数字图像处理 第10章——图像分割
目录
10.1 基础知识
10.2 点、线和边缘检测
10.2.1 背景知识
10.2.2 孤立点的检测
10.2.3 线检测
10.2.5 边缘模型
10.2.5 基本边缘检测
10.2.6 更先进的边缘检测技术
10.2.7 Hough变换
10.3 阈值处理
10.3.1 基础知识
10.3.2 基本的全局阈值处理
编辑10.3.3 用Otsu方法的最佳全局阈值处理
10.3.4 用图像平滑改善全局阈值处理
10.3.5 利用边缘改进全局阈值处理
10.3.6 多阈值处理
10.3.7 可变阈值处理
10.4 基于区域的分割
10.4.1 区域生长
10.4.2 区域分割与聚合
10.5 用形态学分水岭的分割
形态学图像处理中,输入的是图像,输出的是从图像中提取出来的属性,分割是该方向上的另一步骤。分割将图像细分为构成它的子区域或物体,细分的程度取决于要解决的问题。
多数分割算法均基于灰度值的两个基本性质之一:不连续性和相似性。对于不连续的灰度,方法是以灰度突变为基础分割一幅图像,比如图像的边缘。对于相似的灰度,主要方法是根据一组预定义的准则把一幅图像分割为相似的区域。阈值处理、区域生长、区域分割和区域聚合都是这类方法的例子。
10.1 基础知识
令R表示一幅图像占据的整个空间区域。我们可以将图像分割视为把R分为n个子区域R1,R2,...,Rn的过程,满足:
- (a)
 。
。 - (b)
 是一个连通集,i=1,2,...,n。
是一个连通集,i=1,2,...,n。 - (c)
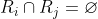 ,对于所有i和j,i≠j。
,对于所有i和j,i≠j。 - (d)
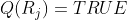 i=1,2,...,n。
i=1,2,...,n。 - (e)
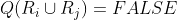 ,对于任何和
,对于任何和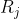 的邻接区域。
的邻接区域。
条件(a)指出,分割必须是完全的;也就是说,每个像素都必须在一个区域内。 条件(b)要求一个区域中的点以某些预定义的方式来连接(即这些点必须是4连接的或8连接的) 条件(c)指出,各个区域必须是不相交的。 条件(d)涉及分割后的区域中的像素必须满足的属性——例如,若Ri中的所有像素都有相同的灰度级。则Q(Ri)=TRUE。 最后,条件(e)指出,两个邻接区域Ri和Rj在属性Q的意义上必须是不同的。
10.2 点、线和边缘检测
本节主要介绍以灰度局部剧烈变化检测为基础的分割方法。
10.2.1 背景知识
对一幅图中灰度的突变,局部变化可以用微分来检测。因为变化短促,可以用一阶微分和二阶微分描述。数字函数的导数可用差分来定义。一维函数f(x)在点x处一阶导数的近似:
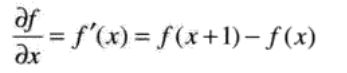
当考虑两变量的图像函数f(x,y)时,为了表示的一致性,使用偏微分。此时将处理沿两个空间轴的偏微分。
关于点x的二阶导数:
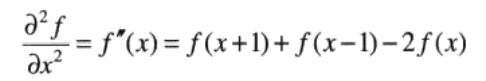
有关结论:
- 一阶导数通常在图像中产生较粗的边缘;
- 二阶导数对精细细节,如细线、孤立点和噪声有较强的相应;
- 二阶导数在灰度斜坡和灰度台阶过渡处会产生双边缘响应;
- 二阶导数的符号可用于确定边缘是从亮到暗还是从暗到亮。
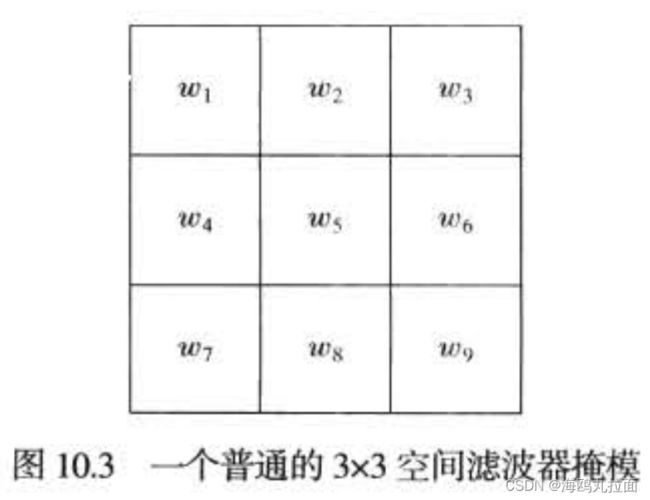
计算图像中每个像素位置处的一阶导数和二阶导数的另一种方法是使用空间滤波器。
对3*3滤波器掩膜来说,导数是计算模板系数与被该模板覆盖的区域中的灰度值的乘积之和。即模板在该区域中心点处的响应如下:

其中zk是像素的灰度,该像素的空间位置对应于模板中第k个系数的位置。
10.2.2 孤立点的检测
点的检测应以二阶导数为基础。使用拉普拉斯算子:
![]()
式中,偏微分可得:
![]()
![]()
故拉普拉斯算子是
![]()
如果在某个点处,该模板的响应的绝对值超过了某个指定的阈值,那么我们说在模板中心位置(x,y)处的该点已被检测到。在输出图像汇总,这样的带你被标注为1,而所有其他点则被标注为0,从而产生一幅二值图像。
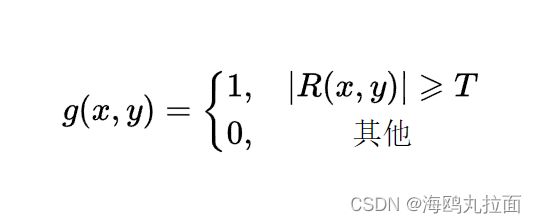
其中,g是输出图像,T为一个非负阈值。R为上述介绍过的,即模板的系数与其覆盖区域的灰度值的乘积之和,也叫作模板的响应。
当模板的中心位于一个孤立点时,模板的响应最强,而在亮度不变的区域响应为0。
10.2.3 线检测
复杂度更高的检测是线检测。对于线检测,可以预期二阶导数将导致更强的响应,并产生比一阶导数更细的线。这样,对于线检测,我们也可使用拉普拉斯模板,适当处理二阶导数的双线效应。
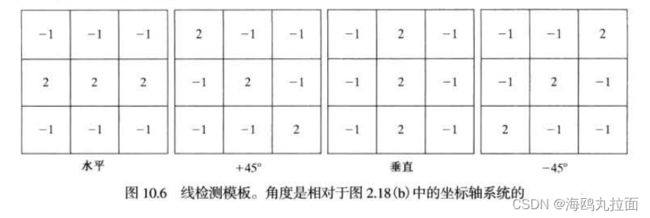
第一个模板对水平方向的线有最佳响应;第二个模板对45°方向的线有最佳响应;第三个模板对垂直方向的线有最佳响应;第四个模板对-45°方向的线有最佳响应。每个模板的首选方向用一个比其他方向更大的系数(如2)加权。每个模板中系数之和为0,表明恒定灰度区域中的响应为0。
若对检测图像中由给定模板定义的方向上的所有线感兴趣,则只须简单对图像运用这个模板,并对结果的绝对值进行阈值处理。留下的点是有最强响应的点,这些点与模板的方向最为接近,且组成了只有一个像素宽的线。
10.2.5 边缘模型
边缘检测是基于灰度突变来分割图像的方法
边缘模型根据它们的灰度剖面分为:台阶模型、斜坡模型和屋顶模型
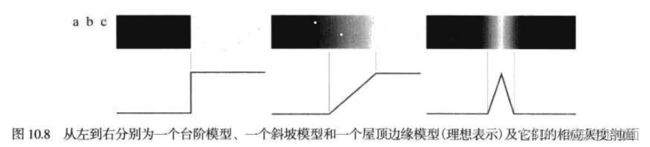
- 台阶边缘是指在1像素的距离上出现两个灰度级间的理想过渡
- 实际中,数字图像都存在被模糊且带有噪声的边缘,模糊的程度主要取决于聚焦机理(如光学成像中的镜头)中的限制,而噪声水平主要取决于成像系统的电子元件。在这种情况下,边缘被建模为一个更接近灰度斜坡的剖面。斜坡的斜度与边缘的模糊程度成反比。
- 屋顶边缘是通过一个区域的线的模型,屋顶边缘的基底(宽度)由该线的宽度和尖锐度觉得。
结论:
- 对图像中的每条边缘,二阶导数生成两个值(一个不希望的特点);
- 二阶导数的零交叉点可用于定位粗边缘的中心,正如我们将在本节稍后将要说明的那样。某些边缘模型可用来在进入和离开斜坡的地方平滑过渡。
执行边缘检测的三个基本步骤:
- 为降噪对图像进行平滑处理。
- 边缘点的检测。如先前提及得那样,这是一个局部操作,从一幅图像中提取所有的点,这些点是变为边缘点的潜在候选者。
- 边缘定位。这一步的目的是从候选边缘点中选择组成边缘点集合的真实成员。
10.2.5 基本边缘检测
图像梯度及其性质
图像f(x,y)位置处寻找边缘的强度和方向用梯度表征,用 ![]() 表示,并用向量来定义:
表示,并用向量来定义:
![]()
该向量有一个重要的几何性质,即指出了f在位置(x,y)处的最大变化率的方向。
向量![]() 的大小(长度)表示为M(x,y),即
的大小(长度)表示为M(x,y),即
![]()
梯度向量的方向由下列对于x轴度量的角度给出:
![]()
任意点(x,y)处一个边缘的方向与该点处梯度向量的方向α(x,y)正交。
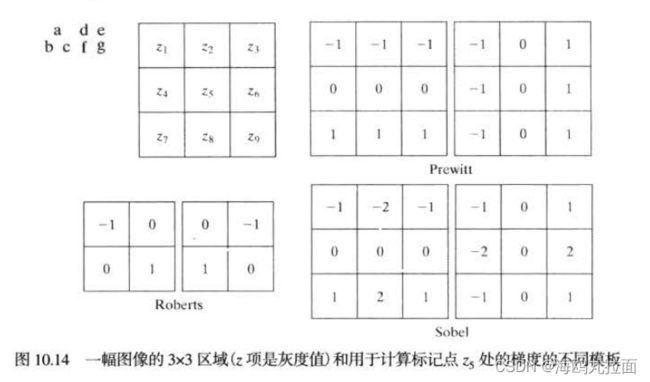
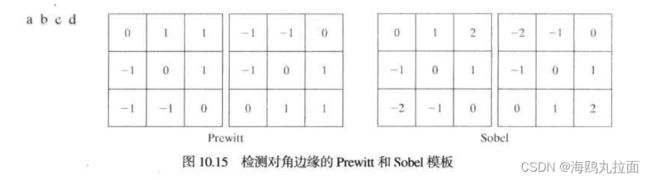
梯度算子
罗伯特交叉梯度算子(Roberts)
![]()
Prewitt算子 检测水平和竖直方向
Sobel算子 检测水平和数值方向,但中心系数上使用一个权值2
10.2.6 更先进的边缘检测技术
这些技术试图通过考虑如图像噪声和边缘本身特性等因素来改善简单的边缘检测方法。
Marr-Hildreth 边缘检测器
Marr and Hildreth证明了:
- 灰度变化并非与图像尺寸无关,这意味着它们的检测需要使用不同尺寸的算子。
- 灰度的突然变化会在一阶导数中导致波峰或波谷,或在二阶导数中等效地引起零交叉。
Marr and Hildreth证明,满足这些条件的最令人满意的算子是滤波器![]() 。
。![]() 是拉普拉斯算子,而G是标准差为
是拉普拉斯算子,而G是标准差为 (有时也称为空间常数)的二维高斯函数
(有时也称为空间常数)的二维高斯函数
![]()
最正得到表达式:
![]()

算法步骤:
- 对输入图像使用n*n高斯低通滤波器进行滤波;
- 计算滤波后图像的拉普拉斯;
- 寻找g(x,y)的零交叉来确定f(x,y)中边缘的位置。
![]()
高斯低通滤波器大小的选择,即n值应是大于等于6σ的最小奇整数。
坎尼边缘检测器
坎尼方法基于三个基本目标:
- 低错误率。所有边缘都应被找到,并且应该没有伪响应。即检测到的边缘必须尽可能是真实的边缘。
- 边缘点应被很好地定位。已定位边缘必须尽可能接近真实边缘。即由检测器标记为边缘的点和真实边缘的中心之间的距离应该最小。
- 单一的边缘点响应。对于真实的边缘点,检测器仅应返回一个点。即真实边缘周围的局部最大数应该是最小的。这意味着在仅存一个单一边缘点的位置,检测器不应指出多个边缘像素。
算法步骤:
- 用一个高斯滤波器平滑输入图像。
- 计算梯度幅值图像和角度图像。
- 对梯度幅值图像应用非最大抑制。
- 用双阈值处理和连接分析来检测并连接边缘。
----------------Sobel算法----------------
import cv2 as cv
import matplotlib.pyplot as plt
import numpy as np
src = cv.imread(r"G:\\11.jpg", 0) # 直接以灰度图方式读入
img = src.copy()
# 计算Sobel卷积结果
x = cv.Sobel(img, cv.CV_16S, 1, 0)
y = cv.Sobel(img, cv.CV_16S, 0, 1)
# 转换数据 并 合成
Scale_absX = cv.convertScaleAbs(x) # 格式转换函数
Scale_absY = cv.convertScaleAbs(y)
result = cv.addWeighted(Scale_absX, 0.5, Scale_absY, 0.5, 0) # 图像混合
# 显示图像
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(10, 8), dpi=100)
axes[0].imshow(img, cmap=plt.cm.gray)
axes[0].set_title("原图")
axes[1].imshow(result, cmap=plt.cm.gray)
axes[1].set_title("Sobel检测后结果")
plt.show()
----------------prewitt算法----------------
import cv2
import numpy as np
from scipy import signal
def prewitt(I, _boundary = 'symm', ):
# prewitt算子是可分离的。 根据卷积运算的结合律,分两次小卷积核运算
# 算子分为两部分,这是对第一部分操作
# 1: 垂直方向上的均值平滑
ones_y = np.array([[1], [1], [1]], np.float32)
i_conv_pre_x = signal.convolve2d(I, ones_y, mode='same', boundary=_boundary)
# 2: 水平方向上的差分
diff_x = np.array([[1, 0, -1]], np.float32)
i_conv_pre_x = signal.convolve2d(i_conv_pre_x, diff_x, mode='same', boundary=_boundary)
# 算子分为两部分,这是对第二部分操作
# 1: 水平方向上的均值平滑
ones_x = np.array([[1, 1, 1]], np.float32)
i_conv_pre_y = signal.convolve2d(I, ones_x, mode='same', boundary=_boundary)
# 2: 垂直方向上的差分
diff_y = np.array([[1], [0], [-1]], np.float32)
i_conv_pre_y = signal.convolve2d(i_conv_pre_y, diff_y, mode='same', boundary=_boundary)
return (i_conv_pre_x, i_conv_pre_y)
if __name__ == '__main__':
I = cv2.imread(r'G:\11.jpg', cv2.IMREAD_GRAYSCALE)
cv2.imshow('origin', I)
i_conv_pre_x, i_conv_pre_y = prewitt(I)
# 取绝对值,分别得到水平方向和垂直方向的边缘强度
abs_i_conv_pre_x = np.abs(i_conv_pre_x)
abs_i_conv_pre_y = np.abs(i_conv_pre_y)
# 水平方向和垂直方向上的边缘强度的灰度级显示
edge_x = abs_i_conv_pre_x.copy()
edge_y = abs_i_conv_pre_y.copy()
# 将大于255的值截断为255
edge_x[edge_x > 255] = 255
edge_y[edge_y > 255] = 255
# 数据类型转换
edge_x = edge_x.astype(np.uint8)
edge_y = edge_y.astype(np.uint8)
# 显示
cv2.imshow('edge_x', edge_x)
cv2.imshow('edge_y', edge_y)
# 利用abs_i_conv_pre_x 和 abs_i_conv_pre_y 求最终的边缘强度
# 求边缘强度有多重方法, 这里使用的是插值法
edge = 0.5 * abs_i_conv_pre_x + 0.5 * abs_i_conv_pre_y
# 边缘强度灰度级显示
edge[edge > 255] = 255
edge = edge.astype(np.uint8)
cv2.imshow('edge', edge)
cv2.waitKey(0)
cv2.destroyAllWindows()
----------------Roberts算法----------------
import cv2
import numpy as np
from scipy import signal
def roberts(I, _boundary='fill', _fillvalue=0):
# 图像的高,宽
H1, W1 = I.shape[0:2]
# 卷积核的尺寸
H2, W2 = 2, 2
# 卷积核1 和 锚点的位置
R1 = np.array([[1, 0], [0, -1]], np.float32)
kr1, kc1 = 0, 0
# 计算full卷积
IconR1 = signal.convolve2d(I, R1, mode='full', boundary=_boundary, fillvalue=_fillvalue)
IconR1 = IconR1[H2 - kr1 - 1:H1 + H2 - kr1 - 1, W2 - kc1 - 1:W1 + W2 - kc1 - 1]
# 卷积核2 和 锚点的位置
R2 = np.array([[0, 1], [-1, 0]], np.float32)
kr2, kc2 = 0, 1
# 再计算full卷积
IconR2 = signal.convolve2d(I, R2, mode='full', boundary=_boundary, fillvalue=_fillvalue)
IconR2 = IconR2[H2 - kr2 - 1:H1 + H2 - kr2 - 1, W2 - kc2 - 1:W1 + W2 - kc2 - 1]
return (IconR1, IconR2)
if __name__ == '__main__':
I = cv2.imread(r'G:\11.jpg', cv2.IMREAD_GRAYSCALE)
# 显示原图
cv2.imshow('origin', I)
# 卷积,注意边界一般扩充采用的symm
IconR1, IconR2 = roberts(I, 'symm')
# 45度方向上的边缘强度的灰度级显示
IconR1 = np.abs(IconR1)
edge45 = IconR1.astype(np.uint8)
cv2.imshow('edge45', edge45)
# 135度方向上的边缘强度的灰度级显示
IconR2 = np.abs(IconR2)
edge135 = IconR2.astype(np.uint8)
cv2.imshow('edge135', edge135)
# 用平方和的开方来衡量最后输出的边缘
edge = np.sqrt(np.power(IconR1, 2.0) + np.power(IconR2, 2.0))
edge = np.round(edge)
edge[edge > 255] = 255
edge = edge.astype(np.uint8)
# 显示边缘
cv2.imshow('edge', edge)
cv2.waitKey(0)
cv2.destroyAllWindows()
----------------log算法----------------
import cv2 as cv
import matplotlib.pyplot as plt
# 读取图像
img = cv.imread(r"G:\11.jpg")
rgb_img = cv.cvtColor(img, cv.COLOR_BGR2RGB)
gray_img = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# 先通过高斯滤波降噪
gaussian = cv.GaussianBlur(gray_img, (3, 3), 0)
# 再通过拉普拉斯算子做边缘检测
dst = cv.Laplacian(gaussian, cv.CV_16S, ksize=3)
LOG = cv.convertScaleAbs(dst)
# 用来正常显示中文标签
plt.rcParams['font.sans-serif'] = ['SimHei']
# 显示图形
titles = ['原始图像', 'LOG 算子']
images = [rgb_img, LOG]
for i in range(2):
plt.subplot(1, 2, i + 1), plt.imshow(images[i], 'gray')
plt.title(titles[i])
plt.xticks([]), plt.yticks([])
plt.show()
----------------Canny算法----------------
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
def smooth(image, sigma=1.4, length=5):
""" Smooth the image
Compute a gaussian filter with sigma = sigma and kernal_length = length.
Each element in the kernal can be computed as below:
G[i, j] = (1/(2*pi*sigma**2))*exp(-((i-k-1)**2 + (j-k-1)**2)/2*sigma**2)
Then, use the gaussian filter to smooth the input image.
Args:
image: array of grey image
sigma: the sigma of gaussian filter, default to be 1.4
length: the kernal length, default to be 5
Returns:
the smoothed image
"""
# Compute gaussian filter
k = length // 2
gaussian = np.zeros([length, length])
for i in range(length):
for j in range(length):
gaussian[i, j] = np.exp(-((i - k) ** 2 + (j - k) ** 2) / (2 * sigma ** 2))
gaussian /= 2 * np.pi * sigma ** 2
# Batch Normalization
gaussian = gaussian / np.sum(gaussian)
# Use Gaussian Filter
W, H = image.shape
new_image = np.zeros([W - k * 2, H - k * 2])
for i in range(W - 2 * k):
for j in range(H - 2 * k):
# 卷积运算
new_image[i, j] = np.sum(image[i:i + length, j:j + length] * gaussian)
new_image = np.uint8(new_image)
return new_image
def get_gradient_and_direction(image):
""" Compute gradients and its direction
Use Sobel filter to compute gradients and direction.
-1 0 1 -1 -2 -1
Gx = -2 0 2 Gy = 0 0 0
-1 0 1 1 2 1
Args:
image: array of grey image
Returns:
gradients: the gradients of each pixel
direction: the direction of the gradients of each pixel
"""
Gx = np.array([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]])
Gy = np.array([[-1, -2, -1], [0, 0, 0], [1, 2, 1]])
W, H = image.shape
gradients = np.zeros([W - 2, H - 2])
direction = np.zeros([W - 2, H - 2])
for i in range(W - 2):
for j in range(H - 2):
dx = np.sum(image[i:i + 3, j:j + 3] * Gx)
dy = np.sum(image[i:i + 3, j:j + 3] * Gy)
gradients[i, j] = np.sqrt(dx ** 2 + dy ** 2)
if dx == 0:
direction[i, j] = np.pi / 2
else:
direction[i, j] = np.arctan(dy / dx)
gradients = np.uint8(gradients)
return gradients, direction
def NMS(gradients, direction):
""" Non-maxima suppression
Args:
gradients: the gradients of each pixel
direction: the direction of the gradients of each pixel
Returns:
the output image
"""
W, H = gradients.shape
nms = np.copy(gradients[1:-1, 1:-1])
for i in range(1, W - 1):
for j in range(1, H - 1):
theta = direction[i, j]
weight = np.tan(theta)
if theta > np.pi / 4:
d1 = [0, 1]
d2 = [1, 1]
weight = 1 / weight
elif theta >= 0:
d1 = [1, 0]
d2 = [1, 1]
elif theta >= - np.pi / 4:
d1 = [1, 0]
d2 = [1, -1]
weight *= -1
else:
d1 = [0, -1]
d2 = [1, -1]
weight = -1 / weight
g1 = gradients[i + d1[0], j + d1[1]]
g2 = gradients[i + d2[0], j + d2[1]]
g3 = gradients[i - d1[0], j - d1[1]]
g4 = gradients[i - d2[0], j - d2[1]]
grade_count1 = g1 * weight + g2 * (1 - weight)
grade_count2 = g3 * weight + g4 * (1 - weight)
if grade_count1 > gradients[i, j] or grade_count2 > gradients[i, j]:
nms[i - 1, j - 1] = 0
return nms
def double_threshold(nms, threshold1, threshold2):
""" Double Threshold
Use two thresholds to compute the edge.
Args:
nms: the input image
threshold1: the low threshold
threshold2: the high threshold
Returns:
The binary image.
"""
visited = np.zeros_like(nms)
output_image = nms.copy()
W, H = output_image.shape
def dfs(i, j):
if i >= W or i < 0 or j >= H or j < 0 or visited[i, j] == 1:
return
visited[i, j] = 1
if output_image[i, j] > threshold1:
output_image[i, j] = 255
dfs(i - 1, j - 1)
dfs(i - 1, j)
dfs(i - 1, j + 1)
dfs(i, j - 1)
dfs(i, j + 1)
dfs(i + 1, j - 1)
dfs(i + 1, j)
dfs(i + 1, j + 1)
else:
output_image[i, j] = 0
for w in range(W):
for h in range(H):
if visited[w, h] == 1:
continue
if output_image[w, h] >= threshold2:
dfs(w, h)
elif output_image[w, h] <= threshold1:
output_image[w, h] = 0
visited[w, h] = 1
for w in range(W):
for h in range(H):
if visited[w, h] == 0:
output_image[w, h] = 0
return output_image
if __name__ == "__main__":
# code to read image
image = cv.imread(r'G:\11.jpg', 0)
cv.imshow("Original", image)
smoothed_image = smooth(image)
cv.imshow("GaussinSmooth(5*5)", smoothed_image)
gradients, direction = get_gradient_and_direction(smoothed_image)
# print(gradients)
# print(direction)
nms = NMS(gradients, direction)
output_image = double_threshold(nms, 40, 100)
cv.imshow("outputImage", output_image)
cv.waitKey(0)
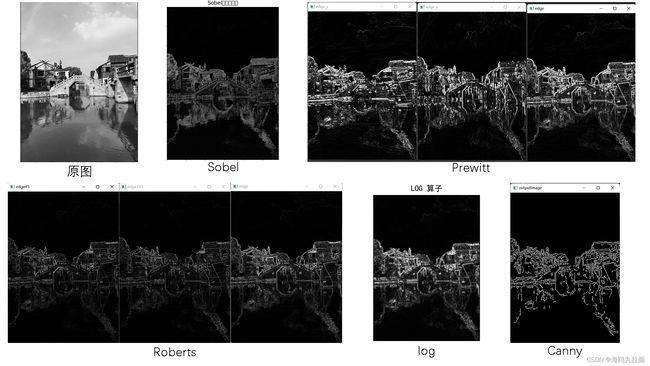
- Sobel算子根据像素点上下、左右邻点灰度加权差,在边缘处达到极值这一现象检测边缘。对噪声具有平滑作用,提供较为精确的边缘方向信息,边缘定位精度不够高。从图像中可以看出边缘检测效果相对较差。
- Prewitt 算子通过对图像上的每个像素点的八方向邻域的灰度加权差之和来进行检测边缘,同样拥有不错的抗噪能力。但由于采用了局部灰度平均,因此容易检测出伪边缘,并且边缘定位精度较低。图中可以明显看出伪边缘最为明显。
- Roberts算子利用局部差分来寻找边缘,检测水平和垂直边缘的效果好于斜向边缘,定位精度高,但对噪声敏感。
- Log算子利用二阶导数零交叉特性检测边缘,定位精度高,边缘连续性好,可以提取对比度较弱的边缘点。
- Canny算子是一种边缘定位精确性和抗噪干扰都较好的折中。图中提取轮廓较为清晰,但是局部失真较重,丢失了许多信息。从实验过程可知Canny 算子对于滤波参数和高、低阈值的选取较为敏感,使得实际应用过程中需要反复调试。
10.2.7 Hough变换
理想情况下,边缘检测应该仅产生位于边缘上的像素集合。实际上,由于噪声、不均匀照明引起的边缘间断,以及其他引入灰度值虚假的不连续的影响,这些像素并不能完全描述边缘特性。因此,一般是在边缘检测后紧跟连接算法,将边缘像素组合成有意义的边缘或区域边界。
Hough变换是一个非常重要的检测间断点边界形状的方法。通过将图像坐标空间变换到参数空间,来实现直线和曲线的拟合。
原理:在x-y坐标空间中,经过点(xi,yi)的直线表示为yi = axi + b,a为斜率,b为截距。通过点(xi,yi)的直线有无数条,对应的a和b也不尽相同。若将xi和yi看作常数,将a和b看作变量,从x-y空间变换到a-b参数空间。则点(xi,yi)处的直线变为b = -xia + yi。x-y空间的另一点(xj,yj)处的直线变为b = -xja + yj。x-y空间中的点在a-b空间中对应一条直线,若点(xi,yi)和(xi,yi)在x-y空间共线,则在a-b空间对应的两直线相交于一点(a’,b’)。反之,在a-b空间相交于同一点的所有直线,在x-y空间都有共线的点与之对应。
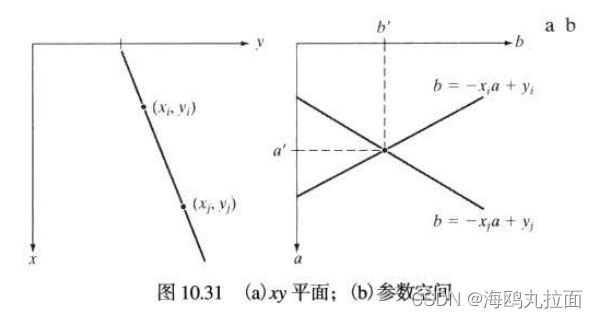
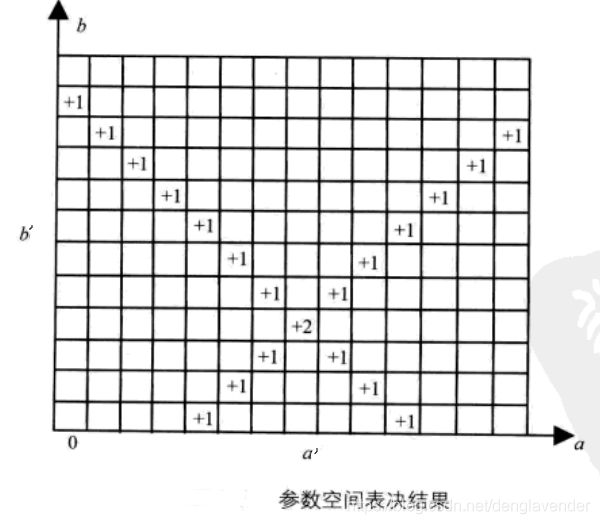
将a-b空间视为离散的。建立二维累加数组A(a,b),第一维是x-y空间中直线斜率的范围,第二维是直线截距范围。二维累加数组A也常被称为Hough矩阵。
初始化A(a,b)为0。对x-y空间的每个前景点(xi,yi),将a-b空间的每个a带入b = -xia + yi,计算对应的b。每计算出一对(a,b),对应的A(a,b) = A(a,b) + 1。所有计算结束后,在a-b空间找最大的A(a,b),即峰值。峰值所对应的(a’,b’)参考点就是原图像中共线点数目最多的直线方程的参数
使用直角坐标表示直线时,当直线为一条垂直直线或接近垂直直线时,该直线的斜率为无限大或接近无限大,故在a-b空间中无法表示,因此要在极坐标参考空间解决这一问题。
直线的法线表示为:xcosθ + ysinθ = ρ
ρ:直线到原点的垂直距离,取值范围为[-D,D],D为一幅图像中对角间的最大距离;θ:x轴到直线垂直线的角度,取值范围为[-90°,90°]。
极坐标中的Hough变换,是将图像x-y空间坐标变换到ρ-θ参数空间中。x-y空间中共线的点变换到ρ-θ空间后,都相交于一点。不同于直角坐标的是,x-y空间共线的点(xi,yi)和(xj,yj)映射到ρ-θ空间是两条正弦曲线,相交于点(ρ‘,θ’)。
具体计算时,也要在ρ-θ空间建立一个二维数组累加器A。除了ρ和θ的取值范围不同,其余与直角坐标类似,最后得到的最大的A所对应的(ρ,θ)。

(1)图像对比度增强
img = ImageEnhance.Contrast(img).enhance(3)
(2)转换为矩阵,灰度化,用Canny算子提取轮廓
img = np.array(img)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, binary = cv2.threshold(gray, 0, 255, cv2.THRESH_OTSU)#阈值变换,cv2.THRESH_OTSU适合用于双峰值图像,ret是阈值,binary是变换后的图像
# canny边缘检测
edges = cv2.Canny(binary, ret-30, ret+30, apertureSize=3)#图像,最小阈值,最大阈值,sobel算子的大小
(3)直线检测
lines = cv2.HoughLinesP(result, 1, 1 * np.pi / 180, 10, minLineLength=10, maxLineGap=5)#统计概率霍夫线变换函数:图像矩阵,极坐标两个参数,一条直线所需最少的曲线交点,组成一条直线的最少点的数量,被认为在一条直线上的亮点的最大距离
(4)在对比度增强后的原图画出检测到的直线
for line in lines:
for x1, y1, x2, y2 in line:
cv2.line(img, (x1, y1), (x2, y2), (255, 0, 0),2)
Hough变换只能处理二值图像,一般在执行变换前需要在图像上执行边缘检测。
10.3 阈值处理
由于阈值处理直观、实现简单且计算速度快,因此图像阈值处理在图像分割应用中处理核心地位。
10.3.1 基础知识
灰度阈值处理基础
一般情况下,我们将图像划分为前景和背景,感兴趣的一般是前景部分,所以用阈值将前景和背景分割开。
![]()
当T是一个适用于整个图像的常数时,上式给出的处理称为全局阈值处理。当T值在一幅图像上改变时,我们使用可变阈值处理这一术语。
双阈值处理
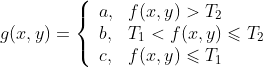
式中a,b,c是任意三个不同的灰度值。

灰度阈值的承购与否直接关系到可区分直方图模式的波谷的宽度和深度。而影响波谷特性的关键因素是:
- 波峰间的间隔(波峰离得越远,分离这些模式的机会越大);
- 图像中的噪声内容(模式随噪声的增加而展宽);
- 物体和背景的相对尺寸;
- 光源的均匀性;
- 图像反射特性的均匀性。
10.3.2 基本的全局阈值处理
当物体和背景像素的灰度分布十分明显时,可以用适用于整个图像的单个(全局)阈值。下面的迭代算法可用于这一目的:
- 为全局阈值T选择一个初始估计值。
- 用T分隔图像。这将产生两组像素:G1由灰度值大于T的所有像素组成,G2由所有小于等于T的像素组成。
- 对G1和G2的像素分别计算平均灰度值(均值)m1和m2。
- 计算一个新的阈值:
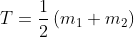
- 重复步骤2到4,直到连续迭代中的T值间的差小于一个预定义的参数△T为止。
import numpy as np
import cv2
import matplotlib.pyplot as plt
img = cv2.imread(r'G:\12.jpg', 0)
# 精度
eps = 1
iry = np.array(img)
r, c = img.shape
avg = 0
for i in range(r):
for j in range(c):
avg += iry[i][j]
T =int(avg/(r*c))
while 1:
G1, G2, cnt1, cnt2 = 0, 0, 0, 0
for i in range(r):
for j in range(c):
if iry[i][j] >= T: G1 += iry[i][j]; cnt1 += 1
else: G2 += iry[i][j]; cnt2 += 1
u1 = int(G1 / cnt1)
u2 = int(G2 / cnt2)
T2 = (u1 + u2) / 2
dis = abs(T2 - T)
if(dis <= eps): break
else :T = T2
new_img = np.zeros((r, c),np.uint8)
for i in range(r):
for j in range(c):
if iry[i][j] >= T: new_img[i][j] = 255
else: new_img[i][j] = 0
cv2.imshow('2', new_img)
cv2.waitKey()
-------------------------显示直方图---------------------------
from PIL import Image
from pylab import *
import cv2
from tqdm import tqdm
def Rgb2gray(image):
h = image.shape[0]
w = image.shape[1]
grayimage = np.zeros((h,w),np.uint8)
for i in tqdm(range(h)):
for j in range(w):
grayimage [i,j] = 0.144*image[i,j,0]+0.587*image[i,j,1]+0.299*image[i,j,1]
return grayimage
# 读取图像到数组中,并灰度化
image = cv2.imread(r"G:\12.jpg")
im = array(Image.open(r'G:\12.jpg').convert('L'))
# 直方图图像
# flatten可将二维数组转化为一维
hist(image.flatten(), 128)
# 显示
show()
 10.3.3 用Otsu方法的最佳全局阈值处理
10.3.3 用Otsu方法的最佳全局阈值处理
Otsu方法是最佳的,因为它使得类间方差最大化。其基本思想是,适当的阈值化的类就其像素灰度值而言,应当是截然不同的,相反地,就其灰度值而言,给出最佳类间分离的阈值将是最佳的(最优的)阈值。除了其最佳性以外,Otsu方法还有一个重要的特性,即它完全以在一幅图像的直方图上执行计算为基础,直方图是很容易得到的一维阵列。
![]()
P1为暗部像素点占整幅图像的比例;P2为亮部像素点占整幅图像的比例;m1为暗部像素均值;m2为亮部像素均值;mG为全图的均值
#otsu
# 彩色图像转换成灰度图像
import numpy as np
from matplotlib import pyplot as plt
from PIL import Image
# 将一个RGB颜色转换成灰度值,结果保留整数
def RGBtoGray(r, g, b):
########## Begin ##########
gray = round(r*0.299 + g*0.587 + b*0.114)
########## End ##########
return gray
# 将真彩色图像转换成灰度图
# 真彩色和灰度图的文件路径分别为path1和path2
def toGrayImage(path1, path2):
img1 = Image.open(path1) # 真彩色图像,像素中是RGB颜色
w, h = img1.size
img2 = Image.new('L', (w, h)) # 新建一个灰度图像,像素中是灰度值
########## Begin ##########
# 此部分功能:依次取出img1中每个像素的RGB颜色,转换成灰度值,再放到img2的对应位置
for x in range(w):
for y in range(h):
r, g, b = img1.getpixel((x, y)) # 取出颜色
gray = RGBtoGray(r, g, b) # 转成灰度值
img2.putpixel((x, y), gray) # 放回像素
########## End ##########
img2.save(path2)
# otsu算法
def otsu(gray):
pixel_number = gray.shape[0] * gray.shape[1]
mean_weigth = 1.0/pixel_number
# #统计各灰度级的像素个数,灰度级分为256级
# bins必须写到257,否则255这个值只能分到[254,255)区间
his, bins = np.histogram(gray, np.arange(0,257))
# 绘制直方图
plt.figure(figsize=(12,8))
plt.hist(gray,256,[0,256],label='灰度级直方图') #运行比较慢,如果电脑卡顿,可以将本行代码注释掉
plt.show()
final_thresh = -1
final_value = -1
intensity_arr = np.arange(256) #灰度分为256级,0级到255级
for t in bins[1:-1]: # 遍历1到254级 (一定不能有超出范围的值)
pcb = np.sum(his[:t])
pcf = np.sum(his[t:])
Wb = pcb * mean_weigth#像素被分类为背景的概率
Wf = pcf * mean_weigth#像素被分类为目标的概率
mub = np.sum(intensity_arr[:t]*his[:t]) / float(pcb)#分类为背景的像素均值
muf = np.sum(intensity_arr[t:]*his[t:]) / float(pcf)#分类为目标的像素均值
#print mub, muf
value = Wb * Wf * (mub - muf) ** 2 #计算目标和背景类间方差
if value > final_value:
final_thresh = t
final_value = value
final_img = gray.copy()
print(final_thresh)
final_img[gray > final_thresh] = 255
final_img[gray < final_thresh] = 0
return final_img
path1 = r'G:\12.jpg' # 真彩色图像
path2 = r'G:\12-huidu.jpg' # 灰度图像
toGrayImage(path1, path2)
imgcolor=plt.imread(path1)
imggray=plt.imread(path2)
plt.imshow(imgcolor)
plt.show()
plt.imshow(imggray,cmap='gray')
plt.show()
plt.imshow(otsu(imggray),cmap='gray')
print(otsu(imggray))
plt.show()
处理结果与基本全局阈值进行对比:
在本次实验中,通过肉眼观察,不太看得出来基本全局阈值处理和Ostu最佳阈值处理的区别。但是理论上,对于某些图像直方图没有明显波谷时,Ostu最佳阈值处理会明显优于基本全局阈值处理。
10.3.4 用图像平滑改善全局阈值处理
噪声会将简单地阈值处理问题变为不可解决的问题。当噪声不能在源头减少,并且阈值处理又是所选择的分割方法时,那么通常能增强性能的一种技术是,在阈值处理之前平滑图像。
采用Ostu方法,分别对带有噪声的图像和去噪图像分别进行处理

由实验结果可以看出,对图像进行去噪处理后再进行阈值处理,分割的效果会好许多。
10.3.5 利用边缘改进全局阈值处理
对于边界明显的图像,前景和背景面积悬殊,但是整体灰度值相近,不易用otsu直接找出正确的阈值,可以使用边缘改进的阈值处理。
算法如下,f(x,y)是输入图像:
- 计算一幅边缘图像,无论是f(x,y)梯度的幅值还是拉普拉斯的绝对值均可。
- 制定一个阈值T。
- 用步骤2中的阈值对步骤1中的图像进行阈值处理,产生一幅二值图像gT(x,y)。在从f(x,y)中选取对应于“强”边缘像素的下一步中,该图像用做一幅模板图像。
- 仅用f(x,y)中对应于gT(x,y)中像素值为1的位置的像素计算直方图。
- 用步骤4中的直方图全局地风格f(x,y),例如使用Otsu方法。
10.3.6 多阈值处理
我们可将阈值处理方法扩展到任意数量的阈值,因为以这种方法为基础的可分性测度也可以扩展到任意数量的分类。在K个类C1,C2,...,Ck的情况下,类间方差可归纳为下面的表达式:

![]()
![]()
10.3.7 可变阈值处理
基于局部图像特性的可变阈值处理
可变局部阈值的通用形式:
![]()
式中,a和b是非负常数,且
![]()
其中,mG是全局图像均值。分割后的图像计算如下:
![]()
式中,f(x,y)是输入图像。该式对图像中的所有像素位置进行求值,并在每个点(x,y)处使用邻域Sxy中的像素计算不同的阈值。
使用移动平均
通常,为减少光照偏差,扫描是以Z字形模式逐步执行的。令Zk+1表示在扫描序列中第k+1步遇到的点的灰度。这个新点处的移动平均(平均灰度)由下式给出:
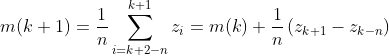
式中,n表示用于计算平均的点的数量,并且m(1)=z1/n。
10.4 基于区域的分割
本节讨论以直接寻找区域为基础的分割技术
10.4.1 区域生长
区域生长是根据预先定义的生长准则,将像素或子区域组合为更大区域的过程。基本方法是从一组“种子”点开始,将与种子预先定义的性质相似的那些领域像素添加到每个种子上,来形成这些生长区域(如特定范围的灰度或颜色)。
基于8连接的一个基本区域生长算法可说明如下:
- 在S(x,y)中寻找所有连通分量,并把每个连通分量腐蚀为一个像素;把找到的所有这种像素标记为1,把S中的所有其他像素标记为0.
- 在坐标对(x,y)处形成图像fQ:若输入图像在该坐标处满足给定的属性Q,则令fQ(x,y)=1,否则令fQ(x,y)=0。
- 令g是这样形成的图像:即把fQ中的8连通种子点的所有1值点,添加到S中的每个种子点。
- 用不同的区域标记(如1,2,3...)标出g中的每个连通分量。这就是由区域生长得到的分割图像。
下面是一个根据鼠标点击确定种子点进行区域生长的算法:
import matplotlib.pyplot as plt
from PIL import Image
import cv2
import numpy as np
def get_x_y(path,n): #path表示图片路径,n表示要获取的坐标个数
im = Image.open(path)
plt.imshow(im, cmap = plt.get_cmap("gray"))
pos=plt.ginput(n)
return pos #得到的pos是列表中包含多个坐标元组
#区域生长
def regionGrow(gray, seeds, thresh, p): #thresh表示与领域的相似距离,小于该距离就合并
seedMark = np.zeros(gray.shape)
#八邻域
if p == 8:
connection = [(-1, -1), (-1, 0), (-1, 1), (0, 1), (1, 1), (1, 0), (1, -1), (0, -1)]
#四邻域
elif p == 4:
connection = [(-1, 0), (0, 1), (1, 0), (0, -1)]
#seeds内无元素时候生长停止
while len(seeds) != 0:
#栈顶元素出栈
pt = seeds.pop(0)
for i in range(p):
tmpX = int(pt[0] + connection[i][0])
tmpY = int(pt[1] + connection[i][1])
#检测边界点
if tmpX < 0 or tmpY < 0 or tmpX >= gray.shape[0] or tmpY >= gray.shape[1]:
continue
if abs(int(gray[tmpX, tmpY]) - int(gray[pt])) < thresh and seedMark[tmpX, tmpY] == 0:
seedMark[tmpX, tmpY] = 255
seeds.append((tmpX, tmpY))
return seedMark
path = r"G:\13.jpg"
img = cv2.imread(path)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# hist = cv2.calcHist([gray], [0], None, [256], [0,256])#直方图
# seeds = originalSeed(gray, th=10)
# print(seeds)
seeds = get_x_y(path=path, n=3) # 获取初始种子
print("选取的初始点为:")
new_seeds = []
for seed in seeds:
print(seed)
# 下面是需要注意的一点
# 第一: 用鼠标选取的坐标为float类型,需要转为int型
# 第二:用鼠标选取的坐标为(W,H),而我们使用函数读取到的图片是(行,列),而这对应到原图是(H,W),所以这里需要调换一下坐标位置,这是很多人容易忽略的一点
new_seeds.append((int(seed[1]), int(seed[0]))) #
result = regionGrow(gray, new_seeds, thresh=3, p=8)
# plt.plot(hist)
# plt.xlim([0, 256])
# plt.show()
result = Image.fromarray(result.astype(np.uint8))
result.show()



区域生长与之前区域分割算法不同,能够通过选取不同的种子点,将具有相似像素的点拼接起来,分割出复杂图像中想要的信息。
10.4.2 区域分割与聚合
将一幅图像细分为一组任意的不相交区域,然后聚合和/或分裂这些区域。
令R表示整幅图像区域,选择一个属性Q,对R进行分割就是依次将它细分为越来越小的四象限区域,以便任何区域Ri都有Q(Ri) = TRUE。从整个区域开始,若Q(R) = FALSE,则将其分割为4个象限区域,若分割后象限区域Q依旧为FALSE,则将对应的象限再次细分为四个子象限区域,以此类推。分割的过程可以用一个四叉树形式直观的表示。细分完成后,对满足属性Q的组合像素的邻接区域进行聚合,即Q(Rj∪Rk) = TRUE时,对两区域进行聚合。
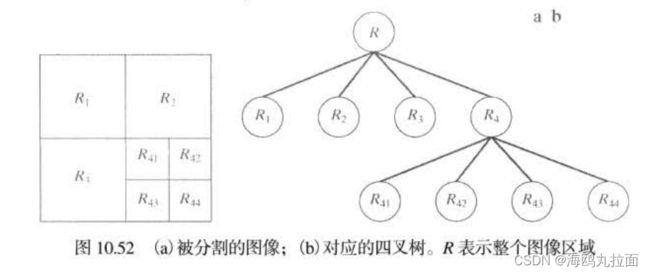
前述讨论可小结尾如下过程:
- 把满足Q(Ri)=FALSE的任何区域Ri分裂为4个不相交的象限区域。
- 不可能进一步分裂时,对满足条件Q(Rj∪RK)=TRUE 的任意两个邻接区域Rj和Rk进行聚合。
- 无法进一步聚合时,停止操作。
习惯上要规定一个不能再进一步执行分裂的最小四象限区的尺寸。
import numpy as np
import cv2
import matplotlib.pyplot as plt # plt 用于显示图片
#判断方框是否需要再次拆分为四个
def judge(w0, h0, w, h):
a = img[h0: h0 + h, w0: w0 + w]
ave = np.mean(a)
std = np.std(a, ddof=1)
count = 0
total = 0
for i in range(w0, w0 + w):
for j in range(h0, h0 + h):
if abs(img[j, i] - ave) < 1 * std:
count += 1
total += 1
if (count / total) < 0.95:#合适的点还是比较少,接着拆
return True
else:
return False
##将图像将根据阈值二值化处理,在此默认125
def draw(w0, h0, w, h):
for i in range(w0, w0 + w):
for j in range(h0, h0 + h):
if img[j, i] > 125:
img[j, i] = 255
else:
img[j, i] = 0
def function(w0, h0, w, h):
if judge(w0, h0, w, h) and (min(w, h) > 5):
function(w0, h0, int(w / 2), int(h / 2))
function(w0 + int(w / 2), h0, int(w / 2), int(h / 2))
function(w0, h0 + int(h / 2), int(w / 2), int(h / 2))
function(w0 + int(w / 2), h0 + int(h / 2), int(w / 2), int(h / 2))
else:
draw(w0, h0, w, h)
img = cv2.imread(r'G:\13.jpg', 0)
img_input = cv2.imread(r'G:\13.jpg', 0)#备份
height, width = img.shape
function(0, 0, width, height)
cv2.imshow('input',img_input)
cv2.imshow('output',img)
cv2.waitKey()
cv2.destroyAllWindows()
由于图像比较简单,可以看出分割效果很好,将人物轮廓完整分割了出来。
10.5 用形态学分水岭的分割
分水岭算法是一种借鉴了形态学理论的分割方法,在该方法中,将一幅图像看成一个拓扑地形图,其中图像的灰度值对应地形高度值。高灰度值对应山峰,低灰度值对应山谷。水总是朝地势低的地方流动,直到某一局部低洼处才停下来,这个低洼处被称为汇水盆地。最终所有的水会分聚在不同的汇水盆地,汇水盆地之间的山脊被称为分水岭。对图像进行分割,就是要在灰度图像中找出不同的“汇水盆地”和“分水岭”。也就是感兴趣的区域内部及其边缘。
一般考虑到各区域内部像素的灰度比较接近,而相邻区域像素间的灰度差距较大,可以先计算一幅图像的梯度图,再寻找梯度图的分水岭。在梯度图中,小梯度值对应区域内部,大梯度值对应区域的边界,分水岭算法就是在寻找大梯度值像素的位置。
直接应用分水岭分割算法的效果往往并不好,通常会由于噪声和梯度的其他局部不规则性造成过度分割。更有甚者,过度分割可能导致不可用的结果。一种解决方案是,通过融入预处理步骤来限制允许存在的区域数量。用于控制过度分割的一种方法是基于标记的。标记是指属于一幅图像的连通分量。与感兴趣物体相联系的标记称为内部标记,与背景相关联的标记称为外部标记。
基于标记的分水岭分割算法:
import numpy as np
import cv2
def watershed(imgpath):
img = cv2.imread(imgpath)
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
ret0, thresh0 = cv2.threshold(gray,0,255,cv2.THRESH_BINARY_INV+cv2.THRESH_OTSU)
kernel = np.ones((3,3),np.uint8)
opening = cv2.morphologyEx(thresh0,cv2.MORPH_OPEN,kernel, iterations = 2)
# 确定背景区域
sure_bg = cv2.dilate(opening,kernel,iterations=3)
# 确定前景区域
dist_transform = cv2.distanceTransform(opening,cv2.DIST_L2,5)
ret1, sure_fg = cv2.threshold(dist_transform,0.7*dist_transform.max(),255,0)
# 查找未知区域
sure_fg = np.uint8(sure_fg)
unknown = cv2.subtract(sure_bg,sure_fg)
# 标记标签
ret2, markers1 = cv2.connectedComponents(sure_fg)
markers = markers1+1
markers[unknown==255] = 0
markers3 = cv2.watershed(img,markers)
img[markers3 == -1] = [0,255,0]
return thresh0,sure_bg,sure_fg,img
if __name__ == '__main__':
imgpath = r'G:\5.jpg'
thresh0, sure_bg, sure_fg, img = watershed(imgpath)
cv2.imshow('thresh0',thresh0)
cv2.imshow('sure_bg', sure_bg)
cv2.imshow('sure_fg', sure_fg)
cv2.imshow('result_img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()

可能由于标记的选择不好,同时受到噪声和梯度的其他局部不规则性,分割效果并不好