PyTorch的安装及基本知识
PyTorch的安装与基础知识
1. PyTorch的介绍和安装
1.1 PyTorch的介绍
PyTorch是由Facebook人工智能研究小组开发的一种基于Lua编写的Torch库的Python实现的深度学习库。它提供两个高层次的特点,ref:
- 使用GPU加速的张量计算(张量与numpy类似)
- 基于tape-based的自动求导的深度神经网络
PyTorch的优势:
- 更加简洁
- 上手快
- 有良好的文档和社区支持
- 项目开源
- 可以更好地调试代码
- 越来越完善的扩展库
关于论文中使用的PyTorch数据可以参考paperswithcode
1.2 PyTorch的安装
PyTorch的安装通常是基于Anaconda,这也是官网推荐的安装方式,因为它会下载相关的所有依赖,一般而言安装PyTorch的流程如下(这里选择基于Anaconda安装PyTorch):
- 安装Anaconda,并针对Anaconda的conda进行换源,这里参考清华源换源教程
- 新建env:
conda create -n [name] python==[version],其中name和version根据用户喜好自行选择,需要注意保证pytorch的版本和python版本兼容,官网描述支持Python3.7-3.9,笔者的命令为conda create -n pytorch python==3.7 - 根据官网选择对应版本,复制相应的命令安装即可,如下图:
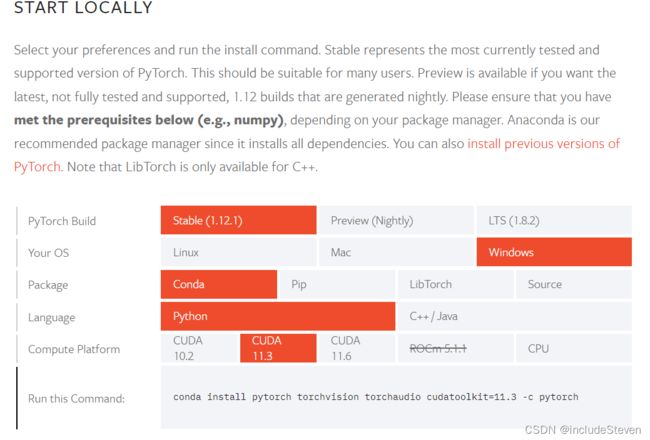
注:如果当前CUDA版本低于10.2,可以选择install previous versions of PyTorch
- 验证PyTorch是否安装成功:可以参考github的验证脚本,也可以使用简单的验证方式如下图,返回为True表示支持GPU加速:

这里需要注意的是:
PyTorch有基于CPU版本和CUDA版本:
-
CPU版本:选择CPU版本,使用conda直接安装即可
-
CUDA版本:使用CUDA版本时,需要保证当前电脑GPU版本大于等于官网对应的版本,可以在命令行中使用
nvidia-smi查看电脑GPU版本(有可能出现该命令查询不到,此时需要自行在本机搜索nvidia-smi的位置,也有可能是电脑没有GPU),如下是本机的GPU版本:

关于PyTorch的相关学习资源,可以参考链接
1.3 Jupyter的简单使用
使用Python进行数据分析、深度学习等领域,常常需要使用到Jupyter,而在安装Anaconda,默认自带Jupyter,关于Jupyter的具体介绍和使用,可以参考链接。
这里只给出其中的一些关键点:
- 安装nb_conda
- 安装jupyter_contrib_nbextensions,并选择相关插件,这里给出一些推荐的插件链接
- 在pytorch的环境下安装ipykernel,可以在jupyter的nb_conda标签中安装,也可以在命令行安装(具体安装教程参考链接的第六章),只有安装之后,才能够在Jupyter中使用到pytorch这个环境,这里给出在Jupyter中安装的流程如下:
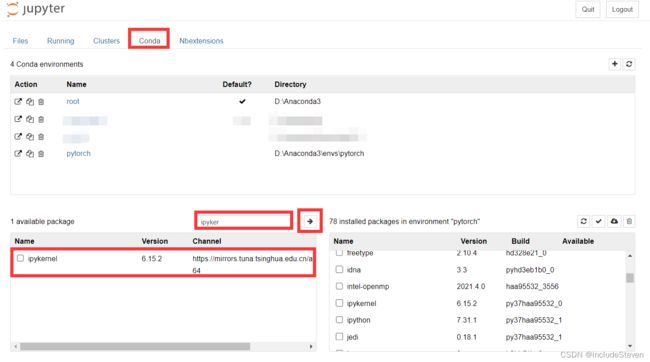
安装完成后,即可在ipynb文件中选择新的kernel:

2. PyTorch基础知识
2.1 张量
2.1.1 张量介绍
张量(Tensor):是现代机器学习的基础,和numpy中的ndarray使用上几乎完全相同。因此它主要用来存储和变换数据,那为什么不直接使用numpy中的ndarray呢?因为Tensor提供GPU计算和自动求梯度等更多功能。
那么学习张量也就和学习numpy的ndarray类似了,首先需要了解张量的创建,然后了解在张量上的操作(属性和方法)。
官方手册tutorial参考:链接
2.1.2 张量创建
这里简单介绍以下五种方式:
- 从数据中创建:torch.tensor([[1, 2], [3, 4]])
- 从numpy数组中创建:torch.from_numpy(np.array(data)),注意这里numpy数组和tensor共享内存
- 从其它张量创建:torch.ones_like(other_tensor), torch.rand_like(other_tensor)
- 从随机数创建:torch.rand((2, 3, ))
- 从常量中创建:torch.zeros((2, 3, )), torch.ones((2, 3, ))
可以发现tensor的创建和numpy的创建非常类似,因此这里也有其它的创建方式:
| 函数 | 功能 |
|---|---|
| torch.tensor(data, device, dtype) | 根据data,指定device,dtype创建tensor |
| eye(sizes) | 对角为1,其余为0 |
| arange(s, e, step) | 从s到e,步长为step |
| linspace(s, e, steps) | 从s到e,均匀分成step份 |
| normal(mean, std) | 正态分布,均值为mean,标准差为std |
| randperm(n) | 长度为n,值为[0, n-1]的随机排列 |
当然,这里还有其它非常多的创建tensor的方式,就不再一一介绍。
2.1.3 张量的属性和操作
张量的属性:
- tensor.shape
- tensor.dtype
- tensor.device
张量的操作:
- torch.add(x, y) / x + y / y.add_(x),其中的
add_()为原地修改 - 索引操作:类似于numpy,需要注意修改索引值会修改原数据值
- 维度变换:tensor.view() / tensor.reshape(),第一个共享内存,第二个不共享内存,但不保证返回的值是其拷贝值,因此不推荐使用第二个,如果需要复制一个张量并改变形状,推荐如下方式:
- tensor.clone().view()
- 扩展/压缩tensor的维度:squeeze()压缩,unsqueeze()扩展
2.1.4 广播机制
当对两个形状不同的 Tensor 按元素运算时,可能会触发广播(broadcasting)机制:先适当复制元素使这两个 Tensor 形状相同后再按元素运算。
那么如何判断两个Tensor是否满足广播机制呢?
只需要看它们的最后一个维度,只有当最后一个维度相同或者两个Tensor中的某个Tensor最后一个维度为1才满足广播机制。
2.2 自动求导
PyTorch中,所有神经网络的核心是autograd包。autograd包为张量上的所有操作都提供了自动求导机制。它是一个在运行时定义(define-by-run)的框架,这意味着反向传播是根据代码如何运行来决定的,并且每次迭代可以是不同的。
2.2.1 Autograd简介
在torch.Tensor中,通过设置requires_grad为True,那么它会追踪对于该张量的所有操作。当完成计算后可以通过调用backward()方法,自动计算所有的梯度。这个张量的所有梯度会自动累加到grad属性。
如果要阻止某个张量被追踪,可以使用detach()方法,也可以将张量的计算过程包裹在
with torch.no_grad():中,该方法在评估模型时十分有用
它的具体实现与Function类有关,通过Tensor和Function互相连接形成了无环图(acyclic graph,见下图),它编码了完整的计算历史。只要张量不是通过用户创建,而是由其它张量计算而来,那么就会把计算使用到的创建张量的Function中,如下:
x = torch.randn(3,3,requires_grad=True)
print(x.grad_fn) # 返回None,因为该张量由用户创建
y = x * 2
print(y.grad_fn) # 返回MulBackward0,因为该张量由其它张量计算而来

当使用backward()方法计算梯度时,如果张量本身是标量,则不需要传入任何参数,否则需要传入一个与张量同形的Tensor
默认情况创建张量没有指定requires_grad,则为False,可以通过requires_grad_()方法修改
2.2.2 梯度
关于梯度的计算,两个知识点:
- 雅可比矩阵,若向量函数 y ⃗ = f ( x ⃗ ) \vec{y} = f(\vec{x}) y=f(x),那么 y ⃗ \vec{y} y关于 x ⃗ \vec{x} x的梯度就是一个雅可比矩阵:
$
J=\left(\begin{array}{ccc}\frac{\partial y_{1}}{\partial x_{1}} & \cdots & \frac{\partial y_{1}}{\partial x_{n}} \ \vdots & \ddots & \vdots \ \frac{\partial y_{m}}{\partial x_{1}} & \cdots & \frac{\partial y_{m}}{\partial x_{n}}\end{array}\right)
$
- 链式求导法则:h(x) = f(g(x)),则 h ′ ( x ) = f ′ ( g ( x ) ) ∗ g ′ ( x ) h'(x) = f'(g(x)) * g'(x) h′(x)=f′(g(x))∗g′(x)
在实际情况中,一般会得到 y ⃗ \vec{y} y的损失函数,即 l = g ( y ⃗ ) l = g(\vec{y}) l=g(y),其中l是标量,因此其梯度 v = ( ∂ l ∂ y 1 ⋯ ∂ l ∂ y m ) v = \left(\begin{array}{lll}\frac{\partial l}{\partial y_{1}} & \cdots & \frac{\partial l}{\partial y_{m}}\end{array}\right) v=(∂y1∂l⋯∂ym∂l),最后可得梯度关于 x ⃗ \vec{x} x的关系为 v J = ( ∂ l ∂ y 1 ⋯ ∂ l ∂ y m ) ( ∂ y 1 ∂ x 1 ⋯ ∂ y 1 ∂ x n ⋮ ⋱ ⋮ ∂ y m ∂ x 1 ⋯ ∂ y m ∂ x n ) = ( ∂ l ∂ x 1 ⋯ ∂ l ∂ x n ) v J=\left(\begin{array}{lll}\frac{\partial l}{\partial y_{1}} & \cdots & \frac{\partial l}{\partial y_{m}}\end{array}\right)\left(\begin{array}{ccc}\frac{\partial y_{1}}{\partial x_{1}} & \cdots & \frac{\partial y_{1}}{\partial x_{n}} \\ \vdots & \ddots & \vdots \\ \frac{\partial y_{m}}{\partial x_{1}} & \cdots & \frac{\partial y_{m}}{\partial x_{n}}\end{array}\right)=\left(\begin{array}{lll}\frac{\partial l}{\partial x_{1}} & \cdots & \frac{\partial l}{\partial x_{n}}\end{array}\right) vJ=(∂y1∂l⋯∂ym∂l)⎝ ⎛∂x1∂y1⋮∂x1∂ym⋯⋱⋯∂xn∂y1⋮∂xn∂ym⎠ ⎞=(∂x1∂l⋯∂xn∂l)
注:grad在反向传播过程中是累加的,因此在每次运行backward()时,一般在之前会清空梯度
out = x.sum()
out.backwar()
print(x.grad)
out2 = x.sum()
x.grad.data.zero_() # 清空x的梯度
out2.backward()
print(x.grad)
当使用backward()方法时,如果对象不是标量,需要将这个向量(只需要保证和被计算向量同size即可)作为参数传给backward
如果我们只想修改tensor的数值,而不希望被autograd记录,可以直接对tensor.data进行操作,从而避免影响到梯度的计算,如下图:

2.3 并行计算简介
2.3.1 并行计算介绍
通过使用GPU,可以让模型训练的更快,这里面就使用到了并行计算的理念,而在PyTorch中的并行计算,目前只支持CUDA。
关于CUDA的补充:
- 对GPU本身的编程,是使用CUDA语言实现
- 在使用PyTorch时,使用的CUDA表示要开始使用GPU进行并行计算
在PyTorch中使用GPU开始计算,只需要使用.cuda()即可,其功能是让我们的模型或者数据从CPU迁移到GPU(0)中,通过GPU开始计算。
补充:
-
数据在GPU和CPU之间传递比较耗时,应尽量避免数据的切换
-
GPU运算很快,但是在进行简单的操作时,应该尽量使用CPU完成
-
默认tensor.cuda()会把tensor保存到第一块GPU,等价于tensor.cuda(0),这可能导致out of memory错误,可以通过以下两种方式设置
-
import os os.environ["CUDA_VISIBLE_DEVICE"] = "2" # 设置默认的显卡 -
CUDA_VISBLE_DEVICE=0,1 python train.py # 使用0,1两块GPU
-
2.3.2 常见的并行方法
- Network partitioning:将网络拆分分布到不同的设备,会遇到GPU的通信问题
- Layer-wise partitioning:将同一层的任务拆分分布到不同的设备,也会遇到GPU的通信问题
- Data parallelism:不拆分模型,而将数据拆分训练同一模型,然后再进行汇总反传,也是目前的主流方式
References
- 深入浅出PyTorch第一章PyTorch的简介和安装
- 深入浅出PyTorch第二章基础知识