redis作为MongoDB的缓存在线实时去重
一、背景原理
部分内容参考基于python的MySQL和redis数据同步实现(redis做缓存)
这个说的真的很清楚,但缺少实际的案例
1、MongDB 数据库
MongDB是一种非关系型数据库,主要用于存放持久化数据,将数据存储在硬盘中,读取速度较慢。每次请求访问数据库时,都存在着I/O操作,如果反复频繁的访问数据库:会在反复链接数据库上花费大量时间,从而导致运行效率过慢;反复的访问数据库也会导致数据库的负载过高。所以,针对MongDB的缺点,衍生出了缓存的概念。
2、redis数据库
redis是一款非关系型数据库,是一种缓存数据库,数据存放在内存中,用于存储使用频繁的数据,这样减少访问数据库的次数,提高运行效率。所以redis数据库读取速度比较快,运行效率高。
3、二者区别与联系
(1) 作用:MongDB用于持久化的存储数据到硬盘,功能强大,速度较慢,基于磁盘,读写redis快,但是不受空间容量限制,性价比高;redis用于存储使用较为频繁的数据到缓存中,读取速度快,基于内存,读写速度快,也可做持久化,但是内存空间有限,当数据量超过内存空间时,需扩充内存,但内存价格贵;
(3) 需求:MongDB和redis因为需求的不同,一般都是配合使用。需要高性能的地方使用Redis,不需要高性能的地方使用MongDB。存储数据在MongDB和Redis之间做同步。所以一般情形下,使用MongDB作为持久化存储数据库存储数据,使用redis作为缓存提升读取速度。
二、数据同步实现方案
把二手房小区价格数据,持久化存储在MongDB数据库中,然后利用redis作为缓存数据库,实现数据的快速读取。这样就需要保持redis和MongDB数据库的数据一致性,接下来,主要讲解查询和数据更新过程的数据库一致性实现。
1、查询一致性
查询数据时,由于redis作为缓存实现快速读取数据,所以首先查询redis中是否存在数据,若存在则返回查询结果,若不存在,则向MongDB数据库请求查询数据,然后由MongDB数据库返回结果。查询流程如下如所示。而且,由于本文中redis作为缓存使用,所以需要添加过期时间,也就是为redis的每条数据记录添加过期时间,若过期时间数据没有被查询则清除,若此时间内,数据被查询,则过期时间重置,这样可以定时清除查询不频繁的数据存在redis中,增加数据读取速度。
2、数据实时重复
redis作为MongoDB的缓存在线实时去重,可以解决在多进程、多线程、异步爬虫时的数据实时重复问题。什么叫数据实时重复呢?
数据重复主要体现在,爬虫一但需要整个库全部数据的实时更新,但并不知道对方网站数据只有一部分数据更新。但要整个库全部数据不能有重复,没法监控对方网页,就需要重新爬整个网站。用案例最能说明问题。
案例一:二手房价格更新
8月数据如下
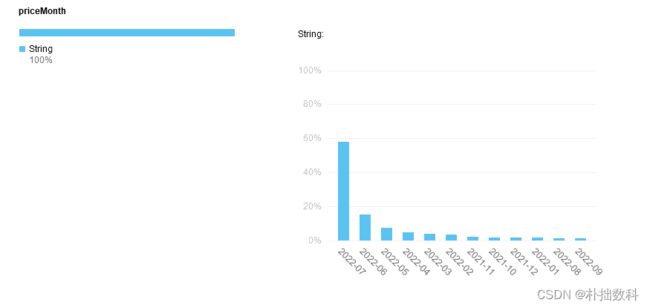
9月数据如下
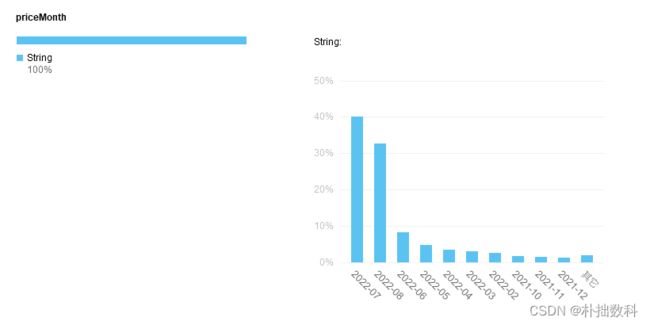
如何判断是数据库有,但真实新数据变化的?
如果有数据,看新爬取的价格时间是否在数据库价格时间列表中,如果priceMonth不在其中则插入,如果在其中则不插入。这里例如第一次爬取在8月,数据大多展示7月数据。本月9月需要把数据更新到8月,要保证数据成功更新,又不重复。就需要快速判断什么页面需要更新,什么页面不需要更新。从而减少请求次数,提高爬虫效率,并且减少对方服务器压力。
明确重复数据的特征
首先明确什么样的数据是重复的。
因为有一万五相同小区名字,但在不同城市的数据。如果拿小区+月份重复,这一万五就丢掉了。就和一个"春天花园"一样,六七个省都有这个小区名字 。那就需要思考省市区(县)+小区+月份更准确 还是 城市+小区+月份就可以。会不会有同一个城市不同的区县有相同的小区名字。
因为中国没有相同市、区的名字,不加“省”也是可以的。最终拿市+区(县)+小区名字+年月作为主键,保证数据绝对的不重复。因此这里redis表的设计采用hash类型的数据,这样可以存在多个key-value对,以用户ID作为hash表的名称。
keyend=item["city"]+item["region"]+item["projectName"]+item["priceMonth"]
基于Redis的数据库性质,查询插入hkeys,hmset的效率比用pandas去重,mongoDB去重,效率高很多,这是大费周章用redis的原因,不然为啥不用mongoDB呢?这里读者发现我不对,或者这种方法效率更低,我愿意有偿听你意见(我只是redis的菜鸟)
import redis
from multiprocessing.dummy import Pool as ThreadPool
import copy
pool =redis.ConnectionPool(host='localhost',port=6379,db=2)
connection = redis.Redis(connection_pool=pool)
# connection.flushall()#清空数据库
list_=copy.deepcopy(mycol2_list)#list(mycol1.find())
def pross_Redis(item):
item["_id"]=str(item['_id'])
item["center"]=str(item["center"])
keyend=item["city"]+item["region"]+item["projectName"]+item["priceMonth"]
# print(len(connection.hkeys(keyend)))
if len(connection.hkeys(keyend))!=10:#如果没有
print(1)
connection.hmset(keyend, mapping=item) # 批量插入
elif len(connection.hkeys(keyend))==10:#如果有
if item["priceMonth"] not in [connection.hget(keyend,"priceMonth").decode('utf-8')]:
print(2)
connection.hmset(keyend, mapping=item) # 批量插入
else:
print("重复数据")
# referencePrice=connection.hget(keyend,"referencePrice")
else:
print("其他数据")
# mycol1.insert_one(item)#.update({'_id':id_}, {'$rename': {'updateDate': 'priceMonth'}}, False, True)
pool = ThreadPool(10)
pool.map(pross_Redis,list_[:30])
pool.close()
pool.join()
fauture=mycol2_list[36]
item=fauture
keyend=item["city"]+item["region"]+item["projectName"]+item["priceMonth"]
isExists = connection.hexists(keyend,"projectName")
if isExists!=True:#如果新数据不存在于数据库,插入
print(1)
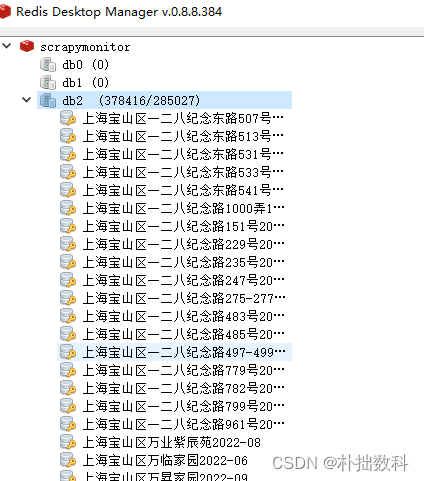
最终效果如下
具体设置方法
方案1 缓存方案
爬"上海市"的时候,把mongoDB上海市的数据缓存到redis,然后设置30分钟或者爬取完释放缓存。
方案2 Redis过滤器快速去重
(1)刚开始爬虫 把MongDB数据库所有数据缓存到redis
(2)把新爬的数据按照keyend和redis主键对比
(3)如果keyend不在redis主键中,插入redis,再插入MongDB
(4)如果keyend在redis主键中,不插入redis
(5) connection.flushall()释放redis数据的缓存
这个拿字典也能实现,只是效率没有redis高,等到一百万数据的时候这个会很明显
最终pipeline的写法如下
from itemadapter import ItemAdapter
import pymongo as pymongo
from .items import ShellItem
import pandas as pd
import redis
from multiprocessing.dummy import Pool as ThreadPool
import copy
class ShellPipeline:
"省略数据库部分"
def process_item(self, items, spider):
items1= ItemAdapter(items).asdict()
global connection
# 用redis作为缓存来去重数据
pool = redis.ConnectionPool(host='localhost', port=6379, db=2)
connection = redis.Redis(connection_pool=pool)#这里必须每次插入都导入最新redis
def pross_Redis(item):
# item["_id"] = str(item['_id'])
item = {"province": item["province"],
"city": item["city"],
"spiderDate": item["spiderDate"],
"projectName": item["projectName"],
"referencePrice": item["referencePrice"],
"region": item["region"],
"priceMonth": item["priceMonth"],
"deliveryDate": item["deliveryDate"],
"center": item["center"]}
item["center"] = str(item["center"])
keyend = item["city"] + item["region"] + item["projectName"] + item["priceMonth"]
# print(len(connection.hkeys(keyend)))
if len(connection.hkeys(keyend)) != 9: # 如果没有数据,9是我数据item有9个key
print(1)
connection.hmset(keyend, mapping=item) # 批量插入
return True
elif len(connection.hkeys(keyend)) == 9: # 如果有
if item["priceMonth"] not in [connection.hget(keyend, "priceMonth").decode('utf-8')]:
print(2)
connection.hmset(keyend, mapping=item) # 批量插入
else:
print("重复数据")
else:
print("其他数据")
postItem = dict(items1)
keyend1= items1["city"] + items1["region"] + items1["projectName"] + items1["priceMonth"]
isExists = connection.hexists(keyend1, "projectName")
if isExists != True: # 如果新数据不存在于数据库,插入
# 把item转化成字典形式
print(postItem)
judje=pross_Redis(postItem)
if judje==True:
print(postItem)
self.coll.insert_one(postItem)#self.coll为MongoDB
return items1
启动函数main如下
from twisted.internet import reactor, defer
from scrapy.crawler import CrawlerRunner
from scrapy.utils.log import configure_logging
import time
import logging
from scrapy.utils.project import get_project_settings
import multiprocessing
# import psycopg2
import time
# # 在控制台打印日志
# configure_logging()
# # CrawlerRunner获取settings.py里的设置信息
# runner = CrawlerRunner(get_project_settings())
import redis
from multiprocessing.dummy import Pool as ThreadPool
import copy
global connection
import pymongo
myclient = pymongo.MongoClient("mongodb://localhost:27017/") #,username='root',password='18091471364@ch'使用MongoClient对象,连接数据库
collist = myclient.list_database_names() # 获取所有数据库
mydb = myclient["companyln"] # 数据库名 esfcomunicate
datalist=[]
#for i in ["test_815_Night","test_815_Night_end","test_esf815"]:
mycol2 = mydb["company_second_hand_house_price"]# collection集合(类似SQL的表)
# datalist=datalist+list(mycol.find())
# 用redis作为缓存来去重数据
pool1 = redis.ConnectionPool(host='localhost', port=6379, db=2)
connection = redis.Redis(connection_pool=pool1)
# 更新取消注释,把底库导入redis
#
# def pross_Redis(item):
# # item["_id"] = str(item['_id'])
# item = {"province": item["province"],
# "city": item["city"],
# "spiderDate": item["spiderDate"],
# "projectName": item["projectName"],
# "referencePrice": item["referencePrice"],
# "region": item["region"],
# "priceMonth": item["priceMonth"],
# "deliveryDate": item["deliveryDate"],
# "center": item["center"]}
#
# item["center"] = str(item["center"])
# keyend = item["city"] + item["region"] + item["projectName"] + item["priceMonth"]
# # print(len(connection.hkeys(keyend)))
# if len(connection.hkeys(keyend)) != 9: # 如果没有
# print(1)
# connection.hmset(keyend, mapping=item) # 批量插入
# return True
# elif len(connection.hkeys(keyend)) == 9: # 如果有
# if item["priceMonth"] not in [connection.hget(keyend, "priceMonth").decode('utf-8')]:
# print(2)
# connection.hmset(keyend, mapping=item) # 批量插入
# else:
# print("重复数据")
# # referencePrice=connection.hget(keyend,"referencePrice")
# else:
# print("其他数据")
# connection.flushall()#清空数据库
# 如何判断是数据库有,但真实新数据变化的
# [connection.hget(keyend,"priceMonth").decode('utf-8')]#==xinshuji.encode('utf-8')
# 把不同月份的合并起来成一个列表,但只显示最新数据
# 如果有数据,看新爬取的价格时间是否在数据库价格时间列表中,如果priceMonth不在其中则插入,如果在其中则不插入
# list_ = copy.deepcopy(list(mycol2.find()))
# from multiprocessing import Pool
# multiprocessing = Pool(processes=8)
#
# def ThreadPool1(list_):
# pool = ThreadPool(10)
# pool.daemon=True
# pool.map(pross_Redis, list_)
# pool.close()
# pool.join()
# multiprocessing.map(pross_Redis, list_)
# multiprocessing.close()
# multiprocessing.join()
#第1行代码导入CMDLINE模块来执行命令行指令。第2行代码用split()函数根据空格拆分指令字符串,再用execute()函数输入到命令行中执行,相当于直接在终端中执行指令“scapy crawl爬虫名”。
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
from scrapy.spiderloader import SpiderLoader
import time
from multiprocessing import Pool
list_all=[['End_gansu','End_guangdong','End_guangxi','End_guizhou'],
['End_hainan','End_hebei','End_heilongjiang','End_henan'],
['End_hubei','End_jiangsu','End_jiangxi','End_shanghai'],
['End_shanxi','End_sichuan','End_tianjing','End_xinjiang'],
['End_fujian','End_shandong','End_yunnan','End_zhejiang'],
['End_anhui', 'End_beijing','End_chongqing',]]
#['End_liaoning','End_jilin','End_neimenggu','End_ningxia'],
# 根据项目配置获取 CrawlerProcess 实例
def process1(name):
# try:
process = CrawlerProcess(settings=get_project_settings())
process.crawl(name)
process.start()
# except:
# pass
# print(process)
# # 获取 spiderloader 对象,以进一步获取项目下所有爬虫名称
spider_loader = list_all#SpiderLoader(list_all)
if __name__ == '__main__':
for P in list_all:
# LIST1=P
start_3=time.time()
pool = Pool(processes=4)
pool.daemon = True
pool.map(process1, P)#LIST1
pool.close()
pool.join()
end_3=time.time()
print('四个进程',end_3-start_3)
案例 二 小程序 显示受限数据实时更新
遇到每次展示150条,但每次请求返回不同的数据,这种数据库看似深不见底,因为不知道到底有多少数据,就需要尽可能多地爬取。
确定enterpriseName公司名称为主键,作为去重keyend
具体设置方法
方案1 缓存方案
爬"上海市"的时候,把mongoDB的数据缓存到redis,然后设置30分钟或者爬取完释放缓存。
方案2 Redis过滤器快速去重
(1)刚开始爬虫 把MongDB数据库所有数据缓存到redis
(2)把新爬的数据按照keyend和redis主键对比
(3)如果keyend不在redis主键中,插入redis,再插入MongDB
(4)如果keyend在redis主键中,不插入redis
(5) connection.flushall()释放redis数据的缓存
这个拿字典也能实现,只是效率没有redis高,等到一百万数据的时候这个会很明显
def process_item(self, item, spider):
items1= ItemAdapter(item).asdict()
global connection
# 用redis作为缓存来去重数据
pool = redis.ConnectionPool(host='localhost', port=6379, db=3)
connection = redis.Redis(connection_pool=pool)
def pross_Redis(item):
# item["_id"] = str(item['_id'])
item.pop('_id', None)
item["certList"] = str(item["certList"])
keyend = item["enterpriseName"]
# print(len(connection.hkeys(keyend)))
isExists = connection.hexists(keyend, "certList")
if isExists != True: # 如果新数据不存在于数据库,插入
print(1)
connection.hmset(keyend, mapping=item) # 批量插入
return True
elif isExists == True: # 如果有
print("重复数据")
else:
print("其他数据")
postItem = dict(items1)
keyend1= postItem["enterpriseName"]
isExists = connection.hexists(keyend1, "certList")
if isExists != True: # 如果新数据不存在于数据库,插入
# 把item转化成字典形式
print(postItem)
judje=pross_Redis(postItem)
if judje==True:
print(postItem)
self.coll.insert_one(postItem)
return items1