「面试必背」大数据面试题100道(收藏)
前言
随着 5G 时代的到来,大数据人工智能产业链又一次迎来了井喷式的爆发,随着岗位需求的不断增加,越来越多的人选择大数据课程,但是没有真正从事大数据工作的人面对企业面试有种无从下手的感觉,面对面试说不到技术的重点,每次面试只能靠队友,靠兄弟支援,尤其是面对架构,编程更是无从下手。于是我决定对市场上大多的有关大数据核心的面试题做一个详细的分析,也希望大家尽可能的做到举一反三,而不是局限于题目本身。
1、选择题
1.1.下面哪个程序负责 HDFS 数据存储。
- a)NameNode
- b)Jobtracker
- c)Datanode
- d)secondaryNameNode
- e)tasktracker
答案 C datanode
1.2.HDfS 中的 block 默认保存几份?
- a)3 份
- b)2 份
- c)1 份
- d)不确定
答案 A 默认 3 份
1.3.下列哪个程序通常与 NameNode 在一个节点启动?
- a)SecondaryNameNode
- b)DataNode
- c)TaskTracker
- d)Jobtracker
答案 D
1.4.HDFS 默认 Block Size
a)32MB
b)64MB
c)128MB
答案:B
1.5.下列哪项通常是集群的最主要瓶颈
- a)CPU
- b)网络
- c)磁盘 IO
- d)内存
答案:C 磁盘
1.6.关于 SecondaryNameNode 哪项是正确的?
- a)它是 NameNode 的热备
- b)它对内存没有要求
- c)它的目的是帮助 NameNode 合并编辑日志,减少 NameNode 启动时间
- d)SecondaryNameNode 应与 NameNode 部署到一个节点
答案 C。
1.7.下列哪项可以作为集群的管理?
- a)Puppet
- b)Pdsh
- c)Cloudera Manager
- d)Zookeeper
答案 ABD
1.8.Client 端上传文件的时候下列哪项正确
- a)数据经过 NameNode 传递给 DataNode
- b)Client 端将文件切分为 Block,依次上传
- c)Client 只上传数据到一台 DataNode,然后由 NameNode 负责 Block 复制工作
答案 B
分析:Client 向 NameNode 发起文件写入的请求。NameNode 根据文件大小和文件块配置情况,返回给 Client 它所管理部分 DataNode 的信息。Client 将文件划分为多个 Block,根据 DataNode 的地址信息,按顺序写入到每一个 DataNode 块中。具体查看 HDFS 体系结构简介及优缺点。
1.9.下列哪个是 Hadoop 运行的模式
- a)单机版
- b)伪分布式
- c)分布式
答案 ABC 单机版,伪分布式只是学习用的。
2、面试题
2.1. Hadoop 的核心配置是什么?
Hadoop 的核心配置通过两个 xml 文件来完成:1,hadoop-default.xml;2,hadoop-site.xml。这些文件都使用 xml 格式,因此每个 xml 中都有一些属性,包括名称和值,但是当下这些文件都已不复存在。
2.2.那当下又该如何配置?
Hadoop 现在拥有 3 个配置文件:1,core-site.xml;2,hdfs-site.xml;3,mapred-site.xml。这些文件都保存在 conf/子目录下。
2.3.“jps”命令的用处?
这个命令可以检查 Namenode、Datanode、Task Tracker、 Job Tracker 是否正常工作。
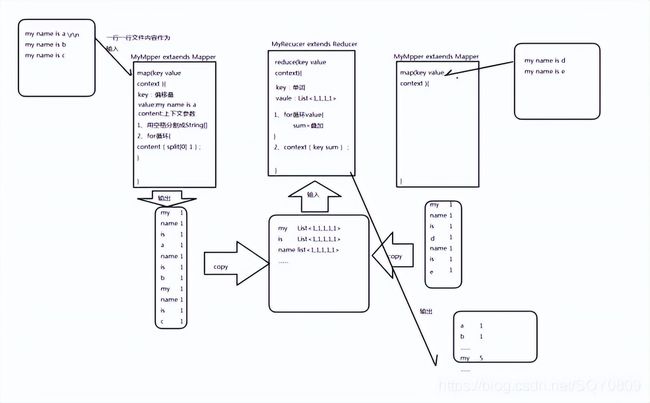
2.4.mapreduce 的原理?
2.5. HDFS 存储的机制?
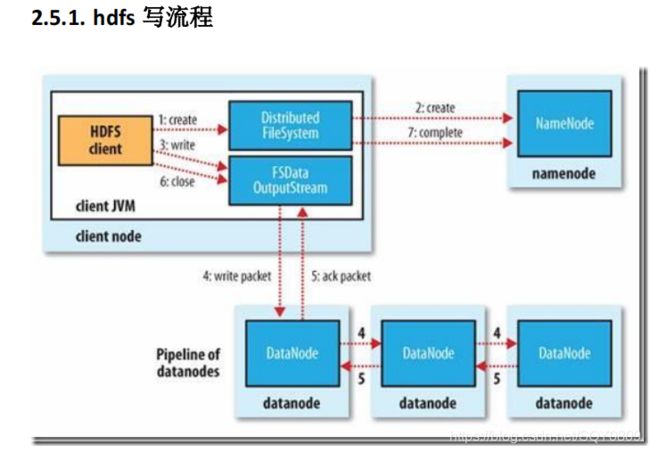
流程:
1、 client 链接 namenode 存数据
2、 namenode 记录一条数据位置信息(元数据),告诉 client 存哪。
3、 client 用 hdfs 的 api 将数据块(默认是 64M)存储到 datanode 上。
4、 datanode 将数据水平备份。并且备份完将反馈 client。
5、 client 通知 namenode 存储块完毕。
6、 namenode 将元数据同步到内存中。
7、 另一块循环上面的过程。
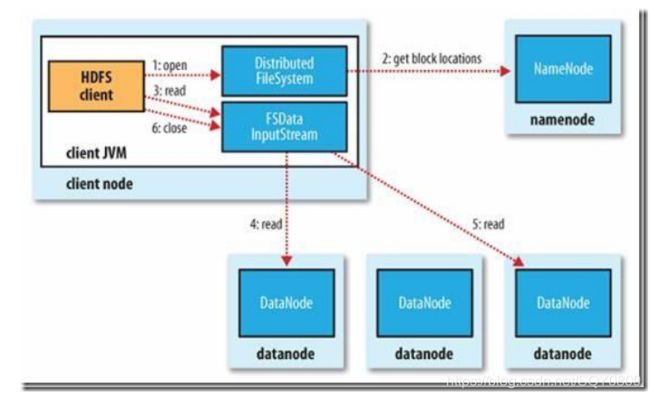
流程:
1、 client 链接 namenode,查看元数据,找到数据的存储位置。
2、 client 通过 hdfs 的 api 并发读取数据。
3、 关闭连接。
2.6.举一个简单的例子说明 mapreduce 是怎么来运行的 ?
wordcount 的例子
2.7.用 mapreduce 来实现下面需求?
现在有 10 个文件夹,每个文件夹都有 1000000 个 url.现在让你找出 top1000000url。
解答:topk
(还可以用 treeMap, 到 1000000 了每来一个都加进去, 删掉最小的)
2.8.hadoop 中 Combiner 的作用?
combiner 是 reduce 的实现,在 map 端运行计算任务,减少 map 端的输出数据。
作用就是优化。
但是 combiner 的使用场景是 mapreduce 的 map 和 reduce 输入输出一样。
2.9.简述 hadoop 安装

2.10. 请列出 hadoop 进程名

2.11. 解决下面的错误

2.12. 写出下面的命令

2.13. 简述 hadoop 的调度器

2.14. 列出你开发 mapreduce 的语言

2.15. 书写程序

2.16. 不同语言的优缺点
2.17. hive 有哪些保存元数据的方式,个有什么特点。
2.18. combiner 和 partition 的作用

2.19. hive 内部表和外部表的区别
- 内部表:加载数据到 hive 所在的 hdfs 目录,删除时,元数据和数据文件都删除
- 外部表:不加载数据到 hive 所在的 hdfs 目录,删除时,只删除表结构
2.20. hbase 的 rowkey 怎么创建好?列族怎么创建比较 好?
- hbase 存储时,数据按照 Row key 的字典序(byte order)排序存储。设计 key 时,要充分排序
- 存储这个特性,将经常一起读取的行存储放到一起。(位置相关性)一个列族在数据底层是一个文件,所以将经常一起查询的列放到一个列族中,列族尽量少, 减少文件的寻址时间。
2.21. 用 mapreduce 怎么处理数据倾斜问题?

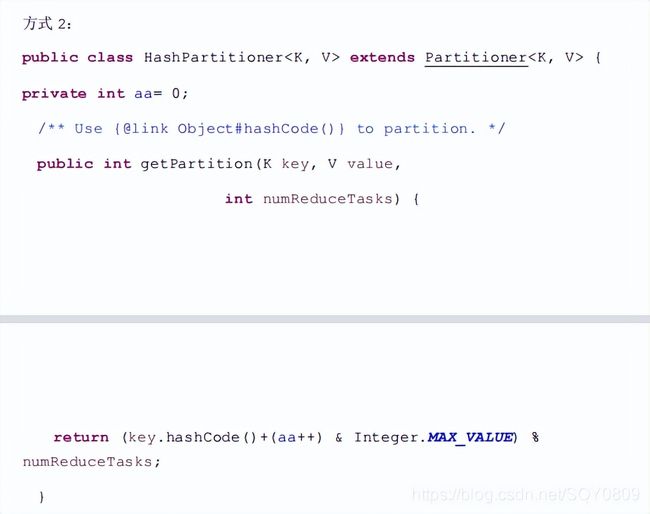
2.22. hadoop 框架中怎么来优化

2.23. 我们开发 job 时,是否可以去掉 reduce 阶段。
可以。设置 reduce 数为 0 即可
2.24. datanode 在什么情况下不会备份
datanode 在强制关闭或者非正常断电不会备份
2.25. combiner 出现在那个过程
出现在 map 阶段的 map 方法后。
2.26. hdfs 的体系结构
- hdfs 有 namenode、secondraynamenode、datanode 组成。
- 为 n+1 模式
- namenode 负责管理 datanode 和记录元数据
- secondraynamenode 负责合并日志
- datanode 负责存储数据
2.27. 3 个 datanode 中有一个 datanode 出现错误会怎样?
这个 datanode 的数据会在其他的 datanode 上重新做备份。
2.28. 描述一下 hadoop 中,有哪些地方使用了缓存机制, 作用分别是什么?
在 mapreduce 提交 job 的获取 id 之后,会将所有文件存储到分布式缓存上,这样文件可以被所有的 mapreduce 共享。
2.29. 如何确定 hadoop 集群的健康状态
通过页面监控,脚本监控。
2.30. 生产环境中为什么建议使用外部表?
1、因为外部表不会加载数据到 hive,减少数据传输、数据还能共享。
2、hive 不会修改数据,所以无需担心数据的损坏
3、 删除表时,只删除表结构、不删除数据。
感谢阅读,由于篇幅有限以上面经资料博主已经整理打包好了,这些知识点的导图和问题的答案详解的PDF文档都可以免费分享给大家,点赞收藏文章后,私信【资料】免费领取!
