【语义分割】6、DeepLabV3:Rethinking Atrous Convolution for Semantic Image Segmentation
文章目录
-
- 一、主要思想
- 二、实现
- 三、代码

一、主要思想
为了提高对不同尺度目标的语义分割,作者串联或并联使用不同扩张率的空洞卷积来实现对多尺度上下文的语义信息捕捉。
Atrous Spatial Pyramid Pooling module
作者开篇抛出了两个问题:
- 目前的深度卷积网络虽然可以提取抽象的高层语义信息,但丢失了细节的空间信息
- 故本文使用了 atrous convolution
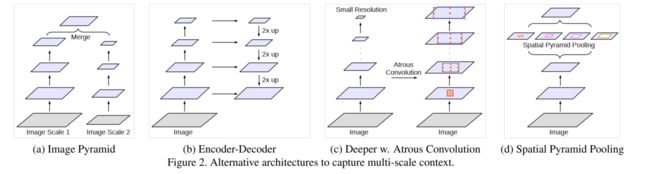
- 目标尺度的多样性为分割带来困难,一般有如下四种解决方式
- ① 给每个金字塔层后面都接了深度卷积网络来抽取特征
- ② encoder-decoder 模块从encoder模块提取多尺度特征,从decoder模块复现原始空间特征
- ③ 在原始网络的上边使用了额外的模块来捕获long-range信息
- ④ 使用多个不同比率的spatial pyramid pooling 来捕获输入特征图中的多尺度目标
二、实现
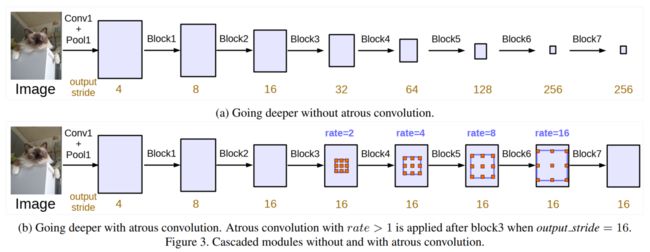
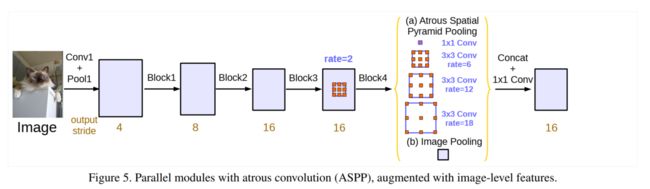
下图展示了使用膨胀卷积的效果:保持分辨率,保持空间细节信息
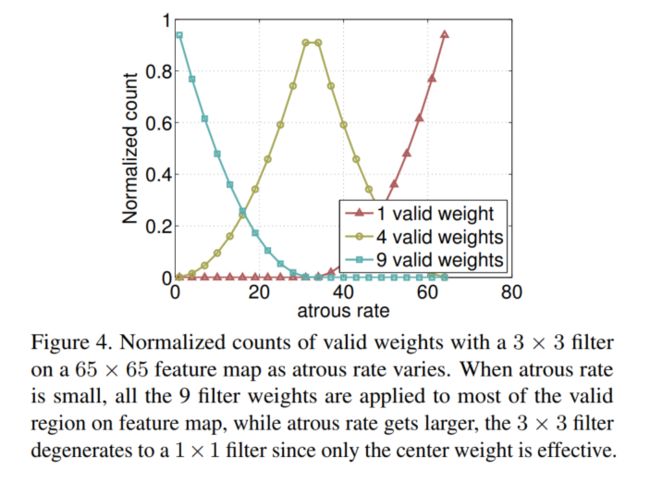
Deeplab V2 中的 ASPP 的使用的问题:
当采样的间隔越大,滤波器中无用的权重就越多,也就是间隔越大,会有很多权重落到特征图外,无法起作用,极端情况就是这个3x3的卷积的效果类似于一个1x1的卷积。
本文作者为了克服上述困难,改进了 ASPP,即并联使用(b)Image pooling (global average pooling) 和 (a)ASPP
三、代码
import torch
import torch.nn as nn
from mmcv.cnn import ConvModule
from mmseg.ops import resize
from ..builder import HEADS
from .decode_head import BaseDecodeHead
class ASPPModule(nn.ModuleList):
"""Atrous Spatial Pyramid Pooling (ASPP) Module.
Args:
dilations (tuple[int]): Dilation rate of each layer.
in_channels (int): Input channels.
channels (int): Channels after modules, before conv_seg.
conv_cfg (dict|None): Config of conv layers.
norm_cfg (dict|None): Config of norm layers.
act_cfg (dict): Config of activation layers.
"""
def __init__(self, dilations, in_channels, channels, conv_cfg, norm_cfg,
act_cfg):
super(ASPPModule, self).__init__()
self.dilations = dilations # (1, 12, 24, 36)
self.in_channels = in_channels # 2048
self.channels = channels # 512
self.conv_cfg = conv_cfg
self.norm_cfg = norm_cfg # BN
self.act_cfg = act_cfg # Relu
for dilation in dilations:
self.append(
ConvModule(
self.in_channels,
self.channels,
1 if dilation == 1 else 3,
dilation=dilation,
padding=0 if dilation == 1 else dilation,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg))
def forward(self, x):
"""Forward function."""
aspp_outs = []
for aspp_module in self:
aspp_outs.append(aspp_module(x))
return aspp_outs
@HEADS.register_module()
class ASPPHead(BaseDecodeHead):
"""Rethinking Atrous Convolution for Semantic Image Segmentation.
This head is the implementation of `DeepLabV3
`_.
Args:
dilations (tuple[int]): Dilation rates for ASPP module.
Default: (1, 6, 12, 18).
"""
def __init__(self, dilations=(1, 6, 12, 18), **kwargs):
super(ASPPHead, self).__init__(**kwargs)
assert isinstance(dilations, (list, tuple))
self.dilations = dilations
self.image_pool = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
ConvModule(
self.in_channels,
self.channels,
1,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg))
self.aspp_modules = ASPPModule(
dilations,
self.in_channels,
self.channels,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg)
self.bottleneck = ConvModule(
(len(dilations) + 1) * self.channels,
self.channels,
3,
padding=1,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg)
def forward(self, inputs):
"""Forward function."""
x = self._transform_inputs(inputs) # x.shape=[4, 2048, 64, 128]
aspp_outs = [
resize(
self.image_pool(x),
size=x.size()[2:],
mode='bilinear',
align_corners=self.align_corners)
]
# len(aspp_outs) = 1
# aspp_outs[0].shape = [4, 512, 64, 128]
aspp_outs.extend(self.aspp_modules(x))
# len(aspp_outs) = 5
# aspp_outs[0-4].shape = [4, 512, 64, 1024]
aspp_outs = torch.cat(aspp_outs, dim=1) # [4, 2560, 64, 128]
output = self.bottleneck(aspp_outs) # [4, 512, 64, 128]
output = self.cls_seg(output) # [4, 19, 64, 128]
return output
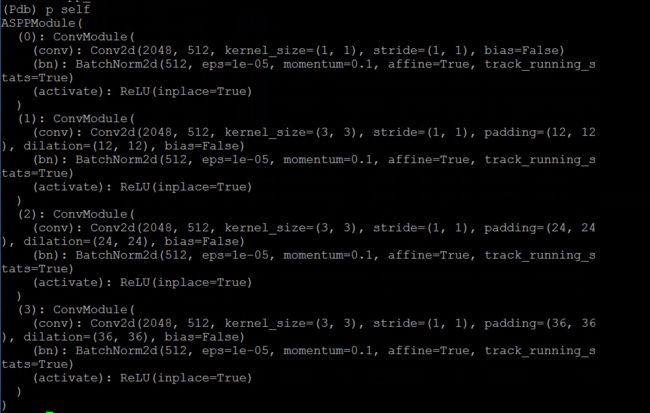
ASPP module: