IO 缓冲区与五种 IO 模型
文章目录
- IO 的基本常识
-
- 操作系统的内核是一套软件
- 阻塞 IO 模型
- 内核空间处理数据的基本单位:页
- 缓冲区
- 小结
- IO 模型
-
- 阻塞 IO 模型
- 非阻塞 IO 模型
- IO 复用模型
- 信号驱动 IO 模型
- 异步 IO 模型
- 五种 IO 模型的区别和理解
IO 的基本常识
操作系统的内核是一套软件
我们在 app 编写代码程序的时候会使用到 IO 操作,Java 也提供了相应的 API 例如 InputStream/OutputStream 等等,JVM 要读取字节码文件同样也需要 I/O 操作,那是否就可以认为它们本身就是支持 IO 的?其实并不是。
IO 操作是对内存进行操作,要实现从物理内存将数据读写的操作,即 IO 就是一个功能,功能要运行就需要有软件能够支撑,操作系统也是一个软件,而 提供 IO 这个功能的软件就是内核。

应用程序要处理 IO 操作,实际上是调用的系统提供的公共函数库,将操作交给内核去执行具体数据读写。很多基础功能需要调用内核去完成。

应用程序和内核都处在内存中,当应用程序发起 IO 操作要将数据写入磁盘的时候,实际上会存在一次从应用程序将数据拷贝到内核空间的过程,然后由内核将数据写入到磁盘中。 应用程序和内核都是软件,应用程序处在用户空间,内核处在内核空间,内核要对应用程序的数据操作,首先就是需要数据拷贝。所以 IO 本质上就是两套软件之间的交互过程。
阻塞 IO 模型

上图是阻塞 IO 模型的读操作流程图,具体步骤如下:
-
应用进程发起读操作调用系统函数 recvfrom,告知内核要读操作了
-
在内核往应用进程拷贝数据前,内核需要做数据准备,这个过程是耗时的,线程会阻塞等待数据准备好(应用进程等待内核准备好数据)
-
内核将数据准备好,意味着阻塞结束,就会开始将数据拷贝到应用进程
写操作就是反过来的步骤:
-
应用进程发起写操作,告知内核要写操作了
-
在应用进程往内核传输数据时,内核需要做数据准备,线程阻塞等待数据准备好(内核等待应用进程准备好数据)
-
应用进程将数据准备好,意味着阻塞结束,就会开始将数据拷贝到内核写入磁盘
我们经常听到的 IO 会阻塞,本质上 IO 阻塞就是上面 IO 模型中 “等待数据” 的概念。
根据上面的步骤,实际的 IO 操作都在内核,应用进程读操作实际上是内核拷贝数据给到应用进程(应用进程的读操作是内核的写操作,内核往内存去写);应用进程写操作实际上是内核拷贝数据写到磁盘(应用进程的写操作是内核的读操作,内核从内存去读)。
内核空间处理数据的基本单位:页
IO 操作是对数据的读写,那么 IO 每次读写多少数据?这涉及一个概念:页。
在内核空间 以 4k 数据作为一页,一页数据就是 IO 的基本单位。当然读写并不全是一次就读写一页 4k,基于 空间局部性原理,在常规操作下,如果数据量较大的情况可能会出现预占位 4-16k 的数据读写作为基本单位(即提前将空间分配给你,减少空间分配次数提高性能),即一页最多是 16k。
注意,这里说的 4k 是内核空间处理数据的基本单位,用户空间的处理单位不是 4k。
缓冲区
// 基础 IO
FileOutputStream out = new FileOutputStream(outFile);
for (int i = 0; i < 10000; i++) {
out.write("Hello".getBytes());
}
out.flush(); // 有用吗?
out.close();
上面是我们在日常开发中可能会写出来的代码,你可以说一下上面的代码有什么问题吗?FileOutputStream 的 flush() 有用吗?
你可能会直接说:在 for 循环执行了太多次 write(),这会有性能问题,日常开发中都是用的 BufferedOutputStream 写的,因为有缓冲区。那再细问下:write() 引发的什么性能问题?为什么要用 BufferedOutputStream?缓冲区的概念是怎样的?
其实可以用刚才的 IO 模型来解释,IO 模型中说到应用程序往内核空间写数据,实际上会发生数据拷贝,基础 IO 每调用一次 write() 就会触发一次数据拷贝,多次调用 write() 就是频繁的触发内核空间的数据拷贝,这就是基础 IO 直接调用 write() 存在的性能隐患。
所谓的基础 IO 也可以理解为就是没有缓冲区的 IO,它们都有一个共同的特点,因为没有缓冲区所以会存在数据拷贝频繁的问题。
FileOutputStream out = new FileOutputStream(outFile);
out.flush();
// 调用 OutputStream 的 flush(),空实现
public void flush() throws IOException {
}
所谓的 flush() 会将数据刷到缓冲区,看源码会发现基础 IO 的 flush() 就是一个空实现,所以 FileOutputStream 调用 flush() 是无效的。
FileOutputStream fos = new FileOutputStream(outFile);
BufferedOutputStream bos = new BufferedOutputStream(fos);
bos.write("Hello".getBytes());
bos.flush();
bos.close();
BufferOutputStream 是带有缓冲区的,调用 write() 时先将数据写到缓冲区,等缓冲区满了之后再将数据给到内核空间做数据拷贝,这样就能减少数据拷贝的次数。
怎么验证有它是有缓冲区的存在?我们用一个 demo 验证下:
FileOutputStream fos = new FileOutputStream("/user/Desktop/a.txt");
int count = 0;
for (int i = 0; i < 32; i++) {
for (int j = 0; j < 1024; j++) { // 每次写 1k 数据
byte[] bytes = "a".getBytes();
fos.write(bytes);
count += bytes.length;
}
System.out.println("===" + count + "===");
Thread.sleep(2000);
}
fos.close();
上面的代码使用基础 IO 写数据,文件的读写是每个字节会 write() 一次,程序执行时实时打开输出的文件,会发现文件已经写入了很多数据。写入多少数据占用空间就有多少。
FileOutputStream fos = new FileOutputStream("/user/Desktop/a.txt");
BufferedOutputStream buffer = new BufferedOutputStream(fos);
int count = 0;
for (int i = 0; i < 32; i++) {
for (int j = 0; j < 1024; j++) {
byte[] bytes = "a".getBytes();
buffer.write(bytes);
count += bytes.length;
}
// buffer.flush(); // 手动调用一次同步,否则会等到 Java 默认缓冲区有 8k 数据后才写入
System.out.println("===" + count + "===");
Thread.sleep(2000);
}
buffer.close();

使用 BufferedOutputStream 写 1k 数据等待 2s 后继续写,程序执行时如果打开输出的文件会发现里面还是空的,直到数据写入到 8k 时打开文件才有数据。

当数据写到 16k 时,你会发现占用空间是 24k,多了 8k 的空间,这就是刚才讲到的空间局部性原理。
系统在进行 IO 操作的时候会有一组优化方案存在,每次操作的数据是 4k 一页,但是为了优化可能会扩展到 8k,在分配具体物理内存的时候,正常在写入时如果是 8k 数据就占用的 8k 空间,但系统检测到你还在不断的写,这时候就会提前先多给你 8k 或 16k 的内存空间,在操作系统的角度来讲它就减少了一次空间分配;下次检测到你空间够用时就不分配了,等你不够了再分配。这就是空间局部性原理。
通过 BufferedOutputStream 的源码也可以发现缓冲区的存在:
public class BufferedOutputStream extends FilterOutputStream {
protected byte buf[]; // 缓冲区字节数组
protected int count; // 记录每次写入的字节数量
public BufferedOutputStream(OutputStream out) {
this(out, 8192);
}
public BufferedOutputStream(OutputStream out, int size) {
super(out);
if (size <= 0) {
throw new IllegalArgumentException("Buffer size <= 0");
}
buf = new byte[size];
}
private void flushBuffer() throws IOException {
if (count > 0) {
out.write(buf, 0, count); // out 即传入的输出流,即 FileOutputStream
count = 0;
}
}
public synchronized void write(int b) throws IOException {
if (count >= buf.length) { // 到达 8k 大小就进行 IO
flushBuffer();
}
buf[count++] = (byte) b; // 在没达到缓冲区指定大小时,没有做 IO
}
public synchronized void flush() throws IOException {
flushBuffer(); // 主动 IO
out.flush();
}
}
public class FileOutputStream extends OutputStream {
public void write(byte b[], int off, int len) throws IOException {
writeBytes(b, off, len, append);
}
// IO
private native void writeBytes(byte b[], int off, int len, boolean append)
throws IOException;
}
上面验证了缓冲区的存在,并且也验证了 Java 的缓冲方案是,在堆区会提供一个 8k 大小的缓冲区字节数组,每次数据达到 8k 会进行一次同步调用,内核空间会进行一次数据拷贝。
小结
上面讲述了 IO 数据读写的底层原理,并且引出了阻塞 IO 模型说明阻塞 IO 的具体流程,内核 IO 的基本单位是页,也提到了缓冲区的概念。简单总结下这三个知识点:
-
用户空间的 IO 操作,实际上是调用的系统提供的公共调用函数库,将操作交给内核去执行具体数据读写,真正做 IO 的是内核
-
阻塞 IO 的 ”阻塞“ 是内核 ”等待数据“ 的过程,所在的线程阻塞,真正操作 IO 的是内核
-
内核空间处理数据的基本单位是一页 4k,基于空间局部性原理可能会提前多分配 4-16k 空间以提高性能减少分配次数
-
基础 IO 每次写出都会出现一次数据拷贝,为了提高性能解决频繁的数据拷贝,Java 的缓冲方案是在堆区会提供一个 8k 大小的缓冲区,每 8k 进行一次数据同步,内核空间才会进行一次拷贝
IO 模型
在上面讲解了阻塞 IO 模型,它并不是唯一的 IO 方案,在后续又提出了四种 IO 模型,分别是非阻塞 IO 模型、IO 复用模型、信号驱动式 IO 模型、异步 IO 模型。并且在以上 IO 模型的基础上,Java 在 java.nio 包下提供了相应的一套 API,也就是 NIO。
IO 分为两个阶段:
-
数据准备阶段
-
内核数据拷贝阶段
IO 模型就是内核系统提供了多种函数,例如 recv/fsync/sync/poll/select,这些函数有相关功能,Java 通过这些函数不同的功能,组合开发了五套 IO 的具体实现方案。但真正的 IO 读写还是在内核完成。
阻塞 IO 模型

阻塞 IO 模型就是应用进程调用系统函数 recvfrom,此时所在线程会阻塞等待数据,直到数据准备好了之后再执行后续动作。
阻塞 IO 模型也是传统的 IO 的实现方案,缺点也很明显:如果在高强度并发状况下很容易将 CPU 拉满,内存处理需要有线程,每个线程在读写前都阻塞等待数据,内核建立联系数量多,对 CPU 损耗大。
非阻塞 IO 模型
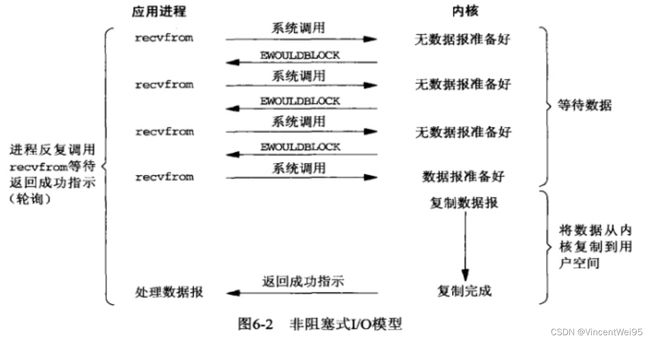
非阻塞 IO 模型就是应用进程调用系统函数 recvfrom,内核在准备数据时,应用进程会轮询的调用 recvfrom 检查数据是否准备好,轮询过程中其他处理照常跑不会阻塞等待,数据准备好了就再继续执行后续动作。
相比阻塞 IO 模型,非阻塞 IO 模型能处理更多的任务量。
IO 复用模型

IO 复用模型是应用进程在调用系统函数 recvfrom 之前,先调用 select 或 poll,这两个系统调用都可以在内核准备好数据(网络数据到达内核)时告知应用进程,这时候应用进程再调用 recvfrom 一定是有数据的。
IO 复用模型的流程是阻塞于 select 或 poll 而没有阻塞于 recvfrom。
IO 复用模型从两个不同的角度看待它有不同的解释:
-
非阻塞 IO 定义成在读写操作时没有阻塞系统调用的 IO 操作(不包括数据从内核拷贝到用户空间时的阻塞,因为这相对于网络 IO 来说确实很短暂),如果按这样理解,IO 复用模型也能称之为非阻塞 IO 模型
-
按 POSIX 来看,它属于同步 IO,在这个角度又可以称之为同步非阻塞 IO
这种 IO 模型比较特别是分段的,因为它能同时监听多个文件描述符 fd,select/poll/epoll 都是属于该 IO 模型,epoll 和 select/poll 不同的地方在于,当应用进程被告知可读时,epoll 可以直接找到对应的 fd,而 select/poll 需要遍历所有 fd 找到可读的那个。
信号驱动 IO 模型

信号驱动 IO 模型是应用进程调用注册信号函数,等内核数据准备好的时候,系统中断当前程序执行 recvfrom。
异步 IO 模型
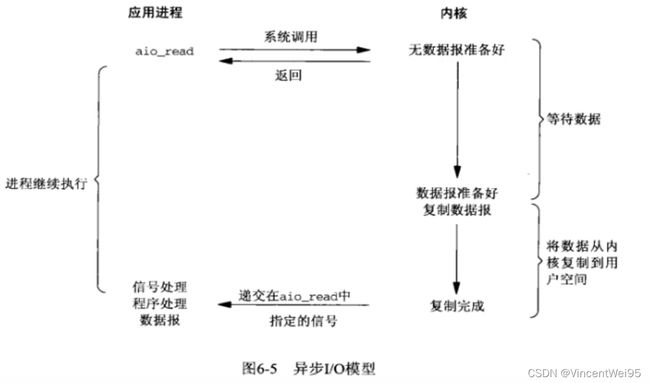
异步 IO 模型是应用进程调用 aio_read,等内核将数据准备好,并且拷贝到应用进程空间后执行事先指定好的函数。整个过程应用进程没有调用 recvfrom,这才是真正的异步 IO。
五种 IO 模型的区别和理解

除了异步 IO 模型外,其他的 IO 模型在第二阶段将数据从内核拷贝到用户空间的操作都是阻塞的,即它们实际上前四种都是同步 IO,只有异步 IO 模型是异步的。
上面的 IO 模型流程图还是比较抽象不太好理解,下面用买票的故事理解上面讲到的五种 IO 模型:
