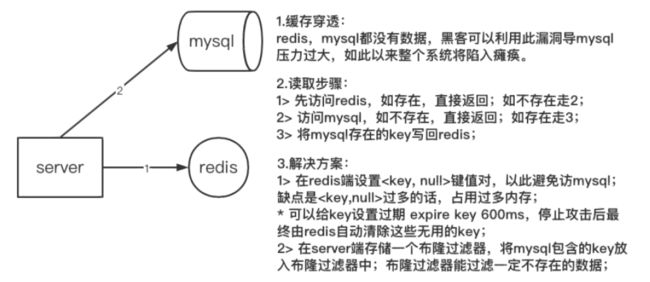
-
描述缓存场景,为了减轻数据库(mysql)的访问压力,在 server 端与数据库(mysql)之间加入缓存用来存储热点数据;
-
描述缓存穿透,server端请求数据时,缓存和数据库都不包含该数据,最终请求压力全部涌向数据库;
-
数据请求步骤,如图中 2 所示;
-
发生原因:黑客利用漏洞伪造数据攻击或者内部业务 bug 造成大量重复请求不存在的数据;
-
解决方案:如图中 3 所示;
应用分析
在实际应用中,该选择多少个 hash 函数?要分配多少空间的位图?预期存储多少元素?如何控制误差?
可以参考https://hur.st/bloomfilter
分布式一致性hash
应用场景
分布式一致性hash最先是用来解决分布式缓存问题的。将数据均衡的分散在不同的服务器中,用来分摊缓存服务器的压力;解决缓存服务器数量变化引起的缓存失效问题。
普通的hash算法在分布式应用中的不足
以前memcached不支持集群,不能够横向扩展,就使用hash将数据均衡分布到多个memcached中。
但是,对于增加节点,就会有问题。
比如,在分布式的存储系统中,要将数据存储到具体的节点上,如果我们采用普通的hash算法进行路由,将数据映射到具体的节点上,如key%N,key是数据的key,N是机器节点数,如果有一个机器加入或退出这个集群,则所有的数据映射都无效了,如果是持久化存储则要做数据迁移,如果是分布式缓存,则其他缓存就失效了。
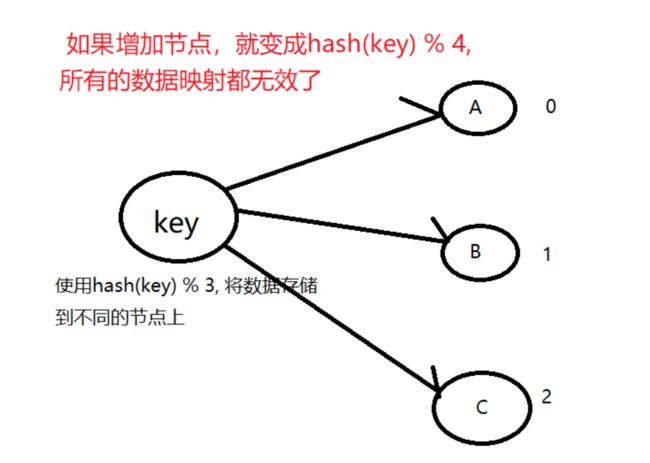
分布式一致性hash解决数据映射失效问题
分布式一致性hash能解决增加节点,数据映射失效的问题。
把算法固定住,不因为增加节点而变化。不是对节点数量取余,而是对固定的数 2 32 2^{32} 232取余。
分布式一致性 hash 算法将哈希空间组织成一个虚拟的圆环,圆环的大小是 2 32 2^{32} 232 ;
将各个节点使用hash函数进行一个哈希,具体可以选择节点的ip + port作为关键字进行hash,这样每个节点就能确定其在哈希环上的位置。存放数据的时候,使用相同的hash函数,得到key在hash环上的具体位置。根据数据的hash值,去hash环找到第一个大于等于数据hash值的节点,数据存储到该节点。

分布式一致性hash,对于增加节点,只会影响部分数据映射。对于这个问题,需要通过数据迁移来解决。
hash偏移
hash 算法得到的结果是随机的,不能保证服务器节点均匀分布在哈希环上;分布不均匀造成请求访问不均匀,服务器承受的压力不均匀。导致了数据倾斜问题。

节点足够多的话, hash具有强随机分布性,数据就会均匀分布。
解决方法:增加虚拟节点。为每一个节点生成多个虚拟节点。

数据迁移参考https://github.com/metang326/consistent_hashing_cpp
总结
hashmap、bloomfilter和分布式一致性hash都是基于hash函数的。
hashmap用于key-value数据的存储,如C++ stl的unordered_map,redis数据组织等;bloomfilter是一种概率行数据结构,可以确定某个key一定不存在或者可能存在;分布式一致性hash用于分布式缓存系统的负载均衡,并且解决节点变化带来的缓存失效问题。