初识知识蒸馏
这里写自定义目录标题
- 知识蒸馏
-
- 1知识蒸馏的作用
- 2怎么做到?
- 3到底怎么实现?
- 注:
知识蒸馏
1知识蒸馏的作用
知识蒸馏的概念来源于大牛Hinton在2015年的一篇文章,在文中首次提出了知识蒸馏的概念。大牛就是大牛眼光独到,早在2015年深度学习起步的时刻就看到了深度学习网络的最大痛点,那就是深度学习网络虽然有极强的学习能力,理论上可以完成对任意函数的无限逼近,可以完成机器视觉、语音识别等一系列棘手的问题,但却面临着程序设计的最大问题-----时间与空间, 复杂的网络结构带来了准确度的提高,但免不了受到硬件的制约,我们不可能让网络无限复杂来达到我们的目的。在实际的部署和使用中我们不得不采用相对简单的网络结构来满足延迟、时间、功耗的要求。针对这一痛点Hinton提出来知识蒸馏的概念。
知识的蒸馏的目的是使用一个小型网络来迁移复杂网络所学到的知识, 在复杂度较小的网络中实现与复杂网络相差无几的准确率。
2怎么做到?
重点来了,这是怎么做到的呢,这里我们以最简单的图像分类问题举例来进行说明,在进行图像分类是我们在神经网络的最后一层的linear后使用softmax函数以及进行onehot处理,我们在使用softmax后使得正确标签的权值得到来放大,其他标签的权值减小,这样我们在进行loss回归的时候就会让网络学习到正确的权值信息。但这样还存存在一个问题,其他的标签难道就没有任何意义吗?比如我们预测汽车的概率为0.6, 自行车的概率为0.05, 人的概率为0.001那么在进行loss计算的时候预测汽车的那一部分权值得到加强,其他部分基本不变, 因为loss基本为零,但事实上为自行车的概率远大于为人的概率,这也是网络学到的知识,但因为权值很小,所以冗余在网络中。这部分知识称之为暗知识,模型蒸馏的作用就是让小型网络学习的过程中也学到大型网络中存在的暗知识。这里我们通过带温度系数的softmax来实现,当温度升高时,暗知识的权值也会提高,这样我们可以学到更多的暗知识,而不是让其冗余在网络中。通过这种方法我们可以让有限的网络学习到更多的知识来进行任务处理。
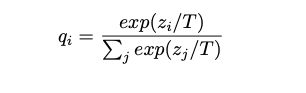
3到底怎么实现?
具体实现可以分为两步,第一步是训练大型网络获得良好的性能,这个网络也称为教师网络。
二、建立学生网络模型,模型的输出采用传统的softmax函数,拟合目标为one-hot形式的训练集输出,它们之间的距离记为loss1。
三、将训练完成的教师网络的softmax分类器加入温度参数,作为具有相同温度参数softmax分类器的学生网络的拟合目标,他们之间的距离记为loss2。
四、引入参数alpha,将loss1×(1-alpha)+loss2×alpha作为网络训练时使用的loss,训练网络。
重点就在于将暗知识放大之后,让学生网络的暗知识去拟合教师网络的暗知识,同时由于教师网络会带有一定的bias,表现为教师网络在训练完成后,对训练集识别的正确率会高于测试集,所以加上loss1来减缓这种趋势,实际应用的时候,可以考虑将alpha首先设置的接近1,比如0.95啥的,来快速拟合教师网络,再逐步调低alpha的值,来确保网络的分类正确率。

注:
本文仅提供了知识蒸馏的主观理解,具体原理可参考原论文。
这里提供一个简单实现蒸馏网络的脚本(无法直接运行,帮助理解):
# -*- coding: utf-8 -*-
import torch
import torchvision
import torchvision.transforms as transforms
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
trainset = torchvision.datasets.CIFAR10(root='./', train=True,
download=True, transform=transform_train)
testset = torchvision.datasets.CIFAR10(root='./', train=False,
download=True, transform=transform_test)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=100,
shuffle=False, num_workers=2)
testloader = torch.utils.data.DataLoader(testset, batch_size=100,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
import torch.nn as nn
import torch.nn.functional as F
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_planes, planes, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion*planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion*planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = F.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, in_planes, planes, stride=1):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, self.expansion*planes, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(self.expansion*planes)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion*planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion*planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
out += self.shortcut(x)
out = F.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, num_blocks, num_classes=10):
super(ResNet, self).__init__()
self.in_planes = 32
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(32)
self.layer1 = self._make_layer(block, 32, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 64, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 128, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 256, num_blocks[3], stride=2)
self.linear = nn.Linear(256*block.expansion, num_classes)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = F.avg_pool2d(out, 4)
out = F.dropout(out, 1)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
"""
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
netT = torch.load('teacher.pkl')
netT.to(device)
soft_target = torch.tensor([]).to(device)
with torch.no_grad():
for data in trainloader:
images, _ = data
images = images.to(device)
outputs = netT(images)
soft_target = torch.cat((soft_target, outputs), 0)
soft_target.to("cpu")
trainloader = torch.utils.data.DataLoader(trainset, batch_size=50000,
shuffle=False, num_workers=2)
with torch.no_grad():
for data in trainloader:
images, labels = data
softset = torch.utils.data.TensorDataset(images, labels, soft_target)
"""
class _ConvLayer(nn.Sequential):
def __init__(self, num_input_features, num_output_features, drop_rate):
super(_ConvLayer, self).__init__()
self.add_module('conv', nn.Conv2d(num_input_features, num_output_features,
kernel_size=3, stride=1, padding=1, bias=False)),
self.add_module('relu', nn.ReLU(inplace=True)),
self.add_module('norm', nn.BatchNorm2d(num_output_features)),
self.drop_rate = drop_rate
def forward(self, x):
x = super(_ConvLayer, self).forward(x)
if self.drop_rate > 0:
x = F.dropout(x, p=self.drop_rate, training=self.training)
return x
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.features = nn.Sequential()
self.features.add_module('convlayer1', _ConvLayer(3, 32, 0.0))
self.features.add_module('maxpool', nn.MaxPool2d(2, 2))
self.features.add_module('convlayer3', _ConvLayer(32, 64, 0.0))
self.features.add_module('avgpool', nn.AvgPool2d(2, 2))
self.features.add_module('convlayer5', _ConvLayer(64, 128, 0.0))
self.classifier = nn.Linear(128, 10)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
def forward(self, x):
features = self.features(x)
out = F.avg_pool2d(features, kernel_size=8, stride=1).view(features.size(0), -1)
out = self.classifier(out)
return out
net = CNN()
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
criterion2 = nn.KLDivLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net.to(device)
netT = torch.load('./saved_pkl/teacher.pkl', map_location=torch.device(device))
netT.to(device)
import time
for epoch in range(2):
time_start=time.time()
running_loss = 0.
batch_size = 128
alpha = 0.95
for i, data in enumerate(
torch.utils.data.DataLoader(trainset, batch_size=batch_size,
shuffle=True, num_workers=0), 0):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
soft_target = netT(inputs)
optimizer.zero_grad()
outputs = net(inputs)
loss1 = criterion(outputs, labels)
T = 2
outputs_S = F.log_softmax(outputs/T, dim=1)
outputs_T = F.softmax(soft_target/T, dim=1)
loss2 = criterion2(outputs_S, outputs_T) * T * T
# 这里这样的原因是在torch中没有开发可以改变t的softmax和log_softmax函数,所以在做loss的时候采用的是在outout上/然后在反向传播后要要再乘t平方
loss = loss1*(1-alpha) + loss2*alpha
loss.backward()
optimizer.step()
print('[%d, %5d] loss: %.4f loss1: %.4f loss2: %.4f' %(epoch + 1, (i+1)*batch_size, loss.item(), loss1.item(), loss2.item()))
torch.save(net, 'student.pkl')
time_end=time.time()
print('Time cost:',time_end-time_start, "s")
print('Finished Training')
# torch.save(net, 'student.pkl')
# net = torch.load('student.pkl')
net.eval()
import time
time_start=time.time()
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %f %%' % (
100 * correct / total))
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch.no_grad():
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
for i in range(4):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
for i in range(10):
print('Accuracy of %5s : %2f %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))
time_end=time.time()
print('Time cost:',time_end-time_start, "s")