[HITML] 哈工大2020秋机器学习Lab1实验报告
Gtihub仓库
不想白嫖的就来这投个币吧
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第1张图片](http://img.e-com-net.com/image/info8/0eee584c1c9148a4a3d4d6776fa218fd.jpg)
| 姓名 | |
| 学号 | |
| 班号 | |
| 电子邮件 | |
| 手机号码 |
1 实验目的
掌握最小二乘法求解(无惩罚项的损失函数)、掌握加惩罚项(2范数)的损失函数优化、梯度下降法、共轭梯度法、理解过拟合、克服过拟合的方法(如加惩罚项、增加样本)
2 实验要求及实验环境
2.1 实验要求
-
生成数据,加入噪声;
-
用高阶多项式函数拟合曲线;
-
用解析解求解两种loss的最优解(无正则项和有正则项)
-
优化方法求解最优解(梯度下降,共轭梯度);
-
用你得到的实验数据,解释过拟合。
-
用不同数据量,不同超参数,不同的多项式阶数,比较实验效果。
-
语言不限,可以用matlab,python。求解解析解时可以利用现成的矩阵求逆。梯度下降,共轭梯度要求自己求梯度,迭代优化自己写。不许用现成的平台,例如pytorch,tensorflow的自动微分工具。
2.2 实验环境
Windows10; python3.8.5; jupyter notebook
3 设计思想
由泰勒级数可知,足够高阶的多项式可以拟合任意的函数,所以本次实验使用多项式来拟合正弦函数 s i n ( 2 π x ) sin(2\pi x) sin(2πx)。在 m m m 阶多项式中,有 m + 1 m+1 m+1 个待定系数,这些系数(由低到高)组成的列向量记作 w w w。用最小二乘法确定 w w w,设 E ( w ) = 1 / 2 ∗ ( X w – Y ) T ( X w – Y ) E(w) = 1/2 * (Xw – Y)^T(Xw– Y) E(w)=1/2∗(Xw–Y)T(Xw–Y),其中, X X X 为多项式中各个未知项代入观测数据求得的矩阵,若记 X i X_i Xi 为 X X X 的第 i i i 行的向量,则 X i [ j ] X_i[j] Xi[j] 为第 i i i 个观测数据 x i x_i xi 的 j j j 次方,记有 n n n 组观测数据,多项式最高次为 m m m,易知 X X X的维度为 n ∗ ( m + 1 ) n*(m+1) n∗(m+1)。 Y Y Y 为观测标签向量, Y [ j ] Y[j] Y[j] 为第 j j j 组观测数据的标签值(即 y y y 值)。从而问题转化为:求向量 w w w,使得 E ( w ) E(w) E(w) 最小。
3.1 生成数据
根据输入的多项式阶数和训练集大小参数生成相应大小的数据集,根据输入的高斯分布的均值和标准差参数生成噪声,将噪声加入到数据集中,最后根据数据集生成训练集等数据。
def generate_data(order, size, mu=0, sigma=0.05, begin=0, end=1):
x = np.arange(begin, end, (end - begin) / size)
guass_noise = np.random.normal(mu, sigma, size) # 高斯分布噪声
y = np.sin(2 * np.pi * x) + guass_noise
train_y = y.reshape(size, 1)
train_x = np.zeros((size, order + 1))
nature_row = np.arange(0, order+1))
for i in range(size):
row = np.ones(order + 1) * x[i]
row = row ** nature_row
train_x[i] = row
return train_x, train_y, x, y
3.2 最小二乘法求解析解(无正则项)
E ( w ) = 1 2 ( X w − Y ) T ( X w − Y ) = 1 2 ( w T X T − Y ) ( X w − Y ) = 1 2 ( w T X T X w − w T X T Y − Y T X w + X T Y ) = 1 2 ( w T X T X w − 2 w T X T Y + X T Y ) E(\pmb{w})=\frac 1 2(\pmb {Xw}-\pmb Y)^T(\pmb{Xw}-\pmb Y)\\ \qquad\quad=\frac 1 2(\pmb w^T\pmb X^T-\pmb Y)(\pmb {Xw}-\pmb Y)\\ \qquad\qquad\qquad\qquad\qquad\;\;\;\;=\frac 1 2(\pmb w^T\pmb X^T\pmb X\pmb w-\pmb w^T\pmb X^T\pmb Y-\pmb Y^T\pmb X\pmb w+\pmb X^T\pmb Y)\\ \qquad\qquad\qquad\quad\,=\frac 1 2(\pmb w^T\pmb X^T\pmb{Xw}-2\pmb w^T\pmb X^T\pmb Y+\pmb X^T\pmb Y)\\ E(www)=21(XwXwXw−YYY)T(XwXwXw−YYY)=21(wwwTXXXT−YYY)(XwXwXw−YYY)=21(wwwTXXXTXXXwww−wwwTXXXTYYY−YYYTXXXwww+XXXTYYY)=21(wwwTXXXTXwXwXw−2wwwTXXXTYYY+XXXTYYY)
令
∂ E ∂ w = X T X w − X T Y = 0 \frac{\partial E}{\partial \pmb w} = \pmb X^T\pmb{Xw}-\pmb X^T\pmb Y =0 ∂www∂E=XXXTXwXwXw−XXXTYYY=0
得
w = ( X T X ) − 1 X T Y \pmb w=(\pmb X^T\pmb X)^{-1}\pmb X^T\pmb Y www=(XXXTXXX)−1XXXTYYY
w = np.linalg.inv(np.dot(train_x.T, train_x)).dot(train_x.T).dot(train_y)
3.3 最小二乘法求解析解(有正则项)
E ~ ( w ) = 1 2 ( X w − Y ) T ( X w − Y ) + λ 2 ∣ ∣ w ∣ ∣ 2 = 1 2 ( w T X T − Y ) ( X w − Y ) + λ 2 w T w = 1 2 ( w T X T X w − w T X T Y − Y T X w + X T Y ) + λ 2 w T w = 1 2 ( w T X T X w − 2 w T X T Y + X T Y ) + λ 2 w T w \widetilde{E}(\pmb{w})=\frac 1 2(\pmb {Xw}-\pmb Y)^T(\pmb{Xw}-\pmb Y) + \frac\lambda 2 ||\pmb w||_2\\ \qquad\;\;\;\;=\frac 1 2(\pmb w^T\pmb X^T-\pmb Y)(\pmb {Xw}-\pmb Y) + \frac \lambda 2\pmb w^T\pmb w\\ \qquad\qquad\qquad\qquad\qquad=\frac 1 2(\pmb w^T\pmb X^TX\pmb w-\pmb w^T\pmb X^T\pmb Y-\pmb Y^T\pmb X\pmb w+\pmb X^T\pmb Y) + \frac \lambda 2\pmb w^T\pmb w\\ \qquad\qquad\qquad\quad=\frac 1 2(\pmb w^T\pmb X^T\pmb{Xw}-2\pmb w^T\pmb X^T\pmb Y+\pmb X^T\pmb Y) + \frac \lambda 2\pmb w^T\pmb w\\ E (www)=21(XwXwXw−YYY)T(XwXwXw−YYY)+2λ∣∣www∣∣2=21(wwwTXXXT−YYY)(XwXwXw−YYY)+2λwwwTwww=21(wwwTXXXTXwww−wwwTXXXTYYY−YYYTXXXwww+XXXTYYY)+2λwwwTwww=21(wwwTXXXTXwXwXw−2wwwTXXXTYYY+XXXTYYY)+2λwwwTwww
令
∂ E ~ ∂ w = X T X w − X T Y + λ w = 0 \frac{\partial \widetilde {E}}{\partial \pmb w} = \pmb X^T\pmb{Xw}-\pmb X^T\pmb Y + \lambda \pmb w=0 ∂www∂E =XXXTXwXwXw−XXXTYYY+λwww=0
得
w = ( X T X + λ ) − 1 X T Y \pmb w=(\pmb X^T\pmb X + \lambda)^{-1}\pmb X^T\pmb Y www=(XXXTXXX+λ)−1XXXTYYY
w = np.linalg.inv(np.dot(train_x.T, train_x) +
lamda * np.eye(train_x.shape[1])).dot(train_x.T).dot(train_y)
3.4 梯度下降法求优化解
E ~ ( w ) = 1 2 ( X w − Y ) T ( X w − Y ) + λ 2 ∣ ∣ w ∣ ∣ 2 = 1 2 ( w T X T X w − 2 w T X T Y + X T Y ) + λ 2 w T w \widetilde{E}(\pmb{w})=\frac 1 2(\pmb {Xw}-\pmb Y)^T(\pmb{Xw}-\pmb Y) + \frac\lambda 2 ||\pmb w||_2\\ \qquad\qquad\qquad\quad=\frac 1 2(\pmb w^T\pmb X^T\pmb{Xw}-2\pmb w^T\pmb X^T\pmb Y+\pmb X^T\pmb Y) + \frac \lambda 2\pmb w^T\pmb w\\ E (www)=21(XwXwXw−YYY)T(XwXwXw−YYY)+2λ∣∣www∣∣2=21(wwwTXXXTXwXwXw−2wwwTXXXTYYY+XXXTYYY)+2λwwwTwww
对 w \pmb w www 求导
∂ E ~ ∂ w = X T X w − X T Y + λ w \frac{\partial \widetilde {E}}{\partial \pmb w} = \pmb X^T\pmb{Xw}-\pmb X^T\pmb Y + \lambda \pmb w ∂www∂E =XXXTXwXwXw−XXXTYYY+λwww
设步长(学习率)为 α \alpha α,对 w \pmb w www 梯度下降,直到迭代结束或收敛
w = w − α ⋅ ∂ E ~ ∂ w \pmb w =\pmb w - \alpha\cdot \frac {\partial \widetilde E} {\partial \pmb w} www=www−α⋅∂www∂E
当新的损失值大于原来的损失值的时候,说明步长过大,此时将步长折半
w = np.zeros((train_x.shape[1], 1))
new_loss = abs(loss(train_x, train_y, w, lamda))
for i in range(times):
old_loss = new_loss
gradient_w = np.dot(train_x.T, train_x).dot(w) - np.dot(train_x.T, train_y) + lamda * w
old_w = w
w -= gradient_w * alpha
new_loss = abs(loss(train_x, train_y, w, lamda))
if old_loss < new_loss: #不下降了,说明步长过大
w = old_w
alpha /= 2
if old_loss - new_loss < epsilon:
break
3.5 共轭梯度法求优化解
先令
∂ E ~ ∂ w = X T X w − X T Y + λ w = 0 \frac{\partial \widetilde {E}}{\partial \pmb w} = \pmb X^T\pmb{Xw}-\pmb X^T\pmb Y + \lambda \pmb w=0 ∂www∂E =XXXTXwXwXw−XXXTYYY+λwww=0
则求 ( X T X + λ ) w = X T Y (\pmb X^T\pmb X + \lambda)\pmb w = \pmb X^T\pmb Y (XXXTXXX+λ)www=XXXTYYY 的解析解,记 A = X T X + λ A = \pmb X^T\pmb X + \lambda A=XXXTXXX+λ, b = X T Y \pmb b = \pmb X^T\pmb Y bbb=XXXTYYY,则求使残差满足精度的 w \pmb w www
A = np.dot(train_x.T, train_x) + lamda * np.eye(train_x.shape[1]) # n+1 * n+1
b = np.dot(train_x.T, train_y) # n+1 * 1
初始化 w 0 = 0 \pmb w_0 = 0 www0=0, r 0 = b \pmb r_0 = \pmb b rrr0=bbb, p 0 = r 0 \pmb p_0 = \pmb r_0 ppp0=rrr0
w = np.zeros((train_x.shape[1], 1)) # 初始化w为 n+1 * 1 的零阵
r = b
p = b
当 r k \pmb r_k rrrk 不满足精度时,进入循环,对第 k k k 次循环,计算:
a k = r k T r k p k T A p k w k = w k + a k p k r k + 1 = r k − a k A p k b k = r k + 1 T r k + 1 r k T r k p k + 1 = r k + 1 + b k p k a_k = \frac {\pmb r_k^T \pmb r_k}{\pmb p_k^T\pmb A\pmb p_k}\\ \pmb w_k = \pmb w_k + a_k\pmb p_k\\ \pmb r_{k+1} = \pmb r_k - a_k\pmb A\pmb p_k\\ b_k =\frac {\pmb r_{k+1}^T \pmb r_{k+1}}{\pmb r_k^T \pmb r_k}\\ \pmb p_{k+1} = \pmb r_{k+1} + b_k \pmb p_k ak=pppkTAAApppkrrrkTrrrkwwwk=wwwk+akpppkrrrk+1=rrrk−akAAApppkbk=rrrkTrrrkrrrk+1Trrrk+1pppk+1=rrrk+1+bkpppk
while True:
if r.T.dot(r) < epsilon:
break
norm_2 = np.dot(r.T, r)
a = norm_2 / np.dot(p.T, A).dot(p)
w = w + a * p
r = r - (a * A).dot(p)
b = np.dot(r.T, r) / norm_2
p = r + b * p
4 实验结果分析
4.1 不带正则项的解析解
固定训练集大小为10,在不同多项式阶数下的拟合结果
- 1阶: y = − 1.477 x + 0.7385 y = -1.477 x + 0.7385 y=−1.477x+0.7385
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第2张图片](http://img.e-com-net.com/image/info8/55ab76a53bfa4befa3504b831efe9441.jpg)
-
3阶: y = 19.22 x 3 − 29.8 x 2 + 10.51 x − 0.1571 y = 19.22 x^3 - 29.8 x^2 + 10.51 x - 0.1571 y=19.22x3−29.8x2+10.51x−0.1571
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第3张图片](http://img.e-com-net.com/image/info8/ec81cb577211414dafc5349cf6717fc8.jpg)
-
5阶: y = − 68.05 x 5 + 163 x 4 − 112 x 3 + 11.12 x 2 + 6.302 x − 0.07645 y =-68.05 x^5 + 163 x^4 - 112 x^3 + 11.12 x^2 + 6.302 x - 0.07645 y=−68.05x5+163x4−112x3+11.12x2+6.302x−0.07645
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第4张图片](http://img.e-com-net.com/image/info8/1294bb896e1949e6885973409daa0311.jpg)
-
9阶: y = 7480 x 9 − 24580 x 8 + 27680 x 7 − 7577 x 6 − 9072 x 5 + 8667 x 4 − 3041 x 3 + 459.6 x 2 − 18.49 x + 0.08736 y=7480 x^9 - 24580 x^8 + 27680x^7 - 7577 x^6 - 9072 x^5 + 8667 x^4 - 3041 x^3 + 459.6 x^2 - 18.49 x + 0.08736 y=7480x9−24580x8+27680x7−7577x6−9072x5+8667x4−3041x3+459.6x2−18.49x+0.08736
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第5张图片](http://img.e-com-net.com/image/info8/8d123c58eeba48bdb2bce37e87d7e0a3.jpg)
在1阶的时候,基本无法拟合,属于欠拟合,提高阶数,3阶的情况下拟合效果已经足够好,继续提高阶数,直到9阶时拟合函数图像完美的穿过了所有的训练集上的点,但是由于过于关注于“穿过训练集上所有的点”这一条件,导致函数的波动较大,反而难以拟合数据集所代表的函数 s i n ( 2 π x ) sin(2\pi x) sin(2πx)
但是增加训练数据集可以有效地降低阶数过高带来的过拟合现象的影响,下图为不同训练集大小的9阶多项式拟合图像。
-
训练集大小为20: y = − 6173 x 9 + 24930 x 8 − 40640 x 7 + . 4000 x 6 − 15200 x 5 + 3359 x 4 − 238.9 x 3 − 38.22 x 2 + 10.54 x + 0.1475 y = -6173 x^9 + 24930 x^8 - 40640 x^7 + .4000 x^6 - 15200 x^5 + 3359 x^4 - 238.9 x^3 - 38.22 x^2 + 10.54 x + 0.1475 y=−6173x9+24930x8−40640x7+.4000x6−15200x5+3359x4−238.9x3−38.22x2+10.54x+0.1475
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第6张图片](http://img.e-com-net.com/image/info8/86532098adda47d094b9f24a843efb83.jpg)
-
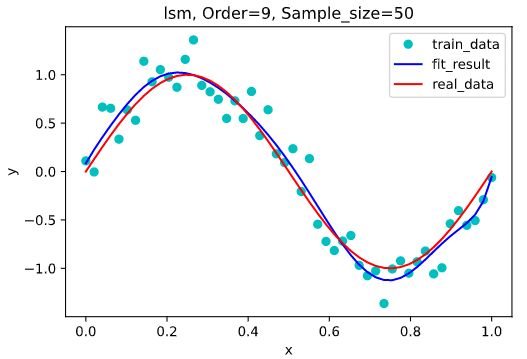
训练集大小为50: y = 3482 x 9 − 14150 x 8 + 23430 x 7 − 20300 x 6 + 9831 x 5 − 2591 x 4 + 325.9 x 3 − 28.06 x 2 + 7.356 x + 0.08484 y= 3482 x^9 - 14150 x^8 + 23430 x^7 - 20300 x^6 + 9831 x^5 - 2591 x^4 + 325.9 x^3 - 28.06 x^2 + 7.356 x + 0.08484 y=3482x9−14150x8+23430x7−20300x6+9831x5−2591x4+325.9x3−28.06x2+7.356x+0.08484
-
训练集大小为100: y = − 3279 x 9 + 14850 x 8 − 27980 x 7 + 28350 x 6 − 16720 x 5 + 5838 x 4 − 1173 x 3 + 106.8 x 2 + 2.833 x + 0.002364 y=-3279 x^9 + 14850 x^8 - 27980 x^7 + 28350 x^6 - 16720 x^5 + 5838 x^4 - 1173 x^3 + 106.8 x^2 + 2.833 x + 0.002364 y=−3279x9+14850x8−27980x7+28350x6−16720x5+5838x4−1173x3+106.8x2+2.833x+0.002364
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第7张图片](http://img.e-com-net.com/image/info8/1c92eaef62594fbcabc0c3a28e6b0738.jpg)
从上面几张图可以看出,在训练集大小为10时,过拟合现象最为严重,随着训练集的增大,过拟合现象逐渐被消除,当训练集大小为100时,我们生成的拟合函数已经几乎完美拟合到了的原数据点的函数上。
4.2 带正则项的解析解
根据3.3中公式所描述的,我们需要确定一个最优的 λ \lambda λ,使用均方根来判断不同参数取值的拟合效果。
训练集大小为10,验证集大小为20,拟合多项式阶为9,多次运行的拟合效果如下:
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第8张图片](http://img.e-com-net.com/image/info8/11b7159aa551411eb57cdac4784a909a.jpg)
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第9张图片](http://img.e-com-net.com/image/info8/f70e6e1bf040495cb741562d7e6438c4.jpg)
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第10张图片](http://img.e-com-net.com/image/info8/fc4e4d46568c4e48b76647d9ae8b2c5d.jpg)
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第11张图片](http://img.e-com-net.com/image/info8/ef1239f97a324f3284eccfab9a5577b4.jpg)
通过多次运行的结果可以看出,随着 λ \lambda λ 取值的减小,拟合函数在训练集上的错误率逐渐减小,在 ( e − 40 , e − 30 ) (e^{-40}, e^{-30}) (e−40,e−30) 区间内的错误率几乎为0,而在验证集上,在 λ > e − 7 \lambda > e^{-7} λ>e−7 时,随着取值的减小,拟合函数的错误率逐渐减小,但是在 λ < e − 15 \lambda < e^{-15} λ<e−15 之后的验证集上的错误率开始上升,说明出现了过拟合现象。
根据多次运行的结果可得最佳的 λ \lambda λ 取值范围大约为 ( e − 11 , e − 7 ) (e^{-11}, e^{-7}) (e−11,e−7) 。
取 λ = e − 9 \lambda = e^{-9} λ=e−9 ,在训练集大小为10,阶数为9的条件下的带惩罚项和不带惩罚项的拟合图像比较。
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第12张图片](http://img.e-com-net.com/image/info8/d0b459da2b1a40fb8e61956efab1efdb.jpg)
可以看到,加入正则项后有效的降低了过拟合现象。
4.3 梯度下降求得优化解
在梯度下降法中,学习率为0.01,根据4.2中的结果取 λ = e − 9 \lambda = e^{-9} λ=e−9
固定训练集大小为10,在不同多项式阶数下的拟合结果 (左图精度为 1 0 − 5 10^{-5} 10−5,右图精度为 1 0 − 6 ) 10^{-6}) 10−6):
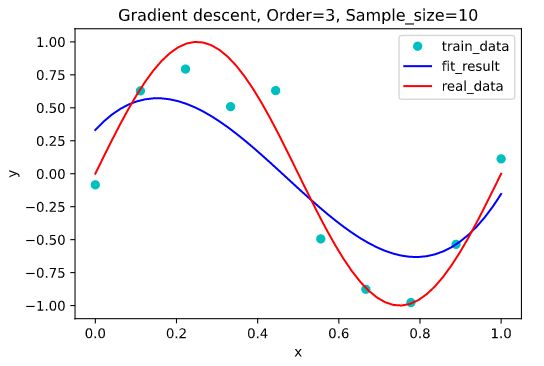
- 3阶,迭代次数:左=37005,右=116453
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第13张图片](http://img.e-com-net.com/image/info8/a82063f097c64b00b6ffe918ef8a7eb8.jpg)
- 5阶,迭代次数:左=17294,右=29646

![[HITML] 哈工大2020秋机器学习Lab1实验报告_第14张图片](http://img.e-com-net.com/image/info8/d10787d9d699459e94835520fa230a19.jpg)
- 7阶,迭代次数:左=9435,右=78793
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第15张图片](http://img.e-com-net.com/image/info8/bf53eddc8e94480f9d47fc0edfd61d7a.jpg)
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第16张图片](http://img.e-com-net.com/image/info8/369bd8f0f66b48248194c90963688975.jpg)
- 9阶,迭代次数:左=23286,右=69858
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第17张图片](http://img.e-com-net.com/image/info8/f5616d4911634fb3bf63075a999077d2.jpg)
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第18张图片](http://img.e-com-net.com/image/info8/e7ae65cac1f642ca87e1336b6a43ca1b.jpg)
固定阶数为9,不同训练集大小下的拟合结果 (左图精度为 1 0 − 5 10^{-5} 10−5,右图精度为 1 0 − 6 ) 10^{-6}) 10−6):
- 训练集大小为20,迭代次数:左=27609,右=49967
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第19张图片](http://img.e-com-net.com/image/info8/802a4285af204c9b8bbdd85217989a9f.jpg)
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第20张图片](http://img.e-com-net.com/image/info8/544767b50f3b41dd9feb272957eb438a.jpg)
- 训练集大小为50,迭代次数:左=20001,右=39570
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第21张图片](http://img.e-com-net.com/image/info8/728bd062b2484d4abbcaada626eefc04.jpg)
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第22张图片](http://img.e-com-net.com/image/info8/7fb72acff37441388c2ef9acea9d58dd.jpg)
- 训练集大小为100,迭代次数:左=17010,右=29397
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第23张图片](http://img.e-com-net.com/image/info8/ca696b5703ce4524a2c09636c7f37ce1.jpg)

从上面的图可以看出,同条件下精度为 1 0 − 6 10^{-6} 10−6的右图的拟合效果要显著强于精度为 1 0 − 5 10^{-5} 10−5下的拟合效果。
随精度的升高,迭代次数变大;随多项式阶增大,迭代次数呈现下降趋势;训练集的大小对于迭代次数几乎没有影响,但仍然满足训练集越大拟合效果也好的结论。
从上面的迭代次数还可以得出一个结论:无论精度是 1 0 − 5 10^{-5} 10−5还是 1 0 − 6 10^{-6} 10−6,它们的迭代次数的量级都在 1 0 5 10^5 105,与共轭梯度相比,性能很差。
4.4 共轭梯度求得优化解
在共轭梯度法中,根据4.2中的结果取 λ = e − 9 \lambda = e^{-9} λ=e−9
固定训练集大小为10,在不同多项式阶数下的拟合结果 (左图精度为 1 0 − 5 10^{-5} 10−5,右图精度为 1 0 − 6 ) 10^{-6}) 10−6):
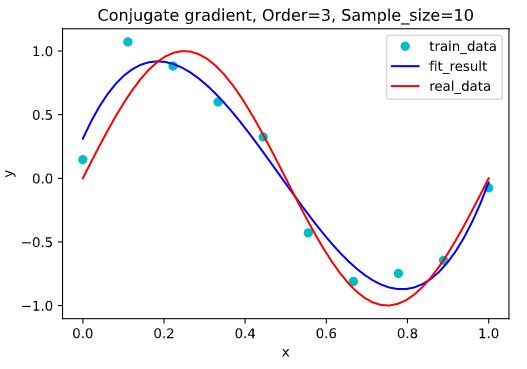
- 3阶,迭代次数:左=4,右=4
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第24张图片](http://img.e-com-net.com/image/info8/5822fef16caa40bd81da176dab699e65.jpg)
- 5阶,迭代次数:左=5,右=5
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第25张图片](http://img.e-com-net.com/image/info8/5c0e7ec13030473ea958917ffbbb09c8.jpg)
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第26张图片](http://img.e-com-net.com/image/info8/a8b03d10385249f3b516c2c5c42bbe62.jpg)
- 7阶,迭代次数:左=7,右=5
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第27张图片](http://img.e-com-net.com/image/info8/2ef013a3764f4595819d08325583327f.jpg)
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第28张图片](http://img.e-com-net.com/image/info8/5b7d1392b6584e34a8289adc68e2b2eb.jpg)
- 9阶,迭代次数:左=5,右=5
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第29张图片](http://img.e-com-net.com/image/info8/35a9c9df337a4842b236f6f3219328ed.jpg)
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第30张图片](http://img.e-com-net.com/image/info8/9f172e51d0e84059beb9c8e6bc53569b.jpg)
固定阶数为9,不同训练集大小下的拟合结果 (左图精度为 1 0 − 5 10^{-5} 10−5,右图精度为 1 0 − 6 ) 10^{-6}) 10−6):
- 训练集大小为20,迭代次数:左=5,右=7
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第31张图片](http://img.e-com-net.com/image/info8/7d4d5808b3f3499f9cfbc9e406e25976.jpg)
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第32张图片](http://img.e-com-net.com/image/info8/515b0620a31c48ea93d5e83a438cb13b.jpg)
- 训练集大小为50,迭代次数:左=5,右=7
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第33张图片](http://img.e-com-net.com/image/info8/fa16d0a6b595450683cceedb5770bfb9.jpg)
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第34张图片](http://img.e-com-net.com/image/info8/841b19b54e0c4c1ab962115efacddb4e.jpg)
- 训练集大小为100,迭代次数:左=7,右=5
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第35张图片](http://img.e-com-net.com/image/info8/b66de934958e4b7fb40c10c0b8067d2e.jpg)
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第36张图片](http://img.e-com-net.com/image/info8/1df9f5a56bc94b0c8ce503744a41e051.jpg)
从上面的图可以看出,同条件下精度为 1 0 − 6 10^{-6} 10−6的右图的拟合效果并未显著强于精度为 1 0 − 5 10^{-5} 10−5下的拟合效果,这与梯度下降的结果大相径庭。
共轭梯度法的迭代次数受精度、多项式阶、训练集的大小的影响并不大,一直稳定在 ( 1 0 0 , 1 0 1 ) (10^0, 10^1) (100,101) 级别范围内。
共轭梯度法同样满足训练集越大拟合效果也好的结论。
4.5 四种方法拟合效果对比
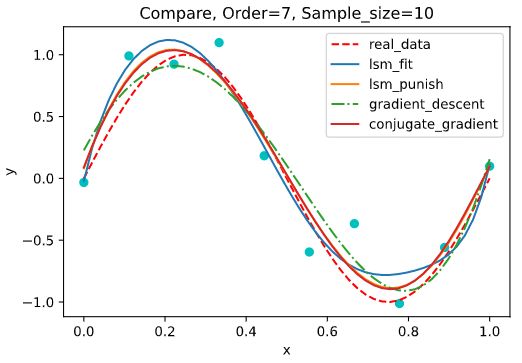
精度取 1 0 − 6 10^{-6} 10−6,训练集大小为10,不同多项式阶数的拟合效果:
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第37张图片](http://img.e-com-net.com/image/info8/3904ffc61e5440d48bff8c87355d746d.jpg)
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第38张图片](http://img.e-com-net.com/image/info8/20b607e9d5244f41ab18fe8a101c4ce2.jpg)
![[HITML] 哈工大2020秋机器学习Lab1实验报告_第39张图片](http://img.e-com-net.com/image/info8/82080bcd959842bb8743c74af613ba7a.jpg)
5 结论
在对正弦函数的多项式拟合中,多项式的次数越高,其模型能力越强,在不加正则项的情况下,高次多项式的拟合效果出现了过拟合,这是由于样本数量少但模型能力强导致的,模型拟合结果过分依赖数据集,而样本不足使得数据存在一定偶然性,这种强拟合能力可能无法拟合出正弦曲线的效果。所以增大数据集可以有效地解决过拟合问题。
在目标函数中加入参数的惩罚项后,过拟合现象得到明显改善。这是由于参数增多时,往往具有较大的绝对值,加入正则项可以有效地降低参数的绝对值,从而使模型复杂度与问题匹配。所以对于训练样本限制较多的问题,增加惩罚项是解决过拟合问题的有效手段。
在使用梯度下降时,由于我们的目标函数是二次的,只有一个极值点,即最值点,所以梯度下降的初值选取并不很重要。如果梯度下降步长设置的比较大,那么下降结果将在目标函数最值附近逐渐向上跳动,从而无法收敛。
梯度下降相比共轭梯度收敛速度很慢,迭代次数很大,而共轭梯度的稳定性较差,更容易出现过拟合现象,但对于数据量较大复杂度较高的情况,共轭梯度显然要比梯度下降来的更优。