python+sklearn实现决策树模型
决策树
基本算法原理
核心思想: 相似的输入必会产生相似的输出.
年龄: 1-青年, 2-中年, 3-老年
学历: 1-本科, 2-硕士, 3-博士
经历: 1-出道, 2-一般, 3-老手, 4-骨灰
性别: 1-男性, 2-女性
| 年龄 | 学历 | 经历 | 性别 | 薪资 |
|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 6000 |
| 2 | 1 | 3 | 1 | 10000 |
| 3 | 3 | 4 | 1 | 50000 |
| … | … | … | … | … |
| 1 | 3 | 2 | 2 | ? |
为了提高搜索效率, 使用树形数据结构处理样本数据:
年 龄 = 1 { 学 历 = 1 学 历 = 2 学 历 = 3 年龄=1 \left\{ \begin{aligned} 学历=1 \\ 学历=2 \\ 学历=3 \\ \end{aligned} \right. 年龄=1⎩⎪⎨⎪⎧学历=1学历=2学历=3
年 龄 = 2 { 学 历 = 1 学 历 = 2 学 历 = 3 年龄=2 \left\{ \begin{aligned} 学历=1 \\ 学历=2 \\ 学历=3 \\ \end{aligned} \right. 年龄=2⎩⎪⎨⎪⎧学历=1学历=2学历=3
年 龄 = 3 { 学 历 = 1 学 历 = 2 学 历 = 3 年龄=3 \left\{ \begin{aligned} 学历=1 \\ 学历=2 \\ 学历=3 \\ \end{aligned} \right. 年龄=3⎩⎪⎨⎪⎧学历=1学历=2学历=3
首先从训练样本矩阵中选择第一个特征进行子表划分, 使每个子表中该特征的值全部相同. 然后再在每个子表中选择下一个特征, 按照同样的规则继续划分更小的子表, 不断重复直到所有的特征用完为止. 此时便得到叶级子表, 其中所有样本的特征值完全相同.
对于待预测样本, 根据每一个特征值, 选择对应的子表, 逐一匹配, 直到找到与之完全匹配的叶级子表, 用该子表中样本的输出, 通过平均(回归) 或者投票(分类) 为待预测样本提供输出.
决策树相关API:
import sklearn.tree as st
# 创建决策树模型
# max_depth: 树的最大深度
model=st.DecisionTreeRegressor(max_depth=4)
model.fit(x, y)
pred_y = model.predict(test_x)
工程优化
决策树在使用时不必用尽所有的特征, 叶级子表中允许混杂不同的特征值, 以此降低决策树的高度.所以在精度牺牲可接受的情况下, 可以降低决策树的高度, 提高模型的性能.
通常情况下,可以优先选择使信息熵减少量最大的特征作为划分子表的依据.
集合算法
根据多个不同的模型给出的预测结果, 利用平均(回归) 或者投票(分类) 的方法, 得出最终的结果.
基于决策树的集合算法, 就是按照某种规则, 构建多颗彼此不同的决策树模型, 分别给出针对未知样本的预测结果, 最后通过平均或投票的方式得到相对综合的结论.
正向激励
首先为样本矩阵中的样本随机分配初始权重, 由此构建一颗带有权重的决策树, 在由该决策树提供预测输出时, 通过加权平均或加权投票的方式产生预测值. 将训练样本带入模型, 预测其输出, 针对那些预测值与实际值不同的样本, 提高其权重, 由此形成第二棵决策树. 重复以上过程, 构建出不同权重的若干棵决策树. 最终使用时, 由这些决策树通过平均/投票的方式得到相对综合的输出,所谓权重,可以理解为每一个树枝所占的比例,比如第一个树枝是%10,第二个是20%,当然实际不是这样,这个是我个人方便理解的方法。
正向激励相关API:
import sklearn.tree as st
import sklearn.ensemble as se
t_model = st.DecisionTreeRegressor(...)
model = se.AdaBoostRegressor(
t_model, # 正向激励内部的模型
n_estimators=400, # 构建400棵树
random_state=7 # 随机种子
)
model.fit(..)
model.predict(..)
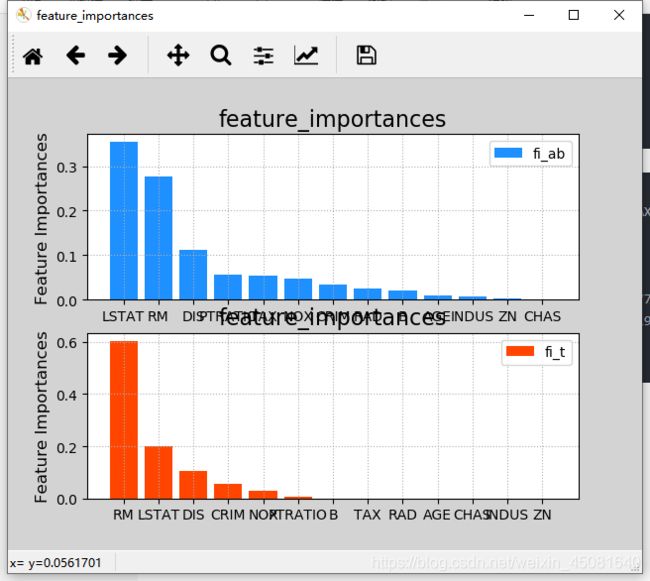
特征重要性
作为决策树模型训练过程中的副产品, 根据每个特征划分子表前后信息熵的减少量得到该特征的重要程度, 此即为该特征重要性指标. 可以通过model.feature_importances_ 来获取每个特征的特征重要性值.
案例: 基于正向激励, 预测房屋价格:
"""
demo01_adaboost.py 正向激励
"""
import sklearn.datasets as sd
import sklearn.utils as su
import sklearn.tree as st
import sklearn.ensemble as se
import sklearn.metrics as sm
import matplotlib.pyplot as mp
import numpy as np
# 读取数据 加载波士顿房屋价格
boston = sd.load_boston()
print(boston.data.shape) # 数据的维度
print(boston.feature_names) # 数据的特征名
print(boston.target.shape)
# 划分测试集与训练集
# 打乱数据集
# 以random_state随机种子作为参数生成数据集
x, y=su.shuffle(boston.data, boston.target,
random_state=7)
train_size = int(len(x)*0.8)
train_x, test_x, train_y, test_y = \
x[:train_size], x[train_size:], \
y[:train_size], y[train_size:]
# 创建决策树回归器模型,使用训练集训练模型,
# 测试集测试模型
t_model=st.DecisionTreeRegressor(max_depth=4)
# 基于正向激励 搞出多颗树
model = se.AdaBoostRegressor(t_model,
n_estimators=400, random_state=7)
model.fit(train_x, train_y)
pred_test_y = model.predict(test_x)
print(sm.r2_score(test_y, pred_test_y))
fi_ab = model.feature_importances_
print(fi_ab)
# 使用决策树训练模型
model=st.DecisionTreeRegressor(max_depth=4)
model.fit(train_x, train_y)
pred_test_y = model.predict(test_x)
print(sm.r2_score(test_y, pred_test_y))
fi_t = model.feature_importances_
# 绘制特征重要性柱状图
mp.figure('feature_importances',facecolor='lightgray')
mp.subplot(211)
mp.title('feature_importances',fontsize=16)
mp.ylabel('Feature Importances', fontsize=12)
mp.grid(linestyle=':')
sorted_indices = fi_ab.argsort()[::-1]
x = np.arange(fi_ab.size)
mp.xticks(x, boston.feature_names[sorted_indices])
mp.bar(x, fi_ab[sorted_indices],
color='dodgerblue', label='fi_ab')
mp.legend()
mp.subplot(212)
mp.title('feature_importances',fontsize=16)
mp.ylabel('Feature Importances', fontsize=12)
mp.grid(linestyle=':')
sorted_indices = fi_t.argsort()[::-1]
x = np.arange(fi_t.size)
mp.xticks(x, boston.feature_names[sorted_indices])
mp.bar(x, fi_t[sorted_indices],
color='orangered', label='fi_t')
mp.legend()
mp.show()
(506, 13)
['CRIM' 'ZN' 'INDUS' 'CHAS' 'NOX' 'RM' 'AGE' 'DIS' 'RAD' 'TAX' 'PTRATIO'
'B' 'LSTAT']
(506,)
0.9068598725149652
[0.03339581 0.00287794 0.00810414 0.00099482 0.0463733 0.27796803
0.00884059 0.11267449 0.02459319 0.05455562 0.05567394 0.0194009
0.35454723]
0.8202560889408634