数据科学导论——数据采集和预处理作业
作业题目
1.请简述深度优先遍历的算法思想
2.请简述广度优先遍历的算法思想
3.数据预处理的方法有哪些?
4.请分别写出下图的深度优先遍历和广度优先遍历的结果(假设V1是顶点)
5.假设2018年普通程序员的税后收入排序后的值(单位为元):
4800,5000,5200,5500,5500,5800,6000,6300,
6500,6800,7000,7500,8000,8500,8800,9000
1)请用等深分箱法对上述数据进行划分;
2)请用等宽分箱法对上述数据进行划分;
3)根据6000元以下、60007000、70008000和8000元以上自定义规则划分上述数据;
6.根据第5题中等宽分箱法的划分结果,按照如下要求进行平滑处理:
1)按箱平均值平滑处理;
2)按箱边界值平滑处理;
3)按箱中值平滑处理。
7.为什么要进行数据预处理?
8.小明想买一双耐克运动鞋,他自己希望的价格最高是890,最低价格是350。现将最高价和最低价映射到区间[0.0, 1.0]。试问,他买了价格为760和950的两双鞋在新区间里的值为多少?
9. 计算机嵌入161班工作后月收入的均值为8700元,标准差为1800元,使用零均值规范化方法将小明月收入9900元映射为多少?
10.假设计算机嵌入161班40名同学工作后月收入A在6900元到13000元范围里,确定小数定标规范化的系数j的大小和映射区间。
11.数据集X的每一行是一个样本,请写出每个样本中心化后的数据。
解答
1.请简述深度优先遍历的算法思想

2.请简述广度优先遍历的算法思想

3.数据预处理的方法有哪些?
数据清理、数据集成、数据规约和数据变换。
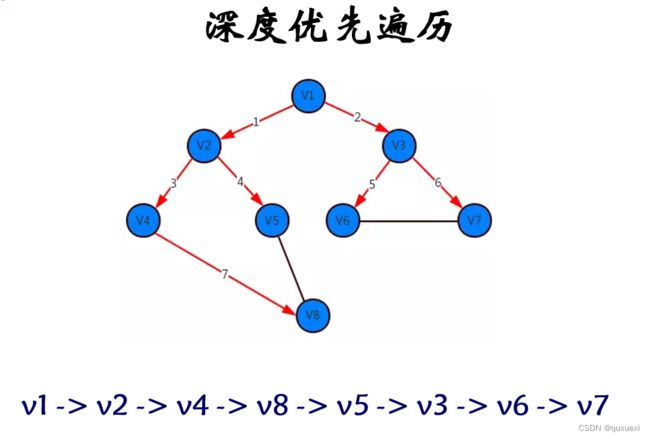
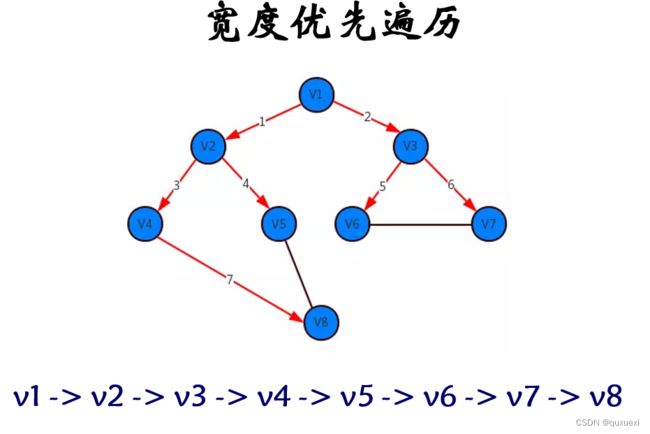
4.请分别写出下图的深度优先遍历和广度优先遍历的结果(假设V1是顶点) 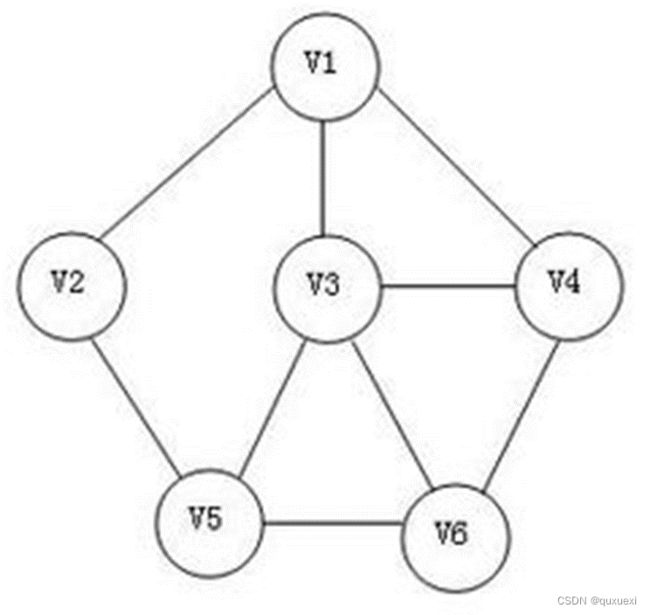
深度优先遍历:v1->v2->v5->v6->v3->v4
广度优先遍历:v1->v2->v3->v4->v5->v6
图的深度优先遍历,和树的先序遍历比较类似,但却又不一样。
二叉树的深度优先遍历又可分为:前序遍历、中序遍历、后序遍历
图的深度优先遍历特点是,选定一个出发点后进行遍历,能前进则前进,若不能前进,回退一步再前进,或再回退一步后继续前进。依此重复,直到所有与选定点相通的所有顶点都被遍历。
5.假设2018年普通程序员的税后收入排序后的值(单位为元):
4800,5000,5200,5500,5500,5800,6000,6300,
6500,6800,7000,7500,8000,8500,8800,9000
1)请用等深分箱法对上述数据进行划分;
2)请用等宽分箱法对上述数据进行划分;
3)根据6000元以下、6000 ~ 7000、7000~8000和8000元以上自定义规则划分上述数据;
一共16个数据,等深和等宽均分为四组
等深分箱法结果:
箱1:4800,5000,5200,5500
箱2:5500,5800,6000,6300
箱3:6500,6800,7000,7500
箱4:8000,8500,8800,9000
等宽分箱法结果
间隔宽度 W = (9000 - 4800)/ 4 = 1050
箱1(4800~5850):4800,5000,5200,5500,5500,5800
箱2(5850~6900):6000,6300,6500,6800
箱3(6900~7950):7000,7500
箱4(7950~9000):8000,8500,8800,9000
用户自定义区间法:
箱1 (6000元以下):4800,5000,5200,5500,5500,5800
箱2 (6000 ~ 7000):6000,6300,6500,6800,7000
箱3 (7000~8000):7500,8000
箱4 (8000元以上):8500,8800,9000
等深分箱法/等频率分箱法:
按照对象的个数来划分,统一权重,每箱具有相同的记录数,每箱记录数称为箱子的深度。这是最简单的一种分箱方法。即,将给定数据划分大致相同数量样本N箱子,每箱具有相同的记录数。等宽分箱法/等距离分箱法:
按照对象的值来划分,统一区间,使数据集在整个属性值的区间上平均分布,即每个箱的区间范围是一个常量,称为箱子宽度。即,将给定数据划分为等间隔的N个箱子。
分法:如何给定数据中A和B分别为最小值和最大值,间隔宽度W的计算公式:
W=(B - A)/ N
用户自定义区间法:
用户可以根据需要自定义区间,当用户明确希望观察某些区间范围内的数据分布时,使用这种方法可以方便地帮助用户达到目的。
6.根据第5题中 等宽分箱法 的划分结果,按照如下要求进行平滑处理:
第5题 等宽分箱法结果
间隔宽度 W = (9000 - 4800)/ 4 = 1050
箱1(4800~5850):4800,5000,5200,5500,5500,5800
箱2(5850~6900):6000,6300,6500,6800
箱3(6900~7950):7000,7500
箱4(7950~9000):8000,8500,8800,9000
1)按箱平均值平滑处理;
箱1(4800~5850):5300,5300,5300,5300,5300,5300
箱2(5850~6900):6400,6400,6400,6400
箱3(6900~7950):7250,7250
箱4(7950~9000):8575,8575,8575,8575
2)按箱边界值平滑处理;
箱1(4800~5850):4800,4800,4800,5800,5800,5800
箱2(5850~6900):6000,6000,6800,6800
箱3(6900~7950):7000,7500
箱4(7950~9000):8000,8000,9000,9000
3)按箱中值平滑处理。
箱1(4800~5850):5350,5350,5350,5350,5350,5350
箱2(5850~6900):6400,6400,6400,6400
箱3(6900~7950):7250,7250
箱4(7950~9000):8650,8650,8650,8650
三种方式进行平滑处理:
- 按箱的平均值平滑:箱中每一个值被箱中的平均值替换;
- 按箱的边界值平滑:箱中的最大和最小值被视为箱边界,观察每个数据与箱子两个边界值的差异,用差异较小的那个边界值替换该数据;
- 按箱的中值平滑:箱中每一个值被箱中的中值替换。
中值:一组数中,如果这组数是奇数个,就是指一个从小到大的序列的中间的那一个数;偶数个,中值就是中间两个数的均值。
7.为什么要进行数据预处理?
杂乱性:数据缺乏统一的标准和定义;
重复性:数据库中存在多条完全相同的记录;
不完整性:系统设计中的不合理或者使用工程中造成的属性缺失;
存在噪声:数据收集过程中产生的随机错误。
因为原始数据往往是不完整的,含有噪声的以及不一致的,采用这些数据进行机器学习/数据挖掘往往得到的结果是不准确的。
8.小明想买一双耐克运动鞋,他自己希望的价格最高是890,最低价格是350。现将最高价和最低价映射到区间 [0.0, 1.0] 。试问,他买了价格为760和950的两双鞋在新区间里的值为多少?
价格为760 : X* = (760 - 350) / (890 - 350) = 0.8
价格为950 : X* = (950 - 350) / (890 - 350) = 1.1 (越界)
最大-最小规范化 :X* =(x-min)/(max-min),映射到 [0,1] 之间,若数据集中且某个数值太大,则规范化后各值都接近0,且相差不大;

9. 计算机嵌入161班工作后月收入的均值为8700元,标准差为1800元,使用 零均值规范化方法 将小明月收入9900元映射为多少?
X* = (9900 - 8700)/ 1800 = 0.667
Z-score(零-均值)规范化:X* =(x-mean)/ sigma ,sigma代表标准差,目前用的最多的数据标准化方法;

10.假设计算机嵌入161班40名同学工作后月收入A在6900元到13000元范围里,确定小数定标规范化的系数j的大小和映射区间。
属性值绝对值的最大值为13000,将13000映射到 [-1,1] 之间,需要小数点向左移动5位,映射为0.13.
所以小数定标规范化的系数 j = 5
映射区间为[ 0.069 , 0.13]
小数定标规范化:X* =x /(10^k),通过移动属性值的小数位数,映射到 [-1,1] 之间,移动的小数位数取决于属性值绝对值的最大值

11.数据集X的每一行是一个样本,请写出每个样本中心化后的数据。 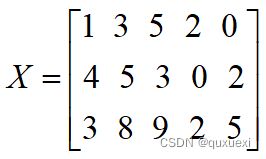
结果:

中心化(零均值化)
所谓中心化,是指变量减去它的均值(即数学期望值)。对于样本数据,将一个变量的每个观测值减去该变量的样本平均值,变换后的变量就是中心化的。