模型压缩中知识蒸馏技术原理及其发展现状和展望
知识蒸馏是非常经典的基于迁移学习的模型压缩技术,在学术界的研究非常活跃,工业界也有许多的应用和较大的潜力,本文给大家梳理知识蒸馏的核心技术,发展现状,未来展望以及学习资源推荐。
1 知识蒸馏基础
1.1 什么是知识蒸馏
一般地,大模型往往是单个复杂网络或者是若干网络的集合,拥有良好的性能和泛化能力,而小模型因为网络规模较小,表达能力有限。利用大模型学习到的知识去指导小模型训练,使得小模型具有与大模型相当的性能,但是参数数量大幅降低,从而可以实现模型压缩与加速,就是知识蒸馏与迁移学习在模型优化中的应用。
Hinton等人最早在文章“Distilling the knowledge in a neural network”[1]中提出了知识蒸馏这个概念,其核心思想是一旦复杂网络模型训练完成,便可以用另一种训练方法从复杂模型中提取出来更小的模型,因此知识蒸馏框架通常包含了一个大模型(被称为teacher模型),和一个小模型(被称为student模型)。
1.2 为什么要进行知识蒸馏
以计算机视觉模型的训练为例,我们经常用在ImageNet上训练的模型作为预训练模型,之所以可以这样做,是因为深度学习模型在网络浅层学习的知识是图像的色彩和边缘等底层信息,某一个数据集学习到的信息也可以应用于其他领域。
那实际上知识蒸馏或者说迁移学习的必要性在哪里?
(1) 数据分布差异。深度学习模型的训练场景和测试场景往往有分布差异,以自动驾驶领域为例,大部分数据集的采集都是基于白天,光照良好的天气条件下,在这样的数据集上训练的模型,当将其用于黑夜,风雪等场景时,很有可能会无法正常工作,从而使得模型的实用性能非常受限。因此,必须考虑模型从源域到目标域的迁移能力。
(2) 受限的数据规模。数据的标注成本是非常高的,导致很多任务只能用少量的标注进行模型的训练。以医学领域为典型代表,数据集的规模并不大,因此在真正专用的模型训练之前往往需要先在通用任务上进行预训练。
(3) 通用与垂直领域。虽然我们可以训练许多通用的模型,但是真实需求是非常垂直或者说个性化的,比如ImageNet存在1000类,但是我们可能只需要用到其中若干类。此时就可以基于1000类ImageNet模型进行知识迁移,而不需要完全从头开始训练。
因此,在工业界对知识蒸馏和迁移学习也有着非常强烈的需求,接下来我们讲解其中的主要算法。
2 知识蒸馏主要算法
知识蒸馏是对模型的能力进行迁移,根据迁移的方法不同可以简单分为基于目标驱动的算法,基于特征匹配的算法两个大的方向,下面我们对其进行介绍。
2.1 知识蒸馏基本框架
Hinton最早在文章“Distilling the knowledge in a neural network”中提出了知识蒸馏的概念,即knowledge distilling,对后续的许多算法都产生了影响,其框架示意图如下:
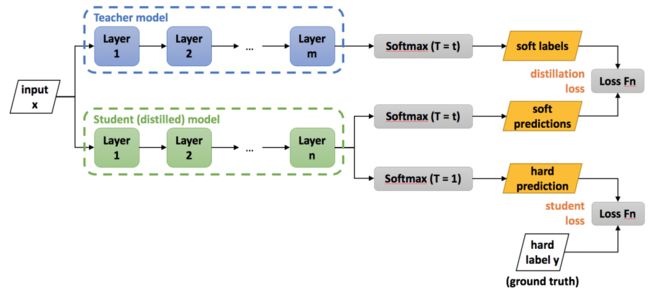
从上图中可以看出,包括一个teacher model和一个student model,teacher model需要预先训练好,使用的就是标准分类softmax损失,但是它的输出使用带温度参数T的softmax函数进行映射,如下:

当T=1时,就是softmax本身。当T>1,称之为soft softmax,T越大,因为输入zk产生的概率f(zk)差异就会越小。
之所以要这么做,其背后的思想是当训练好一个模型之后,模型为所有的误标签都分配了很小的概率。然而实际上对于不同的错误标签,其被分配的概率仍然可能存在数个量级的悬殊差距。这个差距,在softmax中直接就被忽略了,但这其实是一部分有用的信息。
训练的时候小模型有两个损失,一个是与真实标签的softmax损失,一个是与teacher model的蒸馏损失,定义为KL散度。
当teacher model和student model各自的预测概率为pi,qi时,其蒸馏损失部分梯度传播如下:
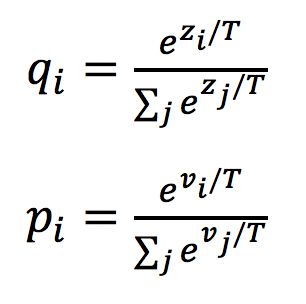
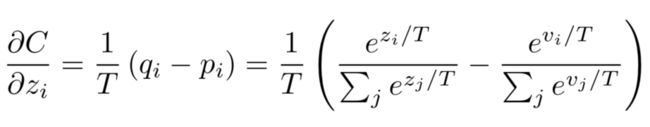
可以看出形式非常的简单,梯度为两者预测概率之差,这就是最简单的知识蒸馏框架。
2.2 优化目标驱动的知识蒸馏框架
Hinton等人提出的框架是在模型最后的预测端,让student模型学习到与teacher模型的知识,这可以称之为直接使用优化目标进行驱动的框架,类似的还有ProjectionNet[2]。

PrjojectNet同时训练一个大模型和一个小模型,两者的输入都是样本,其中大模型就是普通的CNN网络,而小模型会对输入首先进行特征投影。每一个投影矩阵P都对应了一个映射,由一个d-bit长的向量表示,其中每一个bit为0或者1,这是一个更加稀疏的表达。特征用这种方法简化后自然就可以使用更加轻量的网络的结构进行训练。
那么怎么完成这个过程呢?文中使用的是locality sensitive hashing(LSH)算法,这是一种聚类任务中常用的降维的算法。
优化目标包含了3部分,分别是大模型的损失,投影损失,以及大模型和小模型的预测损失,全部使用交叉熵,各自定义如下:

基于优化目标驱动的方法其思想是非常直观,就是结果导向型,中间怎么实现的不关心,对它进行改进的一个有趣方向是GAN的运用。

2.3 特征匹配的知识蒸馏框架
结果导向型的知识蒸馏框架的具体细节是难以控制的,会让训练变得不稳定且缓慢。一种更直观的方式是将teacher模型和student模型的特征进行约束,从而保证student模型确实继承了teacher模型的知识,其中一个典型代表就是FitNets[3],FitNets将比较浅而宽的Teacher模型的知识迁移到更窄更深的Student模型上,框架如下:

FitNets背后的思想是,用网络的中间层的特征进行匹配,不仅仅是在输出端。
它的训练包含了两个阶段:
第一阶段就是根据Teacher模型的损失来指导预训练Student模型。记Teacher网络的某一中间层的权值Wt为Whint,意为指导的意思。Student网络的某一中间层的权值Ws为Wguided,即被指导的意思,在训练之初Student网络进行随机初始化。
我们需要学习一个映射函数Wr使得Wguided的维度匹配Whint,得到Ws',并最小化两者网络输出的MSE差异作为损失,如下:

第二个训练阶段,就是对整个网络进行知识蒸馏训练,与上述Hinton等人提出的策略一致。
不过FitNet直接将特征值进行了匹配,先验约束太强,有的框架对激活值进行了归一化[4]。

基于特征空间进行匹配的方法其实是知识蒸馏的主流,类似的方法非常多,包括注意力机制的使用[5],类似于风格迁移算法的特征匹配[6]等。
3 知识蒸馏算法的展望
上一节我们介绍了知识蒸馏的基本方法,当然知识蒸馏还有非常多有意思的研究方向,这里我们介绍其中几个。
3.1 不压缩模型
机器学习模型要解决的问题如下,其中y是预测值,x是输入,L是优化目标,θ1是优化参数。

因为深度学习模型没有解析解,往往无法得到最优解,我们经常会通过添加一些正则项来促使模型达到更好的性能。
Born Again Neural Networks[7]框架思想是通过增加同样的模型架构,并且重新进行优化,以增加一个模型为例,要解决的问题如下:

具体的流程就是:
(1) 训练一个教师模型使其收敛到较好的局部值。
(2) 对与教师模型结构相同的学生模型进行初始化,其优化目标包含两部分,一部分是要匹配教师模型的输出分布,比如采用KL散度,另一部分就是与教师模型训练时同样的目标,即数据集的预测真值。
然后通过下面这样的流程,一步一步往下传,所以被形象地命名为“born again”。

类似的框架还有Net2Net,network morphism等。
3.2 去掉teacher模型
一般知识蒸馏框架都需要包括一个Teacher模型和一个Student模型,而Deep mutual learning[8]则没有Teacher模型,它通过多个小模型进行协同训练,框架示意图如下。

Deep mutual learning在训练的过程中让两个学生网络相互学习,每一个网络都有两个损失。一个是任务本身的损失,另外一个就是KL散度。由于KL散度是非对称的,所以两个网络的散度会不同。
相比单独训练,每一个模型可以取得更高的精度。值得注意的是,就算是两个结构完全一样的模型,也会学习到不同的特征表达。
3.3 与其他框架的结合
在进行知识蒸馏时,我们通常假设teacher模型有更好的性能,而student模型是一个压缩版的模型,这不就是模型压缩吗?与模型剪枝,量化前后的模型对比是一样的。所以知识蒸馏也被用于与相关技术进行结合,apprentice[9]框架是一个代表。

网络结构如上图所示,Teacher模型是一个全精度模型,Apprentice模型是一个低精度模型。