深度学习之基于CNN实现天气识别
其实和猫狗大战还有上一篇博客的代码差不太多,但是中间出现了新的问题。
1.导入库
import numpy as np
import tensorflow as tf
import os,PIL
import random
import pathlib
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from keras.utils import np_utils
2.加载数据
本环节就是将训练集和测试集的数目,还有路径统计出来。方便后面利用网络进行训练。
dataset_url = "E:/tmp/.keras/datasets/weather_photos"
dataset_dir = pathlib.Path(dataset_url)
train_rain = os.path.join(dataset_dir,"train","rain")
train_shine = os.path.join(dataset_dir,"train","shine")
train_cloudy = os.path.join(dataset_dir,"train","cloudy")
train_sunshine = os.path.join(dataset_dir,"train","sunrise")
test_rain = os.path.join(dataset_dir,"test","rain")
test_shine = os.path.join(dataset_dir,"test","shine")
test_cloudy = os.path.join(dataset_dir,"test","cloudy")
test_sunshine = os.path.join(dataset_dir,"test","sunrise")
train_dir = os.path.join(dataset_dir,"train")
test_dir = os.path.join(dataset_dir,"test")
#统计训练集和测试集的数据数目
train_rain_num = len(os.listdir(train_rain))
train_shine_num = len(os.listdir(train_shine))
train_cloudy_num = len(os.listdir(train_cloudy))
train_sunrise_num = len(os.listdir(train_sunshine))
train_all = train_cloudy_num+train_sunrise_num+train_shine_num+train_rain_num
test_rain_num = len(os.listdir(test_rain))
test_shine_num = len(os.listdir(test_shine))
test_cloudy_num = len(os.listdir(test_cloudy))
test_sunrise_num = len(os.listdir(test_sunshine))
test_all = test_cloudy_num+test_sunrise_num+test_shine_num+test_rain_num
3.超参数的设置
epochs的次数是不固定的,可以自己设置。
batch_size = 32
epochs = 20
height = 180
width = 180
4.数据集预处理
其中包括:归一化,调整图片大小,打乱顺序等
train_generator = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1.0/255)
test_generator = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1.0/255)
train_data_gen = train_generator.flow_from_directory(
batch_size=batch_size,
directory=train_dir,
shuffle=True,
target_size=(height,width),
class_mode="categorical"
)
test_data_gen = test_generator.flow_from_directory(
batch_size=batch_size,
directory=test_dir,
shuffle=True,
target_size=(height,width),
class_mode="categorical"
)
5.搭建网络&&训练模型
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(16,3,padding="same",activation="relu",input_shape=(height,width,3)),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32,3,padding="same",activation="relu"),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(64,3,padding="same",activation="relu"),
tf.keras.layers.AveragePooling2D((2,2)),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128,activation="relu"),
tf.keras.layers.Dense(4,activation='softmax')
])
model.compile(optimizer="adam",
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=["acc"])
history = model.fit_generator(train_data_gen,
steps_per_epoch=train_all//batch_size,
epochs=epochs,
validation_data=test_data_gen,
validation_steps=test_all//batch_size)
所出现的问题就在这里,之前的池化方法都是选择的Max-Pooling,但是单纯的用Max-Pooling,实验效果如下所示:
epochs为20时:
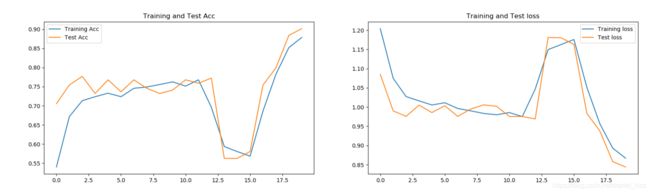
整体趋势是呈现上升的,但是在epochs为13的时候,出现了骤降的现象。
epochs为50时:
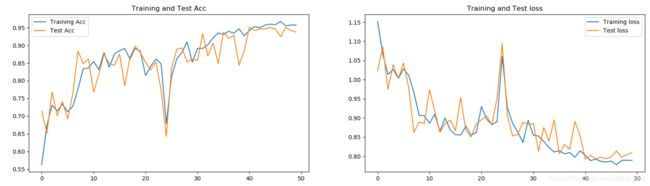
也存在同样的现象。
尝试将所有的池化方法改成Average-Pooling。
epochs为20时的实验效果:
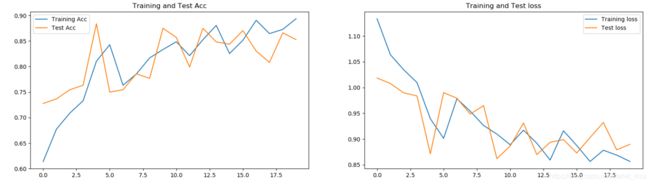
不会出现那样的骤降现象,但是整体呈现波动的趋势。
尝试前两次的池化方法采用Max-Pooling方法,第三次的池化方法采用Average-Pooling方法。
epochs为20时的实验效果:
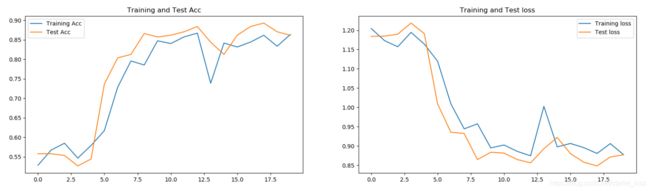
也存在波动的现象,但是相比于之前的两种方法,得到了改善。
使用Max-Pooling和Average-Pooling的情况分别是什么呢?
①Max-Pooling
在目标对象是偏向于纹理、轮廓时,选用Max-Pooling较好。
②Average-Pooling
在目标对象时偏向于背景或其他信息时,选用Average-Pooling较好。
Max&&Average
③可以在较浅层使用Max-Pooling,用来过滤无用的信息;在较深层使用Average-Pooling,防止丢掉太多高维信息。
天气识别,背景信息比较重要,所以使用Average-Pooling方法比较合适。
努力加油a啊