MySQL数据库索引及失效场景
MySQL数据库索引及失效场景
- 1. MySQL索引概述
-
- 1.1 索引的概念
- 1.2 索引的特点
- 1.3 索引的分类
- 1.4 索引的使用场景
- 2. 索引失效场景
-
- 2.1 索引失效9种场景
- 2.2 索引失效场景总结
- 3. 索引失效验证
-
- 3.1 全值匹配
- 3.2 最佳左前缀
- 3.3 索引计算
- 3.4 索引范围:索引列上不能有范围查询
- 3.5 索引覆盖:尽量使用覆盖索引
- 3.6 不等: 使用不等于(!= 或者 <>)的时候
- 3.7 null:字段的is not null 与is null
- 3.8 like:like的前后模糊匹配
- 3.9 or:减少使用or
1. MySQL索引概述
1.1 索引的概念
什么是索引,索引就是排好序的快速查找数据结构。
1.2 索引的特点
索引的优点
1.提高数据检索的效率, 降低数据库的IO成本。
2.通过索引列对数据进行排序, 降低数据排序的成本, 降低了CPU的消耗。
索引的缺点
1.虽然索引大大提高了查询速度, 同时却会降低更新表的速度, 如对表进行INSERT、 UPDATE和DELETE。 因为更新表时, MySQL不仅要保存数据, 还要保存一下索引文件每次更新添加了索引列的字段, 都会调整因为更新所带来的键值变化后的索引信息。
2.实际上索引也是一张表, 该表保存了主键与索引字段, 并指向实体表的记录, 所以索引列也是要占用空间的。
1.3 索引的分类
MySQL 使用的是 Btree 索引。另外还有B+tree 索引,B-tree 索引,具体原理不在细说,原理详情参考官网。
简单说下以下几个常用索引。
单值索引
概念:即一个索引只包含单个列, 一个表可以有多个单列索引
唯一索引
概念: 索引列的值必须唯一, 但允许有空值
主键索引
概念: 设定为主键后数据库会自动建立索引, innodb为聚簇索引。
复合索引
概念: 即一个索引包含多个列
1.4 索引的使用场景
适合创建索引的情况
1.主键自动建立唯一索引;
2.频繁作为查询条件的字段应该创建索引
3.查询中与其它表关联的字段, 外键关系建立索引
4.单键/组合索引的选择问题, 组合索引性价比更高
5.查询中排序的字段, 排序字段若通过索引去访问将大大提高排序速度
6.查询中统计或者分组字段
不适合创建索引的情况
1.表记录太少
2.经常增删改的表或者字段
3.Where 条件里用不到的字段不创建索引
4.过滤性不好的不适合建索引
2. 索引失效场景
2.1 索引失效9种场景
1.全值匹配:查询条件的列与索引列的字段,顺序完全相同。
2. 最佳左前缀:查询条件的列与索引列的字段相同,顺序不同,从不同顺序列开始后边都不走索引。
3. 索引计算:不要在索引上做任何计算
4. 索引范围:索引列上不能有范围查询,比如大于,小于,大于等于,小于等于。
5. 索引覆盖:尽量使用覆盖索引
6. 不等: 使用不等于(!= 或者 <>)的时候
7. null:字段的is not null 与is null
8. like:like的前后模糊匹配
9. or:减少使用or
2.2 索引失效场景总结
全值匹配,左前缀。
索引计算范围要覆盖。
不等于(!= 或者 <>)扫全表,null走索引,not不走。
like模后不模前,见or就走union all
3. 索引失效验证
索引测试环境
1.mysql版本:5.7.27-log,查询语句:select VERSION();
2.建表语句及数据:mysql批量插入数据
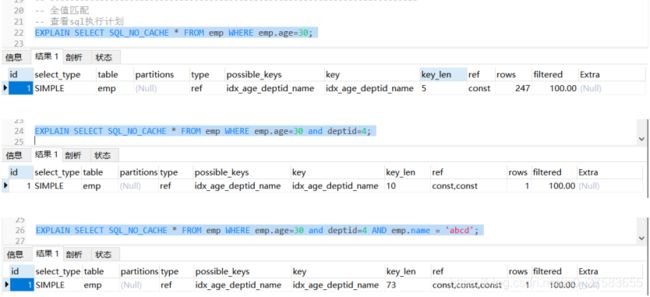
3.1 全值匹配
-- 全值匹配
-- 查看sql执行计划
EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.age=30;
EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.age=30 and deptid=4;
EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.age=30 and deptid=4 AND emp.name = 'abcd';
-- 创建联合索引
CREATE INDEX idx_age_deptid_name ON emp(age,deptid,NAME);
创建索引前

创建索引后
3.2 最佳左前缀
-- 创建索引
CREATE INDEX idx_age_deptid_name ON emp(age,deptid,NAME);
-- 缺少联合索引的第一个字段
explain select sql_no_cache * from emp where deptId = 4 and name = 'abcd';
-- 联合索引的第一二个字段,缺少最后一个字段
explain select sql_no_cache * from emp where age = 30 and deptId = 4;
-- 联合索引的第一三各字段,缺少第二个字段
explain select sql_no_cache * from emp where age = 30 and name = 'abcd' ;
 查询字段与索引字段顺序的不同会导致, 索引无法充分使用, 甚至索引失效!
查询字段与索引字段顺序的不同会导致, 索引无法充分使用, 甚至索引失效!
原因: 使用复合索引, 需要遵循最佳左前缀法则, 即如果索引了多列, 要遵守最左前缀法则。 指的是查询从索引的最左前列开始并且不跳过索引中的列。
结论: 过滤条件要使用索引必须按照索引建立时的顺序, 依次满足, 一旦跳过某个字段, 索引后面的字段都无法被使用
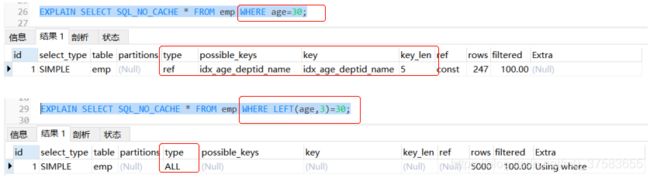
3.3 索引计算
不要在索引上做任何计算!
不在索引列上做任何操作(计算、 函数、 (自动 or 手动)类型转换), 会导致索引失效而转向全表扫描。
1.在查询列上使用函数
-- 索引不带计算
EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE age=30;
-- 索引字段计算
EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE LEFT(age,3)=30;
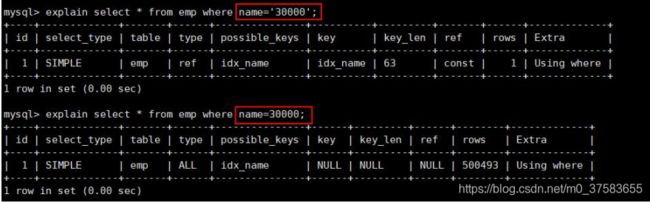
2. 在查询列上做了转换
-- 创建单值索引,字符串类型 name
create index idx_name on emp(name);
-- 字符串加单引号情况
explain select sql_no_cache * from emp where name='30000';
-- 字符串不加单引号, 则会在 name 列上做一次转换!
explain select sql_no_cache * from emp where name=30000;
3.4 索引范围:索引列上不能有范围查询
explain SELECT SQL_NO_CACHE * FROM emp WHERE emp.age=30 and deptid=5 AND emp.name = 'abcd';
explain SELECT SQL_NO_CACHE * FROM emp WHERE emp.age=30 and deptid<=5 AND emp.name = 'abcd';
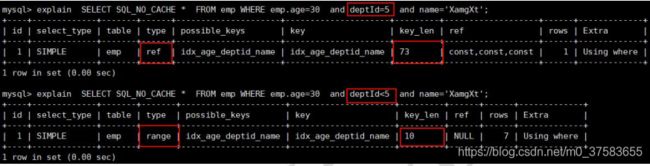 建议: 将可能做范围查询的字段的索引顺序放在最后
建议: 将可能做范围查询的字段的索引顺序放在最后
3.5 索引覆盖:尽量使用覆盖索引
explain SELECT SQL_NO_CACHE * FROM emp WHERE emp.age=30 and deptId=4 and name='XamgXt';
explain SELECT SQL_NO_CACHE age,deptId,name FROM emp WHERE emp.age=30 and deptId=4 and name='XamgXt';

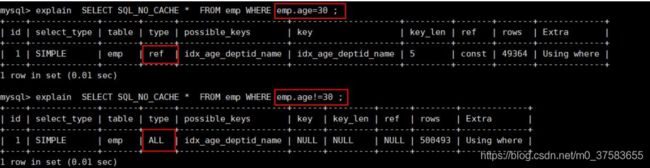
3.6 不等: 使用不等于(!= 或者 <>)的时候
mysql 在使用不等于(!= 或者<>)时, 有时会无法使用索引会导致全表扫描。
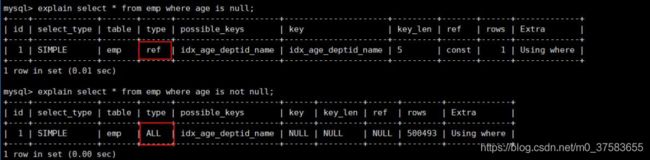
3.7 null:字段的is not null 与is null
当字段允许为 Null 的条件下:
is not null 用不到索引, is null 可以用到索引。

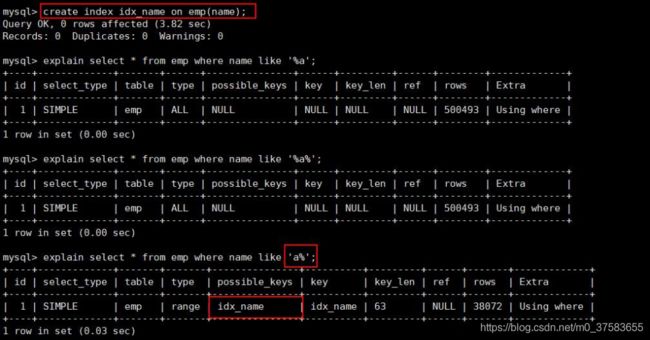
3.8 like:like的前后模糊匹配
前缀不能出现模糊匹配!
3.9 or:减少使用or
 使用 union all 或者 union 来替代:
使用 union all 或者 union 来替代:
