停止以 CSV 格式保存数据帧,这些格式更棒!
欢迎关注 ,专注Python、数据分析、数据挖掘、好玩工具!
数据科学就是要处理数据。整个数据科学模型开发流程涉及数据讨论、数据探索、探索性数据分析、特征工程和建模。读取和保存中间文件是模型开发中的一项常见任务。
数据科学家通常更喜欢以 CSV 格式读取和保存 Pandas 数据帧。处理小尺寸或中等尺寸的数据非常简单,不需要太多开销,但是当处理大尺寸的数据集时,由于资源的限制,工作流会变慢。
CSV、Excel或其他文本文件格式在处理大数据时会失去吸引力。有各种二进制数据格式优于 CSV 文件格式,Pandas包支持使用这种数据格式。
在本文中,我们将比较各种数据格式的内存消耗、保存和读取操作时间数,并进一步总结适合每种情况的数据格式选择,有所收获,欢迎点赞支持、收藏。
数据格式比较
在本文中,我们将比较下面提到的8种数据格式,包括 Pandas 的读取时间、Pandas 的保存时间、磁盘上的内存消耗。
- CSV
- Compressed CSV
- JSON
- Pickle
- Compressed Pickle
- Parquet
- HDF
- Feather
数据源
我将使用来自Kaggle的纽约市出租车持续时间数据集来比较,它拥有1458644条记录和12个特征。数据链接如下:
https://www.kaggle.com/c/nyc-taxi-trip-duration/data
数据可视化对比
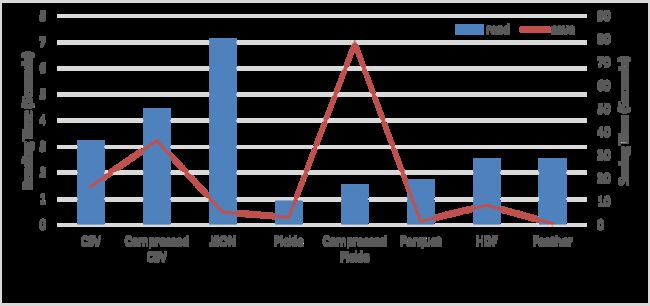

建议
通过观察上述每种文件格式的读取和保存操作以及内存消耗的基准数据,可以针对不同的情况遵循如下建议:
- 如果要在会话或中间文件之间保存数据,请使用pickle、feather 或 parquet 格式。Pickle 最受欢迎和推荐,因为它有最低的读数,节省时间。
- 如果要以最小的大小保存数据或优化内存消耗,请使用 compressed pickle, parquet, compressed CSV 格式。最推荐使用 compressed pickle,因为它的内存消耗最少。
- 要保存非常大的数据帧,请使用 HDF 格式。
- 要在不支持其他格式的其他平台上读取数据,请使用CSV、compressed CSV 格式。
结论
在本文中,我们讨论了8种可用于保存原始数据、中间数据的数据格式,并通过可视化图示的形式比较了读写时间数和内存消耗情况。
- 1、Parquet、Compressed Pickle、Compressed CSV、Feather数据格式可用于优化数据的内存消耗。与标准CSV格式相比,使用这些文件格式可以优化高达78%的内存。
- 2、Pickle、Parquet、Feather文件格式可以优先于标准 CSV 格式,因为它们具有更快的读取和保存能力。
技术交流
欢迎转载、收藏、有所收获点赞支持一下!

目前开通了技术交流群,群友超过2000人,添加方式如下:
如下方式均可,添加时最好方式为:来源+兴趣方向,方便找到志同道合的朋友
- 方式一、发送如下图片至微信,进行长按识别,回复加群;
- 方式二、直接添加小助手微信号:pythoner666,备注:来自CSDN
- 方式三、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
