论文笔记:Convolutional Image Captioning
Convolutional Image Captioning
1、提出方法
近年来,使用由长短期记忆 (LSTM) 单元驱动的循环神经网络,在图像描述方面取得了重大进展。尽管它缓解了梯度消失问题,并且具有强大的记忆依赖性的能力,但 LSTM 单元是复杂的,并且在时间上具有内在的顺序性。
2、创新点
提出了一种卷积(基于 CNN)的图像描述方法,并使用注意力机制来利用空间图像特征。
3、方法
3.1、RNN Approach
这里回顾基于 RNN/LSTM 的方法。
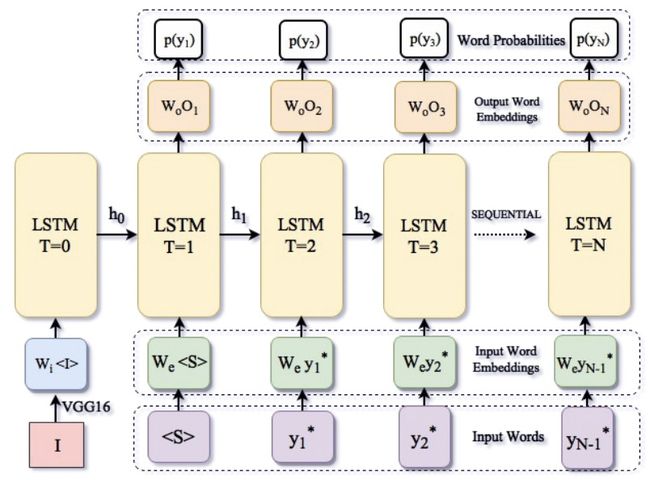
传统的 RNN 结构包含三部分:输入词嵌入、包含存储单元的顺序 LSTM 单元、输出词嵌入。
Inference:
RNN 按照顺序在每个时间步预测一个单词,从 y1 到 yN 。 在每一个时间步 I ,一个依赖于参数 W 的条件概率分布 pi,w(yi|I) 被预测出来。 在推理过程中,我们通常选择概率最高的词 pi,w(yi|I) 。 一旦到了句尾标记 < E >,或者到了句子设定的长度时,句子输出结束。
pi,w(yi|I) 中 yi 与之前所有的单词 yi 包含了这种依赖性。这个概率是通过以下步骤计算的:
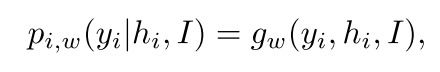
其中 gw 可以是任何可微函数/深度网络。 这个函数可能直接依赖于图像 I 。经典的图像描述方法通常将图像 I 编码为初始的隐藏状态 h0。
而隐藏状态 hi 也与前面的状态 hi-1、输入的图像 I、前面的单词输入yi-1有关:
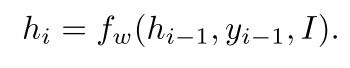
同样,fW 可以是任何可微函数。这个递归函数,一般不直接对输入的独热向量进行操作,输入词通过嵌入层编码成向量表示。
Learning:
word embedding 和 LSTM 的参数 w 可以通过最小化训练数据的负对数似然来获得:
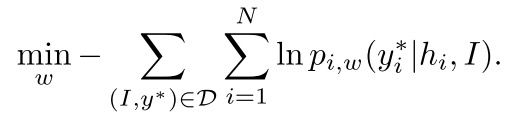
为了避免更复杂的 gradient flows ,在训练过程中,传给下一时间步 LSTM 的单词用的是 ground-truth 的 y*i-1 ,而不是上一时间步预测到的 yi-1。
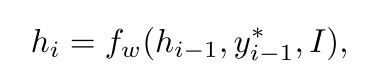
这被称为 teacher forcing 。 虽然这简化了gradient flows ,但它显然会导致训练和测试时的输入信息的不同。
基于 RNN 的技术存在的不足:必须按时序来输出结果;分类准确率低;仍然存在梯度消失的问题。
3.2、Convolutional Approach
这里简介本文提出的 CNN 模型。
这个卷积模型参考《Convolutional sequence to sequence learning》。

我们的模型包含三部分:输入词嵌入、masked convolutions、输出词嵌入。
我们使用了一个带有 masked convolutions 的前馈网络,它没有任何循环功能。 与 RNN 不同,我们的模型可以并行地操作所有单词。
Inference:
我们使用一个简单的前馈网络 fw 来输出概率 pi,w(yi|I) 。 对一个词 yi 的预测依赖于前面的词 y
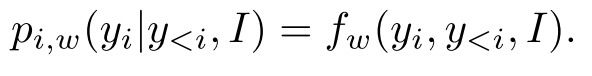
为了不让卷积操作使用当前单词之后的单词,使用 masked convolutional 层来只针对“过去”的单词。
因此,推理从起始标记 < s > 开始,并使用前馈传递过来生成概率 p1,w(y1| ϕ \phi ϕ, I) 。 然后,对 y1~p1,w(y1| ϕ \phi ϕ, I) 进行采样。 采样结束后, y1 反馈到前馈网络中,用来生成后续字 y2 。一旦到了句尾标记 < E >,或者到了句子设定的长度时,句子输出结束。
Learning:
与 RNN 训练类似,我们对过去的单词使用 ground-truth y*< i,而不是使用生成的单词 y < i 。对于词概率 pi,w(yi|y* 这里更详细地介绍 CNN 模型。 我们的处理步骤如下:(1)通过一个输入嵌入层; (2)与图像嵌入相结合; (3)由 CNN 模块进行处理; (4)通过一个输出嵌入(或分类)层产生输出概率分布。 下面将讨论上述四个步骤中的每一个步骤: Input Embedding: 每个单词看作一个9221维的独热向量,我们使用 |Y|=9221 维(Y看作单词集,共9221个),然后将输入的单词嵌入到512维向量中。接下来我们需要拼接图像嵌入,作为 CNN 模块的输入。 Image Embedding: 图像 I 的特征通过 VGG16 网络的 FC7 层提取,然后经过 dropout、ReLU、线性层获得一个512维的嵌入。他和上面的 Input Embedding 共同作为 CNN 模块的输入。 CNN Module: CNN 模块对输入和图像的嵌入向量共同进行操作。它包含三层 masked convolutions ,每一层卷积的 padding 都补0以保证最后输出也是512维。使用 GLU 激活函数,还是用了normalization, residual connections Classification Layer: 我们通过线性层将从 CNN 模块输出的512维向量变为256维。 然后,我们通过一个全连接层将该向量上采样到9221维,再通过一个 softmax 得到输出字概率 pi,w(yi|I) 。 Training: 我们使用交叉熵损失在概率 pi,w(yi|y 我们还提出了一种注意机制。 我们形成一个维度为512的图像向量,并将其添加到每个层的单词嵌入中(图中用红色、绿色和蓝色箭头显示)。 我们为每个词计算单独的注意力参数和单独的关注向量。 在维度为 7×7×512 的VGG16 MaxPooled Conv-5特征上,我们预测了 7×7 的注意参数。我们在每个 Masked convolutions 层都使用注意力。 dj 是第 j 个单词的 GLU 之后的输出,W 表示对 dj 的线性变换,ci 是从 VGG16 后得到的 7x7x512 的特征,让 aij 表示注意力参数。 得到注意力参数 aij 的计算为: 最后 aij 和 ci 逐元素相乘得到注意力模块的输出: ∑ \sum ∑i aijci 另一位大佬的笔记3.3、Architecture
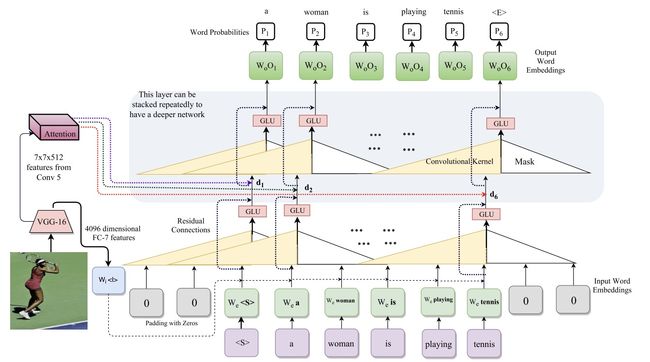
和 dropout 来提升性能。Masked convolutions 的接受域为5。设置句长N(最大句子长度)最大为15。3.3.1、Attention
