使用 InfoSphere BigInsights 分析社交媒体数据和结构化数据
您可能对大数据以及它对业务分析的影响已经有所耳闻。可能您想知道通过采集、处理和管理从网站、电子传感器或软件日志收集的大数据以及您已经拥有的 传统数据,您的组织可获得哪些洞察。诚然,旨在帮助您解决大数据项目各个方面的开源和第三方项目对您没什么坏处。但大部分项目都是为那些具有特定技能的程 序员、管理员和技术专家而设计的。
如果您希望让业务分析师、业务线领导和其他不是程序员的人使用大数据,那该怎么做呢?BigSheets 值得去了解。它是一个包含在 InfoSphere BigInsights 中的电子表格式工具,支持非程序员以迭代方式浏览、操作和可视化存储在分布式文件系统中的数据。BigInsights 随带的示例应用程序可帮助您从各种来源收集和导入数据。在本文中,我们将介绍 BigSheets 和它随带的两个示例应用程序。
BigInsights 是一个软件平台,可帮助公司发现和分析隐藏在大量各种数据中的业务洞察,这些数据常常被忽略或丢弃,因为使用传统方式处理它们非常不切实际或是困难重重。
为了帮助业务部门高效地从这类数据获取价值,BigInsights Enterprise Edition 提供了多个开源项目(包括 Apache Hadoop)和 IBM 开发的一些技术(包括 BigSheets)。Hadoop 和它的相关项目提供了一个有效的软件框架,以便利用分布式计算环境来实现高可伸缩性的数据密集型应用程序。
IBM 技术使用分析软件、企业软件集成、平台扩展和工具充实了这个开源框架。有关 BigInsights 的更多信息,请参阅 参考资料。BigSheets 是一个基于浏览器的分析工具,最初由 IBM 的 Emerging Technologies 小组开发。如今,BigSheets 包含在 BigInsights 中,使业务用户和非程序员能够浏览和分析分布式文件系统中的数据。BigSheets 提供了一个类似电子表格的界面,所以用户可建模、过滤、组合、浏览从各种来源收集的数据并绘制图表。BigInsights Web 控制台在顶部包含一个用于访问 BigSheets 的选项卡。请参阅 参考资料,了解有关该 Web 控制台的更多细节。
图 1 描绘了 BigSheets 中的一个示例数据集合。尽管它看起来像一个典型的电子表格,但此集合包含向公共网站发布的博客中的数据,而且分析师可单击集合中包含的链接来访问发布源内容的站点。
图 1. 基于社交媒体数据的样例 BigSheets 集合,附带源内容的链接
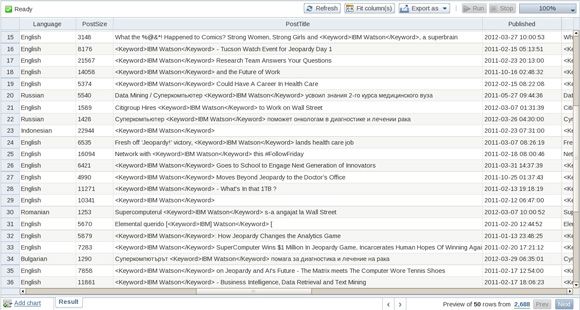
定义一个 BigSheets 集合后,分析师可根据需要过滤或转换该集合的数据。在幕后,BigSheets 会翻译通过一个图形界面表达的用户命令,将它翻译为对基础数据的一个子集执行的 Pig 脚本。分析师可以采用这种方式高效地、迭代式地浏览各种转换。在感到满意后,用户可保存和运行该集合,这会导致 BigSheets 在所有数据集上发起 MapReduce 作业,并将结果写入分布式文件系统,显示新集合的内容。分析师可根据需要对整个数据集进行分页或操作。
BigSheets 随带了一些现成的样例应用程序,业务用户可从 BigInsights Web 控制台启动它们,从网站、关系数据库管理系统 (RDBMS)、远程文件系统和其他来源收集数据。我们将依靠其中两个应用程序来完成这里描述的工作。但是,您一定要认识到的是,程序员和管理员可使用其 他 BigInsights 技术来为 BigSheets 中的后续分析收集、处理和准备数据。这些技术包括 Jaql、Flume、Pig、Hive 和 MapReduce 应用程序等。
IBM Watson
IBM Watson 是一个研究项目,它执行复杂的分析来回答用自然语言表达的问题。Watson 的软件参考从各种来源收集的数据,在一个 IBM Power 750 服务器集群上使用 Hadoop 高效地处理这些数据。IBM Watson 最初在 2011 年的一个电视游戏比赛节目中亮相,击败了两位著名的人类参赛者。请参阅 参考资料 一节,了解 IBM Watson 和 Jeopardy! 游戏节目的更多细节。
在开始之前,让我们看看样例应用程序场景。这涉及到分析有关 IBM Watson 的社交媒体数据,最终将此数据与有关从一个关系 DBMS 提取的媒体推广工作的模拟 IBM 内部数据结合在一起。我们的想法是探索围绕著名品牌、服务或项目的可视性、覆盖范围和 “评论”,这是许多组织中的一种常见需求。我们不会在这里介绍针对这样一个应用程序的所有的分析可能性,因为我们的目的只是强调 BigSheets 的一些关键方面可以如何帮助分析师快速开始处理大数据。但我们将探索的工作有助于您理解只需少量工作即可实现的可能性,这些工作还可能使您对 IBM Watson 的流行性刮目相看。
启动 BigSheets 之前,您的分析需要一些数据。我们首先会查看社交媒体数据的收集。
您可能已经想到,收集和处理从各种社交媒体站点提取的数据可能会非常困难,因为不同的站点会采集不同的信息,采用不同的数据结构。而且,识别和抓取大量站点可能需要很长的时间。
这里,我们使用 BigInsights 随带的 BoardReader 样例应用程序来启动对博客、新闻源、讨论板和视频站点的搜索。 图 2 演示了我们提供给 BigInsights BoardReader 应用程序的输入参数,我们从 BigInsights Web 控制台的 Applications 页面启动该应用程序。如果您还不熟悉 Web 控制台和它的示例应用程序目录。请参阅 参考资料 一节。
图 2. 从 BigInsights Web 控制台调用 BoardReader 应用程序
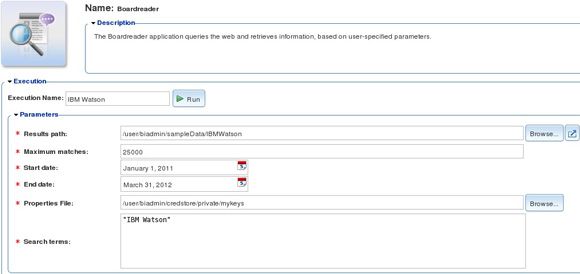
我们简单分析下图 2 中显示的输入参数。Results Path 指定用于应用程序的输出的 Hadoop 分布式文件系统 (HDFS) 目录。后续参数表明我们将返回的结果限制为最大 25,000 个匹配值,将搜索时间段限制为从 2011 年 1 月 1 日到 2012 年 3 月 31 日。Properties File 引用了我们使用 BoardReader 许可密钥填充的 BigInsights 凭据存储。(每个客户必须联系 BoardReader,以获得一个有效的许可密钥。)“IBM Watson” 是我们的搜索主题。
运行该应用程序后,分布式文件系统会在输出目录中包含 4 个新文件,如 图 3 底部所示。
图 3. 存储在 BigInsights 中的应用程序输出
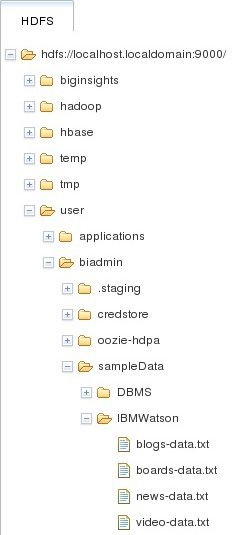
为简便起见,本文会仅使用新闻和博客数据。如果您想了解我们的样例应用程序场景,可使用我们指定的参数执行 BoardReader 应用程序或下载示例数据。请注意,下载内容仅包含 BoardReader 从博客和新闻源收集的信息的子集。具体来讲,我们删除了博客和新闻项的全文本/HTML 内容,以及示例文件中的某些元数据。这里介绍的分析任务不需要使用这些数据,并且我们希望使每个文件的大小保持可管理。
BoardReader 应用程序返回的所有文件都是 JSON 格式的。您可以在 BigInsights Web 控制台的 Files 页面中以文本形式显示此数据的一小部分,但结果难以阅读。稍后您会了解如何将此数据转换为 “表格” 或 BigSheets 数据集合,它们容易浏览得多。但值得注意的是,每个文件都包含稍微不同的 JSON 结构,在建模一个联合了新闻和博客数据集的集合时,需要解决这一问题。在大数据项目中,常常必须以某种方式准备或转换您的数据结构,以便简化后续的分析。
了解了这一社交媒体数据的某些方面后,我们会将它与从一个关系 DBMS 提取的数据结合起来。许多大数据项目都涉及到在现有企业信息(包括存储在一个关系 DBMS 中的数据)上下文中分析新的信息源,比如社交媒体数据。BigInsights 支持连接各种关系 DBMS 和数据仓库,包括 Netezza、DB2®、Informix®、Oracle 和 Teradata 等。
对于我们的示例场景,我们使用有关 IBM 媒体推广工作的模拟数据来填充了一个 DB2 表。将此关系数据与从社交媒体站点提取的信息结合起来,这样做可以为我们提供各种宣传工作的效益和应用返回的一些迹象。尽管 BigInsights 通过一个命令行接口提供了动态关系 DBMS 查询访问,但我们会使用 BigInsights Web 控制台的 Data Import 样例应用程序来提取我们感兴趣的数据。
图 4 给出了我们向此应用程序提供的输入参数。BigInsights 凭据存储中的 mykeys 属性文件包含建议一个数据连接所需的 JDBC 输入参数,包括 JDBC URL(例如 jdbc:db2://myserver.ibm.com:50000/sample)、JDBC 驱动程序类(例如 com.ibm.db2.jcc.DB2Driver)以及 DBMS 用户 ID 和密码。其他输入参数包括一个用于从目标数据库检索感兴趣的数据的简单 SQL SELECT 语句、输出格式(一个逗号分隔的值文件)和存储结果的 BigInsights 输出目录。
图 4. 从 BigInsights Web 控制台调用数据导入应用程序
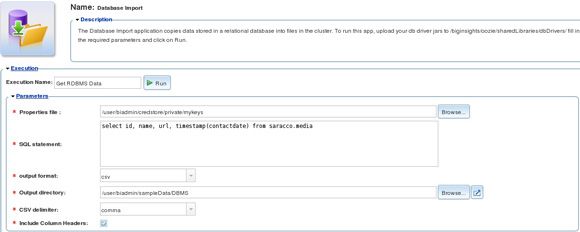
请注意,在执行此应用程序之前,我们会将合适的 DBMS 驱动程序文件上传到所需的 BigInsights 分布式文件系统目录 (/biginsights/oozie/sharedLibraries/dbDrivers) 中。因为 DB2 Express-C 是我们的源 DBMS,所以我们上传了它的 db2jcc4.jar 和 db2jcc_license_cu.jar 文件。
要了解我们的样例应用程序场景中的 DBMS 相关工作,可获取 DB2 Express-C 的一个免费副本(请参阅 参考资料,以获取相关链接),创建和填充一个示例表,并根据描述执行 BigInsights Data Import 应用程序。您还可以下载从 DB2 提取的 CSV 文件,将它直接上传到 BigInsights 中。
要开始使用 BigSheets 分析您的数据,则需要创建集合(电子表格式的结构),在您的分布式文件系统中建模感兴趣 的文件。对于我们的场景,这些文件包含 IBM BoardReader 应用程序生成的基于 JSON 的博客数据、IBM BoardReader 应用程序生成的基于 JSON 的新闻数据,以及从 IBM Data Import 提取的基于 CSV 的数据。
让我们来逐步分析一下创建这样一个集合的基本知识:
- 从 Web 控制台的 Files 页面,使用文件系统导航程序选择 news-data.txt 文件(参见 图 3)。
- 在右侧窗格中,选择 Sheets 按钮,将显示格式从 Text 更改为 Sheets。如 图 5 中所示,此按钮位于 Viewing Size 规范的右侧。
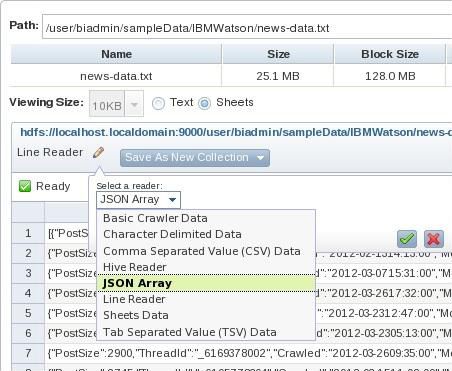
- 为您的文件指定合适的 “阅读器” 或数据格式转换器。同样,如 图 5 中所示,BigSheets 提供了各种内置的阅读器来处理常见的数据格式。对于这个样例文件,JSON Array 阅读器非常适合。
- 保存新集合,将它命名为 “Watson_news”。
图 5. 创建具有合适的 “阅读器” 的集合
按照相同的流程为 blogs-data.txt 文件创建一个独立的集合,将该集合命名为 “Watson_blogs”。最后,为包含 DBMS 数据的 CSV 文件创建第三个集合,选择 BigSheets Comma-Separated Values (CSV) Data 作为此文件的阅读器。将此集合命名为 “Media_Contacts”。
值得注意的是,您可以基于一个目录的内容来创建一个集合,而不用基于单个文件。为此,可使用文件系统导航程序确定目标目录,单击右侧窗格中的 Sheets 按钮,指定要用于该目录中的所有文件的合适阅读器。但是,本文中介绍的应用程序场景需要 3 个独立的集合,如上所述。
在分析数据本身的各个方面之前,分析师常常希望调整其集合的格式、内容和结构。BigSheets 提供了许多宏和函数来支持这类数据准备活动。在本节中,我们将探索其中两个选项:通过删除列来消除不必要的数据,通过联合操作来整合来自两个集合的数据。
BigInsights BoardReader 应用程序返回填充每个 BigSheets 集合中的各列的新闻和博客数据。我们仅需要使用这些列中的一部分来执行本文中将要讨论的分析工作,所以一个重要的早期步骤是创建仅保留我们想要的列的新集合:
- 从 BigSheets 主页中,打开您从 news-data.txt 文件创建的 Watson_news 集合。
- 单击 Build New Collection。
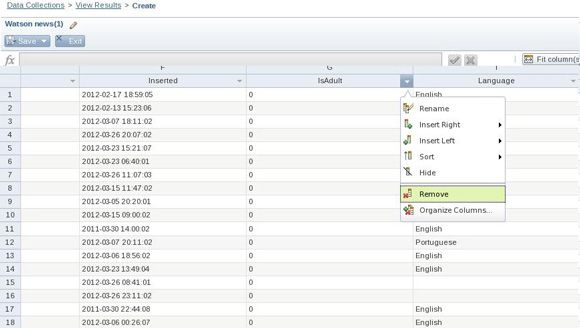
- 导航到 IsAdult 列,如 图 6 所示。单击列标题中的下拉简单并删除该行。对集合中除 Country、FeedInfo、Language、Published、SubjectHtml、Tags、Type 和 Url 以外的所有列这么做。
- 保存并退出,将新集合命名为 “Watson_news_revised”。在系统提示您时,运行该集合。请注意,Run 按钮右侧的状态栏可用于监视作业的进度。(在幕后,当您运行一个集合时,BigSheets 会执行启动了 MapReduce 作业的 Pig 脚本。您可能已经想到,运行时性能依赖于与集合关联的数据量和可用系统资源。)
图 6. 从集合中删除一列
因为我们最终希望将博客和新闻数据合并到单个集合中,以便进行进一步的分析,所以我们采用了相同的方法创建一个仅包含 Country、FeedInfo、Language、Published、SubjectHtml、Tags、Type 和 Url 列的新博客数据集合。将新博客集合命名为 “Watson_blogs_revised”。
接下来,将新编辑的集合(Watson_news_revised 和 Watson_blogs_revised)合并到一个集合中,这个集合将用作探索 IBM Watson 的聚合的基础。为此,需要使用 BigSheets 联合运算符。请注意,这要求所有表格都具有相同的结构。如果遵循前一节中的说明,那么您会有两个这样的集合要合并,每个集合具有 Country、FeedInfo、Language、Published、SubjectHtml、Tags、Type 和 Url 列(按此顺序)。
要合并集合,请执行以下操作:
- 打开 Watson_news_revised 集合并单击 Build New Collection。
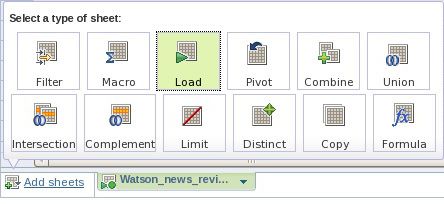
- 单击 Add sheets > Load 向您的工作模型添加另一个集合的内容。(参见 图 7。)在系统提示您时,选择 Watson_blogs_revised collection,将您的表格命名为 “Blogs”,单击绿色勾选标记,以便应用该操作。
图 7. 准备将一个集合加载到一个新表格中
- 检查您的显示,其中会包含这个新表格。请注意,左下角包含一个针对它的新选项卡。(参见 图 8。)
图 8. 检查一个新表格
- 单击 Add sheets > Union 创建另一个表格来联合博客数据和新闻数据。在系统提示您时,单击下拉菜单并选择 Watson_news_revised 作为您将与刚加载的博客数据合并的表格。(参见 图 9。)单击该框下方的加号 (+),然后单击底部的绿色勾选符号来开始联合。
图 9. 指定用于联合的表格
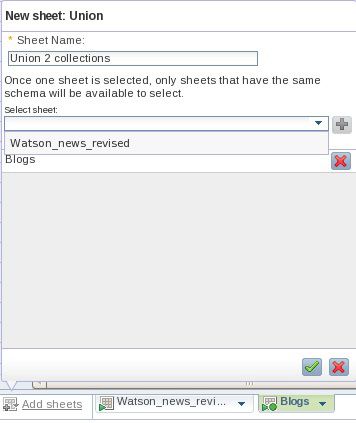
- 保存并退出,将新集合命名为 Watson_news_blogs。运行该集合。
接下来,分析这个新集合中的数据。
第 4 步:浏览一个集合已分析 IBM Watson 的全球覆盖率
我们希望探索的一个区域涉及到 IBM Watson 的全球关注和应用范围。最初,您可能倾向于按国家列的值对 Watson_news_blogs 集合进行排序。但是,如果检查该数据,您会注意到,许多行的这一列包含 null 值。这是从社交媒体站点和其他来源收集的数据的典型情况。想要的数据常常是缺失的,这迫使分析师考虑通过其他方法从关注区域获取洞察。
我们的大部分博客和新闻消息都表明了来源语言,所以我们将按语言和类型对记录进行排序,以帮助我们了解 IBM Watson 在新闻和博客帖子中的全球覆盖率:
- 打开 Watson_news_blogs 集合并单击 Build New Collection。
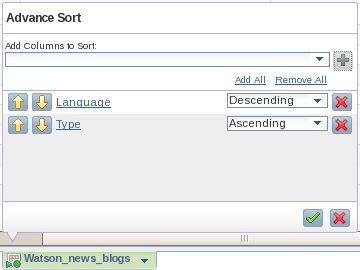
- 从 Language 标题展开下拉菜单并单击 Sort > Advanced。在系统提示您时,从 Add Columns to Sort 菜单中选择 Language 和 Type 列。将 Language 的排序值更改为 Descending 并验证 Language 是否是主要的排序列,如 图 10 所示。单击绿色箭头对您数据的一个子集应用该操作。
图 10. 准备通过两列对一个集合进行排序,并使用 Language 作为主要列
- 检查显示的 50 条示例记录并注意标出的各种语言。
- 保存并退出您的集合,将它命名为 Watson_sorted。然后对整个数据集运行该集合。当检查返回的结果时,您会看到针对特定语言(比如 Vietnamese)的比前一步更多的记录。
尽管您可对集合分页来探索 IBM Watson 在各种语言中的覆盖范围,但可视化全球 “评论” 的最简单方式可能是制作结果图表。这么做可提供一个大视图,它可为进一步的探索和分析工作带来灵感。BigSheets 支持各种不同的图表类型,包括条形图、饼图和标记云等。在这里,我们会使用一种简单的饼图:
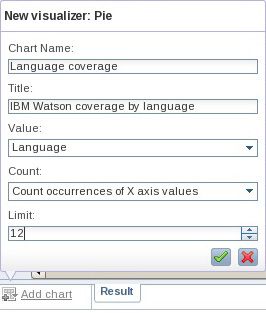
- 打开 Watson_sorted 集合后,单击 Add chart > Chart > Pie。(Add chart 选项卡位于 Result 选项卡下方的集合的左下角。)
- 在系统提示您时,为表格名称和标题提供您选择的值。选择 Language 列作为您想要制作图表的列,将 Count 字段设置为它的默认值。将 Limit 值重设为 12,使饼图能够反映集合中最常出现的 12 种语言的数据。参见 图 11。
图 11. 用于创建一个饼图的输入参数
- 单击绿色勾选标记并在提示时运行图表。
正如您所期望的,最终的饼图表明,我们收集的近 79% 的新闻和博客数据都是使用英文发布的。但您能猜到 IBM Watson 的下一种最流行的语言是什么吗?图 12 中的饼图表明它是俄语。通过将鼠标悬停在 BigSheets 中显示的一个饼图的任何一个扇区上,您可确定它的基础值(在本例中为 Language 列的值)。
图 12. 基于可用的新闻和博客数据,按照语言测量 IBM Watson 的全球关注度
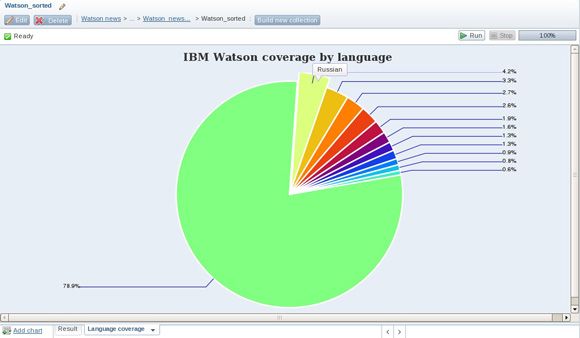
如果将鼠标悬停在图 12 中所示的饼图的第 5 和第 6 个最大的扇区(所占百分比为 2.6% 和 1.9%)上,您会发现它们都是中文的变体。这演示了另一种涉及从各种数据来源(比如不同社交媒体站点)收集的数据的常见情形,您希望同等对待的数据值在 表示上通常会有一定的差别。
让我们看看如何使用 BigSheets 修改这些值,将中文的变体替换为单一值 “Chinese”:
- 如果需要,请打开 Watson_sorted 集合并单击 Edit 按钮(左上角的集合名称下方)。
- 导航到 Language 列并单击列标题中的向下箭头,以展开下拉菜单。选择 Insert Right > New Column 创建一个新列来保存清理的数据。在系统提示您时,将新列命名为 LanguageRevised,单击绿色勾选标记完成该操作。
- 将光标放在 LanguageRevised 列上,在表格顶部的 fx(公式规范)框中输入以下公式:
IF(SEARCH('Chin*', #Language) > 0, 'Chinese', #Language)。参见 图 13。
图 13. 指定一个公式来获取一列的值

此公式导致 BigSheets 在表格的 Language 列中搜索以 “Chin” 开头的值。当它找到这些值时,会将 “Chinese” 写入 LanguageRevised 列中;否则,它会将在 Language 列中找到的值复制到 LanguageRevised 列中。BigInsights InfoCenter(包含在 参考资料 一节中)包含有关定义 BigSheets 公式的详细信息。单击绿色勾选标记应用该公式。 - 保存并退出您的工作。在出现有关数据不同步的警告时,运行此集合的修订后的定义。
- 基于 LanguageRevised 列中的值创建一个包含 12 个扇区的新饼图,将结果与您之前创建的饼图进行比较(基于 Language 列中的 “原始” 数据)。请注意,您的新饼图表明,“Chinese” 是第二种最常见的语言,之后是俄语、西班牙语和德语。
您刚检查的数据可能会引起许多需要进一步分析的问题。这是一种非常典型的大数据分析,它实质上通常是迭代式和探索式的。我们会更深入分析基于英语的新闻和博客帖子中的 IBM Watson 覆盖率,尝试查明它在英国的覆盖率。
与本文的介绍性性质一致,我们将采用一种简单的方法来分析此主题。具体来讲,我们将从 Watson_sorted 集合派生出一个新集合,该集合保留了具有以 “.uk” 结尾的 URL 域名或 Country 值 “GB”(表示大不列颠)的英语语言记录。为实现此目的,我们需要使用 BigSheets Filter 操作符和宏,从一个完整的 URL 字符串提取 URL 主机数据:
- 打开 Watson_sorted 集合并构建一个新集合。
- 添加一个采用 Filter 操作的表格。
- 在系统提示您时,选择 Match all 并在下拉菜单框中将 Language 指定为 English,如 图 14 中所示。然后单击绿色勾选标记,以便将该操作应用到集合数据的一个子集。
图 14. 基于一个列值的过滤
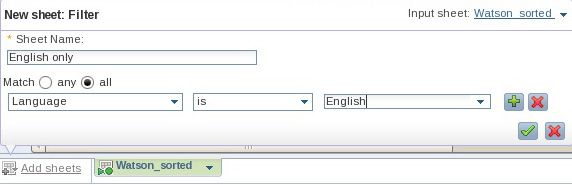
- 保存您的工作(将表格命名为 Watson_sorted_English_UK),但不要退出,因为您将继续细化此集合。
- 添加另一个调用一个宏的表格。在系统提示您时,单击 Categories > url > URLHOST。 选择集合的 URL 列作为包含 URL 值的目标列。(该宏将读取此列中的值并从较大的字符串中提取 URL 主机信息。例如,给定一个 URL 值 “http://www.georgeemsden.co.uk/2011/09/how-long-before-your-laptop- finds-a-cure-for-cancer/”,该宏将返回 “www.georgeemsden.co.uk” 作为 URL 主机名。)
- 单击窗格底部的 Carry Over 选项卡,如 图 15 所示。这很重要,因为它使您能够指定希望保留(或 “处理”)现有集合的哪些列。
图 15. 使用 URLHOST 宏
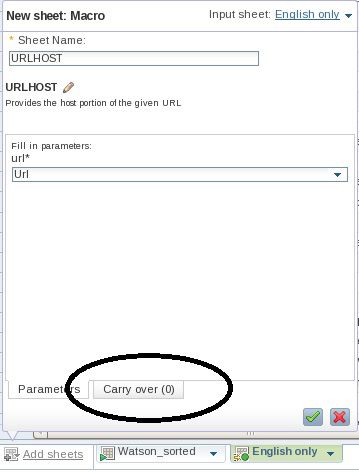
- 单击 Add all 以保留所有现有的列并应用该操作。保存您的工作,但不要退出。
- 添加另一个表格来进一步过滤数据。在系统提示您时,匹配以下两个条件中的任何一个:“URLHOST 以 uk 结尾” 和 “Country 为 GB”,如 图 16 中所示。(考虑到此集合的数据的稀疏性,我们需要匹配其中一个条件来检测位于英国的 URL 主机站点。)请应用该操作。
图 16. 基于两个列值来过滤数据
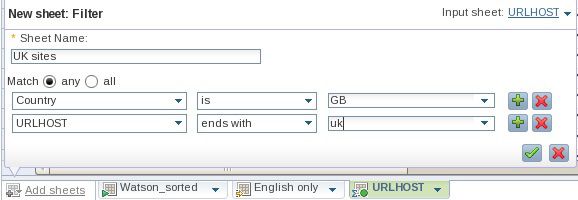
- 保存并退出集合,然后运行它。
按 URLHOST 列对结果进行排序,或者绘制一个图表,这会使您能够快速识别结果集合中的哪些英国站点最常使用 IBM Watson。例如,图 17 显示了我们为前 10 个这类站点生成的一个标记云图表。与任何 BigSheets 标记云一样,更大的字体表明该数据值出现的次数更多,将鼠标悬停在一个数据值上会显示它在集合中出现的次数。
图 17. 10 大使用 IBM Watson 的英国站点

在结束对 BigSheets 的介绍之前,让我们看看涉及我们的示例数据集的其他一些有趣区域:
- 使用 IBM Watson 的不同站点数量和前 12 个使用 IBM Watson 的全球站点。要完成此任务,则需要引入更多的宏和另一种图表类型。
- 作为 IBM 媒体推广工作的主题的站点覆盖率。为了完成此任务,我们会将从一个关系数据库提取的数据与 BigInsights 中的社交媒体数据结合起来。(对于本文,我们创建了有关 IBM 公共关系工作的虚构数据。)
最后,我们将探讨如何将一个集合的内容导出为一个可供第三方应用程序轻松使用的流行数据格式。
评估一项媒体推广活动的效益的一个方面涉及到评估覆盖广度。在本例中,您将使用 BigSheets 确定使用 IBM Watson 的不同的新闻和博客站点的数量。
- 打开 Watson_news_blogs 集合并构建一个新集合。
- 添加一个名为 “Url Hosts” 的表格,它使用 URLHOST 宏从 URL 列中提取的完整字符串中提取 URL 主机名。仅处理 URL 列。(如果需要,请参阅 第 4 步 中的说明,了解 URLHOST 宏的详细信息。)
- 添加另一个表格,对刚创建的表格应用 Distinct 操作符。
- 保存并退出此集合,在系统提示您时运行它。您可以看到有 2,800 多个不同的站点,如 图 18 右下角所示。如果打开 Watson_news_blogs 集合,您会看到总共有超过 7,200 条记录。
图 18. 确定不同主机站点的数量
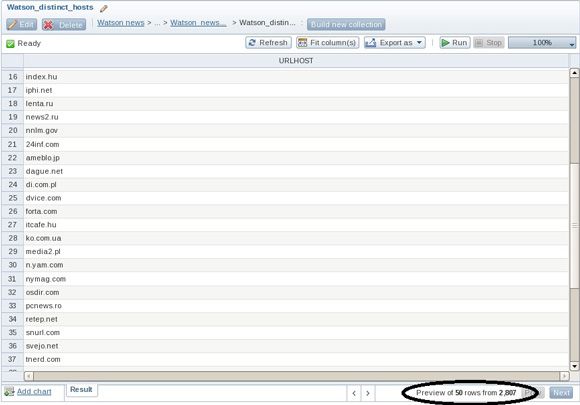
现在您已经知道,一些站点包含多个帖子,您可能希望确定包含有关 IBM Watson 的最多帖子的前 12 个站点,在一个条形图中可视化该结果。这很容易完成,而且结果可能会令您大为惊讶:
- 如果有必要,请打开您刚创建的集合。
- 单击 Add chart > Chart > Column。为图表名称和标题提供您选择的值。保留 X 轴和 Y 轴的默认值。将限制设置为 12。应用这些设置并运行图表。图 19 演示了这些结果。如果您预测 IBM 或 IBM 赞助的站点位于前 3 名,那就错了。
图 19. 基于帖子数量制作使用 IBM Watson 的前 12 个站点的图表
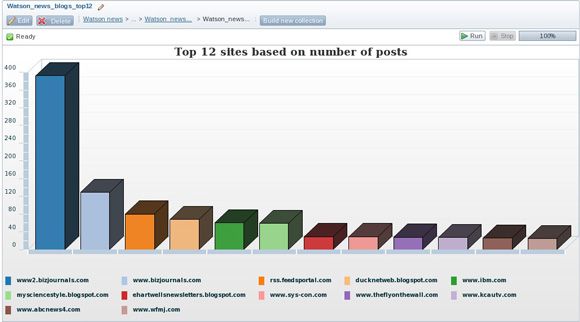
如果检查前两个站点的 URL,您就会了解到它们是 bizjournals.com 的变体,这表明您可能希望返回该集合并转换或清理此数据。前面已经提到过,大数据分析常常需要对数据进行迭代式探索、处理和细化。
最后,确定前 12 个站点可能会让您非常关注每个 URL 主机站点的帖子数量。在这个示例的最后,我们实现了一种轻松方法来获取该信息:
- 如果需要,请打开集合并编辑它。
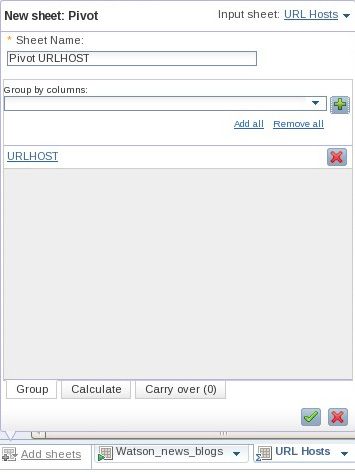
- 单击 Add Sheet > Pivot。将该表格命名为 “Pivot”,并确定使用 URL 主机表格作为输入表格,选择 URLHOST 作为 pivot 列。参见 图 20。
图 20. 创建一个 Pivot 表格来保存聚合的数据
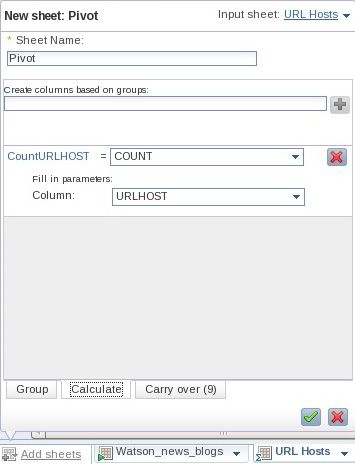
- 单击菜单底部的 Calculate 选项卡。指定一个包含聚合的数据的新列的名称(例如 CountURLHOST),单击加号 (+)。对于新列的值,i请选择 COUNT 并确定使用 URLHOST 作为计数操作的目标列。(参见 图 21。)
图 21. 指定新 Pivot 表格的初始计算参数
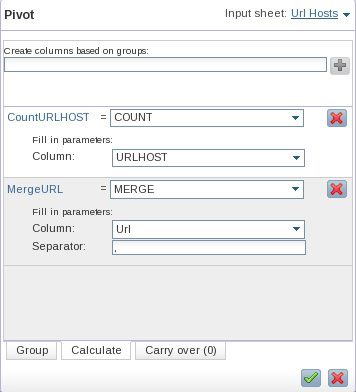
- 仍在 Calculate 选项卡上创建另一个名为 MergeURL 的列,用它来保存与集合中第一列中的 URLHOST 值关联的完整 URL 的合并列表。该列表可能会在以后带来方便。要生成此列表并将它作为新列包含在结果集合中,可单击加号,选择 MERGE 作为新列的值,选择 Url 作为目标列,使用逗号 (,) 作为字段分隔符。确认您的计算规范类似于 图 22 并应用该操作。
图 22. 向您的 Pivot 表格添加另一个计算
- 如果需要,请按降序对聚合的列 (CountURLHOST) 中的值进行排序。
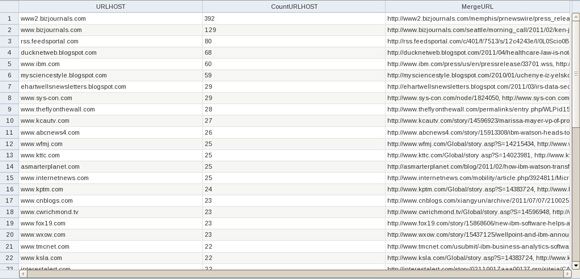
- 保存并退出该集合,然后运行它。浏览结果,其中一部分如 图 23 中所示。
图 23. 检查 Pivot 表格中包含的聚合数据
直到现在,我们的 BigSheets 工作仅涉及到从外部站点收集的数据。但是,许多大数据项目需要将外部数据与内部企业数据相结合,比如关系 DBMS 中的数据。在本节中,您将使用 BigSheets 合并两个集合:一个集合用于建模社交媒体数据,一个集合用于建模关系数据。通过合并这两个集合,您将能够了解企业媒体推广工作与第三方网站的覆盖率之间的 关联。请注意,我们在本文中以 CSV 文件形式提供的示例关系数据包含有关 IBM 媒体联系人的模拟信息。以下是合并集合和可视化结果的方式:
- 打开 Watson_news_blogs 集合并构建一个新集合。
- 使用 URLHOST 宏添加一个表格来提取主机名信息。保留所有现有的列并将该表格命名为 URLHOST。
- 添加另一个表格,该表格会基于导入的 RDBMS 数据来加载您之前构建的 Media_Contacts 集合。(在 第 2 步 中已经创建了此集合。)将这个新表格命名为 Contacts。
- 将 Contacts 表格的最后一列命名为 LastContact。(此列是通过对原始 RDBMS 数据调用
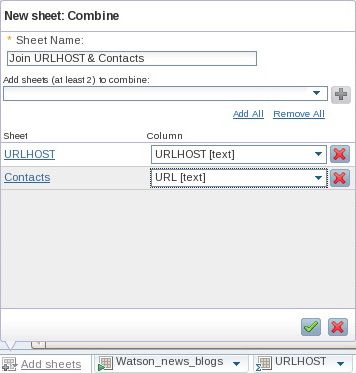
SQL TIMESTAMP()函数来生成的。它的值表明了最后联系目标媒体提供者的时间。) - 添加另一个表格,该表格会分别基于 URLHOST 和 URL 列的值来组合 URLHOST 和 Contacts 表格(参见 图 24)。将这个新表格命名为 Combine。
图 24. 组合(合并)来自两个表格的数据
- 为了简化对结果的检查,删除来自 Media_Contacts 表格的 ID 和 URL 列。重新组织剩余的列,按照一种更加直观的顺序来显示它们,比如 URLHOST、NAME、Published、LastContact、FeedInfo、Country、Language、 SubjectHtml、Tags、Type 和 Url。
- 保存该集合并运行它。浏览结果或为它们制作图表(如果需要)来评估每个目标媒体站点的帖子数量。(图 25 描绘了一个总结此数据的水平条形图。)
图 25. 评估各种站点上有关 IBM Watson 的帖子数量

在某些情况下,您的 BigSheets 分析的结果可能对下游应用程序或无权直接使用 BigInsights 的同事非常有用。幸运的是,您可以轻松地将一个或多个集合导出为流行的数据格式。只需打开目标集合并使用 Export As 函数(位于 Run 按钮左侧),选择 JSON、CSV、ATOM、RSS 或 HTML 作为目标格式。结果会显示在您的浏览器中,您可以将输出保存到本地文件系统中。
现在,您对 BigSheets 的功能有了一定的了解。希望您已了解了内置的宏、函数和操作符如何使您能够浏览、转换和分析各种形式的大数据,而无需使用 Java™ 或脚本语言编写代码。
尽管我们会尽量让场景变得简单一些,使您能快速掌握 BigSheets 的基础知识,但此技术(和补充性的 BigInsights 技术)的功能远不是一篇介绍性文章所能涵盖的。例如,许多社交媒体分析项目都需要深入分析帖子的内容,以评估态度,对内容进行分类,消除错误肯定等。一些 工作需要从文本数据提取上下文,BigInsights 的另一个组件提供了这项功能(这将是另一篇文章的主题)。幸运的是,这些文本分析功能可通过自定义插件与 BigSheets 结合使用。
此外,某些分析任务可能需要使用某种查询语言来轻松表达各种条件,处理和转换嵌套的数据结构,应用复杂的条件逻辑结构等。 BigInsights 确实包含 Jaql(一种基于 JSON 的查询语言),程序员常常使用它为 BigSheets 中的后续分析读取和准备数据。未来的一篇文章将会继续探讨 Jaql。
本文探讨了 BigInsights 如何支持业务分析师处理大数据,而无需编写代码或脚本。具体来讲,本文介绍了两个用于收集社交媒体数据和 RDBMS 数据的样例应用程序,解释了分析师如何使用 BigSheets(一种为业务分析师设计的电子表格式工具)来建模、操作、分析、组织和可视化此数据。为了简便起见,本文仅探讨了 BigSheets 操作符和函数的一个子集,主要介绍与我们涉及 IBM Watson 的样例应用程序场景最相关的操作符和函数,IBM Watson 是一个使用 Apache Hadoop 执行复杂分析来回答用自然语言表述的问题的项目。
如果您已准备好开始实现大数据项目,请参阅 参考资料 一节,获取软件下载、在线培训和与 BigInsights 相关的其他材料的链接。
特别感谢 Stephen Dodd(Effyis Inc. 副总裁)授权我们让样例 BoardReader 输出数据可下载供本文使用。还要感谢 IBM 的 Diana Pupons-Wickham 和 Gary Robinson 对本文的审核。