只需两行代码,2080Ti 就能当 V100用,这个炼丹神器真牛!

作者 | 陈大鑫、青暮
话说人工智能江湖门派众多且繁杂,好似那大脑中的神经网络一般,但繁杂中却仍然有着一统的迹象......
许久之前,ML派坐落美利坚合众山中,百年来武学奇才辈出,隐然成江湖第一大名门正派,门内有三套入门武功,曰:图模型加圈,神经网加层,优化目标加正则。有童谣为证:熟练ML入门功,不会作文也会诌。
不期数年,北方DL神教异军突起,内修表示学习,外练神经网络,心法众多,曰门,曰注意,曰记忆,曰对抗,曰增强。经ImageNet一役威震武林,豢Alpha犬一匹无人可近。一时家家筑丹炉,人人炼丹忙,门徒云集,依附者众,有一统江湖之势。有童谣为证:左手大数据,右手英伟达,每逢顶会炼丹忙。
转至今时,竟知DL神教仍不是源头,它背靠「大力神教」,Transformer、BERT、GPT-3 、DALL.E等等神丹相继纷纷被祭出......
丹炉越来越大、炉火越烧越旺,「大力出奇迹」已被众多教徒们信奉为至高无上的教义。
............................
就这样时间来到了2021年,训练大模型已几乎成为了AI界的共识,近期MLP的涅槃重生与Transformer的一场争斗大戏,让大家不禁悲叹「Attention is all you need」是假的,别的神马也都是不确定的,唯有「Money is all you need 」是真的 。
。

然而,因为虚拟货币挖矿等众多原因,显卡的价格一直居高不下,不容乐观,且一度缺货。随手打开某电商平台,可以看到一张2080Ti 涨到一万五起步 ,一张 V100 更是得四五万。
可就在这样的背景下,如果现在有人告诉你2080Ti可以当作 V100来用,那得节省多少Money?
你会说这怎么可能呢?V100的显存可是有16GB ,而2080Ti的显存只有11GB,相比于计算能力,显存容量可是一票否决制的,虽然计算能力决定了模型训练的快慢,但是显存容量决定了模型能否训练。即使 2080Ti 的计算能力高于 V100,但是由于显存容量不够,batchsize设置为128 的 ResNet50 根本无法进行训练,单就这点儿而言对于吃大显存的 AI 模型就不可能绕的过去。
然而人定胜天,世间上最令人兴奋的事莫过于把看似不可能变成可能,好似魔法一般,其秘诀就在于下面这两行代码:

没错,就是上面这两行看似简简单单的代码,它就像一个“点石成金”的按钮,蕴含着巨大的能量,只要一键开启之后,2080Ti 就可以当作 V100来用!
这么神奇的事情背后究竟是怎么一回事呢?
在一番探寻之后发现,原来是旷视在开源深度学习框架MegEngine 的最新版本V1.4中,新增了动态图的显存优化技术(DTR)。
“炼丹”时使用这项新功能后可以实现显著降低显存占用的魔法般效果。
在使用DTR功能后,11G显存的2080Ti 可以训练出原本32G显存的V100才能训练的模型,可以节省很多Money!另外很多学生党只有 1060 之类的4~6GB的小显存卡,而靠 DTR就能在便宜的民用显卡上训练原本需要吃10GB显存以上的大模型了。
1
“魔法”从何而来
旷视MegEngine 团队在2020年下半年的时候希望由静态图彻底向动态图迁移,所以开始探索动态图上的 sublinear 类似技术,这时团队偶然看到了华盛顿大学和卡纳基梅隆大学团队合作的一篇名为DTR论文:《Dynamic Tensor Rematerialization》,目前该论文已被 ICLR 2021接收为 Spotlight。

论文链接:https://arxiv.org/abs/2006.09616
这篇论文主要讲了一种动态图的显存优化技术——在前向计算时释放保存中间结果的tensor,反向求导时根据计算历史恢复之前释放的tensor,从而达到训练更大模型的目的,亮点是提出了一种动态选取释放的tensor的策略。
而MegEngine框架本来就有静态图上的显存优化,功能上与 DTR 类似,经过一番理论到工程的实现之后,MegEngine团队通过DTR成功实现了动态图显存优化技术。
至于为什么MegEngine 团队要针对动态图做优化,那当然是因为动态图代码易写易调试、是现在的主流趋势,且随着越来越多的深度学习框架支持动态图模式,能否在动态图训练时最大程度地利用有限的显存资源,成为了评估深度学习框架性能的重要指标。然而对于目前业界的主流框架而言,如果想使用显存优化训练更大的模型必须要先转静态图之后再用Sublinear来优化才行。
意思就是你动态图想直接优化显存不行,必须先走静态图这个桥梁才行,这意味什么呢?举个例子哈,假如你要去民事局和心爱的对象办理结婚,但是民事局却告诉你们必须先去一趟警察局登记才行,那谁能乐意呢,不知道情况的被误会了可咋办,多一趟手续多少会带来一些麻烦啊。
所以说,直接在简单易用的动态图上做显存优化就成为了一个迫切的需求,可以给到AI研究员和企业工程师很大的帮助,而未来 MegEngine 也将会全面迁移到动态图上,并且会致力于优化动态图的性能,使得动态图和静态图一样快,甚至更快。
那么在代码里开启动态图优化功能会很麻烦吗?
NO NO NO~就像前文已经说过的一样,真的只需添加下面两行代码就行:

第一行代码是声明DTR的参数,第二行代码是打开DTR开关,只要把这两行放在开头,后面的模型代码保证不用再做任何改动。
真可谓是一键开启动态Sublinear显存优化功能,简直方便到不行!
那么优化效果如何呢?下面通过一张动态Sublinear显存优化图来展示一下:
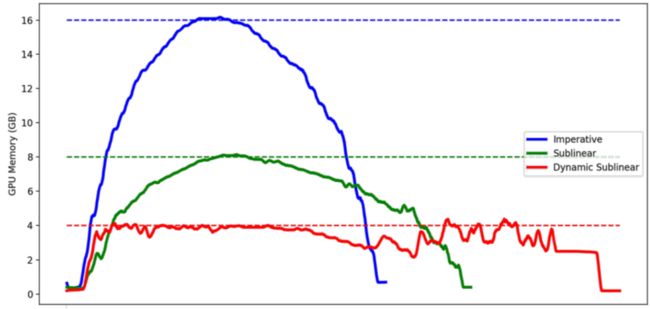
如上图所示,这是某个AI 模型的训练图,蓝色线是不加任何动态图显存优化的训练过程,在峰值条件下需要占用 16GB 的GPU显存;
绿色线是Sublinear优化之后的静态图训练过程,在峰值条件下需要占用 8GB的GPU显存,
红色线是开启动态Sublinear显存优化之后的训练过程,在峰值条件下,仅需要占用4GB的GPU显存,也就是蓝线的1/4。
对比蓝色线和红色线,很明显看出原先的16GB显存占用现在优化到来4GB左右!
大家都知道2080Ti 的计算能力比 V100 高,但是却受限于显存容量比 V100 低,而开启了 DTR 优化之后,相当于用多出来的计算能力弥补了显存容量上的不足,使得原来在 2080Ti 上无法训练的模型可以训练起来。
也即等于一张 2080 Ti 可以用出 V100 的感觉!
且旷视MegEngine的工程师亲自做了测试,发现在 2080Ti上,ResNet50、ShuffleNet等网络模型的最大batchsize可以达到原来的3倍以上。
而且这个黑科技魔法是可叠加到多卡上的,所以说十张2080 Ti 同样可以用出十张V100的效果。
好家伙,这简直就是训练 AI 大模型的神器啊!
因为并不是每个实验室都有像谷歌、Fackbook这样的土豪,而依靠旷视这项 DTR技术实现,可以大大节省购买显卡的资金,能让更多的大学、实验室可以参与到这场不分对错的“大力出奇迹”的 “军备竞赛”当中来。
这背后具体是什么原理呢?MegEngine团队的工程师写了一篇详细的文章介绍其DTR的实现与优化路径,感兴趣的读者可以点击文末的阅读原文链接一键直达。
2
实验数据对比
对这个训练 AI 大模型神器的感觉还是不够直观?
那就不如看一下更直观的实验数据对比。
首先是训练耗时对比。
下图是MegEngine的DTR实现与原论文在PyTorch中的实现在ResNet1202上的训练情况对比,注意到实验用的显卡不同,所以从数据上看MegEngine稍快一些。
不难看出,在显存管理上MegEngine要更好一些,因为在11G的显卡上它仍然能跑batchsize=100 的模型训练。除了论文中尝试的最大batchsize=140之外,MegEngine团队还尝试了更大的batchsize,也都是可以运行的。

下面是在MegEngine框架上开启不同显存优化的训练耗时对比,baseline是在动态图模式下不加任何显存优化运行的结果。
首先是两个常见的模型——ResNet50和ShuffleNet的对比,可以发现开启DTR优化后极限batchsize超过了静态图Sublinear和baseline,且在batchsize相同时耗时和Sublinear持平。
需要说明的是这里拿视觉模型只是为了方便做实验和举例,实际上这项优化功能适用于CV、NLP等不同领域的任意 AI 模型训练。

上面的两个模型都是比较偏静态的,所以可以用静态图的Sublinear显存优化来做对比,而下面这个SPOS网络就比较特殊,它是一个从输入到输出有多条路径可以更新的大网络。
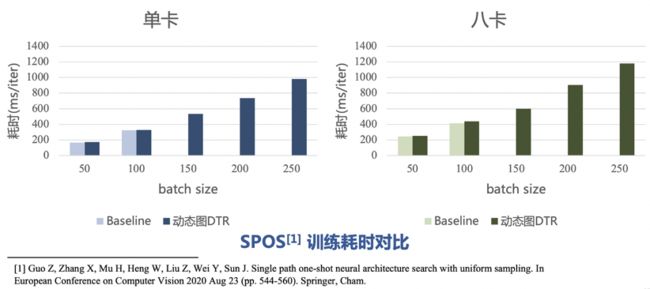
在训练过程中,每一轮会随机采样去更新某一条路径,这就导致每轮执行的语句可能不相同。对于这种网络,在动态图里实现会比较自然。因此,这里只取了动态图DTR优化的结果与Baseline比较。不论是单卡还是八卡,动态图的极限batchsize都在100,如果打开DTR可以跑到250甚至更大。
硬币都是两面的,在MegEngine框架上实现的这项DTR 技术非常之香——2080Ti 可以当作V100来用,但固然也有代价——牺牲了计算算力和计算时长:
牺牲的计算时长由DTR的参数决定,最坏情况下所有 Tensor 在不被用到的时候都立即释放,恢复每个 Tensor 的时间都是 O(N)的,总的时间就会达到 O(N^2) 级别。但一般情况下只是原来的时间的常数倍。
例如训练 batchsize=200 的 ResNet50 需要 16G 左右的显存,每轮的训练耗时是800ms。设置DTR的阈值为7G时,只需要 11G 的显存,训练耗时为 898ms;设置DTR的阈值为3G时,只需要 7.5G 的显存,训练耗时为 1239ms。
但是要清楚地认识到 DTR 的优势不是体现在耗时上,而是体现在可以训练 batchsize 更大的模型。用了DTR耗时一定是会增加的,但是这个是可以容忍的,因为原本不能训练的大模型现在可以训练了!
最后,还要介绍一下这项DTR技术的最神奇之处——显存占用越大越吃香!
也即是显卡容量越大,优化的效果越好,都能把任意大的内存优化到原来层数对应的 1/ 倍,这里的 O(1/
倍,这里的 O(1/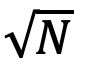 )是对于n层的前馈神经网络的理论下界。
)是对于n层的前馈神经网络的理论下界。
3
总结
1、MegEngine是首个实现DTR技术的开源深度学习框架。
2、一张 2080 Ti 可以用出 V100 的感觉。
3、在2080Ti上,ResNet50、ShuffleNet等网络的最大batchsize可以达到原来的3倍以上!
4、单卡上的优化可以叠加到多卡上一起加倍节省显存。
5、显存占用越大越吃香。
6、对于用户的体验:运行速度更快、使用体验更好:API简洁,用户只用打开开关,不用改动训练代码。
7、对于框架开发者的体验:得益于MegEngine框架简洁的底层实现,在 MegEngine 中实现DTR更加简单自然,并且便于进行扩展。
(注:本文开头二、三两段为清华大学刘知远老师原创,本文已经过刘老师本人授权使用。)
推荐阅读
【重磅】斯坦福李飞飞《注意力与Transformer》总结,84页ppt开放下载!
2021年,深度学习还有哪些未饱和、有潜力且处于上升期的研究方向?
最强通道注意力来啦!金字塔分割注意力模块,即插即用,效果显著,已开源!
Deepfake文字版横空出世:AI高仿你的笔迹只需1个词!
分层级联Transformer!苏黎世联邦提出TransCNN: 显著降低了计算/空间复杂度!
注意力可以使MLP完全替代CNN吗? 未来有哪些研究方向?
清华鲁继文团队提出DynamicViT:一种高效的动态稀疏化Token的ViT
并非所有图像都值16x16个词--- 清华&华为提出一种自适应序列长度的动态ViT
重磅!DLer-ICCV2021论文分享交流群已成立!
大家好,这是ICCV2021论文分享群里,群里会第一时间发布ICCV2021的论文解读和交流分享会,主要设计方向有:图像分类、Transformer、目标检测、目标跟踪、点云与语义分割、GAN、超分辨率、人脸检测与识别、动作行为与时空运动、模型压缩和量化剪枝、迁移学习、人体姿态估计等内容。
进群请备注:研究方向+学校/公司+昵称(如图像分类+上交+小明)
???? 长按识别,即可进群!