SQLServer数据类型优先级对性能的影响
问题:
我在我的应用程序中使用简单的查询/存储过程访问一个很大的表。但执行了很长时间。在where子句中,我使用了有索引并且高选择性(selective)并且没有用函数包裹的字段。但是看起来就像没有使用索引一样,问题出在那里?
解决方案:
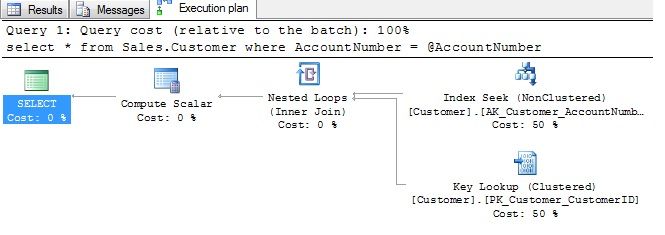
出现这种微秒的问题原因可能是作为参数的数据类型与查询中的数据类型不一致。在这种情况下,SQLServer将会要么把where中的列,要么把参数的数据类型隐式转换为更高级或者更低级的数据类型。当作为被查询列被转换时(转换竞争中的牺牲者),将引起扫描(scan)来满足查询请求。让我们看看以下两个例子,第一个例子使用示例数据库AdventureWorks,我们将通过一个客户的AccountNumber在Sales.Customer表中查询这个客户。AccountNumber这一列的数据类型是varchar(10)并且上面有一个唯一索引。运行下面的查询并且查看执行计划,可以看到结果如我们所愿:
create proceduredbo.PrecedenceTest
(
@AccountNumber varchar(10)
)
as
begin
set nocount on
select *
from Sales.Customer
where AccountNumber = @AccountNumber
end
go
exec dbo.PrecedenceTest'AW00030113'
go
执行计划如下:
接着让我们在参数上做些小改动,把它改为nvarchar(10),然后重新执行语句:
alter procedure dbo.PrecedenceTest
(
@AccountNumber nvarchar(10)
)
as
begin
set nocount on
select *
from Sales.Customer
where AccountNumber = @AccountNumber
end
go
exec dbo.PrecedenceTest 'AW00030113'
go
执行计划显示,优化器选择了扫描TerritoryID上的索引。
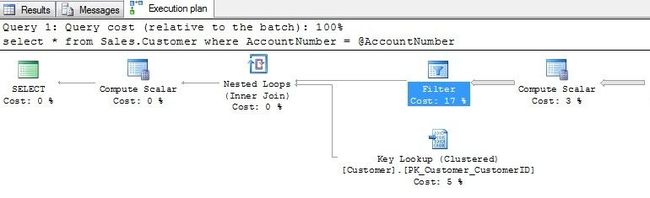
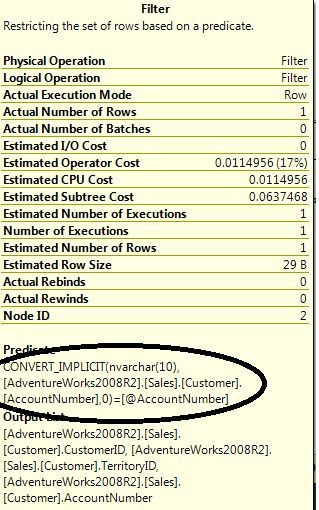
检查Filter操作,可以看到AccountNumber列上被隐式转换了类型来匹配传入的参数。由于数据类型varchar比参数类型nvarchar级别更低,导致其所在的索引失效。
现在让我们验证一下,在较低级别的数据类型作为查找参数下的情况。在这个例子中,Person.Person 表的LastName列是nvarchar类型,并且上面存在一个可用的索引,存储过程传入的参数是varchar类型:
alter procedure dbo.PrecedenceTest(
@LastName varchar(50)
)
as
begin
set nocount on
select *
from Person.Person
where LastName = @LastName
end
go
exec dbo.PrecedenceTest 'Tamburello'
go
执行计划显示,优化器选择使用了索引查找:

点开Index Seek的详细信息,可以看到列LastName的数据类型因为传入参数的原因而隐式转换成更高级的nvarchar类型。
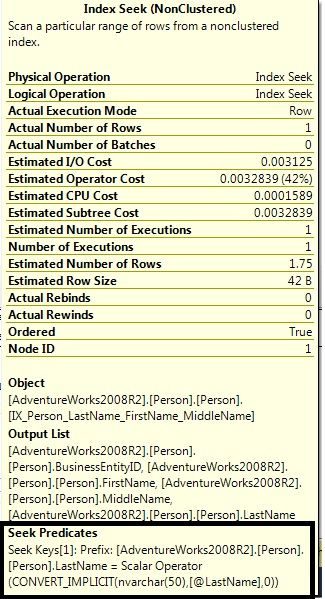
当索引列不再被转换所影响时,优化器可以自由地选择最优执行计划。
不管你是在应用程序或者在存储过程中定义查询参数,确保查询参数中的数据类型和查询列的数据类型相吻合能避免索引扫描和其他转换引起的问题。
补充:数据类型的优先级,从高到底:
-
user-defined data types (highest)
-
sql_variant
-
xml
-
datetimeoffset
-
datetime2
-
datetime
-
smalldatetime
-
date
-
time
-
float
-
real
-
decimal
-
money
-
smallmoney
-
bigint
-
int
-
smallint
-
tinyint
-
bit
-
ntext
-
text
-
image
-
timestamp
-
uniqueidentifier
-
nvarchar (including nvarchar(max) )
-
nchar
-
varchar (including varchar(max) )
-
char
-
varbinary (including varbinary(max) )
-
binary (lowest)