浅析Transformer为什么在多模态任务中受欢迎的原因——以kaggle热门比赛为例
©作者 | 小欣
01 背景
多模态数据的最大挑战之一就是要汇总多种模式(或视图)中的信息,以便在过滤掉模式的冗余部分的同时,又能将补充信息考虑进来。
由于数据的异质性,自然会出现一些挑战,包括各种噪声,模式(或视图)的对齐方式等。
而Transformer,作为曾经nlp领域的SOTA模型,近些年来开始不断入驻其他领域,并拿下了SOTA结果。
随着去年ViT的出现,cv领域也同样掀起了transformer热潮,各种视觉比赛的冠军被transformer类型的模型拿下。
那么,为什么transformer为什么能适用于各种各样的领域,取得不菲的成绩,而cv领域的卷积算子却做不到,本文将以kaggle的一个热门比赛为例,浅析 transformer在多模态领域表现优秀的原因。
02 比赛介绍

kaggle比赛介绍
如上图所示,该比赛是kaggle近期举办的一个多模态任务比赛,目标是预测宠物图片欢迎度。
官方提供了9000多张宠物图像和一个csv表格,该表格记录了每张图像出现的元素成份,比如是否出现宠物眼睛,是否是全身照,是否有遮挡等信息,参赛选手的目标则是根据比赛所给的两份数据,预测这些图片的受欢迎度,方便官方实现个性化推荐的目的。
03 传统机器学习与cv模型的建模
根据比赛提供的两类数据,我们可以走两个极端以说明问题。如只使用表格数据时,实际上可以使用传统的机器学习方法进行建模,比如决策树,线性回归,朴素贝叶斯模型等,也可用性能更好的集成算法,如LGBM,随机森林等优秀算法。
该任务是回归任务,比赛官方以RMSE作为指标,所以这里给出部分传统机器学习算法的成绩。可以发现,这些模型,除了朴素贝叶斯模型外,其他模型的RMSE都差不多。
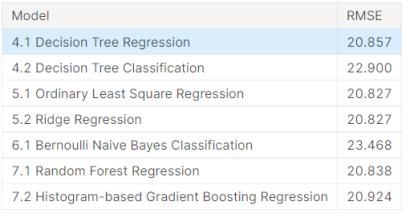
传统机器学习方法的RMSE
但不幸的是,在该比赛中单纯使用表格数据,连比赛的前50%都进不去,但传统机器学习的方法似乎也很难有效地利用图片信息。
在进一步分析,如下图所示,细看传统机器学习的预测值,它们都集中在受欢迎度的平均值附近,通过这种方法来降低损失,也就是说,传统机器学习方法实际只学到了这批数据的平均值,基本上每个机器学习方法的预测值分布图都如下所示。
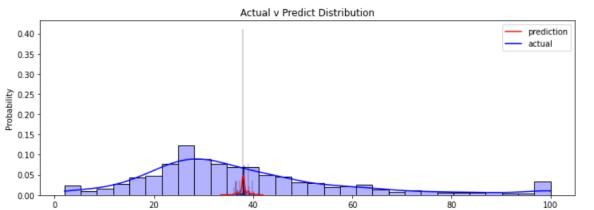
传统机器学习方法的预测值分布
而若是使用卷积神经网络,如优秀的EfficientNet,ResNet等模型,可以比较轻松的预测出每张图片的受欢迎度,由于图像信息丰富,取得的效果更好一些。
在该比赛中,有选手通过使用EfficientNet取得了18.588的RMSE成绩,下图是它的RMSE走势图,比以上的机器学习算法强一点,但仍然难以取得较好的名次,大约只有前30%的成绩。
且类似的,卷积神经网络难以对表格数据入手。这时候,如何将两种不同的数据有效地利用起来,就成了比赛的关键之处。
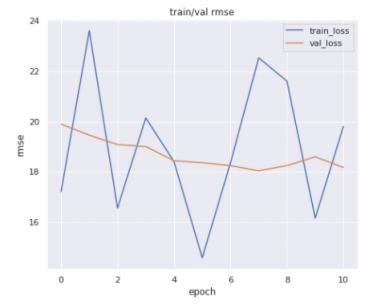
RMSE训练走势图
04 transformer称霸全场
若是按以前的做法,参赛者可能会想方设法将表格数据和图片进行一系列的处理,得到复杂的特征,最后再利用这些特征去训练回归模型,而transformer的出现,使得这一过程大大简化,事实上,该比赛已经被swin称霸,而swin则是目前cv领域最强的transformer结构的模型。
笔者认为, transformer在多模态领域的强大,是因为它自身的self-attention结构能适应各种不同类型的数据,使得各种数据在模式的对齐上表现更加优秀。
Transformer中抛弃了传统的CNN和RNN, 整个网络结构完全是由Attention机制组成。更准确地讲,Transformer由且仅由self-Attenion和Feed Forward Neural Network组成。
首先,我们从self-attention机制说起。该机制具有非常强大的特征提取功能。
正如ViT,他只是将一张图片均匀的切成九个patch,将每个patch拉成一维向量,在传入self-attention机制中,模型能通过该机制将九个patch内的信息进行交互,从而知道哪个patch比较重要,每个patch之间有何联系等,具体如下图所示。

ViT的attention机制找到了图片中最有意义的patch,从而得到了好的结果。
类似的,在其他地方, 如nlp,表格数据方面,它们一般本身是一维长序列数据, transformer同样能很好的处理他们,如下图 的nlp数据为例,
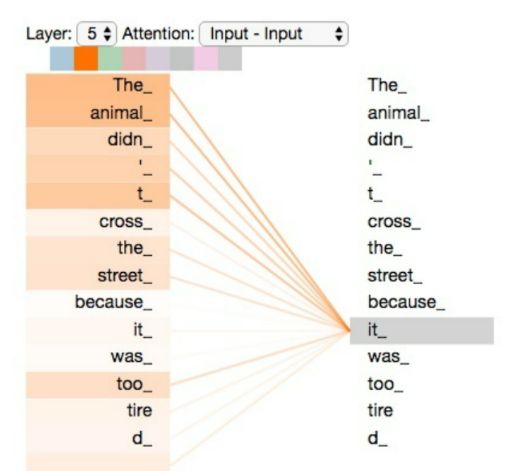
将文本数据输入模型,通过观察直线的粗细,可以发现,模型认为it指代的是这句话的animal这个名词。以上两个例子均说明了transformer在各个领域都具有优秀的表现。
再从模式的对齐这个角度阐述,以往的多模态任务,是从各个数据中获取特征,再采取其他一些attention与concat操作,将特征进行拼接之后,再传入最终的分类器进行训练,这一步,分类器会同时接受两种不同形式的数据进行学习。
使用这种方式构造出来的多模态模型会大量依赖各种模型输出的特征进行多重操作,pipeline巨大并且复杂,很难形成一个end to end的方便好用的模型。
这种操作也可以理解成获取特征的方式难以对齐。同样以上面的宠物欢迎度为例,对于图片数据,我们可能会使用CNN来获取图像内部的特征,而CNN一般是使用卷积核来获取图像局部特征的,它得到的一般也是局部特征;对于表格数据,可以使用传统机器学习方法,类似的,我们可以得到一个特征向量用来表示原来的那一行表格数据。
同样是特征,我们对不同的数据采取了完全不一样的处理方法,对于图片数据,我们获取的可能是局部特征,对于表格数据,我们获取的可能又是其他方面的特征,再将两者进行concat的时候,难免会有模式上的不对齐问题。此时的模型不仅复杂,而且可能难以处理这两种数据。
这种,transformer的出现,拯救了这一局面,因为它本身就擅长处理各种类型不同的数据,所以,如果我们使用transformer来训练模型,我们要做的只是将这些数据做一个flatten操作,再将它们进行concat等简单的操作,最后传入transformer即可,大大简化了训练的难度。
剩下的任务,就交给self-attention了,而在这个kaggle比赛中,self-attention也不负众望,能获得前20%得成绩绰绰有余。
剩下要做的就是,如何对模型进行调参,如何更有效地拼接特征,让transformer能学到更深层次的特征。
不少选手已经依靠Swin取得了17.9甚至更低的RMSE,虽然光看误差,只比卷积神经网络好了0.6的 误差,但是反映在排名上,17.9的RMSE已经具备了进入前10%,也就是铜牌的能力,该比赛的第一名的 RMSE也有17.55。
再介绍一下Swin,它是今年微软提出的最新的transformer结构模型,在各个视觉比赛榜单上取得 了良好的成绩,Swin对transformer结构内部的改进,使得transformer能捕获到各个图片位置的信息, 远远优于ViT。
最后总结一下,学者们在transformer基础上进行了一系列改进,比如cv领域的ViT,T2T,TNT等,到如今最流行的Swin,才使得transformer开始适合多模态任务,但依然有需要改进的点。
但总体上来说,对transformer多模态模型的未来,笔者持乐观态度。
私信我领取目标检测与R-CNN/数据分析的应用/电商数据分析/数据分析在医疗领域的应用/NLP学员项目展示/中文NLP的介绍与实际应用/NLP系列直播课/NLP前沿模型训练营等干货学习资源。