Python3 函数式编程
Python3 函数式编程
目录
- 函数式编程
- 高阶函数
- map
- reduce
- filter
- 返回函数
- 匿名函数(lambda)
- 装饰器
- 参考资料
相关知识:函数内部的变量在函数执行完后就销毁;Python中一切皆变量。
函数式编程概念
- 函数式编程是一种抽象程度很高的编程范式,纯粹的函数式编程语言编写的函数没有变量,因此任意一个函数,只要输入是确定的,输出就是确定的。
- 函数式编程的一个特点就是,允许把函数本身作为参数传入另一个函数,还允许返回一个函数!
- Python 对函数式编程提供部分支持。由于 Python 允许使用变量,因此,Python 不是纯函数式编程语言!
函数是第一类对象
所谓第一类对象,意思是可以用标识符给对象命名,并且对象可以被当作数据处理,例如赋值、作为参数传递给函数,或者作为返回值return等。
高阶函数概述
高阶函数(Higher-order function),由于在 Python 中,变量可以指向函数,函数的参数能接收变量,那么一个函数就可以接受另一个函数作为参数。一个函数可以接收另一个函数作为参数,这种函数就称之为高阶函数。一个简单例子如下:
def add(x, y, f=abs): # abs作为内建函数BIF,不带括号时直接将函数本身赋值给变量
return f(x) + f(y)
add(5.6, 7.9) # 输出13.5
其他好多语言是无法直接传递函数作为参数到另外一个函数,要用到函数指针,而Python可以直接传递一个函数进来。
常用内建高阶函数
python3内建map()/reduce()函数- 内建
filter()函数用于过滤序列 sorted()函数用于排序- 返回函数,函数作为返回值,比如闭包
- 匿名函数,不需要显示地定义函数,
lambda表达式构建匿名函数 - 装饰器,函数嵌套函数,装饰器的功能在于代码运行期间动态增加函数功能
- 偏函数,用于固定住原函数的部分参数,从而在调用时更简单
满足以下两点任意一点的函数,就称之为高阶函数
- 参数是函数。
- 返回值是函数。
内建函数 map
map函数接收两个参数,一个是函数,一个是可迭代对象(Iterable),map将传入的函数依次作用到序列的每个元素,并把结果作为一个新的Iterator返回。
- 可以直接作用于 for 循环的对象统统称为可迭代对象:
Iterable - 可以被 next() 函数调用并不断返回下一个值的对象称为迭代器:
Iterator - 生成器都是 Iterator 对象,但
list、 dict、 str虽然是 Iterable,却不是 Iterator。
Python 的 Iterator 对象表示的是一个数据流, Iterator 对象可以被 next() 函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration 错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过 next() 函数实现按需计算下一个数据,所以 Iterator 的计算是惰性的,只有在需要返回下一个数据时
它才会计算。
代码实例如下:
list(map(str, [ 1, 3, 5, 7, 9])) # 输出 ['1', '3', '5', '7', '9']
内建函数 reduce
reduce 把一个函数(这个函数必须要可以接收两个参数)作用在一个序列[x1, x2, x3, …]上,这个函数必须接收两个参数, reduce 把结果继续和序列的下一个元素做累积计算,效果等同于:reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3),x4)。
实例代码如下:
from functools import deduce
def fn(x,y):
return x*10+y
reduce(fn, [1, 3, 5, 8]) # 输出1358
map和reduce函数结合使用,构建 str2int 函数(字符串转为整数),代码如下:
from functools import reduce
def str2int(s):
def add(x, y):
return x*10 + y
def char2num(s):
return {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9}[s]
return reduce(add, map(char2num, s))
str2int('2323') # 输出2323
内建函数 filter
python 内建的filter()函数用于过滤序列。和 map、reduce函数类似,filter()函数也接收一个函数和一个序列。和 map()不同的时,filter() 把传入的函数依次作用于每个元素,然后根据返回值是 True (1) 还是 False (0) 决定保留还是丢弃该元素。
代码实例如下:
def is_odd(n):
return n % 2 == 1
list(filter(is_odd, [1, 3, 8, 9, 11])) # 输出[1, 3, 9, 11]
用 filter 方法求素数
代码使用的算法是埃氏筛法,算法理解起来非常简单,原理如下:
首先,列出从 2 开始的所有自然数,构造一个序列:
2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, …
取序列的第一个数 2,它一定是素数,然后用 2 把序列的 2 的倍数筛掉:
3, , 5, , 7, , 9, , 11, , 13, , 15, , 17, , 19, , …
取新序列的第一个数 3,它一定是素数,然后用 3 把序列的 3 的倍数筛掉:
5, , 7, , , , 11, , 13, , , , 17, , 19, , …
不断筛下去,就可以得到所有的素数。
程序如下:
# 定义一个从3开始的奇数生成器,
def _odd_iter():
n = 1
while True:
n = n + 2
yield n
# 定义一个筛选函数
def _not_divisible(n):
return lambda x: x % n > 0
# 定义一个生成器,不断返回下一个素数
def primes():
yield 2
it = _odd_iter() # 初始序列
while True:
n = next(it) # 返回序列的第一个数
yield n
it = filter(_not_divisible(n), it) # 构造新序列
# 打印 1000 以内的素数:
for n in primes():
if n < 1000:
print(n)
else:
break
输出结果如下:
2
3
5
7
11
13
17
19
…
997
注意:filter() 函数返回的是一个 Iterator,也就是一个惰性序列,所以要强迫 filter() 完成计算结果,需要用 list() 函数获得所有结果并返回 list。
filter 小结
filter() 的作用是从一个序列中筛出符合条件的元素。由于 filter() 使用了惰性计算,所以只有在取 filter() 结果的时候,才会真正筛选并每次返回下一个筛出的元素。
返回函数
一个函数可以返回一个计算结果,也可以返回一个函数,可以返回函数的函数称为返回函数(有点绕)。返回函数的实例代码如下:
def lazy_sum(*args):
def squre_sum():
ax = 0
for n in args:
ax = ax + n*n
return ax
return squre_sum
调用lazy_sum()时,返回的不是求平方和结果(变量),而是求平方和函数,调用函数f时,才真正计算求平方和的结果,如下所示:
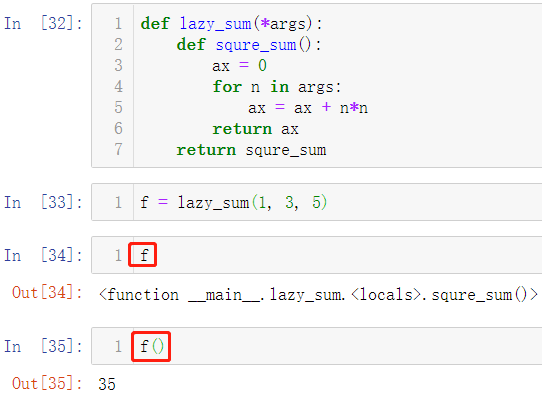
在这个实例中,内部函数 squre_sum 可以引用外部函数 lazy_sum的参数和局部变量,当 lazy_sum 返回函数 squre_sum 时,相关参数和变量都保存在返回的函数中,这种称为闭包。返回函数利用到闭包的特性。
闭包
闭包(closure)是函数式编程的重要的语法结构。函数式编程是一种编程范式 (而面向过程编程和面向对象编程也都是编程范式)。在面向过程编程中,我们见到过函数(function);在面向对象编程中,我们见过对象(object)。函数和对象的根本目的是以某种逻辑方式组织代码,并提高代码的可重复使用性(reusability)。闭包也是一种组织代码的结构,它同样提高了代码的可重复使用性。
一个函数和它的环境变量合在一起,就构成了一个闭包 (closure)。在 Python 中,所谓的闭包是一个包含有环境变量取值的函数对象。环境变量取值被保存在函数对象的 closure 属性中。我的对闭包的理解,闭包可以实现函数和函数之外变量(环境变量)的打包。闭包实例代码如下:
def line_conf():
b = 15 # environment variable
def line(x):
return 2*x+b
return line # return a function object
b = 5
my_line = line_conf()
print(my_line.__closure__)
print(my_line.__closure__[0].cell_contents)
程序输出如下:
(| ,)
15
| 匿名函数(lambda)
- 只能写在一行上。
- 前面是参数,后面是表达式。表达式作为返回值。
匿名函数如何使用:
- 匿名函数通常和高阶函数配合使用,作为参数传入,或者作为返回值返回
- 一些短小的函数,我们就可以写匿名函数,而不用写好几行代码,一行匿名函数就够了。
装饰器
想要动态给函数添加功能时,我们要用到装饰器的知识,装饰器decotrator本质上就是一个返回函数的高阶函数,实例如下:
def log(func):
def wrapper(*args, **kw):
print('call %s():' % func.__name__)
return func(*args, **kw)
return wrapper
@log
def now():
print('2015-3-25')
调用 now()函数,不仅会运行 now()函数本身,还会在运行 now()函数前,打印一行装饰器函数输出的日志,如下:
>>> now()
execute now():
2015-3-25
装饰器总结
在面向对象(OOP)的设计模式中, decorator 被称为装饰模式。OOP的装饰模式需要通过继承和组合来实现,而 Python 除了能支持 OOP 的 decorator 外,直接从语法层次支持 decorator。 Python 的 decorator 可以用函数实现,也可以用类实现。
参考资料
- 《python3教程》-廖雪峰
- 高阶函数、闭包、偏函数、柯里化、匿名函数
- Python深入04 闭包