GhostNet网络
1911_GhostNet:
图:
网络描述:
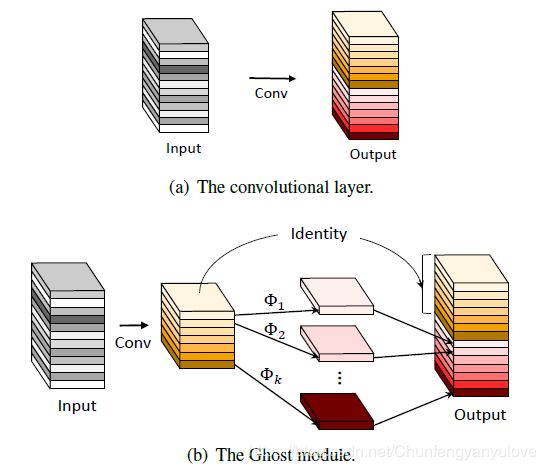
本篇论文是发表于CVPR2020的一篇轻量级网络的论文,作者是华为诺亚方舟实验室,文章的总体思路比较清晰,为了减少网络计算量,作者将传统的卷积分成两步进行,首先利用较少的计算量通过传统的卷积生成channel较小的特征图,然后在此特征图的基础上,通过cheap operation(depthwise conv)再进一步利用较少的计算量,生成新的特征图,最后将两组特征图拼接到一起,得到最终的output,最终实验效果还不错,相同计算量的情况下比MobileNet- V3的效果还要更好一些。
特点,优点:
与目前主流的卷积操作对比,Ghost模块有以下不同点:
(1) 对比Mobilenet、Squeezenet和Shufflenet中大量使用1 × 1 1\times 11×1 pointwise卷积,Ghost模块的原始卷积可以自定义卷积核数量
(2) 目前大多数方法都是先做pointwise卷积降维,再用depthwise卷积进行特征提取,而Ghost则是先做原始卷积,再用简单的线性变换来获取更多特征
(3) 目前的方法中处理每个特征图大都使用depthwise卷积或shift操作,而Ghost模块使用线性变换,可以有很大的多样性
(4) Ghost模块同时使用identity mapping来保持原有特征
代码:
keras实现:
def slices(x,channel):
y = x[:,:,:,:channel]
return y
def GhostModule(x,outchannels,ratio,convkernel,dwkernel,padding='same',strides=1,data_format='channels_last',
use_bias=False,activation=None):
conv_out_channel = math.ceil(outchannels*1.0/ratio)
x = Conv2D(int(conv_out_channel),(convkernel,convkernel),strides=(strides,strides),padding=padding,data_format=data_format,
activation=activation,use_bias=use_bias)(x)
if(ratio==1):
return x
dw = DepthwiseConv2D(dwkernel,strides,padding=padding,depth_multiplier=ratio-1,data_format=data_format,
activation=activation,use_bias=use_bias)(x)
#dw = dw[:,:,:,:int(outchannels-conv_out_channel)]
dw = Lambda(slices,arguments={'channel':int(outchannels-conv_out_channel)})(dw)
x = Concatenate(axis=-1)([x,dw])
pytorch实现:
class SELayer(nn.Module):
def __init__(self, channel, reduction=4):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel), )
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
y = torch.clamp(y, 0, 1)
return x * y
def depthwise_conv(inp, oup, kernel_size=3, stride=1, relu=False):
return nn.Sequential(
nn.Conv2d(inp, oup, kernel_size, stride, kernel_size//2, groups=inp, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
class GhostModule(nn.Module):
def __init__(self, inp, oup, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True):
super(GhostModule, self).__init__()
self.oup = oup
init_channels = math.ceil(oup / ratio)
new_channels = init_channels*(ratio-1)
self.primary_conv = nn.Sequential(
nn.Conv2d(inp, init_channels, kernel_size, stride, kernel_size//2, bias=False),
nn.BatchNorm2d(init_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
self.cheap_operation = nn.Sequential(
nn.Conv2d(init_channels, new_channels, dw_size, 1, dw_size//2, groups=init_channels, bias=False),
nn.BatchNorm2d(new_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
def forward(self, x):
x1 = self.primary_conv(x)
x2 = self.cheap_operation(x1)
out = torch.cat([x1,x2], dim=1)
return out[:,:self.oup,:,:]
class GhostBottleneck(nn.Module):
def __init__(self, inp, hidden_dim, oup, kernel_size, stride, use_se):
super(GhostBottleneck, self).__init__()
assert stride in [1, 2]
self.conv = nn.Sequential(
# pw
GhostModule(inp, hidden_dim, kernel_size=1, relu=True),
# dw
depthwise_conv(hidden_dim, hidden_dim, kernel_size, stride, relu=False) if stride==2 else nn.Sequential(),
# Squeeze-and-Excite
SELayer(hidden_dim) if use_se else nn.Sequential(),
# pw-linear
GhostModule(hidden_dim, oup, kernel_size=1, relu=False),
)
if stride == 1 and inp == oup:
self.shortcut = nn.Sequential()
else:
self.shortcut = nn.Sequential(
depthwise_conv(inp, inp, kernel_size, stride, relu=False),
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
def forward(self, x):
return self.conv(x) + self.shortcut(x)
class GhostNet(nn.Module):
def __init__(self, cfgs, num_classes=1000, width_mult=1.):
super(GhostNet, self).__init__()
# setting of inverted residual blocks
self.cfgs = cfgs
# building first layer
output_channel = _make_divisible(16 * width_mult, 4)
layers = [nn.Sequential(
nn.Conv2d(3, output_channel, 3, 2, 1, bias=False),
nn.BatchNorm2d(output_channel),
nn.ReLU(inplace=True)
)]
input_channel = output_channel
# building inverted residual blocks
block = GhostBottleneck
for k, exp_size, c, use_se, s in self.cfgs:
output_channel = _make_divisible(c * width_mult, 4)
hidden_channel = _make_divisible(exp_size * width_mult, 4)
layers.append(block(input_channel, hidden_channel, output_channel, k, s, use_se))
input_channel = output_channel
self.features = nn.Sequential(*layers)
# building last several layers
output_channel = _make_divisible(exp_size * width_mult, 4)
self.squeeze = nn.Sequential(
nn.Conv2d(input_channel, output_channel, 1, 1, 0, bias=False),
nn.BatchNorm2d(output_channel),
nn.ReLU(inplace=True),
nn.AdaptiveAvgPool2d((1, 1)),
)
input_channel = output_channel
output_channel = 1280
self.classifier = nn.Sequential(
nn.Linear(input_channel, output_channel, bias=False),
nn.BatchNorm1d(output_channel),
nn.ReLU(inplace=True),
nn.Dropout(0.2),
nn.Linear(output_channel, num_classes),
)
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = self.squeeze(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def ghost_net(**kwargs):
"""
Constructs a GhostNet model
"""
cfgs = [
# k, t, c, SE, s
[3, 16, 16, 0, 1],
[3, 48, 24, 0, 2],
[3, 72, 24, 0, 1],
[5, 72, 40, 1, 2],
[5, 120, 40, 1, 1],
[3, 240, 80, 0, 2],
[3, 200, 80, 0, 1],
[3, 184, 80, 0, 1],
[3, 184, 80, 0, 1],
[3, 480, 112, 1, 1],
[3, 672, 112, 1, 1],
[5, 672, 160, 1, 2],
[5, 960, 160, 0, 1],
[5, 960, 160, 1, 1],
[5, 960, 160, 0, 1],
[5, 960, 160, 1, 1]
]
return GhostNet(cfgs, **kwargs)
if __name__=='__main__':
model = ghost_net()
model.eval()
print(model)
input = torch.randn(32,3,224,224)
y = model(input)
print(y)