Programming Languages PartA Week3学习笔记——SML基本语法第二部分
文章目录
-
-
- Building Compound Types
- Records
- Tuples as Syntactic Sugar
- Datatype Bindings
- Case Expressions
- Useful Datatypes
- Pattern Matching的总结
- Type Synonyms
- List and Options are Datatypes
- Polymophic Datatypes
- Each of Pattern Matching / Truth About Functions
- A Little Type Inference
- Polymorphic and Equality Types
- Nested Patterns
- Nested Patterns Precisely
- Function Patterns
- Exceptions
- Tail Recursion
- Accumulators for Tail Recursion
- Perspective on Tail Recursion
-
Building Compound Types
Each of:例如三维空间的x、y、z坐标,一个人的first和last name
One of:例如今天的天气(sunny、partly cloudy、rainy …),打印机的状态(正在打印、等待打印…)

SML中的building-blocks例子


Records
一种包含有field的"Each of" type ,类似于Python的字典,同样的,SML的Records是一种无序字典,例如:
val x = {bar=(1+2,true andalso true), foo=3+4, baz=(false,9)}
(* 获取其中的值使用#field的方式,例如,如果访问的field不存在,会造成type error (statically) *)
#bar x



Tuples as Syntactic Sugar
简单来说就是使用Record生成Tuple,当Record的field是从数字时,可以以任意顺序生成tuple(field数量必须与元素数量相等),即tuple其实是特殊的record,称为语法糖说明这让各种语法更统一(或更简洁),例如:


Datatype Bindings
自定义数据类型,使用datatype关键词定义数据类型,并使用构造函数获取该类型值,例如下图的多个构造函数(类似C++构造函数的重载,可以使用不同类型的参数)。其中Pizza并不是函数,因为没有任何参数,它本身就是一个datatype的值。另外管道符“|”用来分割不同的构造函数。

注意:由于SML的函数可以作为值传递,构造函数也可以作为值传递。函数作为值传递是函数式编程的一大特点,例如下面的例子:
fun swap(s:int*int) =
(#2 s, #1 s)
val funAsValue = swap
val test_tuple = (1,2)
val swap1 = swap(test_tuple)
val sawp2 = funAsValue(test_tuple)
fun f_swap(s:int*int, f:(int*int)->(int*int)) =
f(s)
val swap3 = f_swap(test_tuple, swap)
上述代码的结果可以看到,函数本身就是一个值,可以作为其他变量的值,可以作为其他函数的参数传入。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-k574qzWl-1663158049051)(D:\OneDrive - whu.edu.cn\Programming_Languages_PartA\Week3\week3.assets\image-20220513111042065.png)]
对于数据类型绑定的构造函数,有下面的例子:
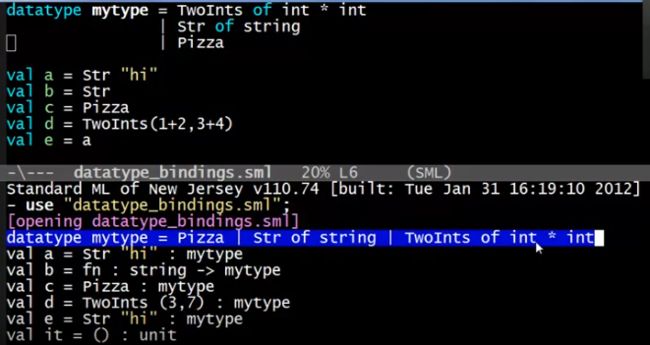
值得注意的是比如a的value是Str “hi”,这是一整个值(是mytype类型的值),Str用来标记(tag)整个mytype类型的数据值来自哪个构造函数,类似Str "hi"的值被称为标记组合(tag union)。d的value是TwoInts (3,7)也是同样的道理。


Case Expressions
Case的用法和其他语言差不多,即用一种数据类型的多个不同值映射到(另一个数据类型的)其他不同值,注意case小写。

Case在匹配的时候对Pattern进行匹配,Patten是不能计算值的一种形式,例如TwoInts(i1,i2),i1和i2只是表示TwoInts之后需要跟两个值,但在这里不是具体的表达式或者值(类似函数定义时的形式参数)。每个Pattern中用的变量名不可以相同。


上图中的第0条是指:Pattern match 可以用来作为测试或者data-extraction函数(比如Pizza输出True,其他的输出False),但这是不推荐的,因为这样丧失了Pattern match的优势(用其他方法就能做到所以就不需要用Case的Pattern match)。
第1条是指:如果使用mytype作为参数,Case应该包含mytype的各种情况(各种构造函数的情况),不然编译器会给出warning例如:
fun g x = case x of Pizza => 3
第2条是指:Case不能重复,否则由于重复的case永远不会被执行,会给出type-checking error
第3条是指:不会忘记测试变量是否有值,因为Pattern本身就是有值的形式,如果被匹配到了说明已经能够取到正常的值了,不会出现hd []这种情况(因为不会匹配这种Pattern)
Useful Datatypes
从应用上来说,datatype是可对应不同类型不同值的一个类型(有点类似java的枚举类型或者C的结构体struct但又不太相似),所以把它看做是SML特有的一种新的概念可能会更好。

datatype实际上是一种one-of 类型,当我们需要one-of 来表达一些信息的时候,就不应该用each-of数据类型来表示,例如在id这个抽象事物中,由于student_num 和 后面的Name之间是并列的“或”关系(one-of),如果用Record来表示就会显得混乱。

但另一方面,当我们要描绘的事物不是id而是某个“人”,这个“人”同时具备student_num和Name时,就是一种each-of关系了,此时使用Records就类似于其他语言通过结构体或者类(或者字典)来记录这个人的信息。

除了one-of和each-of,还有self-reference的关系,在datatype中可以使用自引用(在datatype的定义中使用这个datatype,但跟递归一样需要有一个最终的落脚点(例如下图的Constant of int)),下图:

使用这样的自引用结构的datatype的function也一定是递归的:

示例:

Pattern Matching的总结
datatype的type checking 和 valuation

对于case:

案例:

(* 示例代码 *)
datatype exp = Constant of int
| Negate of exp
| Add of exp*exp
| Multiply of exp*exp
(* bad style *)
fun max_constant e =
Case e of Constant i => i
| Negate e2 => max_constant e2
| Add (e1,e2) => if max_constant e1 > max_constant e2
then max_constant e1
else max_constant e2
| Multiply (e1,e2) => if max_constant e1 > max_constant e2
then max_constant e1
else max_constant e2
(* good style : 可重用代码写在嵌套函数中,重复计算的递归值存到let中变量中 *)
fun max_constant e =
let fun max_of_two(e1,e2) =
let val m1 = max_constant e1
val m2 = max_constant e2
in if m1>m2 then m1 else m2 end
in
Case e of Constant i => i
| Negate e2 => max_constant e2
| Add (e1,e2) => max_of_two(e1,e2)
| Multiply (e1,e2) => max_of_two(e1,e2)
end
(* 另外,使用已有的标准函数库,能让程序更简化。例如Int.max,并且递归值作为该函数的参数时不会像if then else 那样多次计算(已经保存在局部变量中),所以可以不需要再定义局部变量m1和m2 *)
fun max_constant e =
let fun max_of_two(e1,e2) =
Int.max(max_constant e1,max_constant e2)
in
Case e of Constant i => i
| Negate e2 => max_constant e2
| Add (e1,e2) => max_of_two(e1,e2)
| Multiply (e1,e2) => max_of_two(e1,e2)
end
Type Synonyms
type关键词用于为已有类型设置一个别名,相当于C语言的typedef

例如:
(* suit and rank are datatype*)
type card = suit * rank
(* type也能用于record的别名 *)
type name_record = {student_num : int,
first : string,
middle : string option,
last : string}
List and Options are Datatypes
List 可用datatype递归定义,下面是一个例子,但不推荐这样使用。

option中的NONE 和 SOME是构造器,option本身是个datatype。用Case代替isSOME和valOf是一种更好的方式。

list的[]和:: 符号也是构造器,能够通过Case的x::xs’模式来提取hd xs(即下图的x)


Polymophic Datatypes
多态类型,由于list和option都必须是某种类型的list或option(不指定类型就是’a 'b 'c这样的不指定的类型,具有多态特性),所以list和option本身不是types


同时函数的参数不指定具体的类型,则默认是’a,任意类型,由编译器来判断调用时的真实类型。
(* 内部节点上没有数据,并且叶节点有两种不同类型的二叉树 *)
datatype ('a,'b) flower =
Node of ('a,'b) flower * ('a,'b) flower
| Leaf of 'a
| Petal of 'b
Each of Pattern Matching / Truth About Functions
关于函数的真相:每个变量和函数的绑定都使用Patter-matching,每个函数实质上都有且只有一个参数。

One-of types(例如datatype)使用pattern match,同时,each-of types (tuple、records)也使用pattern match,如下图,简单来说我们使用(x1,…,xn)的形式去匹配某个表达式例如(1,2,3,5+1)并valuate,认为这就是一个tuple,从而取值;使用{f1=x1,…,fn=xn}的形式去匹配某个表达式例如{name=jack,num=1+1}并valuate,认为这就是一个record,从而取值。patter match一般是用在access values时。


Val-binding 可以通过patterns来匹配,举个例子假如e是一个tuple表达式,p可以是(x1,…,xn)这样的模式,就将e的值赋值到对应的x1…xn变量中(有点类似于python的元组解包)。
另外假如constructor pattern用在val-binding中,由于构造器可能本身就是一种pattern,所以如果p和e不是同一种variant,会抛出a nonexhaustive binding 的异常。


Function-argument patterns 也和python的解包类似

注意,上述full_name函数的参数是个record的pattern(用的是{},而不是小括号),所以需要特别注意的是SML中的函数都不需要用括号括起来,如果用小括号括起来代表是一个tuple(不论是定义,还是调用时都是,比如 f(1),调用时相当于就是一种pattern match,跟 f 1的结果是一样的)

另外,由于函数都有且只有一个参数,如下的没有参数的函数也有一个参数:
fun hello() = print "Hello World!\n";
此时的参数type是unit,()是用来匹配unit的唯一value的pattern

A Little Type Inference
如果函数参数以pattern match的方式定义(且函数体中没有使用类似#1 或 #foo的方式访问元素),可以不表明类型。假如函数参数不使用pattern match的方式定义,而是使用一个某种tuple 或 record类型的参数,则必须标明类型,否则编译器不知道这个参数具体是一个怎么样(有多少元素或有哪些field)的tuple 或record。
例如:
fun sum_triple2 (triple: int*int*int) =
#1 triple + #2 triple + #3 triple
fun full_name2 (r:{first:string, middle:string, lats:string}) =
#first r ^ " " ^ #middle r ^ " " ^ #last r
(* 如果不标明类型就会抛出异常,例如 *)
fun sum_triple2 triple =
#1 triple + #2 triple + #3 triple
fun full_name2 r =
#first r ^ " " ^ #middle r ^ " " ^ #last r
编译器会根据函数内容判断类型,保证SML语言的一些基本特征,例如:
fun mystery x = case x of
(1,b,c) => #2 x + 10
| (a,b,c) => a * c
编译器的判断步骤:
首先根据(1,b,c)判断x的第一个元素为int;
其次由于x是元组,1和a在同一个位置必然是同样的类型,同时由于a*c必须同类型(基本特征1:运算必须同类型),判断x的第三个元素为int;且#2 x + 10运算也需要同类型,x的第二个元素也为int。
最后,由于(基本特征2:函数的返回值必须是同类型),且#2 x + 10和a*c都返回int,所以case的两种模式返回值类型不矛盾,必然是一个int。
因此:函数类型是int*int*int -> int
注意,如果编译器不能判断类型的参数就会是任意类型,例如’a 'b…,同时,如果参数在表达式中进行了运算,但又没指定类型,会默认是int类型。例如:
fun partial_sum (x,y,z) =
x+z
![]()

Polymorphic and Equality Types
这一节比较抽象,首先的一个rule是如果某个类型t1比t2更通用(例如’a比int更通用),就用t1类型代替t2类型的变量,然后在实际调用时使用t2。这里的思想其实就是多态,函数多态定义(不判断具体类型相当于每种类型的重载都定义了),调用的时候再确定具体的类型。


第二点rule是,我们可以组合某个通用类型与其他相等的通用类型(用来区别这些不同的类型),但type别名或者更换field顺序(通用性是相等的)不会使得类型更通用

相同类型,使用两个引号表示:''a,由表示逻辑运算的=运算得到。

这个运算不会像赋值或者算术运算一样得到一个具体的类型(或者默认获得int类型),而是得到’'a类型,表示两个变量的类型相同,但他们具体是什么类型不重要(更通用):

Nested Patterns
嵌套pattern其实就是更灵活的使用pattern match,比如可以在pattern中解包(例如把每个元素是tuple的list解包到tuple的每个元素,(a,b,c) :: tl),或者按照想要的深度嵌套pattern(比如 x::y::zs ,可以用来匹配至少含有两个元素的list,x和y为单个元素,zx为子列表)

例子:

要实现zip的功能,先给了两个不好的例子


然后给了一个比较好的nest pattern的zip例子

然后是unzip的例子

嵌套pattern的其他例子:


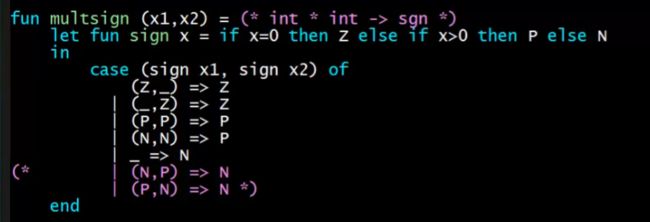
Nested Patterns Precisely
Nested Pattern 匹配的细节,各种pattern都有一套独立的rule来进行match’和binding

Function Patterns
类似显式定义函数的重载(但参数仍然是同一种类型,只是值不同,pattern不同),用多种参数pattern直接作为函数的参数,而不是通过设定某个参数再使用case判断pattern。例如:

Exceptions


异常的关键词exception、raise和handle

跟其他语言的Exception类不太一样,SML的exception关键词定义的不是一个datatype,而相当于定义一个datatype 的constructor。调用时相当于是exn这个数据类型的一些值(例如MySecondException(7,9)是exn的一个值)。

Tail Recursion
递归通常不会比循环更复杂而且有一些优势,但我们需要讨论递归的效率

递归的调用栈和其他语言类似,这一节其实应该在这个课程中早一点讲(毕竟SML的很多函数都需要用到递归)


下面的例子中在递归返回之后函数没有其他的步骤要做(比如上一个例子中的与n的乘法)。这里通过acc参数跟着递归函数层层计算得到最终结果,调用栈返回的时候不会再改变这个值(不会再进行其他步骤,也不就会有计算)。尾递归的逻辑本质上和循环是一致的。

这里的递归调用栈只是一种理论上的模拟,但实际上SML为尾递归进行了优化。后面介绍例子。
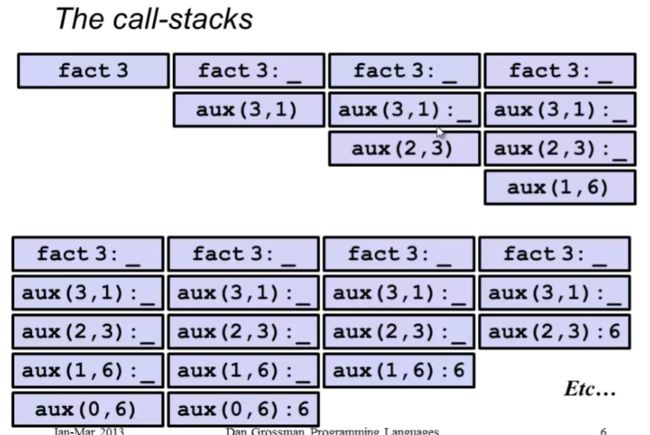
尾递归:

值得注意的是SML中,编译器会为尾递归专门优化,由于尾递归的每个函数call返回值都相同,因此不需要把每个call都入栈记录下来,真实的情况是将上一个caller(上一轮递归的函数call)出栈,再让callee(被递归的函数call)入栈,比如下面的例子:此时递归过程只占用O(1)的栈空间。

尾递归生成列表时要注意列表的顺序,普通递归使用::符号一般不会改变参数列表的原有顺序(一般都是从最后一个元素开始运算,并且结果(先进入列表)放在列表末尾),尾递归实际上类似循环,所以是排在前面的元素(先进入列表)放在列表末尾,所以编写代码要注意自己调整顺序。
Accumulators for Tail Recursion
尾递归方法论:首先定义带有accumulator(累加变量)的helper function ,然后调用时指定accumulator初始值,返回时返回累加后的accumulator。其实可以当成循环变量来理解。

一些例子:


某些情况下,尾递归虽然比普通递归速度快,但都是同样的数量级。例如fact和sum函数都是O(n)。
但上面反转列表函数的第二个例子中,x::acc的耗时是常量,而第一个例子的 @ 运算是append,时间是O(n^2),所以这个时候使用尾递归的特性来反转列表最好。

Perspective on Tail Recursion
虽然尾递归能够让递归的空间复杂度降低到常数O(1),但不是所有场景都能用尾递归表示(甚至某些场景不能用常数或线性的空间复杂度来描述,例如二叉树)

更精准的定义尾递归,tail position,一般来说,作为直接返回值(输出值)的位置就是tail position

