【论文阅读】StarGAN v2:Diverse Image Synthesis for Multiple Domains
【2019.12 arxiv】
代码地址:https://github.com/clovaai/stargan-v2
Choi, Yunjey, Youngjung Uh, Jaejun Yoo, and Jung-Woo Ha. “StarGAN v2: Diverse Image Synthesis for Multiple Domains.” arXiv preprint arXiv:1912.01865 (2019).
任务:多领域的image-to-image转换
概述
本文研究的任务是多领域的image-to-image转换,本文在StarGAN的基础上进行了多样改进,从而提高了模型的效果。
模型结构方面由四部分组成。生成器输入原域图像并通过AdaIN方式吸收风格编码,生成目标域图像。风格编码有两种获得来源,一种来自mapping网络,从随机噪声生成风格编码,而每个不同的目标域分别对应一个mapping-head,另一种来自风格编码器,由输入的目标域图像来获得对应的风格编码。判别器输入一张图像,生成各个目标域的真假图像判断,即有K个数,分别判断输入图像是否属于该目标类的真实图像。
损失函数由四项组成,生成对抗损失中WGAN_GP中的GP项使用R1约束(直接对真实图像进行求导),风格编码重建损失、风格差异最大化约束和图像循环重建损失。
模型结构
模型由四部分组成,一个生成器、一个mapping网络,一个风格编码器和一个判别器

生成器输入原域图像和风格编码,生成目标域图像
风格编码有两种获得来源,一种来自mapping网络,从随机噪声生成风格编码,而每个不同的目标域分别对应一个mapping-head,另一种来自风格编码器,由输入的目标域图像来获得对应的风格编码
判别器输入一张图像,生成各个目标域的真假图像判断,即有K个数,分别判断输入图像是否属于该目标类的真实图像
1、生成器(G)

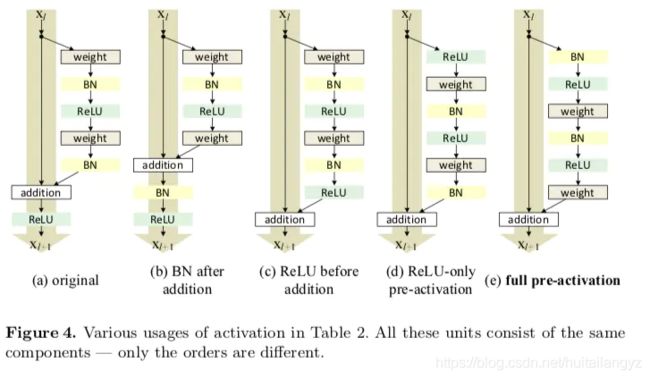
由4个downblock、4个中间block和4个upsamplingblock组成,前6个block使用IN进行归一化,后面6个block使用AdaIN的方式来吸收风格编码特征
所有blocck使用preactivation residual unit
2、mapping 网络(F)
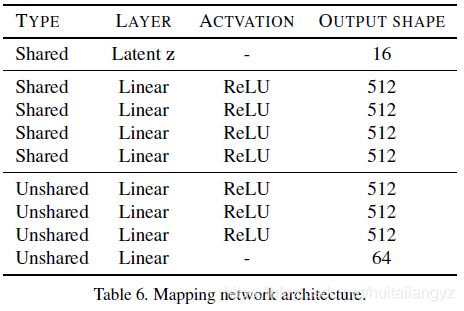
该模块从随机变量生成各个目标域的风格编码,首先是4个共享的FC层,然后是各个目标域私有的4层FC组成的mapping-head,最终得到各个域的风格编码
3、风格编码器(E)和判别器(D)
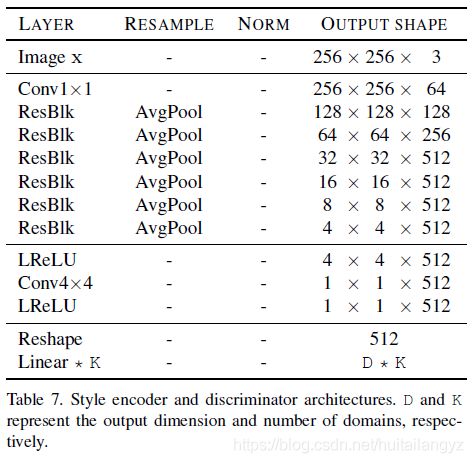
风格编码器和判别器结构类似,只是最后各个域对应的输出长度不同
风格编码器根据输入图像,生成属于各个域的目标编码,D为目标编码长度
判别器根据输入图像,判断该图像对应为各个域真实图像的概率,D为1,不使用PatchGAN
改进步骤
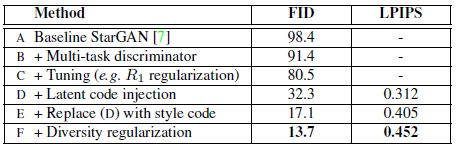
针对StarGAN的方法提出了5点改进方法
B:将StarGAN中的ACGAN判别器改为多任务判别器
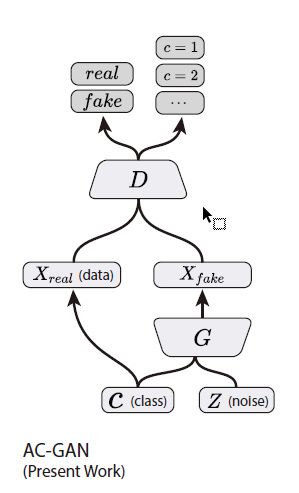
C:判别器约束中WGAN_GP中的GP项变为R1约束
WGAN_GP中原来的GP项对真实图像和生成图像的插值进行求导,R1约束中直接对真实图像进行求导
同时在生成器中使用AdaIN的方法取代concatenation方法来吸收风格编码
(上述方法对于输入图像,每个目标域只能生成一张目标域图像)
D:为了增加图像多样性,引入隐编码作为额外输入,再使用编码器将图像尝试编码回输入隐编码
![]()
E:使用各个域独立的风格编码(mapping网络)
F:使用风格差异化损失函数
损失函数
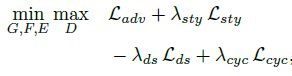
1、生成对抗损失(实际使用WGAN_GP)
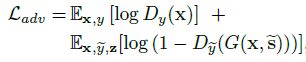
x和y为原域图像和原域类别
![]()
y ~ \tilde{y} y~为目标域类别,z为随机噪声
2、风格重建损失
![]()
先使用G让x根据风格编码生成到目标域,再使用style code的编码器恢复回风格编码
3、风格差异化(最大化)
![]()
![]()
使用同一目标域由于噪声不同而生成的不同风格编码,约束生成的图像之间差异更大,从而增强图像的多样性
在实际训练时
4、循环重建损失
![]()
![]()
先随机让图像转换到任意目标域,再使用原图像获得的风格编码,让其变换回原图像
数据集
1、CelebA-HQ
2、AFHQ(新提出的动物数据集)
15000张512*512的图像,猫、狗、野生动物各5000张,每类至少有8个品种
每类选取500张作为测试集,其余为训练集
在模型训练时使用256*256的图像尺度
评价指标
1、FID
2、LPIPS(Learned perceptual image patch similarity)
使用在ImageNet上预训练的AlexNet的特征来度量两张图像的距离
对于每张原域图像,生成10张目标域图像,计算45对图像间的特征距离,再对所有结果求平均
实验
1、latent-guided图像(由随机噪声生成style code)
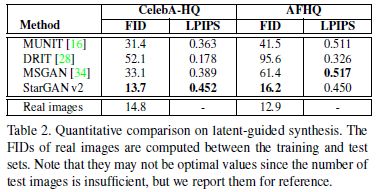

2、reference-guided图像(由目标图像经过Style encoder生成style code)

3、不同改进方法的比较
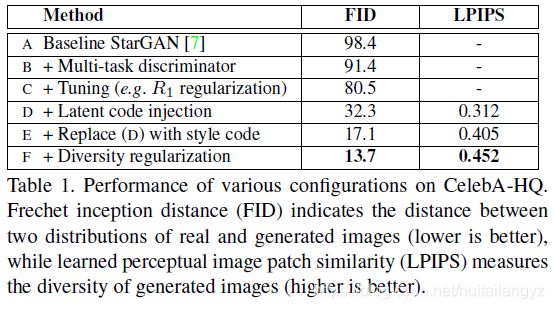
前三种方法每张原域图像只生成一张目标域图像,因此不计算LPIPS
C到D的提升主要原因是因为生成图像数量的关系