人脸识别9-FastDeploy人脸检测、识别、部署
参考:
github:https://github.com/PaddlePaddle/FastDeploy/tree/develop/examples/vision/facedet
win10调试
1
Python SDK快速开始
快速安装
前置依赖
CUDA >= 11.2
cuDNN >= 8.0
python >= 3.8
OS: Linux x86_64/macOS/Windows 10
2
pip install -r requirements.txt
3
pip install numpy opencv-python fastdeploy-python -f https://www.paddlepaddle.org.cn/whl/fastdeploy.html
4、本质上是不同端之间的关系和交互,不同的端定义出了不同的产品类型
linux客户端下载
wget https://bj.bcebos.com/paddlehub/fastdeploy/ppyoloe_crn_l_300e_coco.tgz
tar xvf ppyoloe_crn_l_300e_coco.tgz
wget https://gitee.com/paddlepaddle/PaddleDetection/raw/release/2.4/demo/000000014439.jpg
win10系统浏览器客户端直接下载,复制到浏览器的网页打开即可下载
https://bj.bcebos.com/paddlehub/fastdeploy/ppyoloe_crn_l_300e_coco.tgz
https://gitee.com/paddlepaddle/PaddleDetection/raw/release/2.4/demo/000000014439.jpg
5、python代码示例
# -*- coding: utf-8 -*-
"""
@Author :Mart
@Time :2022/9/8 11:36
@version :Python3.7.4
@Software:pycharm2020.3.2
"""
import cv2
import fastdeploy.vision as vision
model = vision.detection.PPYOLOE("ppyoloe_crn_l_300e_coco/model.pdmodel",
"ppyoloe_crn_l_300e_coco/model.pdiparams",
"ppyoloe_crn_l_300e_coco/infer_cfg.yml")
im = cv2.imread("000000014439.jpg")
result = model.predict(im.copy())
print(result)
vis_im = vision.vis_detection(im, result, score_threshold=0.5)
cv2.imwrite("vis_image.jpg", vis_im)
支持的推理引擎配置
微软,百度,英伟达,因特尔

编译的理解
GCC/Cmake,预处理,编译,汇编,链接
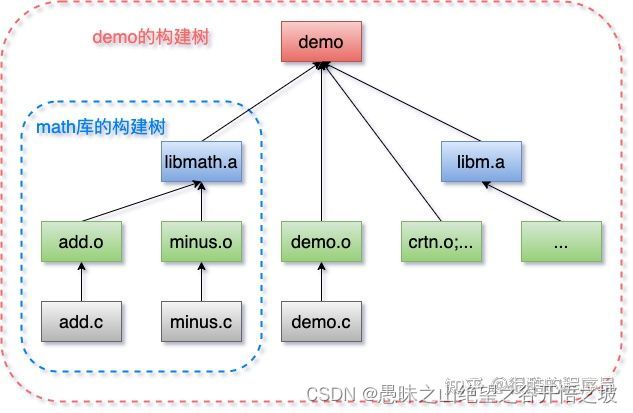
cuda和cudnn和tensorrt的理解
linux 不同的语言,开发方式和依赖的环境包不一样。官方有现成的包,也可以根据需要自动编译定制需要的包
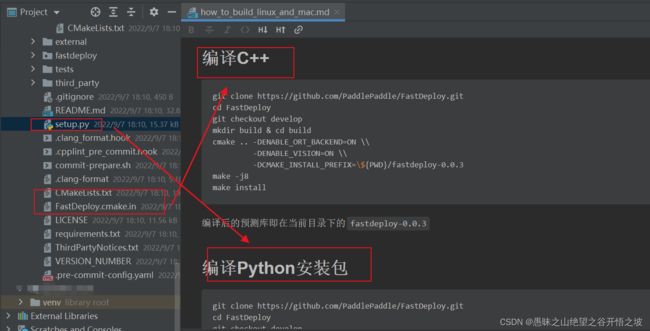
Windows
Windows菜单打开x64 Native Tools Command Prompt for VS 2019命令工具,用VS工具,Visual Studio 16 2019
相关笔记
模型文件介绍
PaddlePaddle动态图文件

PaddlePaddle静态图文件

TensorFlow动态图文件

TensorFlow静态图文件

pytorch动态图

分布式模型训练
[源码解析] 深度学习流水线并行Gpipe(1)—流水线基本实现 参考:https://www.cnblogs.com/rossiXYZ/p/15172665.html
当Spark遇上TensorFlow分布式深度学习框架原理和实践:https://juejin.cn/post/6844903591988166664
数据并行
参考:https://www.zhihu.com/question/53851014
常见的训练方式是单机单卡,也就是一台服务器配置1块AI芯片,这是最简单的训练方式。随着数据量的增加,希望加快模型的训练速度,于是出现了单机多卡,多块AI芯片并行,以一台机器上配置8块AI芯片为例,把数据切分成8份,分别在8块AI芯片上都跑一次BP算法,计算出梯度,然后所有AI芯片上计算出的梯度进行平均,更新模型参数。这样的话,以前一次BP只能训练1个batch的数据,现在就是8个batch。
后者相比于前者,总的batchsize变为前者1/4,学习率也应该变为1/4,这样才相当于相同的batchsize保持相同的学习率

模型并行

模型并行在传统上用于训练过程中太大而无法保存在工作者内存或缓存中的模型。其特点如下:
模型并行涉及到将模型在worker之间进行划分,以便每个worker仅对模型参数的一个子集进行评估和更新。这样就可以分为层间并行和层内模型并行。
层间模型并行会在多个 worker 之间划分模型的各个层。
层内模型并行把每层的模型参数切分到多个设备。层内模型并行在有的论文里被叫做 “Tensor 级别的模型并行” ,是对某一层(如 Linear/Dense Layer 里的 Variable )的模型 Tensor 切分,从而将大的模型 Tensor 分成多个相对较小的 Tensor 进行并行计算;
层间值(激活和梯度)往往是需要跨机器通信的唯一参数。
就其本质而言,模型并行性的计算和通信因模型结构而异,因此在实现上有很大的工作量。
然而,即使模型并行能够训练非常大的模型,传统的模型并行也会导致计算资源的严重利用率不足,因为它一次只主动使用一个worker(如果每个层被分配给一个worker),或者不能重叠计算和通信(如果每个层被分区)。
显存效率:模型并行DNN训练导致GPU资源的严重利用不足。模型并行通过在模型并行 worker 之间划分激活显存,会根据 worker 数量成比例地减少显存使用量。至关重要的是,这是减少单个网络层的激活显存的唯一方法。
计算效率:由于每次前向和反向传播中都需要额外通信激活值,模型并行的计算效率很低。模型并行需要高通信带宽,并且不能很好地扩展到通信带宽受限的节点。此外,每个模型并行worker 都会减少每个通信阶段之间执行的计算量,从而影响计算效率。模型并行性通常与数据并行性结合使用,以在内存和计算效率之间进行权衡。
开发效率:跨多个GPU划分模型的负担留给了程序员,即使对于最有经验的机器学习实践者来说,确定如何在工作者中最好地划分DNN模型也是一项具有挑战性的任务,这往往会导致额外的效率低下。最近有些工作探索了如何使用增强学习来自动确定模型并行性的设备位置。不幸的是,这样的在线决策技术是时间和资源密集型的;它们也不能无缝地结合流水线、数据并行和模型并行。
流水线并行
流水并行(Pipeline Model Parallelism)在有的论文里叫做流水线级别的模型并行,其特点是:
将整个网络分段(stage),不同段在不同的设备上,前后阶段流水分批工作,通过一种“接力”的方式并行。
流水线并行将模型的各层划分为可以并行处理的阶段。当一个阶段完成一个 micro-batch 的正向传递时,激活内存将被通信至流水线的下一个阶段。类似地,当下一阶段完成反向传播时,将通过管道反向通信梯度。必须同时计算多个 micro-batch 以确保流水线的各个阶段能并行计算。
流水线并行训练有可能在数据并行性困难时提供较高的DNN训练性能。特别是,工作人员之间的通信可以限制在分配给不同工作人员的相邻层之间的激活(在前向通道上)和梯度(后向)上。
但是流水线并行依然有一些问题:
显存效率:流水线并行减少的显存与流水线的阶段数成正比,使模型的大小可以随 worker 的数量线性扩展。但是,流水线并行不会减少每一层的激活函数的显存占用量。此外,每个 worker 必须存储同时运行的各个 micro-batch 的激活值。这导致流水线第一阶段的激活内存与单个 mirco batch 的总激活内存大致相同。
计算效率:流水线并行具有最低的通信量,因为它的通信量只和在各阶段边界的各层的激活值大小成正比。但是,它不能无限扩展。像模型并行一样,增加流水线大小会减少每个流水线阶段的计算量,这会降低计算与通信的比率。如果要实现好的计算效率,流水线并行还要求其每个阶段的计算负载完美的均衡。此外,流水线并行性会在每个 batch 的开始和结束时因为需要重新填充或排空流水线而产生 bubble overhead。
开发效率:DNN的双向性(正向传递后反向传递相同的层)使得流水线具有挑战性,更重要的是,一个简单的流水线机制引入了过时权重的最新计算,导致最终模型的精度低于数据并行训练。
模型并行性乍一听挺唬人的,但是其实和令人生畏的数学没太大关系。模型并行更多的是一种对计算机资源的分配问题。有时候我们的模型可能太大了,甚至大到不能把整个模型载入一个GPU中,因为其中有着太多的层,太多的参数。因此,我们可以考虑把整个模型按层分解成若干份,把每一份(其中的层是连续的)载入不同的节点中,也即是每个不同的节点计算着整个模型的不同的层,计算着不同的层的梯度。通过这种方法,单个节点的参数量就减少了,并且使得用更为精确的梯度进行计算提供了可能性。
举例而言,假如我们有10个GPU节点,我们想要训练一个ResNet50网络(其中有50层)。我们可以将前5层分配给GPU#1, 下一个5层分给GPU #2,如此类推,最后的5层自然是分配给了GPU #10。在训练过程中,在每个迭代中,前向传播首先在GPU #1进行,接下来是GPU #2, #3等等。这个过程是串行的,后面的节点必须等待前面的节点运算完之后才能接着运算,但是,反过来说,后面节点在进行运算的时候,并不妨碍前面的节点进行下一个批次的运算,这个其实就是一个流水线(pipeline)的结构了。当涉及到反向传播时,我们首先计算GPU #10的梯度,并且根据此,更新网络参数。然后我们继续计算前一节点GPU #9的梯度,并且更新,以此类推。每个节点就像是一个工厂中的生产部门,所有节点组成了一个流水线。
简评
在我看来,模型并行的名字其实有点误导性,因为我们发现模型并行有时候并不是一个并行计算的良好例子。一个更为精确的名字应该类似于“模型串行化”,因为它使用了一种串行化的方法而不是一种并行的方法。然而,在一些模型场景中,神经网络中的一些层的确可以做到并行化,比如siamese network,其不同的分支是可以看成完全的并行的。在这种场景中,模型并行可以表现得和真正的并行计算一样。数据并行,的确是100%的并行计算了。
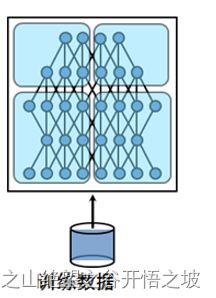
混合并行
最后说说两者之间的联系,有的时候呢数据并行和模型并行会被同时用上。比如深度的卷积神经网络中卷积层计算量大,但所需参数系数 W 少,而FC层计算量小,所需参数系数 W 多。因此对于卷积层适合使用数据并行,对于全连接层适合使用模型并行。 就像这样:
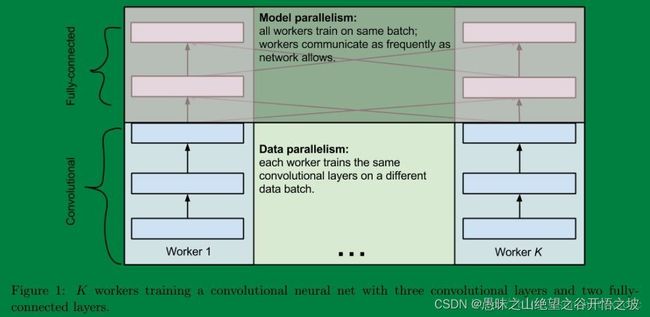
spark和深度学习分布式训练框架
目前来看,Spark最适用的其实是数据处理,清洗等任务,能够在部分领域里取代传统数据库,这本质是因为其选择了MapReduce的机制实现分布式化,每次通信都要等待同步,而目前主流的专用分布式dl/ml框架都是采用参数服务器的形式,允许不同worker之间的异步执行,因此将spark与主流的框架深度结合不会是一件容易的事情。
把基础概念搞清楚。spark处理是大数据处理引擎,它有所谓的ml模块,但仅仅是传统机器学习。
在分布式领域里,前者(分布式深度学习系统)是专才,后者(通用分布式系统)是通才。hdfs负责存储,yarn负责集群管理,hadoop的MR/spark/storm等负责计算,kafka负责流式数据传输,等等,但这些都可以算是通用分布式系统的范畴,都是和业务无关的。而深度学习相关的那些,则是为了解决深度学习这一特定业务领域的问题而专门定制的分布式计算系统,在通用性上较差,但对于相关业务领域,实现了许多有用的功能或做了许多性能优化,较难或无法使用目前的通用分布式计算系统搞定
机器学习,深度学习需要会hadoop/spark这些框架吗?
对结构化数据的数据挖掘,机器学习,数据还是积累在Hadoop集群上,所以需要会。搞图像语音这些的,一般用不上,很多都是给你几台台gpu机器,数据拷贝上去跑。