随机森林(RandomForestClassifier)----概述与应用
文章目录
-
- 随机森林
-
- 构造随机森林
-
- 自主采样(bootstrap sample)
- 特征子集随机选择
- 随机森林中的回归问题与分类问题
- sklearn实现、分析随机森林
- 优点、缺点及参数
随机森林
对于决策树来说,当数据集的特征较多时,构造的决策树往往深度很大,很容易造成对训练数据的过拟合
随机森林本质上是很多决策树的集合,其中每棵树都和其它树略有不同。尽管决策树可能会出现过拟合的特点,但我们可以对这些树的结果取平均值来降低过拟合,这样既可以减少过拟合,又能保持树的预测能力
构造随机森林
构造随机森林通过调整每个树的数据集与特征选择来构造均不相同的决策树
由于使用了自主采样,随机森林中构造每颗决策树的数据集都是略有不同的。由于每个结点的特征选择,每颗树的每次划分都是基于特征的不同子集。这两种方法共同保证随机森林中所有树都不相同
自主采样(bootstrap sample)
随机森林中的每颗树在构造时是彼此完全独立的, 均随机选择进行构建,确保树的唯一性
从构造一棵树开始,首先对数据进行自主采样(bootstrap sample)。即从 n 个大小的数据集中有放回地抽取一个样本,重复多次抽取 n 次,这样就会创建一个与原数据集大小相同地数据集,但有些数据可能会缺失,有些会出现重复
#假如我们要创建列表['a', 'b', 'c', 'd']的自助采样
#可能出现的采样数据集为
#['a', 'b', 'b', 'd']、
#['a', 'b', 'b', 'c']、
#['b', 'b', 'b', 'd']、
#['a', 'c', 'c', 'd']等
特征子集随机选择
在具体的算法部分,随机森林对决策树的算法稍作修改
在每个结点处,算法随机选择 特征的一个子集 ,并对其中的一个特征寻找最佳测试,而不是向决策树那样对所有特征都寻找最佳测试
其中选择特征个数由 max_features 指定,每个结点中特征子集的选择是相互独立的,这样树的每个结点可以使用特征的不同子集来做出决策
其中该参数 max_features 较为重要:
- 若 max_features = n_features(即最大特征数即为总特征数), 则每次划分均要考虑数据集的所有特征,等于未添加特征选择的随机性;
- 若 max_features 较大,那么随机森林中的树将会十分相似,利用最独特的特征可以轻松拟合数据;
- 若 max_features 较小,那么随机森林中的树差异将会很大,为了很好地拟合数据,每颗树的深度都要很大
随机森林中的回归问题与分类问题
对于回归问题,我们可以对这些结果取平均值作为最终预测。
对于分类问题,则采用了"软投票"(soft voting)策略。即每个算法做出"软"预测,给出每个可能的输出标签的概率。对所有树的预测概率取平均值,然后将概率最大的类别作为预测结果。
sklearn实现、分析随机森林
from sklearn.ensemble import RandomForestClassifier #引入随机森林分类器
from sklearn.datasets import make_moons #引入sklearn中的数据集
from sklearn.model_selection import train_test_split #引入拆分数据集方法
X, y = make_moons(n_samples=100, noise=0.25, random_state=3) #随机生成100个数据点
#拆分数据集为训练集与测试集, "stratify"的意思为分层
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)
#"estimators"的意思估计量、估计函数
forest = RandomForestClassifier(n_estimators=5, random_state=2)
forest.fit(X_train, y_train)
print(forest.estimators_) #森林的树均被保存在forest.estimators_中
[DecisionTreeClassifier(max_features='auto', random_state=1872583848),
DecisionTreeClassifier(max_features='auto', random_state=794921487),
DecisionTreeClassifier(max_features='auto', random_state=111352301),
DecisionTreeClassifier(max_features='auto', random_state=1853453896),
DecisionTreeClassifier(max_features='auto', random_state=213298710)]
由上可见,共存在5棵决策树,符合情理。
我们将每颗树学到的决策边界可视化,也将它们的总预测(即整个森林的预测)可视化
import matplotlib.pyplot as plt #导入绘图包
import mglearn #导入mglearn包
#生成 2 行 3 列的6个子图,子图的大小为20*10
fig, axes = plt.subplots(2, 3, figsize=(20, 10))
#zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
#如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
#参数 axes.ravel()表示 6 个画布, forest.estimators_表示 5 个森林, enumerate()方法,输出每个元素的下标和其对应的值
for i, (ax, tree) in enumerate(zip(axes.ravel(), forest.estimators_)):
ax.set_title('Tree {}'.format(i)) #设置图形标题
#画出树的部分图,数据为训练集,树为随机森林生成的子树,画在ax子图中
mglearn.plots.plot_tree_partition(X_train, y_train, tree, ax=ax)
#画出随机森林的分界线
mglearn.plots.plot_2d_separator(forest, X_train, fill=True, ax=axes[-1, -1], alpha=.4)
#设置标题
axes[-1, -1].set_title('Random Forest')
mglearn.discrete_scatter(X_train[:, 0], X_train[:, 1], y_train) #添加数据点, 横坐标,纵坐标,结果
[,
]
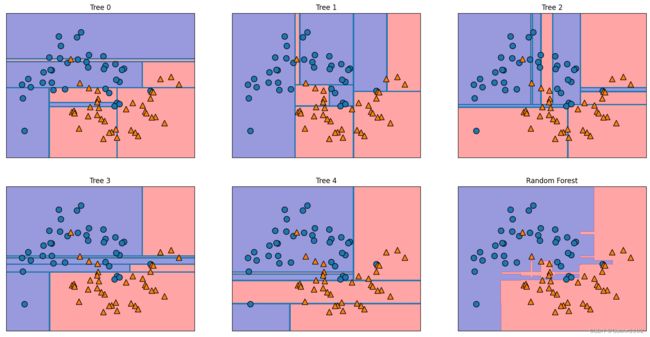
由上图可以看到,这5棵树学到的决策边界大不相同
每颗树都犯了一些错误,因为这里画出的一些训练点实际上并没有包含在这些数的训练集中,原因是自主采样
随机森林比单独每一棵树的过拟合都要小,给出的决策边界也更符合直觉。在任何实际应用中,我们会用到更多数(成百上千),从而得到更平滑的效果
假如我们把包含100棵树的随机森林应用在乳腺癌数据上,如下:
from sklearn.datasets import load_breast_cancer #导入乳腺癌数据包
cancer = load_breast_cancer() #加载乳腺癌数据集
#拆分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, random_state=0)
forest = RandomForestClassifier(n_estimators=100, random_state=0) #生成随机森林
forest.fit(X_train, y_train) #训练数据
print('Accuracy on training set: {:.3f}'.format(forest.score(X_train, y_train)))
print('Accuracy on test set: {:.3f}'.format(forest.score(X_test, y_test))) #输出结果
Accuracy on training set: 1.000
Accuracy on test set: 0.972
在没有调节任何参数的情况下,随机森林的精度为 97%, 比线性模型或单颗决策树都要好,通常随机森林默认参数就可给出很好的结果
与决策树类似,随机森林也可以给出特征重要性,计算方法是将森林中所有数的特征重要性求和并取平均,通常随机森林给出的特征重要性更为可靠
import matplotlib.pyplot as plt
import numpy as np
def plot_feature_importance_cancer(model):
#获取到特征的个数
n_features = cancer.data.shape[1]
#根据重要性进行绘图
plt.barh(range(n_features), model.feature_importances_, align='center')
plt.yticks(np.arange(n_features), cancer.feature_names)
plt.xlabel('Feature importance')
plt.ylabel('Feature')
#绘图画出重要性
plot_feature_importance_cancer(forest)
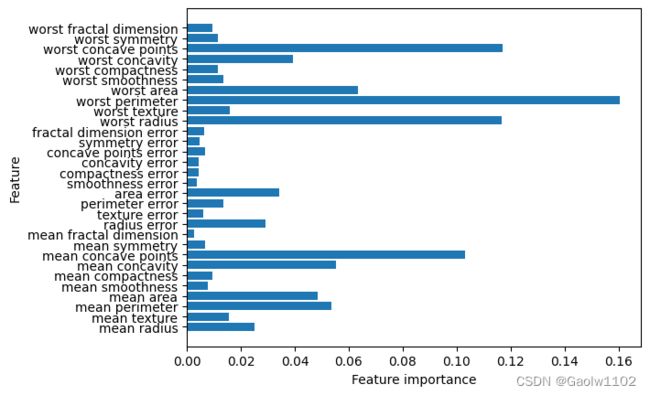
由上图可见,随机森林比单颗树更能从总体把握数据的特征
优点、缺点及参数
从本质上来看,随机森林拥有决策树的所有优点,同时弥补了决策树的一些缺陷,树越多,其鲁棒性越好,但要注意内存情况
随机森林不适合处理维度非常高的稀疏矩阵,另外训练和预测的速度也较慢
分类问题中,max_features = sqrt(n_features); 回归问题中,max_features = n_features;对于参数的设置,一般采取默认值即可