华为GhostNet
华为GhostNet
1. 引言
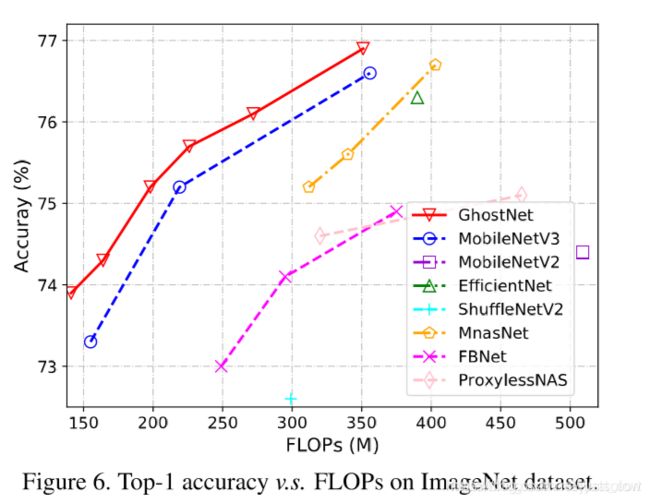
受限于内存以及计算资源,将常规的CNN架构部署到移动设备是件非常困难的事。近几年来有各种移动端网络架构设计,大部分都是从减少卷积计算量的思路出发,谷歌出品的Mobilenet系列是提出了「Depthwise+Pointwise卷积」来减少计算量,旷视则是提出「通道混洗」,利用转置操作,均匀的shuffle各个通道进行卷积。Mixnet是在Mobilenet基础上,关注了卷积核的大小,通过「不同大小卷积核」所生成的卷积图在不增加计算量前提下进一步提高精度。而华为的Ghostnet则是聚焦于「特征图冗余」,希望通过少量的计算(即论文里的cheap operation)得到大量特征图。而Ghostnet在相同计算量下,精度超越了Mobilenetv3,达到了75.7%分类准确率( ImageNet ILSVRC-2012 classification dataset)
2. 何为特征图冗余?
首先作者对训练好的Resnet-50模型进行了特征图可视化

这里作者标出了三组特征图,认为这些特征图彼此是类似的,我们可以用一些cheap operation来得到
因此我们从这里入手,以一种更高效的方式生成这些"Ghost"一样的特征图
3. GhostModules提出
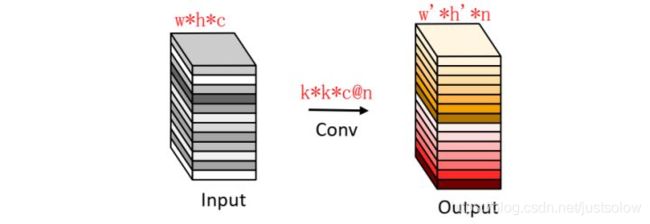
在引言我们也提到了Depthwise+Pointwise卷积,其中1x1卷积层也需要大量的内存和计算量
常规卷积:我们通常使用的卷积是下图这种:
Ghost Module:分为常规卷积、Ghost生成和特征图拼接三步(如下图所示):
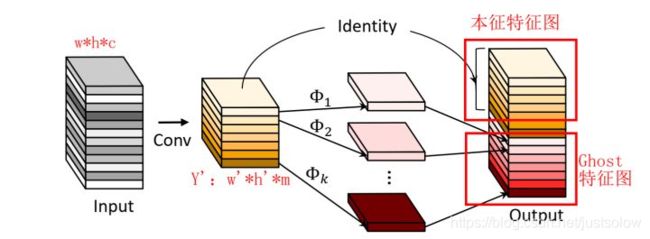
论文中对其这种骚操作的描述是一种线性变换,开始看的时候一头雾水,后来仔细一看所谓的线性变换就是卷积操作而已(普通的卷积就包含了常规的线性操作,比如旋转,平移,仿射变换,小波变换等。)。前面的普通卷积操作其实全部都是PointwiseConv,为了节省计算量。后进行DepthwiseConv,另外增加了DepthwiseConv的数量,包括一个恒定映射。
代码如下:
可以清晰的看出来,普通卷积的kernel_size=1,就是PointwiseConv,加入进来的新卷积核为dw_size=3,也就是DepthwiseConv。
class GhostModule(nn.Module):
def __init__(self, inp, oup, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True):
super(GhostModule, self).__init__()
self.oup = oup
init_channels = math.ceil(oup / ratio)
new_channels = init_channels*(ratio-1)
self.primary_conv = nn.Sequential(
nn.Conv2d(inp, init_channels, kernel_size, stride, kernel_size//2, bias=False),
nn.BatchNorm2d(init_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
self.cheap_operation = nn.Sequential(
nn.Conv2d(init_channels, new_channels, dw_size, 1, dw_size//2, groups=init_channels, bias=False),
nn.BatchNorm2d(new_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
def forward(self, x):
x1 = self.primary_conv(x)
x2 = self.cheap_operation(x1)
out = torch.cat([x1,x2], dim=1)
return out[:,:self.oup,:,:]
代码中primary_conv就是常规的卷积,而cheap operation就是一个Depthwise卷积,通过参数ratio,来控制两部分生成特征图数量之比。最后调用torch.cat连结两部分特征图
作者也给出了计算量压缩比公式
PS: 对于上面的过程也可以这样理解,对于Y’(m通道)中的每一个特征图,对其进行s次映射,s次中包含一次恒等映射,其余s-1次为cheap operate来得到Ghost特征图。所以最终得到m*s通道的输出结果。理论上完全一致。
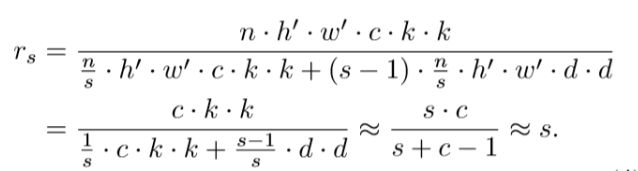
分子式子表示的是普通卷积的计算量,这里n/s=m。
分母左边的式子,代表的是primaryconv的卷积量,右边式子代表的是cheap operation计算量,通过参数s(对应代码中的ratio)来控制两者卷积量之比
最后这里的近似做个说明, dxd计算量于k*k类似,而c代表的通道数远大于s,因此最终近似结果为s。
其中一个疑问?
那么既然前面说了cheap operation是个线性变换,但是在代码实现中,作者在模块最后还是加入了Relu。其实我当时是很疑惑的,因为众所周知加入了Relu激活函数就打破了函数的线性关系。后面在github提了一个小issue
得到的回复是 Relu可以在最后的concat上做,之所以放到前面是为了降低latency
4、GhostBottleNeck
Ghost BottleNeck整体架构和Residual Block非常相似,也可以直接认为是将Residual Block中的卷积操作用Ghost Module(GM)替换得到。
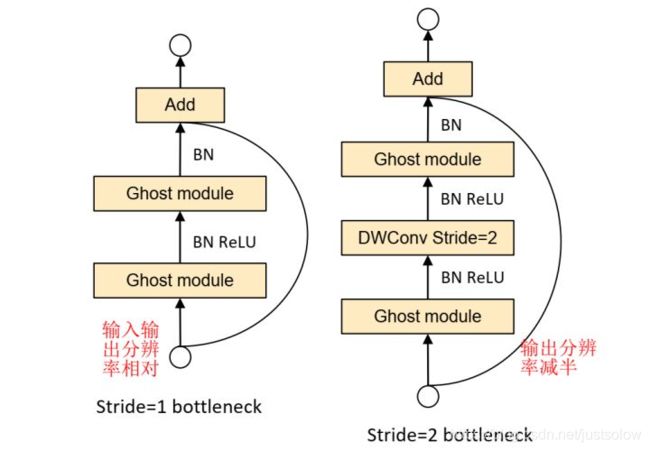
上图基本上对Ghost描述的很清楚,第一张图(左,stride=1)主干通路用两个Ghost Module(GM)串联组成,其中第一个GM扩大通道数,第二个GM将通道数降低到与输入通道数一致;跳跃连接通路与ResNet使用方法一样。这样一来,Ghost BottleNeck输入输出维度也一致了,可以和ResBlock一样,很方便地嵌入到其他CNN网络中。
第二张图(右,stride=2)和第一张图的不同之处在于,主干通路的两个GM之间加入了一个stride=2的Deepwise卷积,可以将特征图大小降为输入的1/2,同样跳跃连接通路也需要同样的降采样,以保证Add操作可以对齐。这个模块可以用来替换其他CNN中的降采样层(1/2)。
并且引入了SElayer,增加了特征图注意力机制。
PS:Ghost BottleNeck的Add操作前主干通路不进行ReLU激活(参考了MobileNetV2);
实际应用中,为了进一步提高效率,GhostModule中的所有常规卷积都用pointwise卷积代替。
代码如下:
class GhostBottleneck(nn.Module):
def __init__(self, inp, hidden_dim, oup, kernel_size, stride, use_se):
super(GhostBottleneck, self).__init__()
assert stride in [1, 2]
self.conv = nn.Sequential(
# pw
GhostModule(inp, hidden_dim, kernel_size=1, relu=True),
# dw
depthwise_conv(hidden_dim, hidden_dim, kernel_size, stride, relu=False) if stride==2 else nn.Sequential(),
# Squeeze-and-Excite
SELayer(hidden_dim) if use_se else nn.Sequential(),
# pw-linear
GhostModule(hidden_dim, oup, kernel_size=1, relu=False),
)
if stride == 1 and inp == oup:
self.shortcut = nn.Sequential()
else:
self.shortcut = nn.Sequential(
depthwise_conv(inp, inp, 3, stride, relu=True),
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
def forward(self, x):
return self.conv(x) + self.shortcut(x)
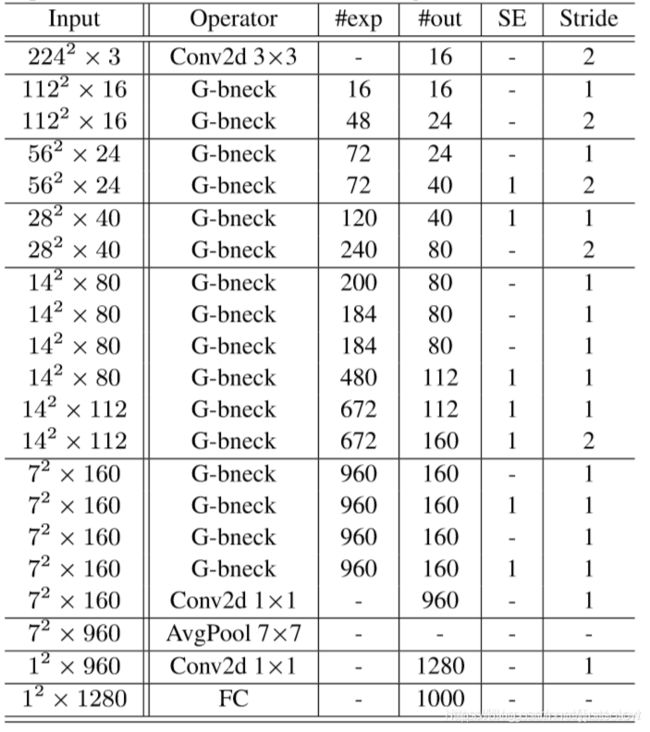
架构图:
实验图: